Recognition: 3 theorem links
· Lean TheoremDisagreement-Regularized Importance Sampling for Adversarial Label Corruption
Pith reviewed 2026-05-11 02:04 UTC · model grok-4.3
The pith
Disagreement-regularized importance sampling uses loss rank disagreement to separate bulk corrupted examples from boundary-clean ones with explicit finite-sample concentration bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DR-IS selects a subset by ranking examples according to their loss-rank disagreement across proxy models and retaining those with high disagreement. The central theorem establishes that, with probability 1-delta, the empirical disagreement of bulk corrupted examples lies at most O(sqrt(log(N/delta)/K)) above its expectation while that of boundary-clean examples lies at least that far below; whenever the structural gap Delta-prime is positive and the clean set is large enough relative to the target subset size, this guarantees strict separation and an explicit upper bound on the contamination fraction inside the selected subset.
What carries the argument
Loss rank-disagreement measured across an independent proxy ensemble, which quantifies how stably an example ranks high or low in loss relative to the rest of the data.
If this is right
- The selected subset carries an explicit, finite-sample upper bound on the fraction of corrupted labels it can contain.
- DR-IS remains stable under targeted attacks that prioritize high-norm adversarial outliers, unlike pure magnitude-based selection.
- The method supplies concentration certificates that complement heuristic training-dynamics filters such as AUM.
- The same disagreement signal can be used to control noise leakage from the statistical tail of the corrupted distribution.
Where Pith is reading between the lines
- The O(1/sqrt(K)) rate suggests that increasing the proxy ensemble size can tighten separation without additional labeled data.
- The approach may extend to other selection problems such as active learning or core-set construction under label noise.
- If the gap Delta-prime can be estimated from data, the method could adaptively choose subset size to meet a target contamination level.
Load-bearing premise
A positive structural expectation gap exists between the disagreement distributions of corrupted and clean groups, and the boundary-clean set is at least as large as the subset being selected.
What would settle it
A dataset where the empirical rank disagreement of known corrupted points exceeds that of known clean points at a rate slower than O(sqrt(log(N/delta)/K)), or where the selected subset contamination rate exceeds the certified bound despite a verified positive Delta-prime and sufficient clean examples, would falsify the separation claim.
Figures

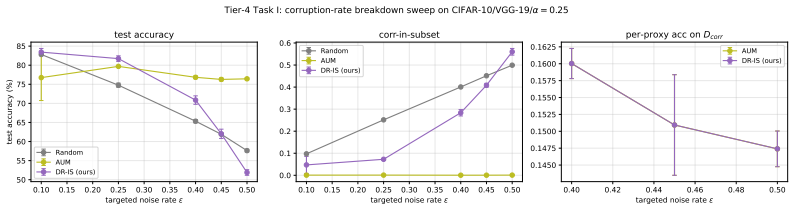




read the original abstract
Standard Importance Sampling (IS) collapses under label corruption because high-norm examples, prioritized for variance reduction, are often adversarial outliers. We formalize this misalignment using an $\varepsilon$-contamination model and propose Disagreement-Regularized Importance Sampling (DR-IS), a sub-sampling method based on loss rank-disagreement across independent proxy ensemble. We prove finite-sample concentration bounds showing that the empirical rank disagreement of bulk corrupted examples is bounded above, and that of boundary-clean examples bounded below, both at rate $O(\sqrt{\log(N/\delta)/K})$ with probability $1-\delta$; when the structural expectation gap $\Delta'$ between the two groups is positive and the boundary-clean set is at least as large as the selected subset, these bounds certify strict separation and control the contamination rate of the selected subset. Empirically, DR-IS remains robust under targeted high-norm attacks that break magnitude-based methods such as the Error $L_2$-norm (EL2N) on benchmark datasets. DR-IS complements training-dynamics approaches like Area Under the Margin ranking (AUM), offering improved robustness in the loss-aligned regime alongside explicit finite-sample concentration certificates and a contamination bound limiting noise leakage from the statistical tail of corrupted points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Disagreement-Regularized Importance Sampling (DR-IS), a subsampling method that uses loss rank-disagreement across an independent proxy ensemble to mitigate the collapse of standard importance sampling under adversarial label corruption formalized via an ε-contamination model. It derives finite-sample concentration bounds showing that the empirical rank disagreement of bulk corrupted examples is upper-bounded and that of boundary-clean examples is lower-bounded, each at rate O(√(log(N/δ)/K)) with probability 1-δ. Under the structural assumptions that the expectation gap Δ' > 0 and that the boundary-clean set is at least as large as the selected subset, these bounds certify strict separation and bound the contamination rate of the selected high-disagreement subset. Empirical evaluations demonstrate robustness to targeted high-norm attacks that defeat magnitude-based baselines such as EL2N, while complementing dynamics-based methods like AUM.
Significance. If the concentration bounds and separation hold under the stated assumptions, the work supplies explicit finite-sample certificates and a contamination bound that are absent from most training-dynamics or heuristic subsampling approaches. This provides a principled, theoretically grounded alternative for robust importance sampling in corrupted regimes and could inform the design of other disagreement-based filters.
major comments (2)
- [Abstract / main theorem] Abstract and the statement of the main separation result: the certification of strict separation and the contamination-rate bound are conditioned on the structural assumption that Δ' := E_clean - E_corrupt > 0 together with |boundary-clean| ≥ size of selected subset. Neither condition is derived from the ε-contamination model; the paper must either supply verifiable conditions guaranteeing Δ' > 0 or analyze the degradation when an adversary places corrupted points near the decision boundary to shrink Δ'.
- [Proof of concentration bounds] The finite-sample bounds are obtained by applying standard concentration inequalities to rank statistics. The derivation should be checked for any hidden dependence on the proxy ensemble size K or on the particular loss used to compute ranks; if the O(√(log(N/δ)/K)) rate is tight only under additional regularity on the loss distribution, this must be stated explicitly.
minor comments (2)
- [Notation] Notation for the proxy ensemble and the rank-disagreement statistic should be introduced once and used consistently; the current abstract uses both “proxy ensemble” and “independent proxy ensemble” without a single defining equation.
- [Experiments] The empirical section would benefit from an explicit table reporting the measured Δ' on each benchmark under the attack configurations, so readers can assess how close the operating regime is to the assumed positive-gap regime.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important aspects of the assumptions and proof details that we address point by point below. We will incorporate revisions to strengthen the presentation of the structural assumptions and the concentration analysis.
read point-by-point responses
-
Referee: [Abstract / main theorem] Abstract and the statement of the main separation result: the certification of strict separation and the contamination-rate bound are conditioned on the structural assumption that Δ' := E_clean - E_corrupt > 0 together with |boundary-clean| ≥ size of selected subset. Neither condition is derived from the ε-contamination model; the paper must either supply verifiable conditions guaranteeing Δ' > 0 or analyze the degradation when an adversary places corrupted points near the decision boundary to shrink Δ'.
Authors: We agree that Δ' > 0 is a structural assumption not implied by the ε-contamination model. The model allows arbitrary placement of corrupted points, so an adversary can indeed position them near the decision boundary to reduce Δ'. We cannot derive Δ' > 0 in general from the contamination model alone, as it depends on the data distribution and proxy model behavior. In the revision we will add a dedicated discussion section that (i) states verifiable conditions under which Δ' > 0 is expected (e.g., when clean examples produce systematically higher rank disagreement than bulk corrupted ones under the true labeling), and (ii) analyzes the degradation of the separation and contamination bounds as Δ' approaches or falls below zero, including a quantitative sensitivity result showing how the certified contamination rate worsens. revision: yes
-
Referee: [Proof of concentration bounds] The finite-sample bounds are obtained by applying standard concentration inequalities to rank statistics. The derivation should be checked for any hidden dependence on the proxy ensemble size K or on the particular loss used to compute ranks; if the O(√(log(N/δ)/K)) rate is tight only under additional regularity on the loss distribution, this must be stated explicitly.
Authors: The O(√(log(N/δ)/K)) rate arises directly from applying Hoeffding’s inequality to the empirical disagreement, which is the average of K independent bounded [0,1] rank-disagreement indicators. The 1/√K factor is therefore explicit and not hidden. The boundedness holds for any loss function used to produce ranks, because disagreement is defined via relative ordering rather than the absolute loss values. No further regularity (e.g., sub-Gaussian tails or moment bounds beyond [0,1]) is required for the stated rate. In the revision we will (i) restate the boundedness assumption at the beginning of the proof, (ii) note that the rate is general for any loss yielding bounded disagreement statistics, and (iii) add a remark that if an unbounded loss were used without truncation the bounds would require a different concentration tool. revision: yes
Circularity Check
No circularity: bounds follow from standard concentration inequalities on rank statistics
full rationale
The paper's central derivation applies standard finite-sample concentration inequalities (e.g., Hoeffding-type bounds) to the empirical rank-disagreement random variables computed across an independent proxy ensemble. The resulting O(√(log(N/δ)/K)) rates are applied separately to the bulk-corrupted and boundary-clean groups; strict separation is then stated as holding only under the explicit structural assumptions Δ' > 0 and |boundary-clean| ≥ selected-subset size. Neither the concentration statement nor the DR-IS selection rule is defined in terms of its own output, fitted to a prediction target, or justified solely by self-citation. The derivation chain therefore remains self-contained against external probabilistic tools and does not reduce to any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- K
- δ
axioms (2)
- domain assumption ε-contamination model for label corruption
- ad hoc to paper Positive structural expectation gap Δ' between corrupted and clean groups
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove finite-sample concentration bounds showing that the empirical rank disagreement of bulk corrupted examples is bounded above, and that of boundary-clean examples bounded below, both at rate O(√(log(N/δ)/K)) ... when the structural expectation gap Δ' ... is positive
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Assumption 2 (Quantile concentration of corrupted ranks) ... Assumption 3 (Boundary disagreement) ... Assumption 4 (Average tail variance)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (High-Quantile Separation) ... McDiarmid’s inequality
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Variance reduction in sgd by distributed importance sampling.arXiv preprint arXiv:1511.06481,
Guillaume Alain, Alex Lamb, Chinnadhurai Sankar, Aaron Courville, and Yoshua Ben- gio. Variance reduction in SGD by distributed importance sampling.arXiv preprint arXiv:1511.06481, 2015. Also appeared at the ICLR 2016 Workshop Track
-
[2]
Food-101 – mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 – mining discriminative components with random forests. InComputer Vision – ECCV 2014, pages 446–461. Springer, 2014
work page 2014
-
[3]
Selection via proxy: Efficient data selection for deep learning
Cody Coleman, Christopher Yeh, Stephen Mussmann, Baharan Mirzasoleiman, Peter Bailis, Percy Liang, Jure Leskovec, and Matei Zaharia. Selection via proxy: Efficient data selection for deep learning. InInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[4]
Importance sampling for minibatches.Journal of Machine Learning Research, 19(27):1–21, 2018
Dominik Csiba and Peter Richtárik. Importance sampling for minibatches.Journal of Machine Learning Research, 19(27):1–21, 2018
work page 2018
- [5]
-
[6]
Aymeric Dieuleveut, Alain Durmus, and Francis Bach. Bridging the gap between constant step size stochastic gradient descent and Markov chains.Annals of Statistics, 48(3), 2020
work page 2020
-
[7]
Deep Bayesian active learning with image data
Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep Bayesian active learning with image data. InProceedings of the 34th International Conference on Machine Learning (ICML), pages 1183–1192, 2017
work page 2017
-
[8]
Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor W. Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural networks with extremely noisy labels. InAdvances in Neural Information Processing Systems (NeurIPS), volume 31, 2018
work page 2018
-
[9]
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Vir- tanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Hal- dane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin S...
work page 2020
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 770–778, 2016
work page 2016
-
[11]
Robust estimation of a location parameter
Peter J Huber. Robust estimation of a location parameter. pages 492–518, 1992
work page 1992
-
[12]
Matplotlib: A 2d graphics environment.Computing in science & engineering, 9(3):90–95, 2007
John D Hunter. Matplotlib: A 2d graphics environment.Computing in science & engineering, 9(3):90–95, 2007
work page 2007
-
[13]
Angela H. Jiang, Daniel L.-K. Wong, Giulio Zhou, David G. Andersen, Jeffrey Dean, Gre- gory R. Ganger, Gauri Joshi, Michael Kaminksy, Michael Kozuch, Zachary C. Lipton, and Padmanabhan Pillai. Accelerating deep learning by focusing on the biggest losers.arXiv preprint arXiv: 1910.00762, 2019
-
[14]
Tyler B. Johnson and Carlos Guestrin. Training deep models faster with robust, approximate importance sampling. InAdvances in Neural Information Processing Systems (NeurIPS), vol- ume 31, 2018. 10
work page 2018
-
[15]
Not all samples are created equal: Deep learning with importance sampling
Angelos Katharopoulos and François Fleuret. Not all samples are created equal: Deep learning with importance sampling. InProceedings of the 35th International Conference on Machine Learning (ICML), pages 2525–2534, 2018
work page 2018
-
[16]
Alex Kendall and Yarin Gal. What uncertainties do we need in Bayesian deep learning for com- puter vision? InAdvances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
work page 2017
-
[17]
GRAD-MATCH: Gradient matching based data subset selection for efficient deep model training
Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, Abir De, and Rishabh Iyer. GRAD-MATCH: Gradient matching based data subset selection for efficient deep model training. InProceedings of the 38th International Conference on Machine Learn- ing (ICML), pages 5464–5474, 2021
work page 2021
-
[18]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[19]
Simple and scalable pre- dictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable pre- dictive uncertainty estimation using deep ensembles. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), volume 30, 2017
work page 2017
-
[20]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
work page 2002
-
[21]
Junnan Li, Richard Socher, and Steven C. H. Hoi. DivideMix: Learning with noisy labels as semi-supervised learning. InInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[22]
Early- learning regularization prevents memorization of noisy labels
Sheng Liu, Jonathan Niles-Weed, Narges Razavian, and Carlos Fernandez-Granda. Early- learning regularization prevents memorization of noisy labels. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), volume 33, 2020
work page 2020
-
[23]
arXiv preprint arXiv:1511.06343 , year =
Ilya Loshchilov and Frank Hutter. Online batch selection for faster training of neural networks. InInternational Conference on Learning Representations (ICLR) Workshop Track, 2016. arXiv preprint arXiv:1511.06343, 2015
-
[24]
SGDR: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[25]
On the method of bounded differences
Colin McDiarmid. On the method of bounded differences. InSurveys in Combinatorics, 1989, volume 141 ofLondon Mathematical Society Lecture Note Series, pages 148–188. Cambridge University Press, 1989
work page 1989
-
[26]
Data structures for statistical computing in python
Wes McKinney. Data structures for statistical computing in python. InProceedings of the Python in Science Conference, volume 445, pages 56–61. SciPy, 2010
work page 2010
-
[27]
Sören Mindermann, Jan M. Brauner, Muhammed T. Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan N. Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal. Prioritized training on points that are learnable, worth learning, and not yet learnt. InProceedings of the 39th International Conference on Machine Learning (ICML), pages 156...
work page 2022
-
[28]
Coresets for data-efficient training of machine learning models
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models. InProceedings of the 37th International Conference on Machine Learning (ICML), pages 6950–6960, 2020
work page 2020
-
[29]
Deanna Needell, Nathan Srebro, and Rachel Ward. Stochastic gradient descent, weighted sampling, and the randomized Kaczmarz algorithm.Mathematical Programming, 155(1–2): 549–573, 2016
work page 2016
-
[30]
Pytorch: An imperative style, high- performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high- perf...
work page 2019
-
[31]
Deep learning on a data diet: Finding important examples early in training
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziugaite. Deep learning on a data diet: Finding important examples early in training. InAdvances in Neural Information Processing Systems (NeurIPS), volume 34, pages 20596–20607, 2021. 11
work page 2021
-
[32]
Concentration inequalities for Markov chains by Marton couplings and spectral methods.Electron
Daniel Paulin. Concentration inequalities for Markov chains by Marton couplings and spectral methods.Electron. J. Probab, 20:1–32, 2015
work page 2015
-
[33]
Scikit-learn: Machine learning in Python.J
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. Scikit-learn: Machine learning in Python.J. Mach. Learn. Res., 12: 2825–2830, 2011
work page 2011
-
[34]
Geoff Pleiss, Tianyi Zhang, Ethan R. Elenberg, and Kilian Q. Weinberger. Identifying mis- labeled data using the area under the margin ranking. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, 2020
work page 2020
-
[35]
Non-convex learning via stochas- tic gradient Langevin dynamics: a nonasymptotic analysis
Maxim Raginsky, Alexander Rakhlin, and Matus Telgarsky. Non-convex learning via stochas- tic gradient Langevin dynamics: a nonasymptotic analysis. InConference on Learning Theory, pages 1674–1703. PMLR, 2017
work page 2017
-
[36]
Prioritized experience replay,
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay,
-
[37]
URLhttps://arxiv.org/abs/1511.05952
-
[38]
H. S. Seung, M. Opper, and H. Sompolinsky. Query by committee. InProceedings of the Fifth Annual Workshop on Computational Learning Theory (COLT), pages 287–294. Association for Computing Machinery, 1992
work page 1992
-
[39]
Very deep convolutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. InInternational Conference on Learning Representations (ICLR), 2015
work page 2015
-
[40]
Beyond neural scaling laws: Beating power law scaling via data pruning
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: Beating power law scaling via data pruning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, 2022
work page 2022
-
[41]
Thomas Strohmer and Roman Vershynin. A randomized Kaczmarz algorithm with exponential convergence.Journal of Fourier Analysis and Applications, 15(2):262–278, 2009
work page 2009
-
[42]
Swabha Swayamdipta, Roy Schwartz, Nicholas Lourie, Yizhong Wang, Hannaneh Hajishirzi, Noah A. Smith, and Yejin Choi. Dataset cartography: Mapping and diagnosing datasets with training dynamics. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9275–9293, 2020
work page 2020
-
[43]
Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Ben- gio, and Geoffrey J. Gordon. An empirical study of example forgetting during deep neural network learning. InInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[44]
Pauli Virtanen, Ralf Gommers, Travis E Oliphant, Matt Haberland, Tyler Reddy, David Cour- napeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, et al. Scipy 1.0: fundamental algorithms for scientific computing in python.Nature methods, 17(3):261–272, 2020
work page 2020
-
[45]
Understand- ing deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understand- ing deep learning requires rethinking generalization. InInternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[46]
Peilin Zhao and Tong Zhang. Stochastic optimization with importance sampling for regularized loss minimization. InProceedings of the 32nd International Conference on Machine Learning (ICML), pages 1–9, 2015. A Proofs A.1 Proof of Theorem 1 Proof.Fix anyi∈ {1, . . . , N}. We first establish the concentration of the empirical rank- disagreementbσ2 i around ...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.