Recognition: no theorem link
Toward Better Geometric Representations for Molecule Generative Models
Pith reviewed 2026-05-11 03:11 UTC · model grok-4.3
The pith
LENSEs improves molecule generation by training a representation head, perceptual loss, and node-level alignment to smooth pretrained encoder outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
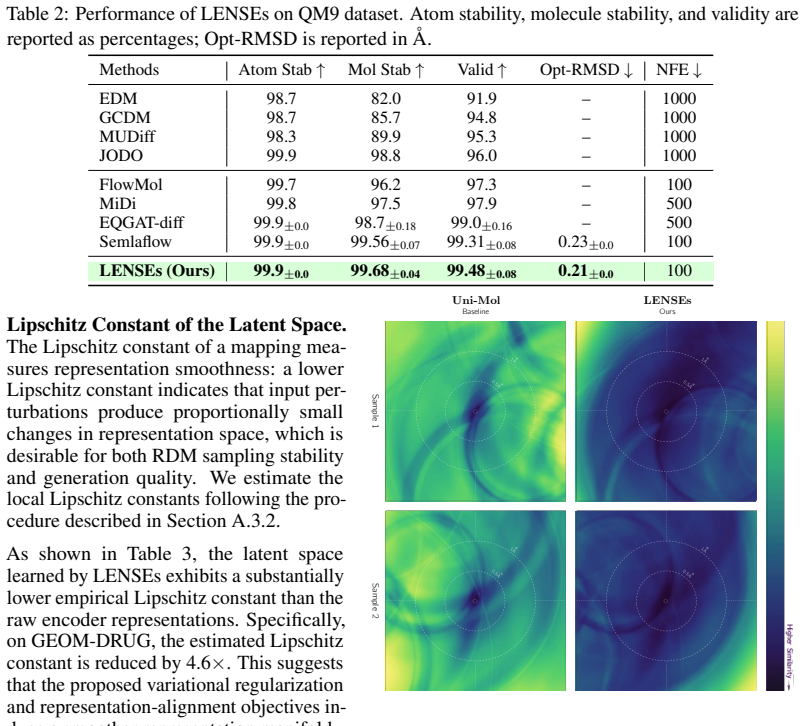
Pretrained molecular encoders produce non-smooth representations that limit generation quality. LENSEs counters this by simultaneously training a representation head for multi-level features, applying a molecule perceptual loss in the semantic space, and using a node-level representation alignment (REPA) loss to close the gap between pretraining and generation. On the GEOM-DRUG dataset this yields 97.28 percent validity and 98.51 percent molecule stability while also lowering the Lipschitz constant by a factor of 4.6 and improving performance on QM9 probing tasks, indicating that generative training with alignment objectives can serve as a pretraining paradigm for molecular encoders.
What carries the argument
The LENSEs framework consisting of a jointly trained representation head, molecule perceptual loss, and REPA alignment loss that refines pretrained geometric representations during generator training.
If this is right
- Molecule generators conditioned on refined representations achieve higher validity and stability on challenging datasets such as GEOM-DRUG.
- The Lipschitz constant of the learned mapping decreases substantially, producing smoother representation spaces.
- Probing tasks on QM9 show that the refined representations carry more semantic information for downstream molecular tasks.
- Generative training combined with alignment losses can function as an effective pretraining objective for molecular encoders.
Where Pith is reading between the lines
- The same alignment pattern could be tested on other pretrained encoders beyond UniMol to check whether non-smoothness is a general limitation.
- If the perceptual and alignment losses prove robust, they might reduce reliance on extensive hyperparameter searches when adapting new encoders to generation.
- The approach implicitly suggests that future encoder pretraining objectives should incorporate generative consistency as a regularizer.
Load-bearing premise
The observed gains in validity, stability, and smoothness arise primarily from the three proposed mechanisms rather than from baseline implementation differences or dataset-specific tuning choices.
What would settle it
Retraining the same generator on GEOM-DRUG after ablating any one of the three mechanisms (representation head, perceptual loss, or REPA) and finding that validity or stability falls below the previous state-of-the-art would falsify the central claim.
Figures





read the original abstract
Geometric representation-conditioned molecule generation provides an effective paradigm that decouples molecule representation modeling from structure generation. By decoupling molecule generation into two stages-first generating a meaningful molecule representation, and then generating a 3D molecule conditioned on this representation-the efficiency and quality of the generation process can be significantly enhanced. However, its effectiveness is fundamentally limited by the quality of the representation space: pretrained molecular encoders, such as UniMol, produce representations that are non-smooth and not fully exploited during the generative training process. In this work, we propose LENSEs, a framework that better exploits the potential of molecule representations in representation-conditioned generation methods. In particular, LENSEs introduces three complementary mechanisms: (1) a representation head, simultaneously trained during generative tasks, that extracts multi-level representations from the pretrained encoder; (2) a molecule perceptual loss that optimizes the generator in a semantic-informative representation space; and (3) a node-level representation alignment (REPA) loss that explicitly aligns the generator's hidden states with encoder representations, reducing the semantic gap between pretraining and generation. We demonstrate the effectiveness of these improvements through extensive molecule generation tasks. Specifically, on the challenging molecule generation dataset GEOM-DRUG, LENSEs achieves 97.28% validity and 98.51% molecule stability, surpassing existing advanced methods. Further analyses through Lipschitz constant reduction (4.6x) and QM9 probing tasks also demonstrate the smoother, more informative refined representations, establishing generative training with alignment objectives as a potential pretraining paradigm for molecular encoders.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LENSEs, a framework for improving geometric representations in molecule generative models by decoupling representation learning from structure generation. It proposes three mechanisms—a jointly trained representation head extracting multi-level features from pretrained encoders like UniMol, a molecule perceptual loss operating in semantic representation space, and a node-level REPA alignment loss to reduce the pretraining-generation semantic gap—and reports that these yield smoother, more informative representations. On the GEOM-DRUG dataset, LENSEs achieves 97.28% validity and 98.51% stability, outperforming prior methods, with supporting evidence from a 4.6x Lipschitz constant reduction and QM9 probing tasks; the work also suggests generative alignment as a potential pretraining paradigm for molecular encoders.
Significance. If the reported gains on GEOM-DRUG and the Lipschitz/QM9 analyses are shown to be causally attributable to the three proposed mechanisms rather than uncontrolled factors, the work would meaningfully advance representation-conditioned molecule generation by demonstrating how to better exploit pretrained encoders. The concrete metrics, explicit Lipschitz analysis, and suggestion of generative training as pretraining provide falsifiable claims that could influence follow-up work on smoother molecular latent spaces.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the headline claim that the three mechanisms (representation head, perceptual loss, REPA) are the primary drivers of the 97.28% validity / 98.51% stability on GEOM-DRUG is not supported by ablation studies that hold encoder weights, optimizer schedule, total compute, and data splits fixed while varying only the new components; without such controls, the attribution to smoother representations remains unverified.
- [Abstract] Abstract: the 4.6x Lipschitz constant reduction is presented as evidence of improved representation smoothness, but the manuscript does not specify the exact computation (e.g., which layers, finite-difference method, or sampling strategy) or whether the reduction persists when the generator is trained without the perceptual and REPA losses, weakening the link to the proposed mechanisms.
- [Experiments] Experiments section: baseline comparisons to prior advanced methods do not clarify whether those baselines were re-implemented with the identical UniMol encoder and training budget or taken directly from original publications; any mismatch in implementation details could account for the reported gains independently of the new losses.
minor comments (2)
- [Method] The equations defining the perceptual loss and REPA alignment loss would benefit from explicit notation for the weighting hyperparameters and the precise form of the alignment (e.g., cosine similarity or MSE on node embeddings) to aid reproducibility.
- [Experiments] Table reporting GEOM-DRUG metrics should include standard deviations over multiple runs and a column indicating whether each baseline uses the same pretrained encoder backbone.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications based on the manuscript and committing to revisions where the concerns identify gaps in detail or controls.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline claim that the three mechanisms (representation head, perceptual loss, REPA) are the primary drivers of the 97.28% validity / 98.51% stability on GEOM-DRUG is not supported by ablation studies that hold encoder weights, optimizer schedule, total compute, and data splits fixed while varying only the new components; without such controls, the attribution to smoother representations remains unverified.
Authors: We agree that isolating the causal contribution of the representation head, perceptual loss, and REPA requires ablations with all other factors fixed. The manuscript reports full LENSEs results against prior methods plus supporting Lipschitz and QM9 analyses, but does not include the exact controlled ablations described. In the revision we will add these experiments: the pretrained UniMol encoder weights will be held fixed, the optimizer schedule, total compute, and data splits will be identical, and we will vary only the presence of each new component (and combinations thereof). This will directly test attribution to the proposed mechanisms. revision: yes
-
Referee: [Abstract] Abstract: the 4.6x Lipschitz constant reduction is presented as evidence of improved representation smoothness, but the manuscript does not specify the exact computation (e.g., which layers, finite-difference method, or sampling strategy) or whether the reduction persists when the generator is trained without the perceptual and REPA losses, weakening the link to the proposed mechanisms.
Authors: We acknowledge the need for greater transparency on the Lipschitz analysis. The revised manuscript will specify the exact layers evaluated, the finite-difference procedure, and the sampling strategy over representations. We will also report the Lipschitz constant obtained when the generator is trained without the perceptual and REPA losses (while keeping all other settings identical). This will clarify whether the reported reduction is attributable to the alignment objectives. revision: yes
-
Referee: [Experiments] Experiments section: baseline comparisons to prior advanced methods do not clarify whether those baselines were re-implemented with the identical UniMol encoder and training budget or taken directly from original publications; any mismatch in implementation details could account for the reported gains independently of the new losses.
Authors: All baselines were re-implemented from scratch using the identical UniMol encoder, training budget, optimizer schedule, and data splits as LENSEs. The revised Experiments section will explicitly state this re-implementation protocol and list the shared hyperparameters to eliminate any ambiguity about implementation differences. revision: yes
Circularity Check
No circularity: empirical proposal with external benchmarks and no self-referential reductions.
full rationale
The paper introduces LENSEs as a framework with three mechanisms (representation head, perceptual loss, REPA alignment) trained jointly on top of a fixed pretrained encoder (UniMol). Performance claims are supported by direct evaluation on GEOM-DRUG (validity/stability metrics) and auxiliary analyses (Lipschitz constants, QM9 probing), none of which reduce by construction to fitted inputs or self-citations. No equations are presented that equate a 'prediction' to a parameter fit, and no uniqueness theorems or ansatzes are imported from prior author work. The derivation chain consists of standard generative modeling steps plus new loss terms whose effects are measured externally rather than defined into existence.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weighting hyperparameters
axioms (1)
- domain assumption Pretrained molecular encoders such as UniMol produce representations that are non-smooth and under-exploited in generative training.
Reference graph
Works this paper leans on
-
[1]
Deep generative molecular design reshapes drug discovery.Cell Reports Medicine, 3(12), 2022
Xiangxiang Zeng, Fei Wang, Yuan Luo, Seung-gu Kang, Jian Tang, Felice C Lightstone, Evandro F Fang, Wendy Cornell, Ruth Nussinov, and Feixiong Cheng. Deep generative molecular design reshapes drug discovery.Cell Reports Medicine, 3(12), 2022
work page 2022
-
[2]
Yu Cheng, Yongshun Gong, Yuansheng Liu, Bosheng Song, and Quan Zou. Molecular design in drug discovery: a comprehensive review of deep generative models.Briefings in bioinformatics, 22(6):bbab344, 2021
work page 2021
-
[3]
Xiangru Tang, Howard Dai, Elizabeth Knight, Fang Wu, Yunyang Li, Tianxiao Li, and Mark Gerstein. A survey of generative ai for de novo drug design: new frontiers in molecule and protein generation.Briefings in Bioinformatics, 25(4):bbae338, 2024
work page 2024
-
[4]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules.Journal of Chemical Information and Computer Sciences, 28 (1):31–36, 1988
work page 1988
-
[5]
Self-referencing embedded strings (selfies): A 100% robust molecular string representation
Mario Krenn, Florian Häse, AkshatKumar Nigam, Pascal Friederich, and Alan Aspuru-Guzik. Self-referencing embedded strings (selfies): A 100% robust molecular string representation. Machine Learning: Science and Technology, 1(4):045024, 2020
work page 2020
-
[6]
Austin H Cheng, Andy Cai, Santiago Miret, Gustavo Malkomes, Mariano Phielipp, and Alán Aspuru-Guzik. Group selfies: a robust fragment-based molecular string representation.Digital Discovery, 2(3):748–758, 2023
work page 2023
-
[7]
Emiel Hoogeboom, Víctor Garcia Satorras, Clement Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d.International Conference on Machine Learning, pages 9087–9102, 2022
work page 2022
-
[8]
arXiv preprint arXiv:2203.02923 , year=
Minkai Xu, Lantao Yu, Yang Song, Chence Shi, Stefano Ermon, and Jian Tang. Geodiff: A geo- metric diffusion model for molecular conformation generation.arXiv preprint arXiv:2203.02923, 2022
-
[9]
Deepan Adak, Yogesh Singh Rawat, and Shruti Vyas. Molvision: Molecular property prediction with vision language models.arXiv preprint arXiv:2507.03283, 2025
-
[10]
Zhanfeng Wang, Wenhao Zhang, Minghong Jiang, Yicheng Chen, Zhenyu Zhu, Wenjie Yan, Jianming Wu, and Xin Xu. X2-gnn: A physical message passing neural network with natural generalization ability to large and complex molecules.The Journal of Physical Chemistry Letters, 15(51):12501–12512, 2024
work page 2024
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
work page 2020
-
[12]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
Joseph L Watson, David Juergens, Nathaniel R Bennett, Brian L Trippe, Jason Yim, Helen E Eisenach, Woody Ahern, Andrew J Borst, Robert J Ragotte, Lukas F Milles, et al. De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
work page 2023
-
[15]
Gabriele Corso, Hannes Stärk, Bowen Jing, Regina Barzilay, and Tommi Jaakkola. Diffdock: Diffusion steps, twists, and turns for molecular docking.arXiv preprint arXiv:2210.01776, 2022
-
[16]
W Patrick Walters and Regina Barzilay. Applications of deep learning in molecule generation and molecular property prediction.Accounts of chemical research, 54(2):263–270, 2020
work page 2020
-
[17]
Gary Tom, Stefan P Schmid, Sterling G Baird, Yang Cao, Kourosh Darvish, Han Hao, Stanley Lo, Sergio Pablo-García, Ella M Rajaonson, Marta Skreta, et al. Self-driving laboratories for chemistry and materials science.Chemical Reviews, 124(16):9633–9732, 2024. 11
work page 2024
-
[18]
Advances and challenges in deep generative models for de novo molecule generation
Dongyu Xue, Yukang Gong, Zhaoyi Yang, Guohui Chuai, Sheng Qu, Aizong Shen, Jing Yu, and Qi Liu. Advances and challenges in deep generative models for de novo molecule generation. Wiley Interdisciplinary Reviews: Computational Molecular Science, 9(3):e1395, 2019
work page 2019
-
[19]
Flowmol3: flow matching for 3d de novo small-molecule generation.Digital Discovery, 2026
Ian Dunn and David R Koes. Flowmol3: flow matching for 3d de novo small-molecule generation.Digital Discovery, 2026
work page 2026
-
[20]
Cheng Zeng, Jirui Jin, Connor Ambrose, George Karypis, Mark Transtrum, Ellad B Tadmor, Richard G Hennig, Adrian Roitberg, Stefano Martiniani, and Mingjie Liu. Propmolflow: property-guided molecule generation with geometry-complete flow matching.Nature Computa- tional Science, pages 1–10, 2026
work page 2026
-
[21]
Danny Reidenbach, Filipp Nikitin, Olexandr Isayev, and Saee Gopal Paliwal. Applications of modular co-design for de novo 3d molecule generation.Digital Discovery, 5(2):754–768, 2026
work page 2026
-
[22]
3d molecule generation from rigid motifs via se (3) flows.arXiv preprint arXiv:2601.16955, 2026
Roman Poletukhin, Marcel Kollovieh, Eike Eberhard, and Stephan Günnemann. 3d molecule generation from rigid motifs via se (3) flows.arXiv preprint arXiv:2601.16955, 2026
-
[23]
Francesca Grisoni, Michael Moret, Robin Lingwood, and Gisbert Schneider. Bidirectional molecule generation with recurrent neural networks.Journal of chemical information and modeling, 60(3):1175–1183, 2020
work page 2020
-
[24]
Geometric latent diffusion models for 3d molecule generation
Minkai Xu, Alexander S Powers, Ron O Dror, Stefano Ermon, and Jure Leskovec. Geometric latent diffusion models for 3d molecule generation. InInternational Conference on Machine Learning, pages 38592–38610. PMLR, 2023
work page 2023
-
[25]
Zian Li, Cai Zhou, Xiyuan Wang, Xingang Peng, and Muhan Zhang. Geometric representation condition improves equivariant molecule generation.arXiv preprint arXiv:2410.03655, 2024
-
[26]
Diffusion model as representation learner
Xingyi Yang and Xinchao Wang. Diffusion model as representation learner. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18938–18949, 2023
work page 2023
-
[27]
Uni-mol: A universal 3d molecular representation learning framework
Gengmo Zhou, Zhifeng Gao, Qiankun Ding, Hang Zheng, Hongteng Xu, Zhewei Wei, Linfeng Zhang, and Guolin Ke. Uni-mol: A universal 3d molecular representation learning framework. International Conference on Learning Representations, 2023
work page 2023
-
[28]
Shikun Feng, Zhi Ni, Yanyan Lan, Zhi-Ming Ma, and Wei-Ying Ma. Fractional denoising for 3d molecular pre-training.International Conference on Machine Learning, 2023
work page 2023
-
[29]
Tianhong Li, Dina Katabi, and Kaiming He. Return of unconditional generation: A self- supervised representation generation method.Advances in Neural Information Processing Systems, 37:125441–125468, 2024
work page 2024
-
[30]
Shaoheng Yan, Zian Li, and Muhan Zhang. Georecon: Graph-level representation learning for 3d molecules via reconstruction-based pretraining.arXiv preprint arXiv:2506.13174, 2025
-
[31]
Rong Yin, Ruyue Liu, Xiaoshuai Hao, Xingrui Zhou, Yong Liu, Can Ma, and Weiping Wang. Multi-modal molecular representation learning via structure awareness.IEEE Transactions on Image Processing, 2025
work page 2025
-
[32]
Image style transfer using convolutional neural networks
Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2414–2423, 2016
work page 2016
-
[33]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017
work page 2017
-
[34]
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution.European Conference on Computer Vision, pages 694–711, 2016
work page 2016
-
[35]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024. 12
work page internal anchor Pith review arXiv 2024
-
[36]
Cai Zhou, Zijie Chen, Zian Li, Jike Wang, Kaiyi Jiang, Pan Li, Rose Yu, Muhan Zhang, Stephen Bates, and Tommi Jaakkola. Rethinking diffusion models with symmetries through canoni- calization with applications to molecular graph generation.arXiv preprint arXiv:2602.15022, 2026
-
[37]
Alex Morehead and Jianlin Cheng. Geometry-complete diffusion for 3D molecule gen- eration and optimization.Communications Chemistry, 7(1):150, 2024. doi: 10.1038/ s42004-024-01233-z
work page 2024
-
[38]
Clement Vignac, Nagham Osman, Laura Toni, and Pascal Frossard. Midi: Mixed graph and 3d denoising diffusion for molecule generation.European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2023
work page 2023
-
[39]
Yuxuan Song, Jingjing Gong, Minkai Xu, Ziyao Cao, Yanyan Lan, Stefano Ermon, Hao Zhou, and Wei-Ying Ma. Equivariant flow matching with hybrid probability transport for 3d molecule generation.Advances in Neural Information Processing Systems, 36:549–568, 2023
work page 2023
-
[40]
Haokai Hong, Wanyu Lin, and Kay Chen Tan. Accelerating 3d molecule generation via jointly geometric optimal transport.arXiv preprint arXiv:2405.15252, 2024
-
[41]
arXiv preprint arXiv:2303.03543 , year=
Jiaqi Guan, Wesley Wei Qian, Xingang Peng, Yufeng Su, Jian Peng, and Jianzhu Ma. 3d equivariant diffusion for target-aware molecule generation and affinity prediction.arXiv preprint arXiv:2303.03543, 2023
-
[42]
Arne Schneuing, Charles Harris, Yuanqi Du, Kieran Didi, Arian Jamasb, Ilia Igashov, Weitao Du, Carla Gomes, Tom L Blundell, Pietro Lio, et al. Structure-based drug design with equivariant diffusion models.Nature Computational Science, 4(12):899–909, 2024
work page 2024
-
[43]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[44]
Geometric latent diffusion models for 3D molecule generation
Minkai Xu, Alexander Powers, Ron Dror, Stefano Ermon, and Jure Leskovec. Geometric latent diffusion models for 3D molecule generation. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 38592–38610. PMLR, 2023
work page 2023
-
[45]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[46]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
work page 2023
-
[47]
Spin-nerf: Multiview segmen- tation and perceptual inpainting with neural radiance fields
Ashkan Mirzaei, Tristan Aumentado-Armstrong, Konstantinos G Derpanis, Jonathan Kelly, Marcus A Brubaker, Igor Gilitschenski, and Alex Levinshtein. Spin-nerf: Multiview segmen- tation and perceptual inpainting with neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20669–20679, 2023
work page 2023
-
[48]
Learning diffusion models with flexible representation guidance
Chenyu Wang, Cai Zhou, Sharut Gupta, Zongyu Lin, Stefanie Jegelka, Stephen Bates, and Tommi Jaakkola. Learning diffusion models with flexible representation guidance. InICML 2025 Generative AI and Biology (GenBio) Workshop, 2025. URL https://openreview. net/forum?id=o2W4FTtBVJ
work page 2025
-
[49]
Sheheryar Zaidi, Michael Schaarschmidt, James Martens, Hyunjik Kim, Yee Whye Teh, Alvaro Sanchez-Gonzalez, Peter Battaglia, Razvan Pascanu, and Jonathan Godwin. Pre-training via denoising for molecular property prediction.arXiv preprint arXiv:2206.00133, 2022
-
[50]
Tynan Perez and Rafael Gomez-Bombarelli. Self-conditioned denoising for atomistic represen- tation learning.arXiv preprint arXiv:2603.17196, 2026
-
[51]
Quantum chemistry structures and properties of 134 kilo molecules.Scientific Data, 1(1):1–7, 2014
Raghunathan Ramakrishnan, Pavlo O Dral, Matthias Rupp, and O Anatole von Lilienfeld. Quantum chemistry structures and properties of 134 kilo molecules.Scientific Data, 1(1):1–7, 2014. 13
work page 2014
-
[52]
Auto-encoding variational bayes.International Confer- ence on Learning Representations, 2014
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.International Confer- ence on Learning Representations, 2014
work page 2014
-
[53]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review arXiv 2013
-
[54]
Simon Axelrod and Rafael Gomez-Bombarelli. Geom, energy-annotated molecular conforma- tions for property prediction and molecular generation.Scientific Data, 9(1):185, 2022
work page 2022
-
[55]
Ross Irwin, Alessandro Tibo, Jon Paul Janet, and Simon Olsson. Semlaflow–efficient 3d molecular generation with latent attention and equivariant flow matching.arXiv preprint arXiv:2406.07266, 2024
-
[56]
Ian Dunn and David Ryan Koes. Mixed continuous and categorical flow matching for 3d de novo molecule generation.ArXiv, pages arXiv–2404, 2024
work page 2024
-
[57]
Han Huang, Leilei Sun, Bowen Du, and Weifeng Lv. Learning joint 2d & 3d diffusion models for complete molecule generation.arXiv preprint arXiv:2305.12347, 2023
-
[58]
Tuan Le, Julian Cremer, Frank Noe, Djork-Arné Clevert, and Kristof Schütt. Navigating the design space of equivariant diffusion-based generative models for de novo 3d molecule generation.arXiv preprint arXiv:2309.17296, 2023
-
[59]
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In 2007 15th European signal processing conference, pages 606–610. IEEE, 2007. 14 Appendix Contents Appendix Contents 15 A Methods and Algorithms 16 A.1 Additional Implementation Details . . . . . . . . . . . . . . . . . . . . . . . . . . 16 A.2 Training Algorithm ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.