Recognition: no theorem link
Inference-Time Attribute Distribution Alignment for Unconditional Diffusion
Pith reviewed 2026-05-11 01:47 UTC · model grok-4.3
The pith
Pretrained unconditional diffusion models can align generated samples to arbitrary attribute distributions at inference time without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize inference-time attribute distributional alignment as an optimal control problem over the reverse diffusion process. We view the diffusion process as the rollout of a dynamical system and augment it with additive, time-dependent perturbations as control inputs. These perturbations are solved for using an optimal-control-based algorithm that optimizes a differentiable distribution-matching objective while penalizing control effort to preserve data fidelity. This yields a plug-and-play method that works on pretrained unconditional diffusion models without any retraining or finetuning.
What carries the argument
Casting the reverse diffusion process as a dynamical system and solving for additive time-dependent perturbations via an optimal-control algorithm to match a target attribute distribution.
Load-bearing premise
That penalizing the control effort is enough to keep generated samples high-quality and faithful to the original model even when the target attribute distribution differs strongly from the training data.
What would settle it
Run the method on a target attribute distribution far from the model's natural output, such as requiring 90 percent of generated faces to belong to one demographic group, then measure whether an attribute classifier recovers the exact target proportion while FID scores and visual artifacts remain comparable to the unperturbed baseline.
Figures

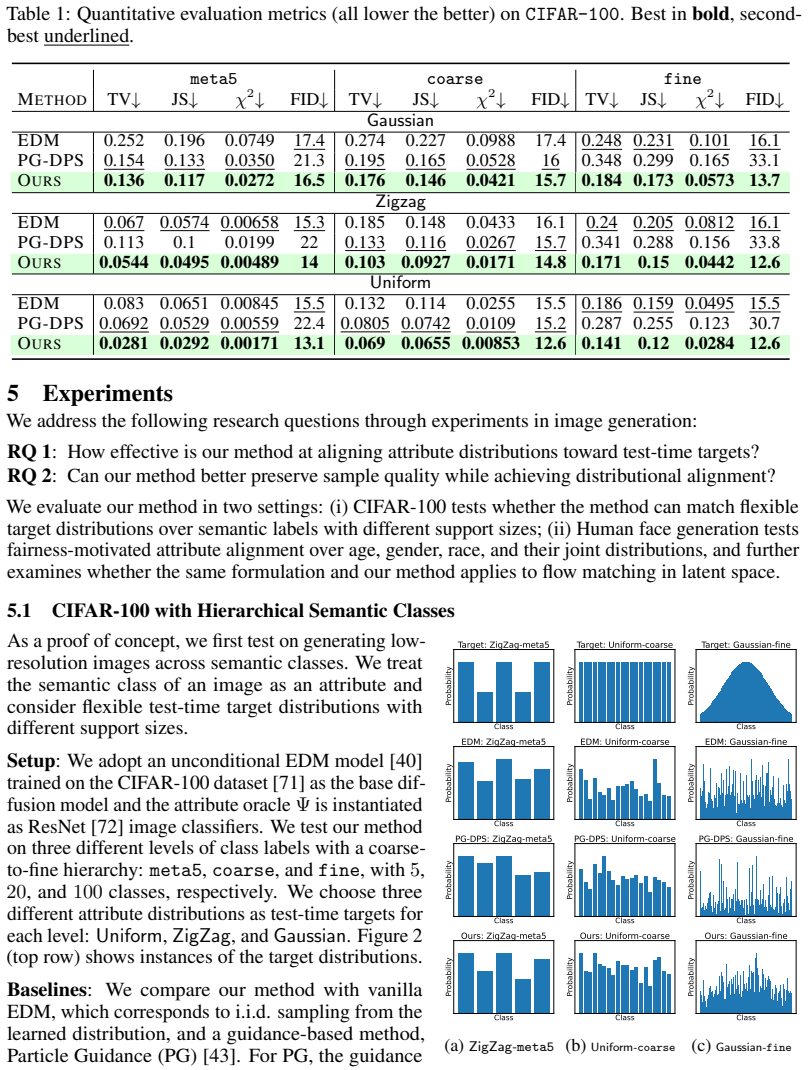


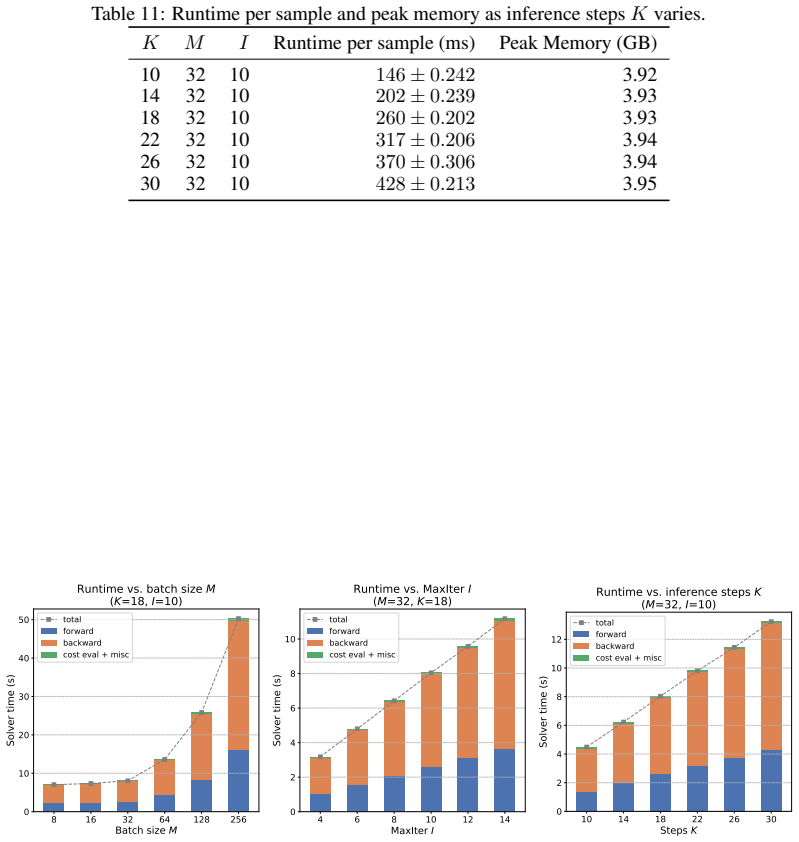
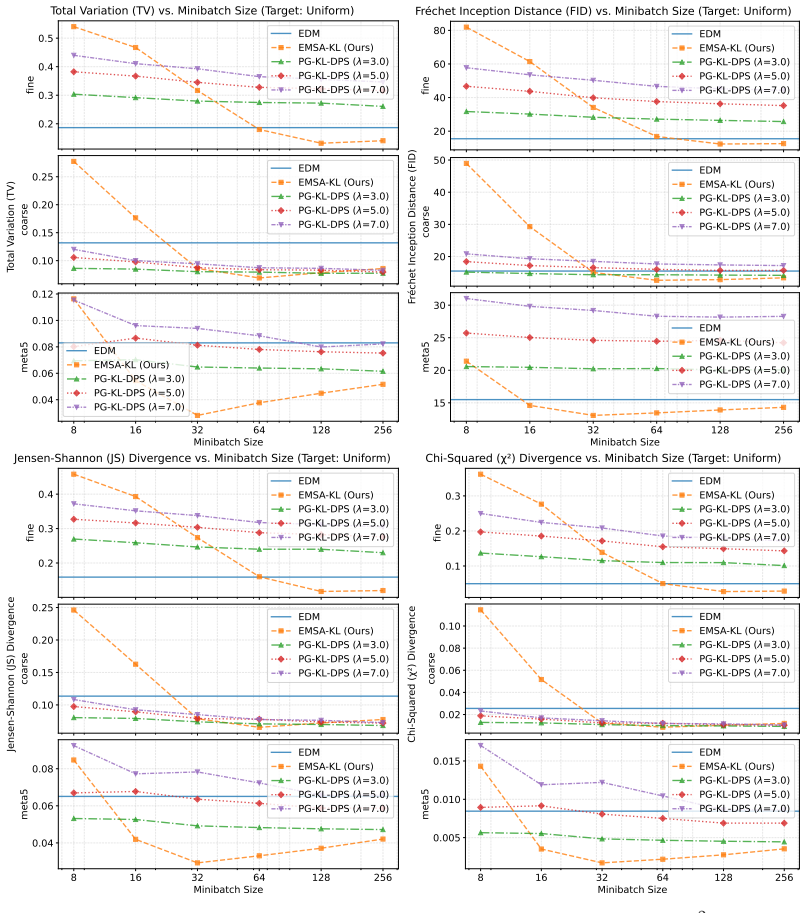



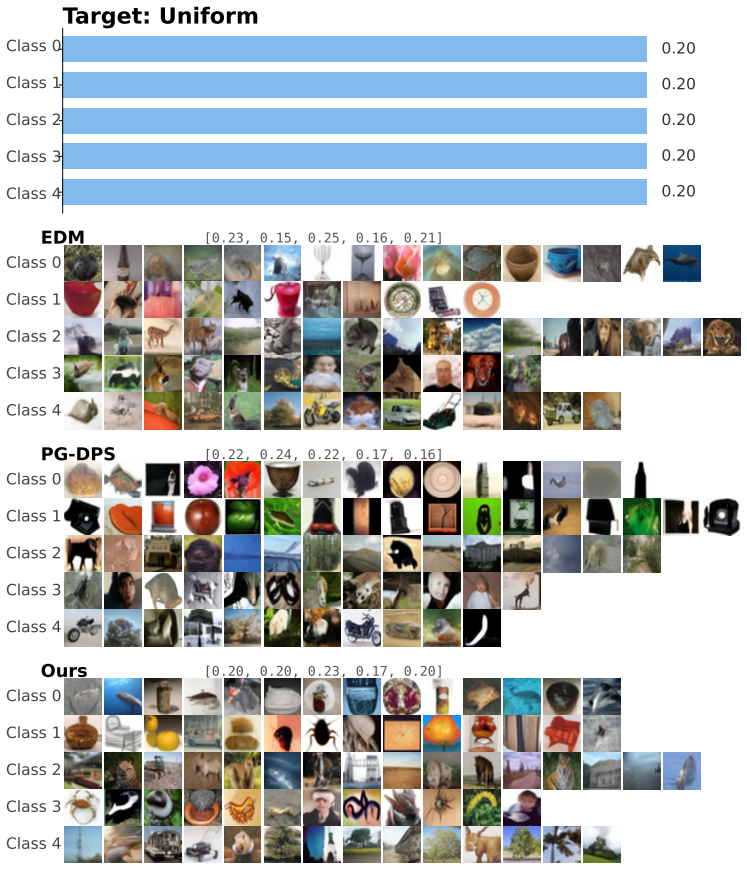




read the original abstract
Inference-time controllable generation is essential for real-world applications of unconditional diffusion models. However, most existing techniques focus on individual samples, struggling in applications that require the sample population to follow specific attribute distributions (e.g., demographic balance or semantic proportions). We formalize this setting as the inference-time attribute distributional alignment problem for pretrained unconditional diffusion models. To address this, we cast inference-time attribute distributional alignment as an optimal control problem over the reverse diffusion process, viewing the process as the rollout of a dynamical system and augmenting it with additive, time-dependent perturbations as control. We solve for the perturbations using an optimal-control-based algorithm to optimize a differentiable distribution-matching objective while penalizing control effort to preserve data fidelity. Experiment results in image generation demonstrate that our proposed plug-and-play approach can better align attribute distributions to diverse and flexible test-time targets compared to baselines, without retraining or finetuning the pretrained diffusion model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes inference-time attribute distributional alignment for pretrained unconditional diffusion models as an optimal control problem over the reverse diffusion process. It augments the process with additive time-dependent perturbations as controls, solves for them via an optimal-control algorithm that minimizes a differentiable distribution-matching objective while penalizing control effort to preserve fidelity, and claims this yields a plug-and-play method that better aligns sample populations to arbitrary test-time attribute targets than baselines without any retraining or fine-tuning.
Significance. If the central claim holds, the work would be significant for practical deployment of unconditional diffusion models in settings that require population-level attribute control (e.g., demographic balance or semantic proportions) rather than per-sample conditioning. The optimal-control framing is a clean and principled reduction of the problem, and the emphasis on inference-time, parameter-free (beyond the single penalty coefficient) operation is a genuine strength that distinguishes it from retraining-based alternatives.
major comments (2)
- [Experiments] Experiments section: the abstract states that results 'demonstrate' superior alignment to baselines, yet supplies no quantitative metrics (e.g., distribution distances, attribute accuracy rates), baseline implementations, ablation studies on the penalty coefficient, or analysis of failure cases. This leaves the central empirical claim only weakly supported and prevents assessment of whether the method actually outperforms existing approaches by a meaningful margin.
- [§3] §3 (optimal-control formulation): the claim that penalizing control effort (λ‖u‖) is sufficient to keep controlled trajectories inside the data manifold for arbitrary target distributions is load-bearing for the fidelity guarantee. No analysis, bounds, or empirical checks are provided showing that the resulting u_t remain small enough in high-dimensional image space to avoid mode collapse or artifacts once perturbations accumulate over diffusion steps; the method therefore implicitly relies on an unverified assumption about the interaction between the matching objective and the scalar penalty.
minor comments (2)
- Notation for the controlled reverse process and the distribution-matching loss could be made more explicit (e.g., by numbering the key equations for the dynamics and the objective) to aid reproducibility.
- The abstract and introduction would benefit from a concise statement of the precise mathematical form of the attribute distribution alignment problem (e.g., what distance or divergence is being matched) before moving to the control formulation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important areas for strengthening the empirical support and theoretical grounding of the optimal-control formulation. We will revise the manuscript to address both major points, as detailed below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract states that results 'demonstrate' superior alignment to baselines, yet supplies no quantitative metrics (e.g., distribution distances, attribute accuracy rates), baseline implementations, ablation studies on the penalty coefficient, or analysis of failure cases. This leaves the central empirical claim only weakly supported and prevents assessment of whether the method actually outperforms existing approaches by a meaningful margin.
Authors: We agree that the current experimental presentation is insufficiently quantitative. The revised manuscript will include explicit metrics such as Wasserstein or MMD distances between generated and target attribute distributions, per-attribute classification accuracies on held-out classifiers, full details on baseline re-implementations, systematic ablations over the penalty coefficient λ (including sensitivity plots), and a dedicated failure-case analysis. These additions will allow direct assessment of performance margins. revision: yes
-
Referee: [§3] §3 (optimal-control formulation): the claim that penalizing control effort (λ‖u‖) is sufficient to keep controlled trajectories inside the data manifold for arbitrary target distributions is load-bearing for the fidelity guarantee. No analysis, bounds, or empirical checks are provided showing that the resulting u_t remain small enough in high-dimensional image space to avoid mode collapse or artifacts once perturbations accumulate over diffusion steps; the method therefore implicitly relies on an unverified assumption about the interaction between the matching objective and the scalar penalty.
Authors: We acknowledge that the manuscript currently provides only the formulation and empirical results without dedicated analysis of control magnitudes. In the revision we will add (i) plots of ‖u_t‖ across diffusion timesteps for multiple target distributions, (ii) an ablation showing how increasing λ constrains trajectory deviation, and (iii) a brief argument bounding the accumulated perturbation under the combined objective. These additions will make the fidelity assumption explicit and verifiable while preserving the plug-and-play nature of the method. revision: yes
Circularity Check
No significant circularity in optimal control formulation
full rationale
The paper formulates attribute alignment as an optimal control problem on the pretrained diffusion reverse process, introducing additive perturbations solved via a standard algorithm that minimizes a differentiable matching loss plus control penalty. This construction draws on external optimal control theory and diffusion dynamics without reducing any prediction or result to a fitted parameter, self-definition, or self-citation chain. The derivation remains self-contained and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
free parameters (1)
- control effort penalty coefficient
axioms (2)
- domain assumption The reverse diffusion process can be viewed as the rollout of a dynamical system.
- domain assumption The distribution-matching objective is differentiable with respect to the control perturbations.
Reference graph
Works this paper leans on
-
[1]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[2]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, June 2022
work page 2022
-
[3]
Video diffusion models.Advances in neural information processing systems, 35: 8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35: 8633–8646, 2022
work page 2022
-
[4]
Lumiere: A space-time diffusion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, Yuanzhen Li, Michael Rubinstein, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, and Inbar Mosseri. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia, pages 94:1–94:11, 2024. URL https://doi.org/1...
-
[5]
Akio Hayakawa, Masato Ishii, Takashi Shibuya, and Yuki Mitsufuji. MMDisco: Multi- modal discriminator-guided cooperative diffusion for joint audio and video generation. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=agbiPPuSeQ
work page 2025
-
[6]
Permutation invariant graph generation via score-based generative modeling
Chenhao Niu, Yang Song, Jiaming Song, Shengjia Zhao, Aditya Grover, and Stefano Ermon. Permutation invariant graph generation via score-based generative modeling. InProceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 4474–4484. PMLR, 26–28 Aug 2020...
work page 2020
-
[7]
Generative modelling of structurally constrained graphs
Manuel Madeira, Cl´ement Vignac, Dorina Thanou, and Pascal Frossard. Generative modelling of structurally constrained graphs. InAdvances in Neural Information Processing Systems, volume 37, pages 137218–137262, 2024
work page 2024
-
[8]
DDPS: Discrete diffusion posterior sampling for paths in layered graphs
Hao Luan, See-Kiong Ng, and Chun Kai Ling. DDPS: Discrete diffusion posterior sampling for paths in layered graphs. InICLR 2025 Frontiers in Probabilistic Inference: Learning Meets Sampling Workshop, 2025. URLhttps://openreview.net/forum?id=DBdkU0Ikzy
work page 2025
-
[9]
Michael Janner, Yilun Du, Joshua B. Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InInternational Conference on Machine Learning, 2022
work page 2022
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, page 02783649241273668, 2023. 10
work page 2023
-
[11]
Zeyu Feng, Hao Luan, Kevin Yuchen Ma, and Harold Soh. Diffusion meets options: Hi- erarchical generative skill composition for temporally-extended tasks. In2025 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 10854–10860, 2025. doi: 10.1109/ICRA55743.2025.11127641
-
[12]
Jo˜ao Carvalho, An Thai Le, Piotr Kicki, Dorothea Koert, and Jan Peters. Motion planning diffu- sion: Learning and adapting robot motion planning with diffusion models.IEEE Transactions on Robotics, 41:4881–4901, 2025. doi: 10.1109/TRO.2025.3593109
-
[13]
Diffusion models beat GANs on image syn- thesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image syn- thesis. InAdvances in Neural Information Processing Systems, volume 34, pages 8780– 8794, 2021. URL https://proceedings.neurips.cc/paper_files/paper/2021/ file/49ad23d1ec9fa4bd8d77d02681df5cfa-Paper.pdf
work page 2021
-
[14]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael Thompson Mccann, Marc Louis Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InThe Eleventh Inter- national Conference on Learning Representations, 2023. URL https://openreview.net/ forum?id=OnD9zGAGT0k
work page 2023
-
[15]
TFG: Unified training-free guidance for diffusion models
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Zou, and Stefano Ermon. TFG: Unified training-free guidance for diffusion models. InAdvances in Neural Information Processing Systems, volume 37, pages 22370–22417, 2024
work page 2024
-
[16]
Zeyu Feng, Hao Luan, Pranav Goyal, and Harold Soh. LTLDoG: Satisfying temporally-extended symbolic constraints for safe diffusion-based planning.IEEE Robotics and Automation Letters, 9(10):8571–8578, 2024. doi: 10.1109/LRA.2024.3443501
-
[17]
Nic Fishman, Leo Klarner, Emile Mathieu, Michael Hutchinson, and Valentin De Bortoli. Metropolis sampling for constrained diffusion models.Advances in Neural Information Pro- cessing Systems, 36:62296–62331, 2023
work page 2023
-
[18]
Training-free constrained generation with stable diffusion models
Stefano Zampini, Jacob K Christopher, Luca Oneto, Davide Anguita, and Ferdinando Fioretto. Training-free constrained generation with stable diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview. net/forum?id=TrNB08KuHK
work page 2025
-
[19]
Simultane- ous multi-robot motion planning with projected diffusion models
Jinhao Liang, Jacob K Christopher, Sven Koenig, and Ferdinando Fioretto. Simultane- ous multi-robot motion planning with projected diffusion models. InForty-second Inter- national Conference on Machine Learning, 2025. URLhttps://openreview.net/forum? id=Sp7jclUwkV
work page 2025
-
[20]
Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation
Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, and Baining Guo. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10219–10228, 2023
work page 2023
-
[21]
Jedi: Joint-image diffusion models for finetuning-free personalized text-to-image generation
Yu Zeng, Vishal M Patel, Haochen Wang, Xun Huang, Ting-Chun Wang, Ming-Yu Liu, and Yogesh Balaji. Jedi: Joint-image diffusion models for finetuning-free personalized text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6786–6795, 2024
work page 2024
-
[22]
Projected coupled diffusion for test-time constrained joint generation
Hao Luan, Yi Xian Goh, See-Kiong Ng, and Chun Kai Ling. Projected coupled diffusion for test-time constrained joint generation. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=1FEm5JLpvg
work page 2026
-
[23]
CHD: Coupled hierarchical diffusion for long-horizon tasks
Ce Hao, Anxing Xiao, Zhiwei Xue, and Harold Soh. CHD: Coupled hierarchical diffusion for long-horizon tasks. In9th Annual Conference on Robot Learning, 2025. URL https: //openreview.net/forum?id=tXY6VQlXfA
work page 2025
-
[24]
Fair generative modeling via weak supervision
Kristy Choi, Aditya Grover, Trisha Singh, Rui Shu, and Stefano Ermon. Fair generative modeling via weak supervision. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1887–1898. PMLR, 13–18 Jul 2020. URLhttps://proceedings.mlr.press/v119/choi20a.html. 11
work page 2020
-
[25]
Rishubh Parihar, Abhijnya Bhat, Abhipsa Basu, Saswat Mallick, Jogendra Nath Kundu, and R. Venkatesh Babu. Balancing act: Distribution-guided debiasing in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6668–6678, June 2024
work page 2024
-
[26]
CausalGraph2LLM: Evaluating LLMs for causal queries
Mintong Kang, Vinayshekhar Bannihatti Kumar, Shamik Roy, Abhishek Kumar, Sopan Khosla, Balakrishnan Murali Narayanaswamy, and Rashmi Gangadharaiah. FairGen: Controlling sensitive attributes for fair generations in diffusion models via adaptive latent guidance. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages...
-
[27]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
work page 2024
-
[28]
arXiv preprint arXiv:2409.07253 , year=
Buhua Liu, Shitong Shao, Bao Li, Lichen Bai, Zhiqiang Xu, Haoyi Xiong, James Kwok, Sumi Helal, and Zeke Xie. Alignment of diffusion models: Fundamentals, challenges, and future. arXiv preprint arXiv:2409.07253, 2024
-
[29]
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Yusuke Kato, and Kazuki Kozuka. Align- ing diffusion models by optimizing human utility.Advances in Neural Information Processing Systems, 37:24897–24925, 2024
work page 2024
-
[30]
Masatoshi Uehara, Yulai Zhao, Chenyu Wang, Xiner Li, Aviv Regev, Sergey Levine, and Tom- maso Biancalani. Inference-time alignment in diffusion models with reward-guided generation: Tutorial and review.arXiv preprint arXiv:2501.09685, 2025
-
[31]
Debiasing text-to-image diffusion models
Ruifei He, Chuhui Xue, Haoru Tan, Wenqing Zhang, Yingchen Yu, Song Bai, and Xiaojuan Qi. Debiasing text-to-image diffusion models. InProceedings of the 1st ACM Multimedia Workshop on Multi-Modal Misinformation Governance in the Era of Foundation Models, MIS ’24, page 29–36, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400712012....
-
[32]
Fair sampling in diffusion models through switching mechanism
Yujin Choi, Jinseong Park, Hoki Kim, Jaewook Lee, and Saerom Park. Fair sampling in diffusion models through switching mechanism. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 21995–22003, 2024
work page 2024
-
[33]
Felix Friedrich, Manuel Brack, Lukas Struppek, Dominik Hintersdorf, Patrick Schramowski, Sasha Luccioni, and Kristian Kersting. Auditing and instructing text-to-image generation models on fairness.AI and Ethics, 5(3):2103–2123, Jun 2025. ISSN 2730-5961. doi: 10.1007/ s43681-024-00531-5
work page 2025
-
[34]
Fairgen: Enhancing fairness in text-to-image diffusion models via self-discovering latent directions
Yilei Jiang, Wei-Hong Li, Yiyuan Zhang, Minghong Cai, and Xiangyu Yue. Fairgen: Enhancing fairness in text-to-image diffusion models via self-discovering latent directions. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 18411–18420, October 2025
work page 2025
-
[35]
Jia Li, Lijie Hu, Jingfeng Zhang, Tianhang Zheng, Hua Zhang, and Di Wang. Fair text-to-image diffusion via fair mapping.Proceedings of the AAAI Conference on Artificial Intelligence, 39 (25):26256–26264, 2025. doi: 10.1609/aaai.v39i25.34823. URL https://ojs.aaai.org/ index.php/AAAI/article/view/34823
-
[36]
Mashrur M. Morshed and Vishnu Boddeti. Diverseflow: Sample-efficient diverse mode coverage in flows. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23303–23312, June 2025
work page 2025
-
[37]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. InAdvances in Neural Information Processing Systems, pages 11895–11907, 2019. 12
work page 2019
-
[38]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=PxTIG12RRHS
work page 2021
-
[39]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=St1giarCHLP
work page 2021
-
[40]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=k7FuTOWMOc7
work page 2022
-
[41]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. URLhttps://arxiv.org/abs/2207.12598
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
Yingqing Guo, Hui Yuan, Yukang Yang, Minshuo Chen, and Mengdi Wang. Gradient guidance for diffusion models: An optimization perspective.Advances in Neural Information Processing Systems, 37:90736–90770, 2024
work page 2024
-
[43]
Gabriele Corso, Yilun Xu, Valentin De Bortoli, Regina Barzilay, and Tommi S. Jaakkola. Particle guidance: non-i.i.d. diverse sampling with diffusion models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=KqbCvIFBY7
work page 2024
-
[44]
Fine- tuning text-to-image diffusion models for fairness
Xudong Shen, Chao Du, Tianyu Pang, Min Lin, Yongkang Wong, and Mohan Kankanhalli. Fine- tuning text-to-image diffusion models for fairness. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=hnrB5YHoYu
work page 2024
-
[45]
Training diffusion models towards diverse image generation with reinforcement learning
Zichen Miao, Jiang Wang, Ze Wang, Zhengyuan Yang, Lijuan Wang, Qiang Qiu, and Zicheng Liu. Training diffusion models towards diverse image generation with reinforcement learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10844–10853, 2024
work page 2024
-
[46]
Julius Berner, Lorenz Richter, and Karen Ullrich. An optimal control perspective on diffusion- based generative modeling.Transactions on Machine Learning Research, 2024. ISSN 2835-
work page 2024
-
[47]
URLhttps://openreview.net/forum?id=oYIjw37pTP
-
[48]
Carles Domingo-Enrich, Jiequn Han, Brandon Amos, Joan Bruna, and Ricky T. Q. Chen. Stochastic optimal control matching. InAdvances in Neural Information Processing Systems, volume 37, pages 112459–112504, 2024. doi: 10.52202/079017-3573
-
[49]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=xQBRrtQM8u
work page 2025
-
[50]
Stochastic control for fine-tuning diffusion models: Optimality, regularity, and convergence
Yinbin Han, Meisam Razaviyayn, and Renyuan Xu. Stochastic control for fine-tuning diffusion models: Optimality, regularity, and convergence. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=DnNV3Ea09e
work page 2025
-
[51]
Xiao, Carles Domingo-Enrich, Weiyang Liu, and Dinghuai Zhang
Zhen Liu, Tim Z. Xiao, Carles Domingo-Enrich, Weiyang Liu, and Dinghuai Zhang. Value gradient guidance for flow matching alignment. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= 6MmOy2Ji8V
work page 2025
-
[52]
Stochastic optimal control for diffusion bridges in function spaces
Byoungwoo Park, Jungwon Choi, Sungbin Lim, and Juho Lee. Stochastic optimal control for diffusion bridges in function spaces. InThe Thirty-eighth Annual Conference on Neural Informa- tion Processing Systems, 2024. URLhttps://openreview.net/forum?id=WyQW4G57Zd. 13
work page 2024
-
[53]
UniDB: A unified diffusion bridge framework via stochastic optimal control
Kaizhen Zhu, Mokai Pan, Yuexin Ma, Yanwei Fu, Jingyi Yu, Jingya Wang, and Ye Shi. UniDB: A unified diffusion bridge framework via stochastic optimal control. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=uqCfoVXb67
work page 2025
-
[54]
Training free guided flow-matching with optimal control
Luran Wang, Chaoran Cheng, Yizhen Liao, Yanru Qu, and Ge Liu. Training free guided flow-matching with optimal control. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=61ss5RA1MM
work page 2025
-
[55]
Variational control for guidance in diffusion models
Kushagra Pandey, Farrin Marouf Sofian, Felix Draxler, Theofanis Karaletsos, and Stephan Mandt. Variational control for guidance in diffusion models. InProceedings of the 41st International Conference on Machine Learning (ICML), 2025
work page 2025
-
[56]
Solving inverse problems via diffusion optimal control
Henry Li and Marcus Aloysius Pereira. Solving inverse problems via diffusion optimal control. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=wqLC4G1GN3
work page 2024
-
[57]
Adaptive diffusion guidance via stochastic optimal control.arXiv preprint arXiv:2410.21245, 2024
Iskander Azangulov, Peter Potaptchik, Qinyu Li, Eddie Aamari, George Deligiannidis, and Judith Rousseau. Adaptive diffusion guidance via stochastic optimal control.arXiv preprint arXiv:2410.21245, 2024
-
[58]
RB-modulation: Training-free stylization using reference-based modulation
Litu Rout, Yujia Chen, Nataniel Ruiz, Abhishek Kumar, Constantine Caramanis, Sanjay Shakkot- tai, and Wen-Sheng Chu. RB-modulation: Training-free stylization using reference-based modulation. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=bnINPG5A32
work page 2025
-
[59]
Eric Tillmann Bill, Enis Simsar, and Thomas Hofmann. Optimal control meets flow matching: A principled route to multi-subject fidelity.arXiv preprint arXiv:2510.02315, 2025
-
[60]
Brian DO Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326, 1982
work page 1982
-
[61]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=PqvMRDCJT9t
work page 2023
-
[62]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=XVjTT1nw5z
work page 2023
-
[63]
Calvin Luo. Understanding diffusion models: A unified perspective.arXiv preprint arXiv:2208.11970, 2022
-
[64]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=9_gsMA8MRKQ
work page 2023
-
[65]
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
work page 2011
-
[66]
Noise2score: Tweedie’s approach to self-supervised image denoising without clean images
Kwanyoung Kim and Jong Chul Ye. Noise2score: Tweedie’s approach to self-supervised image denoising without clean images. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 864–874, 2021. URL https://proceedings.neurips.cc/paper_files/paper/ 2021/file/0...
work page 2021
-
[67]
Solving inverse problems in medi- cal imaging with score-based generative models
Yang Song, Liyue Shen, Lei Xing, and Stefano Ermon. Solving inverse problems in medi- cal imaging with score-based generative models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=vaRCHVj0uGI
work page 2022
-
[68]
Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song. Denoising diffusion restoration models.Advances in neural information processing systems, 35:23593–23606, 2022. 14
work page 2022
-
[69]
Springer Science & Business Media, 2012
Wendell H Fleming and Raymond W Rishel.Deterministic and stochastic optimal control, volume 1. Springer Science & Business Media, 2012
work page 2012
-
[70]
W. Levine. Optimal control theory: An introduction.IEEE Transactions on Automatic Control, 17(3):423–423, 1972. doi: 10.1109/TAC.1972.1100008
-
[71]
Qianxiao Li, Long Chen, Cheng Tai, and Weinan E. Maximum principle based algorithms for deep learning.Journal of Machine Learning Research, 18(165):1–29, 2018. URL http: //jmlr.org/papers/v18/17-653.html
work page 2018
-
[72]
Learning multiple layers of features from tiny images.Technical Report, 2009
Alex Krizhevsky et al. Learning multiple layers of features from tiny images.Technical Report, 2009
work page 2009
-
[73]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[74]
Statistical distances and their role in robustness
Marianthi Markatou, Yang Chen, Georgios Afendras, and Bruce G Lindsay. Statistical distances and their role in robustness. InNew advances in statistics and data science, pages 3–26. Springer, 2018
work page 2018
-
[75]
Perception prioritized training of diffusion models
Jooyoung Choi, Jungbeom Lee, Chaehun Shin, Sungwon Kim, Hyunwoo Kim, and Sungroh Yoon. Perception prioritized training of diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11472–11481, 2022
work page 2022
-
[76]
Flow matching in latent space.arXiv preprint arXiv:2307.08698,
Quan Dao, Hao Phung, Binh Nguyen, and Anh Tran. Flow matching in latent space.arXiv preprint arXiv:2307.08698, 2023
-
[77]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
work page 2019
-
[78]
Kimmo Karkkainen and Jungseock Joo. FairFace: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1548–1558, 2021
work page 2021
-
[79]
Amir Beck.Introduction to Nonlinear Optimization. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2014. doi: 10.1137/1.9781611973655. URL https://epubs. siam.org/doi/abs/10.1137/1.9781611973655
-
[80]
Cambridge University Press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex Optimization. Cambridge University Press, 2004
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.