Recognition: 2 theorem links
· Lean TheoremOn the Complexity of Discounted Robust MDPs with L_p Uncertainty Sets
Pith reviewed 2026-05-11 02:03 UTC · model grok-4.3
The pith
Policy iteration for robust MDPs with any compact uncertainty set runs in strongly polynomial time given an oracle for robust Markov chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For any compact uncertainty set, the policy iteration algorithm for RMDPs is strongly polynomial with oracle access to solutions of Robust Markov chains (RMCs). Strongly polynomial-time bounds are presented on the policy iteration algorithm for RMCs with L1 and L∞ uncertainty sets. Hardness results are established for RMCs with Lp uncertainty sets for integer p satisfying 1 < p < ∞.
What carries the argument
Policy iteration on robust MDPs, whose improvement steps reduce to solving robust Markov chains under the chosen Lp uncertainty set.
If this is right
- For L1 and L∞ uncertainty sets, the number of policy iterations on robust Markov chains is bounded by a polynomial in the number of states.
- Robust Markov chain problems with Lp uncertainty for 1 < p < ∞ are hard, preventing strongly polynomial solutions via the same route.
- The overall RMDP algorithm inherits strong polynomiality directly from the quality of the RMC oracle.
- Experimental runs confirm that policy iteration converges rapidly in practice precisely when the theoretical bounds apply.
Where Pith is reading between the lines
- If efficient oracles for intermediate Lp sets can be constructed, the general oracle result would immediately yield tractable algorithms for those models as well.
- The separation between L1/L∞ and other p values supplies a concrete criterion for choosing uncertainty sets in applications where runtime guarantees are required.
Load-bearing premise
Uncertainty sets are compact, the discount factor is a fixed constant, and an exact oracle exists for solving the robust Markov chain subproblems.
What would settle it
An explicit family of compact uncertainty sets together with an RMDP instance on which policy iteration requires a number of iterations exponential in the number of states and actions would disprove the strong polynomiality claim.
Figures

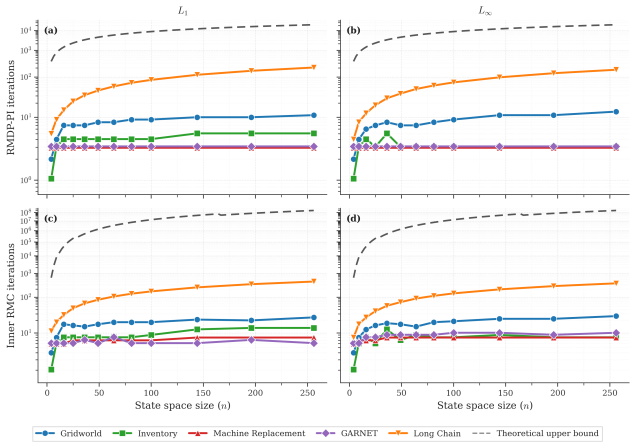
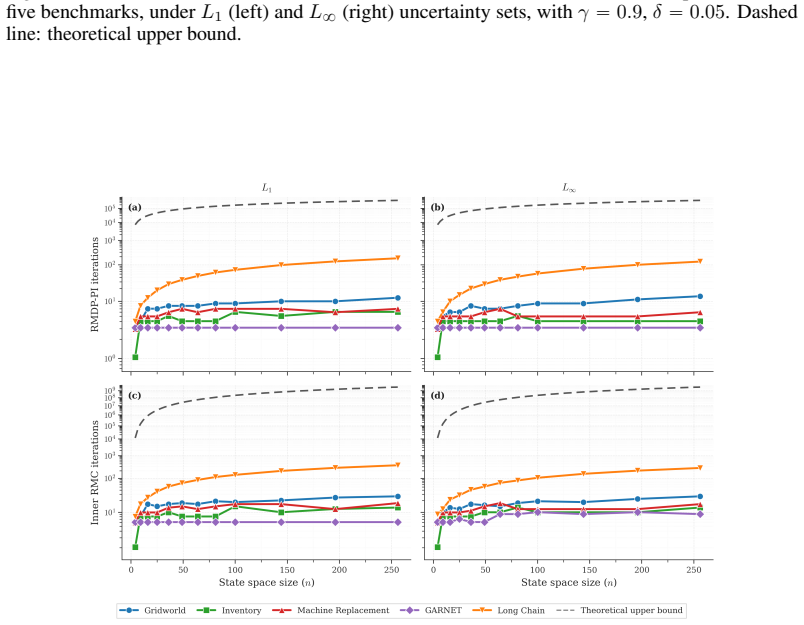

read the original abstract
A basic model in sequential decision making is the Markov decision process (MDP), which is extended to Robust MDPs (RMDPs) by allowing uncertainty in transition probabilities and optimizing against the worst-case transition probabilities from the uncertainty sets. The class of $(s, a)$-rectangular RMDPs with $L_p$ uncertainty sets provides a flexible and expressive model for such problems. We study this class of RMDPs with a discounted-sum cost criterion and a constant discount factor. The existence of an efficient algorithm for this class is a fundamental theoretical question in optimization and sequential decision making. Previous results only establish a strongly polynomial-time algorithm for $L_\infty$ uncertainty sets. In this work, our main results are as follows: (a)~we show that for any compact uncertainty set, the policy iteration algorithm for RMDPs is strongly polynomial with oracle access to solutions of Robust Markov chains (RMCs); (b)~we present strongly polynomial-time bounds on the policy iteration algorithm for RMCs with $L_1$ and $L_\infty$ uncertainty sets; and (c)~we establish hardness results for RMCs with $L_p$ uncertainty sets for integer $p$ satisfying $1<p<\infty$. Finally, motivated by our theoretical bounds, we present experimental results showing how fast policy iteration converges for RMDPs with $L_1$ and $L_\infty$ uncertainty sets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the complexity of policy iteration for discounted (s,a)-rectangular robust MDPs with Lp uncertainty sets under a constant discount factor. It claims that for any compact uncertainty set, policy iteration on RMDPs is strongly polynomial given an oracle for solving robust Markov chains (RMCs); it gives explicit strongly polynomial iteration bounds for the RMC subproblem under L1 and L∞ uncertainty sets; and it proves hardness for RMC instances with Lp uncertainty sets when 1 < p < ∞ is integer. The work also includes motivating experiments on convergence speed for the L1 and L∞ cases.
Significance. If the proofs are correct, the results provide a clean modular separation between the combinatorial policy-improvement structure and the inner robust evaluation, extending the known strongly polynomial result for L∞ to L1 while establishing that intermediate Lp norms are hard. The oracle-based argument for general compact sets and the explicit bounds for the tractable cases are technically useful for robust optimization and sequential decision making. The hardness results clarify why L1/L∞ are special. Experimental validation, while secondary, supports the practical relevance of the polynomial bounds.
minor comments (3)
- The statement of strong polynomiality in part (a) should explicitly note the dependence on the number of states, actions, and the fixed discount factor; the current wording in the abstract leaves open whether the iteration bound is independent of the uncertainty-set description size.
- Section 5 (experiments): the convergence plots would be clearer if the y-axis were shown on a logarithmic scale and if the number of random instances per parameter setting were reported.
- The hardness reduction for 1 < p < ∞ (Theorem 4.3 or equivalent) should include a short remark on whether the constructed RMC instances remain (s,a)-rectangular when lifted back to the RMDP setting.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on the complexity of policy iteration for discounted robust MDPs with Lp uncertainty sets, for recognizing the modular separation between policy improvement and robust evaluation, and for recommending minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper establishes complexity-theoretic results on policy iteration for robust MDPs and robust Markov chains under compact uncertainty sets. Part (a) reduces the RMDP problem to polynomially many calls to an RMC oracle via standard contraction arguments that hold for any compact set and constant discount factor; parts (b) and (c) then supply explicit polynomial bounds for L1/L∞ oracles and hardness proofs for intermediate Lp cases. These steps rely on independent algorithmic analysis, oracle separation, and standard hardness reductions rather than any self-definition, fitted-parameter renaming, or load-bearing self-citation. The derivation chain is self-contained against external complexity benchmarks and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncertainty sets are compact and the discount factor is constant.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present strongly polynomial-time bounds on the policy iteration algorithm for RMCs with L1 and L∞ uncertainty sets; ... hardness results for RMCs with Lp uncertainty sets for integer p satisfying 1<p<∞.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the cumulative transition-probability potential ... halving of the cumulative gap ... combinatorial bound on the number of halvings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Principles of model checking , publisher =
Christel Baier and Joost. Principles of model checking , publisher =
-
[2]
Mathematics of Operations Research , volume=
Robust dynamic programming , author=. Mathematics of Operations Research , volume=. 2005 , publisher=
work page 2005
-
[3]
Robust control of Markov decision processes with uncertain transition matrices , author=. Operations Research , volume=. 2005 , publisher=
work page 2005
-
[4]
Journal of Machine Learning Research , volume=
Partial policy iteration for l1-robust markov decision processes , author=. Journal of Machine Learning Research , volume=
-
[5]
SIAM Journal on Computing , volume=
On the complexity of numerical analysis , author=. SIAM Journal on Computing , volume=. 2009 , publisher=
work page 2009
-
[6]
In: Pro- ceedings of the Twentieth Annual ACM Symposium on Theory of Computing STOC
Canny, John , title =. 1988 , publisher =. doi:10.1145/62212.62257 , booktitle =
- [7]
-
[8]
arXiv preprint arXiv:2601.23229 , year=
Strongly polynomial time complexity of policy iteration for L_ robust MDPs , author=. arXiv preprint arXiv:2601.23229 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Fast Algorithms for L_ -constrained S-rectangular Robust MDPs , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
International Colloquium on Automata, Languages, and Programming , pages=
Exponential lower bounds for policy iteration , author=. International Colloquium on Automata, Languages, and Programming , pages=. 2010 , organization=
work page 2010
-
[11]
Mathematics of Operations Research , volume=
The simplex and policy-iteration methods are strongly polynomial for the Markov decision problem with a fixed discount rate , author=. Mathematics of Operations Research , volume=. 2011 , publisher=
work page 2011
-
[12]
Reinforcement learning: an introduction , author=. 2018 , publisher=
work page 2018
- [13]
-
[14]
Mathematics of Operations Research , volume=
Robust Markov decision processes , author=. Mathematics of Operations Research , volume=. 2013 , publisher=
work page 2013
-
[15]
Journal of the Operational Research Society , volume=
On the generation of markov decision processes , author=. Journal of the Operational Research Society , volume=. 1995 , publisher=
work page 1995
- [16]
- [17]
-
[18]
Inequalities for the l1 deviation of the empirical distribution , author=. Hewlett-Packard Labs, Tech. Rep , pages=
-
[19]
Bahram Behzadian and Reazul Hasan Russel and Marek Petrik and Chin Pang Ho , title =
-
[20]
Robert Givan and Sonia M. Leach and Thomas L. Dean , title =. Artif. Intell. , volume =
-
[21]
Cyrus Derman , title =
-
[22]
A probabilistic production and inventory problem , author=. Management Science , volume=. 1963 , publisher=
work page 1963
-
[23]
Journal of the ACM (JACM) , volume=
Strategy iteration is strongly polynomial for 2-player turn-based stochastic games with a constant discount factor , author=. Journal of the ACM (JACM) , volume=. 2013 , publisher=
work page 2013
- [24]
-
[25]
M. R. Garey and Ronald L. Graham and David S. Johnson , title =
-
[26]
Real analysis: modern techniques and their applications , author=. 1999 , publisher=
work page 1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.