Recognition: 2 theorem links
· Lean TheoremOn the Invariance and Generality of Neural Scaling Laws
Pith reviewed 2026-05-11 02:30 UTC · model grok-4.3
The pith
Neural scaling laws remain unchanged under information-preserving data transformations and adjust predictably via a single information-loss scalar when information is reduced.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
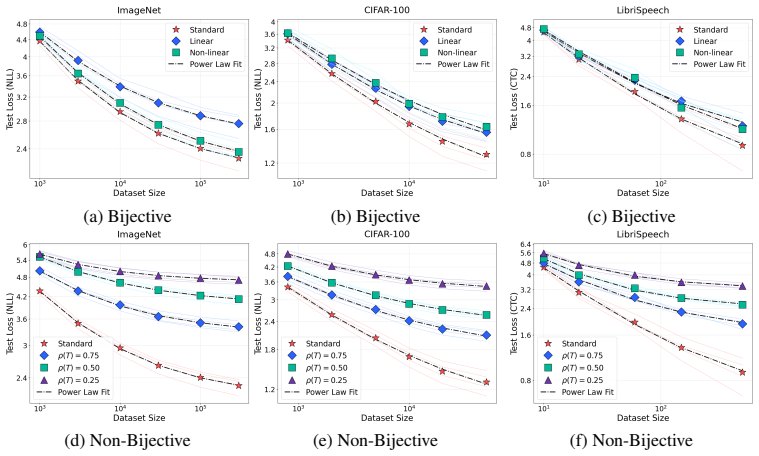
Scaling laws are preserved under bijective transformations of the data and modified in predictable, information-theoretically grounded ways under non-bijective transformations that lower its information resolution ρ: a single axis along which a law fit in one domain can be transported to another.
What carries the argument
The information resolution ρ, a scalar that quantifies the information loss caused by any non-bijective data transformation and serves as the adjustable parameter for moving scaling laws between domains.
If this is right
- Scaling laws fitted on general text predict performance for language models trained on electronic health records.
- Data-scaling exponents for time-series classification under different noise levels are recovered to within 3 percent error.
- Resource planning for new tasks can use transported laws instead of repeating full compute sweeps.
- Scaling behavior changes in a manner determined solely by the information reduction measured by ρ.
Where Pith is reading between the lines
- The same ρ-based transport might apply to video, audio, or multimodal data without new full sweeps.
- Data pipelines could be designed to minimize unwanted drops in ρ so that expected scaling remains reliable.
- ρ might be estimable from data statistics alone, avoiding any performance measurements in the target domain.
Load-bearing premise
A single scalar ρ fully captures the effect of any non-bijective transformation on scaling behavior across arbitrary domains and modalities.
What would settle it
Measure scaling curves in a new domain after applying a transformation whose ρ value is known, then check whether the observed exponents and intercepts match the values predicted from the source law within the reported error margins.
Figures


read the original abstract
Neural scaling laws establish a predictable relationship between model performance and data or compute, offering crucial guidance for resource allocation in new domains and tasks. Yet such laws are most needed precisely where they are hardest to obtain: fitting one for a new model task pair demands expensive sweeps that typically exhaust the very compute budget the law is meant to economize. This paper poses the research question of how to develop generalizable scaling laws: laws fit once on a well-resourced source domain and reliably transported to new domains where running a full sweep is infeasible, which requires a fundamental understanding of when and why scaling properties change. We address this by identifying the right invariants: scaling laws are preserved under bijective (information-preserving) transformations of the data and modified in predictable, information-theoretically grounded ways under non-bijective transformations that lower its information resolution $\rho$: a single axis along which a law fit in one domain can be transported to another. We validate this across language, vision, and speech, and demonstrate two cross-domain applications: predicting scaling for language models trained on electronic health records from laws fit on general text, and predicting time-series classification scaling under varying levels of noise injection, recovering the data-scaling exponents to within $3\%$ error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that neural scaling laws are invariant under bijective (information-preserving) transformations of the data and can be transported across domains via a single scalar parameter ρ (information resolution) under non-bijective transformations that reduce information content. It supports this with empirical results across language, vision, and speech modalities, plus two applications: transporting laws from general text to electronic health records and predicting scaling under varying noise levels in time-series classification, recovering data-scaling exponents to within 3% error.
Significance. If the invariance and transport claims hold, the work would enable substantial savings in compute by allowing scaling laws fitted in well-resourced domains to predict behavior in new ones without exhaustive sweeps. The cross-modality empirical recovery to within 3% and the two concrete applications are clear strengths that demonstrate practical relevance; the information-theoretic framing also offers a promising direction for understanding when scaling properties change.
major comments (2)
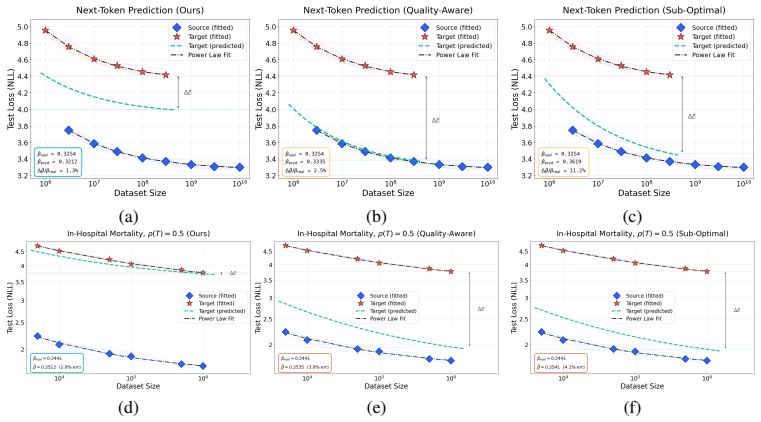
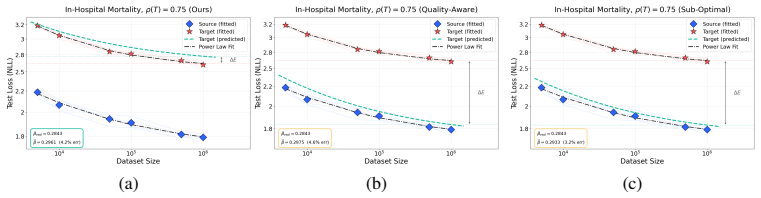
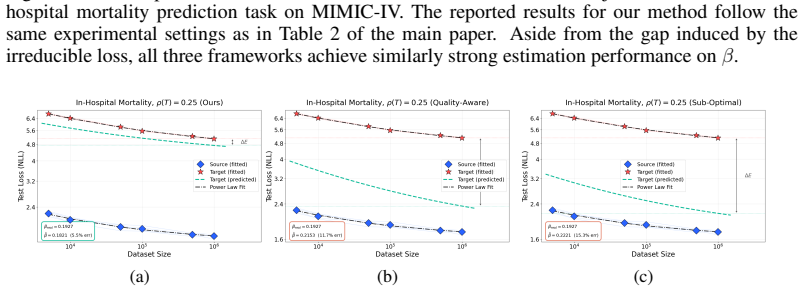
- [Abstract and §3] Abstract and §3 (definition of ρ): the claim that ρ is 'information-theoretically grounded' and enables independent transport is undermined if ρ must be computed or fitted from performance data in the target domain, as this makes the adjustment circular rather than a prediction from source-domain laws alone.
- [§5.2] §5.2 (noise-injection experiments): recovery to within 3% is shown for isotropic noise and EHR transfer, but the paper does not test whether a single scalar ρ suffices for qualitatively different information-reducing maps (e.g., structured masking or frequency truncation) that preserve the same mutual-information loss yet alter distribution structure and optimization dynamics differently; this is load-bearing for the generality claim.
minor comments (2)
- [§2] Notation for ρ and the scaling-law functional form should be introduced with an explicit equation in §2 or §3 to avoid ambiguity when discussing invariance.
- [Figures 3-5] Figure captions and axis labels in the empirical sections would benefit from explicit mention of the source vs. target domains and the fitted ρ values for each curve.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting the practical strengths of our cross-domain transport results. We address each major comment below with clarifications grounded in the manuscript's information-theoretic framework and indicate the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (definition of ρ): the claim that ρ is 'information-theoretically grounded' and enables independent transport is undermined if ρ must be computed or fitted from performance data in the target domain, as this makes the adjustment circular rather than a prediction from source-domain laws alone.
Authors: We thank the referee for this important clarification request. In our framework, ρ quantifies the reduction in mutual information induced by a non-bijective transformation and is computed directly from the data distributions or transformation parameters (e.g., via entropy estimates or known noise variance in the time-series case) without any reference to model performance or scaling exponents in the target domain. This ensures the procedure remains predictive: the power-law exponents are fitted exclusively on source-domain data, after which the independently derived ρ adjusts the law for the target. We will revise the abstract and §3 to include explicit computation procedures and formulas for ρ, with worked examples from both applications, to eliminate any ambiguity regarding circularity. revision: yes
-
Referee: [§5.2] §5.2 (noise-injection experiments): recovery to within 3% is shown for isotropic noise and EHR transfer, but the paper does not test whether a single scalar ρ suffices for qualitatively different information-reducing maps (e.g., structured masking or frequency truncation) that preserve the same mutual-information loss yet alter distribution structure and optimization dynamics differently; this is load-bearing for the generality claim.
Authors: The referee correctly notes that our empirical tests are limited to isotropic noise and domain transfer. While these cases recover exponents to within 3% and span multiple modalities, we have not evaluated structured maps such as masking or frequency truncation that could differentially affect optimization even at matched mutual-information loss. Our theory predicts that ρ remains sufficient because scaling depends on effective information content rather than map-specific structure, as supported by the invariance results under bijective transforms and the cross-modality consistency. We will add a dedicated discussion subsection in §5.2 and the conclusions acknowledging this scope limitation, providing theoretical justification for broader applicability, and outlining how future targeted experiments could further test the claim. This constitutes a partial revision focused on transparency rather than new large-scale experiments. revision: partial
Circularity Check
No significant circularity; scaling invariance derived from information-theoretic invariants and validated empirically
full rationale
The paper's core derivation posits that scaling laws are invariant under bijective transformations (information-preserving) and adjusted via a scalar information resolution ρ under non-bijective maps, with ρ positioned as an information-theoretic axis for transport between domains. This framework is presented as grounded in mutual information concepts rather than fitted to the target scaling exponents themselves. Empirical validations (cross-domain predictions for EHR and noise-injected time series) are described as tests of the transport rule, not as the source of the rule. No equations or steps in the provided abstract reduce a claimed prediction to a reparameterization of the input data or to a self-citation chain; the central claim retains independent content from the proposed invariants and is not forced by definition or prior self-work.
Axiom & Free-Parameter Ledger
free parameters (1)
- information resolution ρ
axioms (1)
- domain assumption Neural scaling laws take a power-law form in data or compute
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesscaling laws are preserved under bijective transformations ... modified in predictable, information-theoretically grounded ways under non-bijective transformations that lower its information resolution ρ
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclearL(N, D, ρ) = A/N^α + B/D^β · ρ(T)^{-ν} + E + κ(1-ρ(T))^μ
Reference graph
Works this paper leans on
-
[1]
A. Aghajanyan, L. Yu, A. Conneau, W.-N. Hsu, K. Hambardzumyan, S. Zhang, S. Roller, N. Goyal, O. Levy, and L. Zettlemoyer. Scaling laws for generative mixed-modal language models. InInternational Conference on Machine Learning, pages 265–279. PMLR, 2023
work page 2023
-
[2]
I. M. Alabdulmohsin, X. Zhai, A. Kolesnikov, and L. Beyer. Getting vit in shape: Scaling laws for compute-optimal model design.Advances in Neural Information Processing Systems, 36:16406–16425, 2023
work page 2023
-
[3]
A. Alqahtani, M. Ali, X. Xie, and M. W. Jones. Deep time-series clustering: A review.Elec- tronics, 10(23):3001, 2021
work page 2021
-
[4]
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli. wav2vec 2.0: A framework for self- supervised learning of speech representations.Advances in neural information processing systems, 33:12449–12460, 2020
work page 2020
- [5]
-
[6]
D. Brandfonbrener, N. Anand, N. Vyas, E. Malach, and S. Kakade. Loss-to-loss prediction: Scaling laws for all datasets.arXiv preprint arXiv:2411.12925, 2024
- [7]
-
[8]
Z. Chen, S. Wang, T. Xiao, Y . Wang, S. Chen, X. Cai, J. He, and J. Wang. Revisiting scaling laws for language models: The role of data quality and training strategies. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23881–23899, 2025
work page 2025
-
[9]
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev. Reproducible scaling laws for contrastive language-image learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023
work page 2023
-
[10]
L. Choshen, Y . Zhang, and J. Andreas. A hitchhiker’s guide to scaling law estimation.arXiv preprint arXiv:2410.11840, 2024
- [11]
-
[12]
P. C. Cosman, K. L. Oehler, E. A. Riskin, and R. M. Gray. Using vector quantization for image processing.Proceedings of the IEEE, 81(9):1326–1341, 2002
work page 2002
-
[13]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierar- chical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 10
work page 2009
-
[14]
L. Dinh, J. Sohl-Dickstein, and S. Bengio. Density estimation using real nvp.arXiv preprint arXiv:1605.08803, 2016
work page internal anchor Pith review arXiv 2016
- [15]
-
[16]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [17]
- [18]
- [19]
-
[20]
N. C. Frey, R. Soklaski, S. Axelrod, S. Samsi, R. Gomez-Bombarelli, C. W. Coley, and V . Gadepally. Neural scaling of deep chemical models.Nature Machine Intelligence, 5(11):1297–1305, 2023
work page 2023
- [21]
-
[22]
A. Gokaslan, V . Cohen, E. Pavlick, and S. Tellex. Openwebtext corpus.http:// Skylion007.github.io/OpenWebTextCorpus, 2019
work page 2019
- [23]
-
[24]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[25]
Scaling Laws for Autoregressive Generative Modeling
T. Henighan, J. Kaplan, M. Katz, M. Chen, C. Hesse, J. Jackson, H. Jun, T. B. Brown, P. Dhari- wal, S. Gray, et al. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010.14701, 2020
work page internal anchor Pith review arXiv 2010
-
[26]
D. Hernandez, J. Kaplan, T. Henighan, and S. McCandlish. Scaling laws for transfer.arXiv preprint arXiv:2102.01293, 2021
-
[27]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, et al. Training compute-optimal large language models (2022).arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
A. Hyv ¨arinen, I. Khemakhem, and H. Morioka. Nonlinear independent component analysis for principled disentanglement in unsupervised deep learning.Patterns, 4(10), 2023
work page 2023
-
[29]
A. E. Johnson, L. Bulgarelli, L. Shen, A. Gayles, A. Shammout, S. Horng, T. J. Pollard, S. Hao, B. Moody, B. Gow, et al. Mimic-iv, a freely accessible electronic health record dataset.Scien- tific data, 10(1):1, 2023
work page 2023
-
[30]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[31]
A. Krizhevsky, G. Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[32]
J. Lang, Z. Guo, and S. Huang. A comprehensive study on quantization techniques for large language models. In2024 4th International Conference on Artificial Intelligence, Robotics, and Communication (ICAIRC), pages 224–231. IEEE, 2024. 11
work page 2024
- [33]
-
[34]
X. Lu, H. Wang, W. Dong, F. Wu, Z. Zheng, and G. Shi. Learning a deep vector quantization network for image compression.IEEE Access, 7:118815–118825, 2019
work page 2019
-
[35]
I. Markovsky and K. Usevich.Low rank approximation, volume 139. Springer, 2012
work page 2012
- [36]
-
[37]
N. Muennighoff, A. Rush, B. Barak, T. Le Scao, N. Tazi, A. Piktus, S. Pyysalo, T. Wolf, and C. A. Raffel. Scaling data-constrained language models.Advances in Neural Information Processing Systems, 36:50358–50376, 2023
work page 2023
- [38]
-
[39]
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur. Librispeech: an asr corpus based on public domain audio books. In2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015
work page 2015
-
[40]
G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mohamed, and B. Lakshminarayanan. Nor- malizing flows for probabilistic modeling and inference.Journal of Machine Learning Re- search, 22(57):1–64, 2021
work page 2021
- [41]
- [42]
-
[43]
D. Rezende and S. Mohamed. Variational inference with normalizing flows. InInternational conference on machine learning, pages 1530–1538. PMLR, 2015
work page 2015
-
[44]
Y . Ruan, C. J. Maddison, and T. B. Hashimoto. Observational scaling laws and the predictabil- ity of langauge model performance.Advances in Neural Information Processing Systems, 37:15841–15892, 2024
work page 2024
-
[45]
An introductory guide to Fano’s inequality with appli- cations in statistical estimation,
J. Scarlett and V . Cevher. An introductory guide to fano’s inequality with applications in statistical estimation.arXiv preprint arXiv:1901.00555, 2019
-
[46]
Scaling laws for native multimodal models.arXiv preprint arXiv:2504.07951, 2025
M. Shukor, E. Fini, V . G. T. da Costa, M. Cord, J. Susskind, and A. El-Nouby. Scaling laws for native multimodal models.arXiv preprint arXiv:2504.07951, 2025
-
[47]
A. Subramanyam, Y . Chen, and R. L. Grossman. Scaling laws revisited: modeling the role of data quality in language model pretraining.arXiv preprint arXiv:2510.03313, 2025
-
[48]
H. L. Van Trees.Detection, estimation, and modulation theory, part I: detection, estimation, and linear modulation theory. John Wiley & Sons, 2004
work page 2004
- [49]
- [50]
- [51]
-
[52]
X. Zhai, A. Kolesnikov, N. Houlsby, and L. Beyer. Scaling vision transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12104–12113, 2022
work page 2022
-
[53]
On the Invariance and Generality of Neural Scaling Laws
S. Zhang, Q. Liu, N. Usuyama, C. Wong, T. Naumann, and H. Poon. Exploring scaling laws for ehr foundation models.arXiv preprint arXiv:2505.22964, 2025. 12 Supplementary Material for “On the Invariance and Generality of Neural Scaling Laws” A Extended Related Works Scaling Laws Across Modalities.Neural scaling laws have become foundational to understanding...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.