Recognition: no theorem link
foap4: Adaptive mesh refinement with OpenACC, MPI, and p4est
Pith reviewed 2026-05-11 02:56 UTC · model grok-4.3
The pith
AMR simulations run efficiently on GPUs with OpenACC and MPI even using small 8^3 grid blocks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
foap4 demonstrates that AMR simulations of gas dynamics can be carried out efficiently on GPUs with OpenACC and MPI, even when using relatively small grid blocks of 8^3 or 16^3 cells, as shown through 2D and 3D benchmarks on both static and adaptive meshes of varying sizes.
What carries the argument
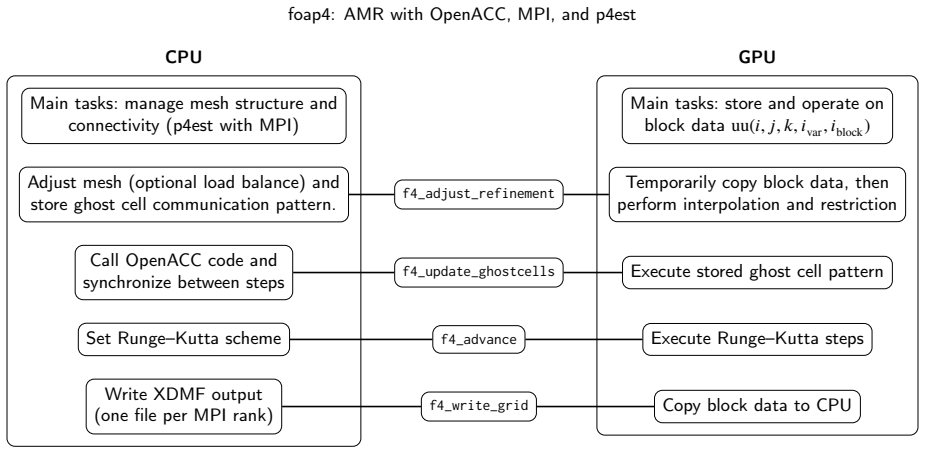
The foap4 framework, which integrates OpenACC directives for GPU offloading with MPI communication and the p4est library for adaptive mesh handling inside a Fortran codebase.
If this is right
- Existing Fortran AMR codes can be updated for GPU use via OpenACC without major architectural changes.
- Small grid blocks remain practical for maintaining high adaptivity in GPU-based AMR.
- Both static and adaptive mesh modes achieve usable performance for explicit Euler solvers in 2D and 3D.
- The approach scales across problem sizes and different accelerator hardware.
Where Pith is reading between the lines
- The same integration pattern could be tested on other hyperbolic or parabolic equation systems.
- OpenACC may lower the barrier for GPU porting compared with lower-level alternatives for legacy Fortran codes.
- Energy consumption and memory bandwidth limits on GPUs could become the next performance bottlenecks to examine.
- Multi-node GPU clusters might reveal additional communication overheads not fully captured in the current tests.
Load-bearing premise
The chosen benchmark problems and hardware configurations represent the production workloads that existing Fortran AMR codes would encounter when ported to GPUs.
What would settle it
A measurement showing substantially lower efficiency or poor scaling when the same framework is applied to larger, more complex real-world AMR problems on a wider range of GPU hardware.
Figures












read the original abstract
GPUs and other accelerators are increasingly used for scientific computing. In the future, we want to add GPU support to parallel adaptive mesh refinement (AMR) codes written in Fortran. To understand which changes are necessary to obtain good performance we have developed foap4, an AMR framework implemented in Fortran that uses OpenACC, MPI, and the p4est library. We discuss the design and implementation of the framework. Several benchmark problems are considered, in which Euler's equations of gas dynamics are solved using explicit time integration. These benchmarks are performed in both 2D and 3D, using static and adaptive meshes, for varying problem sizes on different hardware. Our results show that AMR simulations can be carried out efficiently on GPUs with OpenACC and MPI, even when using relatively small grid blocks of $8^3$ or $16^3$ cells.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents foap4, a Fortran AMR framework that combines OpenACC for GPU acceleration, MPI for distributed parallelism, and the p4est library for mesh management. It reports benchmarks solving the Euler equations with explicit time integration on static and adaptive meshes in both 2D and 3D, across varying problem sizes and hardware, and concludes that efficient GPU performance is achievable even with small blocks of 8^3 or 16^3 cells.
Significance. If the reported timings are robust, the work provides a concrete, portable path for adding GPU support to existing Fortran AMR codes without requiring large block sizes or complete rewrites, which addresses a practical barrier in computational physics and fluid dynamics on accelerator hardware.
major comments (2)
- [Results] The efficiency claim for 8^3/16^3 blocks (abstract and results) rests on overall wall-clock timings but does not isolate the relative cost of MPI halo exchanges or the increased number of OpenACC kernel launches that accompany adaptive regridding; without such a breakdown it is unclear whether the result generalizes beyond the chosen Euler benchmarks.
- [Results] The manuscript states that both static and adaptive meshes were tested, yet the performance tables do not report separate overheads for mesh adaptation steps versus the time-stepping loop, leaving open the possibility that the small-block efficiency is an artifact of the specific test problems rather than a general property of the foap4 design.
minor comments (2)
- [Methods] Notation for block sizes (e.g., 8^3) is used without an explicit definition of the underlying cell count or ghost-layer width in the methods section.
- [Results] The hardware configurations and compiler flags used for the OpenACC runs should be listed in a dedicated table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major comments point by point below, with partial revisions to add clarifying discussion on performance overheads.
read point-by-point responses
-
Referee: [Results] The efficiency claim for 8^3/16^3 blocks (abstract and results) rests on overall wall-clock timings but does not isolate the relative cost of MPI halo exchanges or the increased number of OpenACC kernel launches that accompany adaptive regridding; without such a breakdown it is unclear whether the result generalizes beyond the chosen Euler benchmarks.
Authors: We agree that isolating MPI halo exchange costs and extra kernel launches from regridding would strengthen generalization claims. In the revised manuscript we have added text noting that regridding occurs infrequently (every 10-20 steps in the reported tests) relative to the explicit time-stepping loop. The static-mesh benchmarks, which incur no regridding overhead, exhibit comparable small-block efficiency, indicating that the result is not driven solely by the adaptive overheads present in the Euler cases. A full quantitative breakdown would require additional instrumentation not performed in the original study. revision: partial
-
Referee: [Results] The manuscript states that both static and adaptive meshes were tested, yet the performance tables do not report separate overheads for mesh adaptation steps versus the time-stepping loop, leaving open the possibility that the small-block efficiency is an artifact of the specific test problems rather than a general property of the foap4 design.
Authors: The tables report aggregate wall-clock times for complete runs. We have revised the results section to state explicitly the adaptation frequency used and to highlight that time-stepping dominates runtime in both static and adaptive configurations. Separate adaptation overheads are not tabulated because they were secondary to demonstrating overall feasibility with small blocks; however, the direct comparison between static and adaptive timings in the same Euler benchmarks shows that small-block performance persists when adaptation is absent. The chosen test problems are standard for explicit AMR gas dynamics and the framework design itself is not problem-specific. revision: partial
Circularity Check
No circularity: empirical implementation and benchmark results
full rationale
The paper describes the design and implementation of the foap4 AMR framework using Fortran, OpenACC, MPI, and p4est, followed by empirical performance measurements on benchmark problems solving Euler equations in 2D/3D with static and adaptive meshes. No derivation chain, first-principles predictions, or fitted parameters are present; all claims rest on direct timing results from hardware runs. No self-citations, ansatzes, or renamings reduce results to inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fypp – python powered fortran metaprogramming
Aradi, B., 2026. Fypp – python powered fortran metaprogramming. https://github.com/aradi/fypp. Accessed: 2026-04-16
work page 2026
-
[2]
P4est : Scalable Algorithms for Parallel Adaptive Mesh Refinement on Forests of Octrees
Burstedde, C., Wilcox, L.C., Ghattas, O., 2011. P4est : Scalable Algorithms for Parallel Adaptive Mesh Refinement on Forests of Octrees. SIAM Journal on Scientific Computing 33, 1103–1133. doi:10.1137/100791634
-
[3]
GPUAccelerationofanEstablishedSolarMHDCodeus- ing OpenACC
Caplan, R.M., Linker, J.A., Mikić, Z., Downs, C., Török, T., Titov, V.S.,2019. GPUAccelerationofanEstablishedSolarMHDCodeus- ing OpenACC. Journal of Physics: Conference Series 1225, 012012. doi:10.1088/1742-6596/1225/1/012012
-
[4]
On Godunov-Type Methods for Gas Dynamics
Einfeldt, B., 1988. On Godunov-Type Methods for Gas Dynamics. SIAM Journal on Numerical Analysis 25, 294–318. doi:10.1137/ 0725021
work page 1988
-
[5]
Gottlieb,S.,Shu,C.W.,Tadmor,E.,2001.StrongStability-Preserving High-OrderTimeDiscretizationMethods. SIAMReview43,89–112. doi:10.1137/S003614450036757X
-
[6]
Harten,A.,Lax,P.D.,VanLeer,B.,1997. OnUpstreamDifferencing and Godunov-Type Schemes for Hyperbolic Conservation Laws, in: Hussaini, M.Y., Van Leer, B., Van Rosendale, J. (Eds.), Upwind and High-Resolution Schemes. Springer Berlin Heidelberg, Berlin, Heidelberg, pp. 53–79. doi:10.1007/978-3-642-60543-7_4
-
[7]
Efficient Implementation of Weighted ENO Schemes
Jiang, G.S., Shu, C.W., 1996. Efficient Implementation of Weighted ENO Schemes. Journal of Computational Physics 126, 202–228. doi:10.1006/jcph.1996.0130
-
[8]
2023, A&A, 673, A66, doi: 10.1051/0004-6361/202245359
Keppens,R.,PopescuBraileanu,B.,Zhou,Y.,Ruan,W.,Xia,C.,Guo, Y., Claes, N., Bacchini, F., 2023. MPI-AMRVAC 3.0: Updates to an open-source simulation framework. Astronomy & Astrophysics 673, A66. doi:10.1051/0004-6361/202245359
-
[9]
MPI-AMRVAC: A parallel, grid-adaptive PDE toolkit
Keppens,R.,Teunissen,J.,Xia,C.,Porth,O.,2021. MPI-AMRVAC: A parallel, grid-adaptive PDE toolkit. Computers & Mathematics with Applications 81, 316–333. doi:10.1016/j.camwa.2020.03.023
-
[10]
Koren, B., 1993. A robust upwind discretization method for ad- vection, diffusion and source terms, in: Vreugdenhil, C.B., Koren, B. (Eds.), Numerical Methods for Advection-Diffusion Problems. Braunschweig/Wiesbaden: Vieweg, pp. 117–138
work page 1993
-
[11]
Kraus, J., Schlottke, M., Adinetz, A., Pleiter, D., 2014. Accelerating a C++ CFD Code with OpenACC, in: 2014 First Workshop on AcceleratorProgrammingUsingDirectives,IEEE,NewOrleans,LA, USA. pp. 47–54. doi:10.1109/WACCPD.2014.11
-
[12]
IDEFIX: A versatile performance-portableGodunovcodeforastrophysicalflows
Lesur, G.R.J., Baghdadi, S., Wafflard-Fernandez, G., Mauxion, J., Robert, C.M.T., Van Den Bossche, M., 2023. IDEFIX: A versatile performance-portableGodunovcodeforastrophysicalflows. Astron- omy & Astrophysics 677, A9. doi:10.1051/0004-6361/202346005
-
[13]
Liska, M.T.P., Chatterjee, K., Issa, D., Yoon, D., Kaaz, N., Tchekhovskoy, A., Van Eijnatten, D., Musoke, G., Hesp, C., Rohoza, V., Markoff, S., Ingram, A., Van Der Klis, M., 2022. H-AMR: A New GPU-accelerated GRMHD Code for Exascale Computing with 3D Adaptive Mesh Refinement and Local Adaptive Time Stepping. The Astrophysical Journal Supplement Series 26...
work page 2022
-
[14]
An adaptive finite element scheme for transient problems in CFD
Lohner, R., 1987. An adaptive finite element scheme for transient problems in CFD. Computer Methods in Applied Mechanics and Engineering 61, 323–338. doi:10.1016/0045-7825(87)90098-3
-
[15]
Marowka, A., 2022. On the Performance Portability of OpenACC, OpenMP, Kokkos and RAJA, in: International Conference on High PerformanceComputinginAsia-PacificRegion,ACM,VirtualEvent Japan. pp. 103–114. doi:10.1145/3492805.3492806
-
[16]
McCall, A.J., Roy, C.J., 2017. A Multilevel Parallelism Approach with MPI and OpenACC for Complex CFD Codes, in: 23rd AIAA Computational Fluid Dynamics Conference, American Institute of Aeronautics and Astronautics, Denver, Colorado. doi:10.2514/6. 2017-3293
work page doi:10.2514/6 2017
-
[17]
Agile.https: //research-software-directory.org/projects/agile
Netherlands eScience Center, 2026. Agile.https: //research-software-directory.org/projects/agile. Accessed: 2026-04-16
work page 2026
-
[18]
The PLUTO Code on GPUs: A First Look at Eulerian MHD Methods
Rossazza, M., Mignone, A., Bugli, M., Truzzi, S., Riha, L., Panoc, T., Vysocky, O., Shukla, N., Romeo, A., Berta, V., 2025. The PLUTO Code on GPUs: A First Look at Eulerian MHD Methods. doi:10.48550/ARXIV.2511.20337
-
[19]
The calculation of the interaction of non- stationaryshockwaveswithbarriers
Rusanov, V.V., 1961. The calculation of the interaction of non- stationaryshockwaveswithbarriers. ZhurnalVychislitel’noiMatem- atiki i Matematicheskoi Fiziki 1, 267–279. Teunissen et al.:Preprint submitted to ElsevierPage 16 of 17 foap4: AMR with OpenACC, MPI, and p4est
work page 1961
-
[20]
Ruuth, S.J., Spiteri, R.J., 2004. High-Order Strong-Stability- Preserving Runge–Kutta Methods with Downwind-Biased Spatial Discretizations. SIAM Journal on Numerical Analysis 42, 974–996. doi:10.1137/S0036142902419284
-
[21]
Gamer-2: A GPU-accelerated adaptive mesh refinement code – accuracy, performance, and scalability
Schive, H.Y., ZuHone, J.A., Goldbaum, N.J., Turk, M.J., Gaspari, M., Cheng, C.Y., 2018. Gamer-2: A GPU-accelerated adaptive mesh refinement code – accuracy, performance, and scalability. Monthly Notices of the Royal Astronomical Society 481, 4815–4840. doi:10. 1093/mnras/sty2586
work page 2018
-
[22]
Stone, J.M., Mullen, P.D., Fielding, D., Grete, P., Guo, M., Kemp- ski, P., Most, E.R., White, C.J., Wong, G.N., 2024. AthenaK: A Performance-Portable Version of the Athena++ AMR Framework. doi:10.48550/arXiv.2409.16053,arXiv:2409.16053
-
[23]
Simulating streamer discharges in 3D with the parallel adaptive Afivo framework
Teunissen, J., Ebert, U., 2017. Simulating streamer discharges in 3D with the parallel adaptive Afivo framework. Journal of Physics D: Applied Physics 50, 474001. doi:10.1088/1361-6463/aa8faf
-
[24]
Computer Physics Communications 233, 156–166
Teunissen,J.,Ebert,U.,2018.Afivo:Aframeworkforquadtree/octree AMR with shared-memory parallelization and geometric multigrid methods. Computer Physics Communications 233, 156–166. doi:10. 1016/j.cpc.2018.06.018
work page 2018
-
[25]
The Kokkos EcoSystem: Comprehensive Performance Portability for High Performance Computing
Trott, C., Berger-Vergiat, L., Poliakoff, D., Rajamanickam, S., Lebrun-Grandie,D.,Madsen,J.,AlAwar,N.,Gligoric,M.,Shipman, G., Womeldorff, G., 2021. The Kokkos EcoSystem: Comprehensive Performance Portability for High Performance Computing. Com- puting in Science & Engineering 23, 10–18. doi:10.1109/MCSE.2021. 3098509
-
[26]
Towards the ultimate conservative difference scheme III
Van Leer, B., 1977. Towards the ultimate conservative difference scheme III. Upstream-centered finite-difference schemes for ideal compressible flow. Journal of Computational Physics 23, 263–275. doi:10.1016/0021-9991(77)90094-8
-
[27]
MPI-AMRVAC 2.0 for Solar and Astrophysical Applications
Xia, C., Teunissen, J., Mellah, I.E., Chané, E., Keppens, R., 2018. MPI-AMRVAC 2.0 for Solar and Astrophysical Applications. The Astrophysical Journal Supplement Series 234, 30. doi:10.3847/ 1538-4365/aaa6c8
work page 2018
-
[28]
An improved framework of GPU computing for CFD applications on structured grids using OpenACC
Xue, W., Jackson, C.W., Roy, C.J., 2021. An improved framework of GPU computing for CFD applications on structured grids using OpenACC. Journal of Parallel and Distributed Computing 156, 64–
work page 2021
-
[29]
doi:10.1016/j.jpdc.2021.05.010
-
[30]
Zhang, W., Almgren, A., Beckner, V., Bell, J., Blaschke, J., Chan, C., Day, M., Friesen, B., Gott, K., Graves, D., Katz, M., Myers, A., Nguyen, T., Nonaka, A., Rosso, M., Williams, S., Zingale, M.,
-
[31]
Journal of Open Source Software 4, 1370
AMReX: A framework for block-structured adaptive mesh refinement. Journal of Open Source Software 4, 1370. doi:10.21105/ joss.01370. Teunissen et al.:Preprint submitted to ElsevierPage 17 of 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.