Recognition: no theorem link
NPMixer: Hierarchical Neighboring Patch Mixing for Time Series Forecasting
Pith reviewed 2026-05-11 01:55 UTC · model grok-4.3
The pith
NPMixer decomposes time series with a learnable wavelet and mixes neighboring patches hierarchically to improve multivariate forecasting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
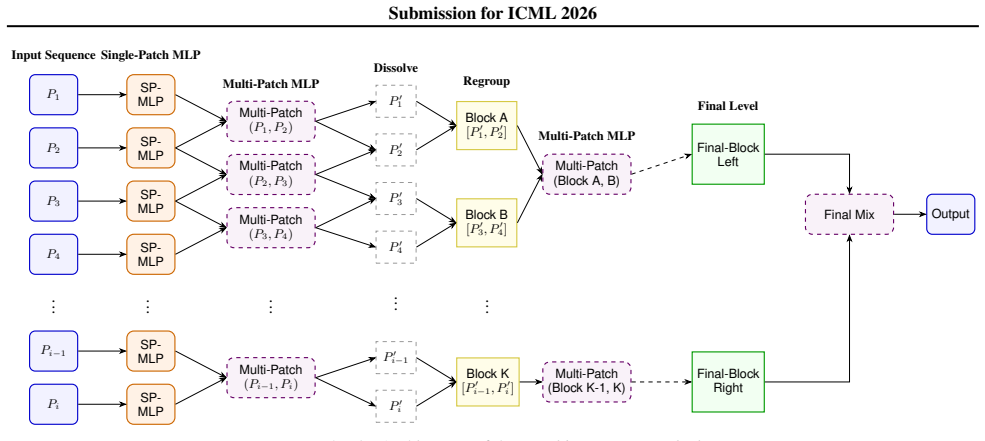
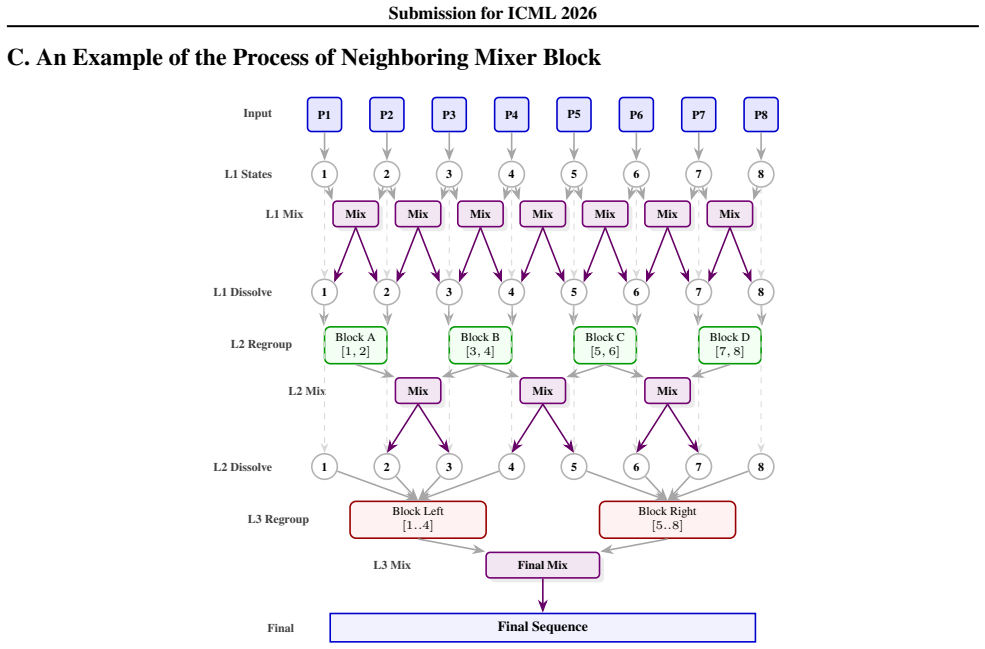
NPMixer is a hierarchical architecture featuring a Learnable Stationary Wavelet Transform that adaptively learns filter coefficients to decompose multivariate signals into trend and detail components in a data-dependent manner. The Neighboring Mixer Block then applies series of MLP layers to non-overlapping patches to capture local temporal dynamics and expand the receptive field across scales by learning patterns within and across patches. A Channel-Mixing Encoder processes the high-frequency components to capture channel correlations while preserving the stability of the underlying global trend.
What carries the argument
The Neighboring Mixer Block, a stack of hierarchical MLPs operating on non-overlapping patches after a learnable wavelet decomposition, which expands the receptive field to model multi-scale temporal dependencies and channel correlations.
If this is right
- Forecasting accuracy improves when receptive fields are expanded through successive neighboring patch mixing rather than fixed-scale convolutions or global attention.
- Separating trend and detail components allows channel correlations to be modeled selectively on high-frequency parts without disturbing long-term stability.
- MLP-based hierarchical mixing on patches provides competitive or superior results to transformer-based models on standard multivariate forecasting tasks.
- The architecture maintains performance gains across varying prediction horizons and dataset characteristics in 71 percent of tested configurations.
Where Pith is reading between the lines
- The same decomposition-plus-neighbor-mixing pattern could be tested on univariate series or on non-temporal sequence tasks such as text or audio where local structure matters.
- Because the model relies on fixed non-overlapping patches, its behavior on irregularly sampled or streaming time series would reveal whether online adaptation of the wavelet filters remains stable.
- Combining the channel-mixing encoder with explicit trend modeling from classical time-series methods might further reduce error on datasets dominated by seasonality.
Load-bearing premise
The learnable wavelet decomposition and hierarchical neighboring patch mixing capture the relevant local temporal dynamics and channel correlations more effectively than prior architectures without introducing new overfitting risks or requiring dataset-specific tuning.
What would settle it
Running the full set of 28 experimental setups on the seven benchmarks after ablating either the learnable wavelet filters or the neighboring patch mixing structure and observing whether performance drops below the reported state-of-the-art levels.
Figures

read the original abstract
Multivariate time series forecasting remains a challenge due to the complexity of local temporal dynamics and global dependencies across multiple variables. In this paper, we propose \textbf{N}eighboring \textbf{P}atching \textbf{Mixer} (\textbf{NPMixer}), a hierarchical architecture featuring a Learnable Stationary Wavelet Transform that adaptively learns filter coefficients to decompose signals into trend and detail components in a data-dependent manner. Our framework introduces a Neighboring Mixer Block that captures local temporal dynamics through a series of hierarchical MLP layers operating on non-overlapping patches. Specifically, the mixer block utilizes MLPs to learn temporal patterns within and across these patches, expanding the receptive field to capture multi-scale dependencies. A Channel-Mixing Encoder is applied to high-frequency components to learn channel correlations while preserving the stability of the underlying global trend. Extensive experiments on seven benchmark datasets demonstrate that NPMixer consistently outperforms state-of-the-art models, achieving better performance in 20 out of 28 ($71.4\%$) evaluated experimental setups for MSE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NPMixer, a hierarchical architecture for multivariate time series forecasting. It uses a Learnable Stationary Wavelet Transform to adaptively decompose signals into trend and detail components via data-dependent filter coefficients, a Neighboring Mixer Block with hierarchical MLPs on non-overlapping patches to capture local temporal dynamics and multi-scale dependencies, and a Channel-Mixing Encoder for high-frequency channel correlations. The central empirical claim is consistent outperformance over state-of-the-art models on seven benchmark datasets, with better MSE in 20 out of 28 setups (71.4%).
Significance. If the performance gains prove robust and attributable to the proposed components, NPMixer would offer a useful advance in time series forecasting by showing how learnable wavelet decomposition combined with hierarchical neighboring patch mixing can better handle local dynamics and channel correlations than prior architectures.
major comments (2)
- [Experiments] Experiments section: The results consist solely of single-run point estimates of MSE across the 28 setups (7 datasets × 4 horizons) with no standard deviations, confidence intervals, multiple random seeds, or statistical significance tests. This directly undermines the central claim of consistent superiority in 20/28 cases, as the reported wins cannot be distinguished from run-to-run variability or differences in hyperparameter search effort.
- [§3 (Methodology)] §3 (Methodology): The description of the Neighboring Mixer Block does not include an ablation isolating the contribution of the hierarchical neighboring patch mixing versus the learnable wavelet or the channel-mixing encoder, leaving open whether the reported gains stem from the full architecture or from one component.
minor comments (1)
- [Abstract] The abstract could specify the exact forecasting horizons and datasets used in the 28 setups for greater precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive view of NPMixer's potential contribution. We address each major comment below and commit to revisions that strengthen the empirical support and component analysis.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The results consist solely of single-run point estimates of MSE across the 28 setups (7 datasets × 4 horizons) with no standard deviations, confidence intervals, multiple random seeds, or statistical significance tests. This directly undermines the central claim of consistent superiority in 20/28 cases, as the reported wins cannot be distinguished from run-to-run variability or differences in hyperparameter search effort.
Authors: We agree that single-run point estimates limit the ability to quantify variability and statistical significance, even though consistent gains across seven diverse datasets and four horizons provide supporting evidence. In the revised manuscript we will rerun all experiments using multiple random seeds (at least five), report mean MSE with standard deviations, and include paired statistical significance tests against the strongest baselines to substantiate the 20/28 superiority claim. revision: yes
-
Referee: [§3 (Methodology)] §3 (Methodology): The description of the Neighboring Mixer Block does not include an ablation isolating the contribution of the hierarchical neighboring patch mixing versus the learnable wavelet or the channel-mixing encoder, leaving open whether the reported gains stem from the full architecture or from one component.
Authors: The referee correctly observes that the current manuscript lacks an ablation that isolates the hierarchical neighboring patch mixing from the learnable wavelet decomposition and channel-mixing encoder. While each component is motivated in the text, an explicit ablation is needed to attribute performance. We will add a dedicated ablation study in the revised version, evaluating variants that remove or replace each module while keeping the others fixed, and report the resulting MSE changes on the benchmark datasets. revision: yes
Circularity Check
No circularity: empirical architecture with no derivation chain
full rationale
The paper presents NPMixer as a neural architecture for multivariate time series forecasting, built from a learnable stationary wavelet transform, neighboring mixer blocks with MLPs on patches, and a channel-mixing encoder. No first-principles derivation, theorem, or prediction is claimed; performance is asserted solely via empirical MSE comparisons on seven benchmarks. No equations reduce to fitted inputs by construction, no self-citations are invoked as load-bearing uniqueness results, and no ansatz or renaming of known results occurs in a circular manner. The model definitions are independent of the reported outcomes.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable filter coefficients of the stationary wavelet transform
axioms (1)
- domain assumption Standard deep-learning assumptions that gradient-based optimization on MSE will discover useful temporal and cross-channel patterns when the architecture is sufficiently expressive.
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. ICLR , year=
-
[10]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author=. ICLR , year=
-
[11]
Jena Climate Dataset , year =
- [12]
- [13]
-
[14]
Time series analysis: forecasting and control , author=. 2015 , publisher=
work page 2015
-
[15]
Informer: Beyond efficient transformer for long sequence time-series forecasting , author=. AAAI , year=
-
[16]
International conference on machine learning , year=
Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting , author=. International conference on machine learning , year=
-
[17]
Crossformer: Transformer Utilizing Cross-Dimension Dependency for Multivariate Time Series Forecasting , author=. ICLR , year=
-
[18]
Are transformers effective for time series forecasting? , author=. AAAI , year=
-
[19]
Si-An Chen and Chun-Liang Li and Sercan O Arik and Nathanael Christian Yoder and Tomas Pfister , journal=
-
[20]
Proceedings of the IEEE , volume=
What is the fast Fourier transform? , author=. Proceedings of the IEEE , volume=. 1967 , publisher=
work page 1967
-
[21]
Frequency-domain MLPs are more effective learners in time series forecasting , author=. NeurIPS , year=
-
[22]
WaveForM: Graph Enhanced Wavelet Learning for Long Sequence Forecasting of Multivariate Time Series , abstractNote=. AAAI , author=. 2023 , month=
work page 2023
-
[23]
Msgnet: Learning multi-scale inter-series correlations for multivariate time series forecasting , author=. AAAI , year=
-
[24]
Hui Chen and Viet Luong and Lopamudra Mukherjee and Vikas Singh , booktitle=. Simple
-
[25]
Nason, G. P. and Silverman, B. W. The Stationary Wavelet Transform and some Statistical Applications. Wavelets and Statistics. 1995
work page 1995
-
[26]
Continuous and discrete wavelet transforms , author=. SIAM review , volume=. 1989 , publisher=
work page 1989
-
[27]
TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting , author=. ICLR , year=
-
[28]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting , author=. ICLR , year=
-
[29]
The eleventh international conference on learning representations , year=
Micn: Multi-scale local and global context modeling for long-term series forecasting , author=. The eleventh international conference on learning representations , year=
-
[30]
Tsmixer: Lightweight mlp-mixer model for multivariate time series forecasting , author=. ACM SIGKDD , year=
-
[31]
Swin transformer: Hierarchical vision transformer using shifted windows , author=. IEEE/CVF , year=
-
[32]
Advances in Neural Information Processing Systems , volume=
Crossgnn: Confronting noisy multivariate time series via cross interaction refinement , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Timexer: Empowering transformers for time series forecasting with exogenous variables , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
International Conference on Learning Representations , year=
Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift , author=. International Conference on Learning Representations , year=
- [35]
-
[36]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. NeurIPS , year=
-
[37]
Optuna: A Next-generation Hyperparameter Optimization Framework , author=. 2019 , eprint=
work page 2019
-
[40]
Proceedings of the National Academy of Sciences , volume =
Gabriel Michau and Gaetan Frusque and Olga Fink , title =. Proceedings of the National Academy of Sciences , volume =. 2022 , doi =
work page 2022
-
[41]
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis , author=. 2023 , eprint=
work page 2023
-
[42]
Optuna: A next-generation hyperparameter optimization framework, 2019
Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M. Optuna: A next-generation hyperparameter optimization framework, 2019
work page 2019
-
[43]
Box, G. E., Jenkins, G. M., Reinsel, G. C., and Ljung, G. M. Time series analysis: forecasting and control. John Wiley & Sons, 2015
work page 2015
-
[44]
Msgnet: Learning multi-scale inter-series correlations for multivariate time series forecasting
Cai, W., Liang, Y., Liu, X., Feng, J., and Wu, Y. Msgnet: Learning multi-scale inter-series correlations for multivariate time series forecasting. In AAAI, 2024
work page 2024
-
[45]
Performance measurement system ( PeMS )
California Department of Transportation (Caltrans) . Performance measurement system ( PeMS ). https://pems.dot.ca.gov/, 2024. Accessed: 2024-05-20
work page 2024
-
[46]
Simple TM : A simple baseline for multivariate time series forecasting
Chen, H., Luong, V., Mukherjee, L., and Singh, V. Simple TM : A simple baseline for multivariate time series forecasting. In ICLR, 2025
work page 2025
-
[47]
Chen, S.-A., Li, C.-L., Arik, S. O., Yoder, N. C., and Pfister, T. TSM ixer: An all- MLP architecture for time series forecasting. TMLR, 2023
work page 2023
-
[48]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021
work page 2021
-
[49]
Tsmixer: Lightweight mlp-mixer model for multivariate time series forecasting
Ekambaram, V., Jati, A., Nguyen, N., Sinthong, P., and Kalagnanam, J. Tsmixer: Lightweight mlp-mixer model for multivariate time series forecasting. In ACM SIGKDD, 2023
work page 2023
- [50]
-
[51]
Heil, C. E. and Walnut, D. F. Continuous and discrete wavelet transforms. SIAM review, 31 0 (4): 0 628--666, 1989
work page 1989
-
[52]
Crossgnn: Confronting noisy multivariate time series via cross interaction refinement
Huang, Q., Shen, L., Zhang, R., Ding, S., Wang, B., Zhou, Z., and Wang, Y. Crossgnn: Confronting noisy multivariate time series via cross interaction refinement. Advances in Neural Information Processing Systems, 36: 0 46885--46902, 2023
work page 2023
-
[53]
Reversible instance normalization for accurate time-series forecasting against distribution shift
Kim, T., Kim, J., Tae, Y., Park, C., Choi, J.-H., and Choo, J. Reversible instance normalization for accurate time-series forecasting against distribution shift. In International Conference on Learning Representations, 2022
work page 2022
-
[54]
itransformer: Inverted transformers are effective for time series forecasting
Liu, Y., Hu, T., Zhang, H., Wu, H., Wang, S., Ma, L., and Long, M. itransformer: Inverted transformers are effective for time series forecasting. In ICLR, 2024
work page 2024
-
[55]
Swin transformer: Hierarchical vision transformer using shifted windows
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., and Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In IEEE/CVF, 2021
work page 2021
-
[56]
Max Planck Institute for Biogeochemistry . Jena climate dataset. https://www.bgc-jena.mpg.de/wetter/, 2024. Accessed: 2024-05-20
work page 2024
-
[57]
Fully learnable deep wavelet transform for unsupervised monitoring of high-frequency time series
Michau, G., Frusque, G., and Fink, O. Fully learnable deep wavelet transform for unsupervised monitoring of high-frequency time series. Proceedings of the National Academy of Sciences, 119 0 (8): 0 e2106598119, 2022. doi:10.1073/pnas.2106598119
-
[58]
Nason, G. P. and Silverman, B. W. The Stationary Wavelet Transform and some Statistical Applications, pp.\ 281--299. Springer New York, New York, NY, 1995. ISBN 978-1-4612-2544-7
work page 1995
-
[59]
H., Sinthong, P., and Kalagnanam, J
Nie, Y., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. In ICLR, 2023
work page 2023
-
[60]
Qiu, X., Hu, J., Zhou, L., Wu, X., Du, J., Zhang, B., Guo, C., Zhou, A., Jensen, C. S., Sheng, Z., et al. Tfb: Towards comprehensive and fair benchmarking of time series forecasting methods. arXiv preprint arXiv:2403.20150, 2024
-
[61]
ElectricityLoadDiagrams20112014
Trindade, A. ElectricityLoadDiagrams20112014 . UCI Machine Learning Repository, 2015. DOI : https://doi.org/10.24432/C58C86
-
[62]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. NeurIPS, 2017
work page 2017
-
[63]
Micn: Multi-scale local and global context modeling for long-term series forecasting
Wang, H., Peng, J., Huang, F., Wang, J., Chen, J., and Xiao, Y. Micn: Multi-scale local and global context modeling for long-term series forecasting. In The eleventh international conference on learning representations, 2023
work page 2023
-
[64]
Wang, S., Wu, H., Shi, X., Hu, T., Luo, H., Ma, L., Zhang, J. Y., and ZHOU, J. Timemixer: Decomposable multiscale mixing for time series forecasting. In ICLR, 2024 a
work page 2024
-
[65]
Timexer: Empowering transformers for time series forecasting with exogenous variables
Wang, Y., Wu, H., Dong, J., Qin, G., Zhang, H., Liu, Y., Qiu, Y., Wang, J., and Long, M. Timexer: Empowering transformers for time series forecasting with exogenous variables. Advances in Neural Information Processing Systems, 37: 0 469--498, 2024 b
work page 2024
-
[66]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting
Wu, H., Xu, J., Wang, J., and Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. NeurIPS, 2021
work page 2021
-
[67]
Timesnet: Temporal 2d-variation modeling for general time series analysis, 2023
Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., and Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis, 2023
work page 2023
-
[68]
Waveform: Graph enhanced wavelet learning for long sequence forecasting of multivariate time series
Yang, F., Li, X., Wang, M., Zang, H., Pang, W., and Wang, M. Waveform: Graph enhanced wavelet learning for long sequence forecasting of multivariate time series. AAAI, Jun. 2023
work page 2023
-
[69]
Frequency-domain mlps are more effective learners in time series forecasting
Yi, K., Zhang, Q., Fan, W., Wang, S., Wang, P., He, H., An, N., Lian, D., Cao, L., and Niu, Z. Frequency-domain mlps are more effective learners in time series forecasting. NeurIPS, 2023
work page 2023
-
[70]
Are transformers effective for time series forecasting? In AAAI, 2023
Zeng, A., Chen, M., Zhang, L., and Xu, Q. Are transformers effective for time series forecasting? In AAAI, 2023
work page 2023
-
[71]
Zhang, Y. and Yan, J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In ICLR, 2023
work page 2023
-
[72]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., and Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In AAAI, 2021
work page 2021
-
[73]
Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting
Zhou, T., Ma, Z., Wen, Q., Wang, X., Sun, L., and Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In International conference on machine learning. PMLR, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.