Recognition: 2 theorem links
· Lean TheoremRisk-Consistent Multiclass Learning from Random Label-Subset Membership Queries
Pith reviewed 2026-05-11 01:45 UTC · model grok-4.3
The pith
Random label-subset queries support unbiased multiclass risk estimation under ERM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
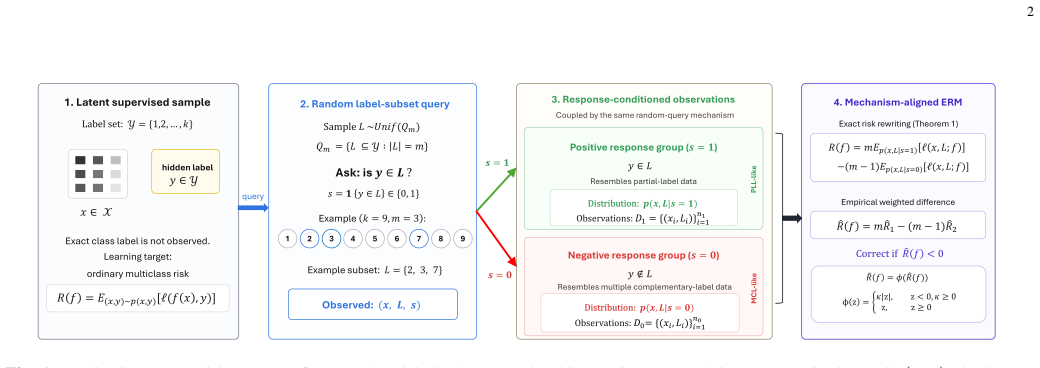
The authors model the data-generating process for instances paired with random label-subset queries and their responses. From this they derive an unbiased estimator of the target multiclass risk that can be plugged into empirical risk minimization. To fix the problem of negative empirical risks, they propose two corrected estimators using non-negative and absolute-value operations. Theoretical results include a conditional generalization bound and excess-risk bound for the unbiased estimator along with a bias-and-consistency guarantee for the corrected versions.
What carries the argument
Unbiased risk estimator derived from the modeled distribution of random label-subset query responses, along with non-negative and absolute-value corrected variants for stable ERM.
If this is right
- Direct training of multiclass classifiers becomes possible using only subset-membership feedback instead of full labels.
- Negative empirical risks are eliminated, reducing overfitting in the learning process.
- Generalization and excess risk bounds hold when the query mechanism matches the modeled distribution.
- The corrected estimators achieve consistency, converging to the true risk as the number of queries increases.
Where Pith is reading between the lines
- Applications in privacy-preserving settings could use subset queries to avoid disclosing exact class labels to annotators.
- The framework might be adapted to other weak supervision types by re-deriving the distribution model for different query types.
- Real-world validation would require checking how closely actual annotator responses match the assumed random subset distribution.
- Extensions could include active selection of which subsets to query for more efficient learning.
Load-bearing premise
The queries must be generated randomly according to exactly the distribution used to derive the unbiased risk estimator.
What would settle it
Collect a large dataset with both full labels and random subset queries generated according to the model; train with the proposed estimators and verify whether the excess risk over the true risk approaches zero as the training set size increases.
Figures




read the original abstract
Obtaining accurate class labels is often costly or unreliable, and may also be limited by privacy or other practical conditions. Compared with asking an annotator to provide the exact class, it is often easier to ask whether the true label belongs to a certain label subset. This query-response form defines a distinct weak-supervision mechanism: weak supervision information is generated through feedback on a label subset. Although weakly supervised learning has studied many learning frameworks, most existing work starts from established weak label objects. A systematic characterization is still lacking for weakly supervised learning generated directly by such query response observations. This paper proposes a multiclass learn ing framework under random label-subset queries. We model the data-generating distribution of query-response observations and derive an unbiased estimator of the target risk under the empirical risk minimization (ERM) framework. To address negative empirical risk and the associated overfitting problem, we introduce corrected risk estimators based on non-negative and absolute-value corrections. Theoretical analysis establishes a conditional generalization and excess-risk bound for the unbiased estimator, and a bias-and-consistency result for the corrected risk estimator. Experiments under the matched random-query mechanism demonstrate the feasibility of direct query-response learning and the stabilization effect of risk correction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
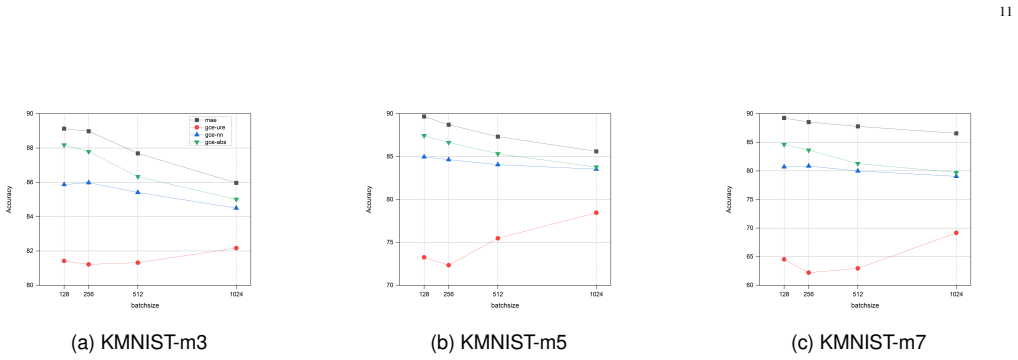
Summary. The paper proposes a multiclass learning framework based on random label-subset membership queries as a form of weak supervision. It models the data-generating process of query-response pairs, derives an unbiased estimator of the target multiclass risk under ERM, introduces non-negative and absolute-value corrections to mitigate negative empirical risks and overfitting, establishes a conditional generalization bound and excess-risk bound for the unbiased estimator along with a bias-and-consistency result for the corrected estimators, and reports experiments showing feasibility and stabilization under the matched query mechanism.
Significance. If the derivations hold under the stated assumptions, the work provides a direct modeling approach to risk estimation from subset queries, which could be useful for privacy-sensitive or cost-constrained labeling scenarios. The risk-correction techniques address a known practical pathology in weak-supervision ERM. The theoretical bounds and consistency results, if rigorously established, would constitute a solid contribution to the analysis of query-based weak supervision; the experiments confirm behavior under idealized conditions but do not yet demonstrate broader applicability.
major comments (3)
- [Modeling and derivation sections (likely §3–4)] The unbiasedness claim for the risk estimator (derived from the query-response distribution model) holds only when the random label-subset queries are generated exactly according to the modeled mechanism. Any deviation—non-uniform subset probabilities, feature-dependent selection, or annotator bias—renders the estimator biased and invalidates the subsequent conditional generalization bound, excess-risk bound, and consistency results for the corrections. The manuscript should explicitly state the precise distributional assumptions on subset generation (e.g., uniformity, independence from features) and discuss sensitivity.
- [Experiments section] All reported experiments are conducted exclusively under the matched random-query mechanism. This provides no empirical evidence on robustness to realistic mismatches between the assumed and actual query process, which directly undermines the practical claim that the framework enables 'direct query-response learning' in applied weak-supervision settings.
- [Theoretical analysis of corrected estimators] The bias-and-consistency result for the corrected risk estimators requires the corrections to be applied to an estimator whose bias vanishes with sample size; the manuscript should clarify whether the non-negativity and absolute-value corrections preserve consistency under the same conditions as the unbiased estimator or introduce additional bias terms that must be controlled.
minor comments (2)
- [Abstract] Abstract contains a typographical error: 'multiclass learn ing' should be 'multiclass learning'.
- [Preliminaries / Notation] Notation for the query-response distribution and the target risk should be introduced with explicit definitions and contrasted with standard supervised risk to improve readability.
Simulated Author's Rebuttal
Thank you for the thorough and constructive review of our manuscript. We appreciate the referee's identification of key areas for clarification and strengthening. Below we respond point by point to the major comments, indicating revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [Modeling and derivation sections (likely §3–4)] The unbiasedness claim for the risk estimator (derived from the query-response distribution model) holds only when the random label-subset queries are generated exactly according to the modeled mechanism. Any deviation—non-uniform subset probabilities, feature-dependent selection, or annotator bias—renders the estimator biased and invalidates the subsequent conditional generalization bound, excess-risk bound, and consistency results for the corrections. The manuscript should explicitly state the precise distributional assumptions on subset generation (e.g., uniformity, independence from features) and discuss sensitivity.
Authors: We agree that the unbiasedness holds specifically under the modeled query mechanism. Section 3 defines the data-generating process with random label-subset queries drawn from a fixed distribution independent of the input features (uniform over subsets of given cardinality). We will revise to state these assumptions explicitly and prominently at the start of the modeling section, and add a dedicated paragraph on sensitivity to deviations such as non-uniformity, feature dependence, or annotator bias, including remarks on how the bounds would be affected and possible extensions when the mechanism is known but mismatched. revision: yes
-
Referee: [Experiments section] All reported experiments are conducted exclusively under the matched random-query mechanism. This provides no empirical evidence on robustness to realistic mismatches between the assumed and actual query process, which directly undermines the practical claim that the framework enables 'direct query-response learning' in applied weak-supervision settings.
Authors: The experiments validate the framework and corrections under the exact matched mechanism assumed in the theory, which is the appropriate first step for confirming the derivations. We acknowledge the lack of robustness tests to mismatches limits claims about broader applicability. In revision we will add a discussion of this limitation in the experiments section together with new simulation results under controlled deviations (e.g., biased subset selection), thereby providing initial empirical evidence on sensitivity while preserving the paper's focus on the core matched case. revision: yes
-
Referee: [Theoretical analysis of corrected estimators] The bias-and-consistency result for the corrected risk estimators requires the corrections to be applied to an estimator whose bias vanishes with sample size; the manuscript should clarify whether the non-negativity and absolute-value corrections preserve consistency under the same conditions as the unbiased estimator or introduce additional bias terms that must be controlled.
Authors: The bias-and-consistency result is obtained by observing that both corrections are continuous functions that equal the unbiased estimator whenever the empirical risk is non-negative and sufficiently close to the true risk (which holds with high probability for large n by the unbiased estimator's consistency). Consequently the corrections introduce no persistent asymptotic bias. We will revise the relevant theorem statement and proof sketch in the theoretical analysis section to make this argument explicit and confirm that consistency is preserved under the same conditions as the unbiased estimator. revision: yes
Circularity Check
No significant circularity in derivation of unbiased risk estimator
full rationale
The paper models the data-generating distribution of random label-subset query responses as an explicit assumption and derives an unbiased estimator of the multiclass target risk via standard ERM techniques. This modeling step is not self-referential: the target risk is not defined in terms of the estimator, nor is the estimator fitted to a subset and then renamed as a prediction. Subsequent corrections for negative risk, generalization bounds, and consistency results follow from the modeled distribution without reducing to self-citations, imported uniqueness theorems, or ansatzes smuggled from prior work. Experiments are restricted to the matched mechanism, but this is a limitation on empirical validation rather than a circularity in the derivation chain itself. The overall argument is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Query responses are generated according to a known probabilistic model depending on the true label and the queried subset.
- standard math Empirical risk minimization applied to the estimated risk yields a useful classifier.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We model the data-generating distribution of query-response observations and derive an unbiased estimator of the target risk under the empirical risk minimization (ERM) framework. To address negative empirical risk ... we introduce corrected risk estimators based on non-negative and absolute-value corrections.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
R(f) = m E[¯ℓ(X, L; f) | s = 1] − (m − 1) E[¯ℓ(X, L; f) | s = 0]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A brief introduction to weakly supervised learning,
Z.-H. Zhou, “A brief introduction to weakly supervised learning,” National Science Review, vol. 5, no. 1, pp. 44–53, 2018
work page 2018
-
[2]
Learning classifiers from only positive and unlabeled data,
C. Elkan and K. Noto, “Learning classifiers from only positive and unlabeled data,” inProceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 213–220, 2008
work page 2008
-
[3]
Positive- unlabeled learning with non-negative risk estimator,
R. Kiryo, G. Niu, M. C. Du Plessis, and M. Sugiyama, “Positive- unlabeled learning with non-negative risk estimator,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[4]
Learning from comple- mentary labels,
T. Ishida, G. Niu, W. Hu, and M. Sugiyama, “Learning from comple- mentary labels,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[5]
Complementary- label learning for arbitrary losses and models,
T. Ishida, G. Niu, A. K. Menon, and M. Sugiyama, “Complementary- label learning for arbitrary losses and models,” inProceedings of the 36th International Conference on Machine Learning, vol. 97 of Proceedings of Machine Learning Research, pp. 2971–2980, 2019
work page 2019
-
[6]
Learning with multiple complementary labels,
L. Feng, T. Kaneko, B. Han, G. Niu, B. An, and M. Sugiyama, “Learning with multiple complementary labels,” inProceedings of the 37th Inter- national Conference on Machine Learning, vol. 119 ofProceedings of Machine Learning Research, pp. 3072–3081, 2020
work page 2020
-
[7]
Unbiased risk estimators can mislead: A case study of learning with complementary labels,
Y . Chou, G. Niu, H. Lin, and M. Sugiyama, “Unbiased risk estimators can mislead: A case study of learning with complementary labels,” in Proceedings of the 37th International Conference on Machine Learning, vol. 119 ofProceedings of Machine Learning Research, pp. 1929–1938, 2020
work page 1929
-
[8]
T. Cour, B. Sapp, and B. Taskar, “Learning from partial labels,”Journal of Machine Learning Research, vol. 12, pp. 1501–1536, 2011
work page 2011
-
[9]
Progressive identification of true labels for partial-label learning,
J. Lv, M. Xu, L. Feng, G. Niu, X. Geng, and M. Sugiyama, “Progressive identification of true labels for partial-label learning,” inProceedings of the 37th International Conference on Machine Learning, vol. 119 of Proceedings of Machine Learning Research, pp. 6500–6510, 2020
work page 2020
-
[10]
Provably consistent partial-label learning,
L. Feng, J. Lv, B. Han, M. Xu, G. Niu, X. Geng, B. An, and M. Sugiyama, “Provably consistent partial-label learning,” inAdvances in Neural Information Processing Systems, vol. 33, pp. 10948–10960, 2020
work page 2020
-
[11]
Estimating labels from label proportions,
N. Quadrianto, A. J. Smola, T. S. Caetano, and Q. V . Le, “Estimating labels from label proportions,”Journal of Machine Learning Research, vol. 10, pp. 2349–2374, 2009
work page 2009
-
[12]
Learning with label propor- tions via npsvm,
Z. Qi, B. Wang, F. Meng, and L. Niu, “Learning with label propor- tions via npsvm,”IEEE Transactions on Cybernetics, vol. 47, no. 10, pp. 3293–3305, 2017
work page 2017
-
[13]
Llp- gan: A gan-based algorithm for learning from label proportions,
J. Liu, B. Wang, H. Hang, H. Wang, Z. Qi, Y . Tian, and Y . Shi, “Llp- gan: A gan-based algorithm for learning from label proportions,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 11, pp. 8377–8388, 2023
work page 2023
-
[14]
Learning from aggregate observations,
Y . Zhang, N. Charoenphakdee, Z. Wu, and M. Sugiyama, “Learning from aggregate observations,”Advances in Neural Information Process- ing Systems, vol. 33, pp. 7993–8005, 2020
work page 2020
-
[15]
Multi-class classification without multi-class labels,
Y .-C. Hsu, Z. Lv, J. Schlosser, P. Odom, and Z. Kira, “Multi-class classification without multi-class labels,” inInternational Conference on Learning Representations, 2019
work page 2019
-
[16]
Learning from similarity-confidence data,
Y . Cao, L. Feng, Y . Xu, B. An, G. Niu, and M. Sugiyama, “Learning from similarity-confidence data,” inInternational conference on machine learning, pp. 1272–1282, PMLR, 2021
work page 2021
-
[17]
A general framework for learning from weak supervision,
H. Chen, J. Wang, L. Feng, X. Li, Y . Wang, X. Xie, M. Sugiyama, R. Singh, and B. Raj, “A general framework for learning from weak supervision,” inProceedings of the 41st International Conference on Machine Learning, pp. 7462–7485, 2024
work page 2024
-
[18]
Unified risk analysis for weakly su- pervised learning,
C.-K. Chiang and M. Sugiyama, “Unified risk analysis for weakly su- pervised learning,”Transactions on Machine Learning Research, 2025
work page 2025
-
[19]
Learning with biased complemen- tary labels,
X. Yu, T. Liu, M. Gong, and D. Tao, “Learning with biased complemen- tary labels,” inProceedings of the European Conference on Computer Vision (ECCV), pp. 68–83, 2018. 13
work page 2018
-
[20]
Learning from pairwise confidence comparisons and unlabeled data,
J. Li, S. Huang, C. Hua, and Y . Yang, “Learning from pairwise confidence comparisons and unlabeled data,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 9, no. 1, pp. 668– 680, 2025
work page 2025
-
[21]
Binary classification fromm-tuple similarity-confidence data,
J. Li, J. Qin, C. Hua, and Y . Yang, “Binary classification fromm-tuple similarity-confidence data,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 9, no. 2, pp. 1418–1427, 2025
work page 2025
-
[22]
Active learning literature survey,
B. Settles, “Active learning literature survey,” Technical Report 1648, University of Wisconsin–Madison Department of Computer Sciences,
-
[23]
Accessed: 2023-08-30
work page 2023
-
[24]
Active learning for semantic segmentation with multi-class label query,
S. Hwang, S. Lee, H. Kim, M. Oh, J. Ok, and S. Kwak, “Active learning for semantic segmentation with multi-class label query,”Advances in Neural Information Processing Systems, vol. 36, pp. 27020–27039, 2023
work page 2023
-
[25]
Activesleeplearner: Less annotation budget for better large-scale sleep staging,
Q. Liu, J. Wei, T. Penzel, M. De V os, Y . Zhang, Z. Huang, M. Poluektov, Y . Zhu, and C. Li, “Activesleeplearner: Less annotation budget for better large-scale sleep staging,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 9, no. 2, pp. 1756–1765, 2025
work page 2025
- [26]
-
[27]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
work page 1998
-
[28]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review arXiv 2017
-
[29]
Deep Learning for Classical Japanese Literature
T. Clanuwat, M. Bober-Irizar, A. Kitamoto, A. Lamb, K. Yamamoto, and D. Ha, “Deep learning for classical japanese literature,”arXiv preprint arXiv:1812.01718, 2018
work page Pith review arXiv 2018
-
[30]
A database for handwritten text recognition research,
J. J. Hull, “A database for handwritten text recognition research,”IEEE Transactions on pattern analysis and machine intelligence, vol. 16, no. 5, pp. 550–554, 1994
work page 1994
-
[31]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y . Ng,et al., “Reading digits in natural images with unsupervised feature learning,” inNIPS workshop on deep learning and unsupervised feature learning, vol. 2011, p. 4, Granada, 2011
work page 2011
-
[32]
Learning multiple layers of features from tiny im- ages,
A. Krizhevsky, “Learning multiple layers of features from tiny im- ages,” technical report, Department of Computer Science, University of Toronto, 2009
work page 2009
-
[33]
Emnist: Extending mnist to handwritten letters,
G. Cohen, S. Afshar, J. Tapson, and A. Van Schaik, “Emnist: Extending mnist to handwritten letters,” in2017 international joint conference on neural networks (IJCNN), pp. 2921–2926, IEEE, 2017
work page 2017
-
[34]
Realistic evaluation of deep partial-label learning algorithms,
W. Wang, D.-D. Wu, J. Wang, G. Niu, M.-L. Zhang, and M. Sugiyama, “Realistic evaluation of deep partial-label learning algorithms,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.