Recognition: 2 theorem links
· Lean TheoremBayesian Fine-tuning in Projected Subspaces
Pith reviewed 2026-05-11 01:57 UTC · model grok-4.3
The pith
Bayesian fine-tuning works effectively when weights are projected into very low-dimensional subspaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Effective uncertainty quantification can be achieved in very low-dimensional parameter spaces obtained by projecting the weight space, allowing a parameter-efficient Bayesian fine-tuning method that maintains computational efficiency, improves calibration and generalization, and exploits the low-rank nature of weight covariances in the projected space.
What carries the argument
The projection of the weight space into low-dimensional subspaces combined with modeling uncertainty via low-rank covariance matrices.
If this is right
- Models achieve better calibration and generalization than standard LoRA or other Bayesian variants.
- The number of trainable parameters remains low, preserving efficiency gains.
- Training converges more stably without the instability seen in higher-parameter Bayesian methods.
- Uncertainty can be quantified effectively without offsetting the original benefits of low-rank adaptation.
Where Pith is reading between the lines
- This suggests that similar projections could apply to other parameter-efficient methods beyond LoRA for adding Bayesian features.
- Low-rank covariances in subspaces might generalize to other uncertainty modeling tasks in deep learning.
- Practitioners could test these projections on different model architectures to see if the low-dimensional property holds broadly.
Load-bearing premise
There exists an appropriate projection of the weight space into a very low-dimensional space where uncertainty can be modeled to yield effective Bayesian fine-tuning with improved calibration and generalization.
What would settle it
A counterexample where no such projection exists that maintains or improves performance over non-Bayesian low-rank methods, or where covariances in the projected space are not low-rank.
Figures




read the original abstract
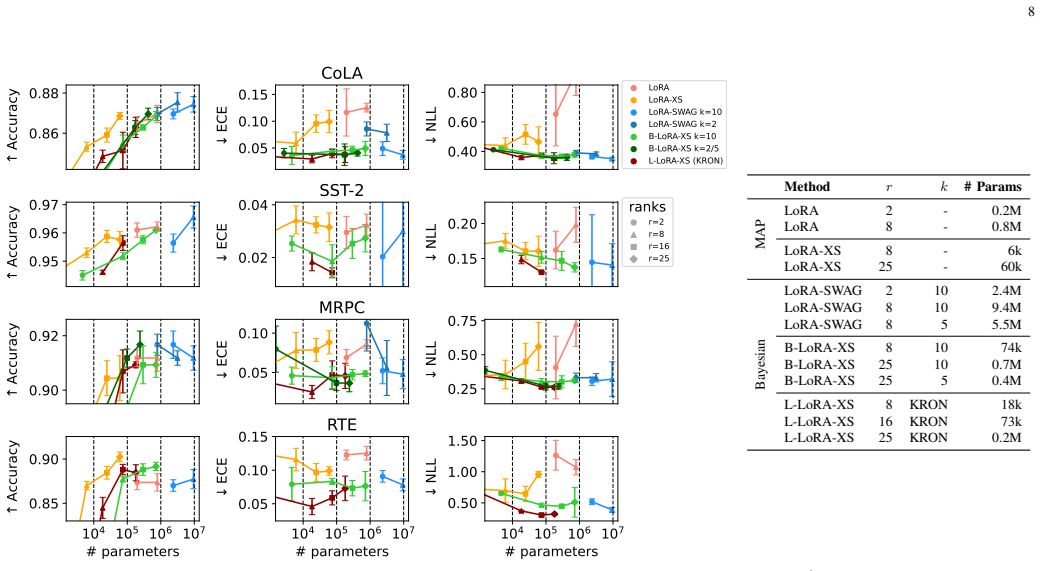
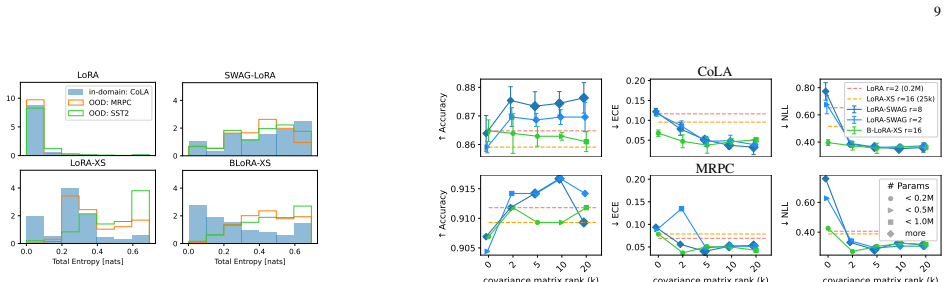
Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning of large models by decomposing weight updates into low-rank matrices, significantly reducing storage and computational overhead. While effective, standard LoRA lacks mechanisms for uncertainty quantification, leading to overconfident and poorly calibrated models. Bayesian variants of LoRA address this limitation, but at the cost of a significantly increased number of trainable parameters, partially offsetting the original efficiency gains. Additionally, these models are harder to train and may suffer from unstable convergence. In this work, we propose a novel framework for parameter-efficient Bayesian fine-tuning, demonstrating that effective uncertainty quantification can be achieved in very low-dimensional parameter spaces. The proposed method achieves strong performance with improved calibration and generalization while maintaining computational efficiency. Our empirical findings show that, with the appropriate projection of the weight space uncertainty can be effectively modeled in a low-dimensional space, and weight covariances exhibit low ranks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for parameter-efficient Bayesian fine-tuning of large models by projecting the weight space into low-dimensional subspaces, where uncertainty can be modeled effectively. It claims this yields improved calibration and generalization over standard LoRA and full Bayesian LoRA variants while preserving efficiency, supported by empirical findings that weight covariances exhibit low ranks under an appropriate projection.
Significance. If the results hold, this could advance scalable Bayesian methods for fine-tuning foundation models by mitigating the parameter overhead of Bayesian LoRA. The low-rank covariance observation in projected spaces offers a potentially useful insight for posterior geometry in overparameterized networks.
major comments (2)
- Abstract: The central claim that 'with the appropriate projection of the weight space uncertainty can be effectively modeled in a low-dimensional space' is load-bearing but provides no generalizable, data-independent procedure for selecting the projection (e.g., via Hessian or gradient covariance). This risks circularity or offsetting pre-computation costs, directly affecting the efficiency and generalization assertions.
- §4 (Experiments): The reported strong performance, low-rank covariances, and calibration gains lack explicit quantitative metrics (e.g., ECE, accuracy deltas), baseline comparisons to Bayesian LoRA, error bars over runs, and ablations on alternative subspace choices, making it impossible to verify robustness independent of task-specific data.
minor comments (3)
- Introduction: The related work discussion should explicitly contrast the proposed projection with prior subspace methods for Bayesian inference to clarify novelty.
- Notation: Define the projection operator and low-dimensional covariance explicitly with equations early in the method section for clarity.
- Figures: Add labels, legends, and full-space comparisons to any covariance rank plots to improve interpretability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify our work. We address each major comment below, indicating where revisions will be made to improve clarity, rigor, and completeness.
read point-by-point responses
-
Referee: Abstract: The central claim that 'with the appropriate projection of the weight space uncertainty can be effectively modeled in a low-dimensional space' is load-bearing but provides no generalizable, data-independent procedure for selecting the projection (e.g., via Hessian or gradient covariance). This risks circularity or offsetting pre-computation costs, directly affecting the efficiency and generalization assertions.
Authors: We agree that the abstract states the central claim without specifying a selection procedure, which leaves the efficiency claims open to the concerns raised. The manuscript's primary contribution is the empirical observation that weight covariances exhibit low rank under suitable projections, enabling effective Bayesian modeling. To address this directly, we will revise the abstract to note that the projection is constructed via a standard, low-cost data-driven method (principal components of the gradient covariance on a small data subset) and add a concise description of this procedure, along with a cost analysis, in the methods section. This revision will eliminate any appearance of circularity while preserving the paper's focus. revision: yes
-
Referee: §4 (Experiments): The reported strong performance, low-rank covariances, and calibration gains lack explicit quantitative metrics (e.g., ECE, accuracy deltas), baseline comparisons to Bayesian LoRA, error bars over runs, and ablations on alternative subspace choices, making it impossible to verify robustness independent of task-specific data.
Authors: The experiments do include comparisons against standard LoRA and Bayesian LoRA variants along with calibration and performance metrics, but we accept that the presentation lacks sufficient explicit quantitative details such as accuracy/ECE deltas, error bars across multiple seeds, and ablations on alternative projections. We will expand Section 4 with tables reporting these deltas, standard deviations from repeated runs, and additional ablations (e.g., random versus gradient-based subspaces) to allow independent verification of robustness. These changes will be incorporated in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and claims present a novel framework for Bayesian fine-tuning via projected subspaces, supported by empirical findings on low-rank covariances and improved calibration. No load-bearing derivations, equations, self-citations, or fitted parameters are quoted that reduce any prediction to its inputs by construction. The central assertion relies on observed low-rank structure after projection rather than self-definitional or tautological steps. This is consistent with a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
work page 2022
- [2]
-
[3]
Z. Jiang, J. Araki, H. Ding, and G. Neubig, “How can we know when language models know? on the calibration of language models for question answering,”Transactions of the Association for Computational Linguistics, vol. 9, pp. 962–977, 2021
work page 2021
-
[4]
K. Tian, E. Mitchell, A. Zhou, A. Sharma, R. Rafailov, H. Yao, C. Finn, and C. Manning, “Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computational Lin...
work page 2023
-
[5]
Uncertainty quantification with pre-trained language models: A large-scale empirical analysis,
Y . Xiao, P. P. Liang, U. Bhatt, W. Neiswanger, R. Salakhutdinov, and L.-P. Morency, “Uncertainty quantification with pre-trained language models: A large-scale empirical analysis,” inEMNLP, 2022. 12
work page 2022
-
[6]
Preserving pre-trained features helps calibrate fine-tuned language models,
G. He, J. Chen, and J. Zhu, “Preserving pre-trained features helps calibrate fine-tuned language models,” inInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[7]
Weight uncertainty in neural network,
C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra, “Weight uncertainty in neural network,” inInternational Conference on Machine Learning. PMLR, 2015, pp. 1613–1622
work page 2015
-
[8]
Being bayesian, even just a bit, fixes overconfidence in relu networks,
A. Kristiadi, M. Hein, and P. Hennig, “Being bayesian, even just a bit, fixes overconfidence in relu networks,” inProceedings of the 37th International Conference on Machine Learning, 2020
work page 2020
-
[9]
L. Aitchison, A. Yang, and S. W. Ober, “Deep kernel processes,” in International Conference on Machine Learning. PMLR, 2021, pp. 130–140
work page 2021
-
[10]
What are bayesian neural network posteriors really like?
P. Izmailov, S. Vikram, M. D. Hoffman, and A. G. G. Wilson, “What are bayesian neural network posteriors really like?” inInternational Conference on Machine Learning. PMLR, 2021, pp. 4629–4640
work page 2021
-
[11]
Gaussian stochastic weight averaging for bayesian low-rank adaptation of large language models,
E. Onal, K. Fl ¨oge, E. Caldwell, A. Sheverdin, and V . Fortuin, “Gaussian stochastic weight averaging for bayesian low-rank adaptation of large language models,” inSixth Symposium on Advances in Approximate Bayesian Inference - Non Archival Track, 2024
work page 2024
-
[12]
Bayesian low-rank adaptation for large language models,
A. Yang, M. Robeyns, X. Wang, and L. Aitchison, “Bayesian low-rank adaptation for large language models,” inInternational Conference on Representation Learning, vol. 2024, 2024, pp. 1812–1842
work page 2024
-
[13]
Bayesian low-rank learning (bella): A practical approach to bayesian neural networks,
B. G. Doan, A. Shamsi, X.-Y . Guo, A. Mohammadi, H. Alinejad- Rokny, D. Sejdinovic, D. Teney, D. C. Ranasinghe, and E. Abbasnejad, “Bayesian low-rank learning (bella): A practical approach to bayesian neural networks,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 15, pp. 16 298–16 307, 2025
work page 2025
-
[14]
Minimal ranks, maximum confidence: Parameter-efficient uncertainty quantification for LoRA,
P. Marszałek, K. Bałazy, J. Tabor, and T. Ku´smierczyk, “Minimal ranks, maximum confidence: Parameter-efficient uncertainty quantification for LoRA,” inFindings of the Association for Computational Linguistics: EMNLP 2025. Suzhou, China: Association for Computational Linguistics, Nov. 2025, pp. 1260–1271. [Online]. Available: https: //aclanthology.org/202...
work page 2025
-
[15]
Predictive uncertainty estimation via prior networks,
A. Malinin and M. Gales, “Predictive uncertainty estimation via prior networks,” inAdvances in Neural Information Processing Systems, vol. 31. Curran Associates, Inc., 2018
work page 2018
-
[16]
A multilinear singular value decomposition,
L. De Lathauwer, B. De Moor, and J. Vandewalle, “A multilinear singular value decomposition,”SIAM Journal on Matrix Analysis and Applications, vol. 21, no. 4, pp. 1253–1278, 2000
work page 2000
-
[17]
Subspace inference for bayesian deep learning,
P. Izmailov, W. J. Maddox, P. Kirichenko, T. Garipov, D. Vetrov, and A. G. Wilson, “Subspace inference for bayesian deep learning,” in Uncertainty in Artificial Intelligence. PMLR, 2020, pp. 1169–1179
work page 2020
-
[18]
arXiv preprint arXiv:2405.17604 , year=
K. Bałazy, M. Banaei, K. Aberer, and J. Tabor, “LoRA-XS: Low-rank adaptation with extremely small number of parameters,”arXiv preprint arXiv:2405.17604, 2024
-
[19]
Asvd: Activation-aware singular value decomposition for compressing large language models,
Z. Yuan, Y . Shang, Y . Song, D. Yang, Q. Wu, Y . Yan, and G. Sun, “Asvd: Activation-aware singular value decomposition for compressing large language models,”arXiv preprint arXiv:2312.05821, 2023
-
[20]
Svd-llm: Truncation- aware singular value decomposition for large language model com- pression,
X. Wang, Y . Zheng, Z. Wan, and M. Zhang, “Svd-llm: Truncation-aware singular value decomposition for large language model compression,” arXiv preprint arXiv:2403.07378, 2024
-
[21]
Note on a method for calculating corrected sums of squares and products,
B. P. Welford, “Note on a method for calculating corrected sums of squares and products,”Technometrics, vol. 4, no. 3, pp. 419–420, 1962
work page 1962
-
[22]
Algorithms for computing the sample variance: Analysis and recommendations,
T. F. Chan, G. H. Golub, and R. J. LeVeque, “Algorithms for computing the sample variance: Analysis and recommendations,”The American Statistician, vol. 37, no. 3, pp. 242–247, 1983
work page 1983
-
[23]
N. Ahmed, T. Natarajan, and K. R. Rao, “Discrete cosine transform,” IEEE transactions on Computers, vol. 100, no. 1, pp. 90–93, 1974
work page 1974
-
[24]
A. V . Oppenheim,Discrete-time signal processing. Pearson Education India, 1999
work page 1999
-
[25]
K. R. Rao and P. Yip,Discrete cosine transform: algorithms, advantages, applications. Academic press, 2014
work page 2014
-
[26]
N. Halko, P. G. Martinsson, and J. A. Tropp, “Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions,”SIAM Review, vol. 53, no. 2, pp. 217–288, 2011
work page 2011
-
[27]
The efficient generation of random orthogonal matrices with an application to condition estimators,
G. W. Stewart, “The efficient generation of random orthogonal matrices with an application to condition estimators,”SIAM Journal on Numerical Analysis, vol. 17, no. 3, pp. 403–409, 1980
work page 1980
-
[28]
Distributions of matrix variates and latent roots derived from normal samples,
A. T. James, “Distributions of matrix variates and latent roots derived from normal samples,”The Annals of Mathematical Statistics, vol. 35, no. 2, pp. 475–501, 1964
work page 1964
-
[29]
Ledoux,The concentration of measure phenomenon
M. Ledoux,The concentration of measure phenomenon. American Mathematical Soc., 2001, no. 89
work page 2001
-
[30]
A simple baseline for bayesian uncertainty in deep learning,
W. J. Maddox, P. Izmailov, T. Garipov, D. P. Vetrov, and A. G. Wilson, “A simple baseline for bayesian uncertainty in deep learning,” inAdvances in Neural Information Processing Systems, vol. 32. Curran Associates, Inc., 2019
work page 2019
-
[31]
A scalable laplace approximation for neural networks,
H. Ritter, A. Botev, and D. Barber, “A scalable laplace approximation for neural networks,” inICLR, 2018
work page 2018
-
[32]
Laplace redux-effortless bayesian deep learning,
E. Daxberger, A. Kristiadi, A. Immer, R. Eschenhagen, M. Bauer, and P. Hennig, “Laplace redux-effortless bayesian deep learning,”NeurIPS, 2021
work page 2021
-
[33]
Adapting the linearised laplace model evidence for modern deep learning,
J. Antor ´an, D. Janz, J. U. Allingham, E. Daxberger, R. R. Barbano, E. Nalisnick, and J. M. Hern ´andez-Lobato, “Adapting the linearised laplace model evidence for modern deep learning,” inICML, 2022
work page 2022
-
[34]
GLUE: A multi-task benchmark and analysis platform for natural language understanding,
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. Bowman, “GLUE: A multi-task benchmark and analysis platform for natural language understanding,” inProceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. Brussels, Belgium: Association for Computational Linguistics, 2018, pp. 353–355
work page 2018
-
[35]
Roberta: A robustly optimized bert pretraining approach,
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” 2019
work page 2019
-
[36]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Villani,Optimal Transport: Old and New, ser
C. Villani,Optimal Transport: Old and New, ser. Grundlehren der mathematischen Wissenschaften. Springer Berlin Heidelberg, 2008
work page 2008
-
[38]
An introduction to roc analysis,
T. Fawcett, “An introduction to roc analysis,”Pattern Recognition Letters, vol. 27, no. 8, pp. 861–874, 2006, rOC Analysis in Pattern Recognition
work page 2006
-
[39]
Parameter-efficient transfer learning for nlp,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for nlp,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 2790–2799
work page 2019
-
[40]
Parameter-efficient transfer learning with diff pruning,
D. Guo, A. Rush, and Y . Kim, “Parameter-efficient transfer learning with diff pruning,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Online: Association for Computational Linguistics, 2021, pp. 4884–4896
work page 2021
-
[41]
Prefix-tuning: Optimizing continuous prompts for generation,
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Online: Association for Computational Linguistics, 2021, pp. 4582–4597
work page 2021
-
[42]
The power of scale for parameter-efficient prompt tuning,
B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” inProceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Processing. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021, pp. 3045–3059
work page 2021
-
[43]
Vera: Vector-based random matrix adaptation,
D. J. Kopiczko, T. Blankevoort, and Y . M. Asano, “Vera: Vector-based random matrix adaptation,” inInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[44]
Adaptive budget allocation for parameter-efficient fine-tuning,
Q. Zhang, M. Chen, A. Bukharin, P. He, Y . Cheng, W. Chen, and T. Zhao, “Adaptive budget allocation for parameter-efficient fine-tuning,” inThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[45]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[46]
BLob: Bayesian low-rank adaptation by backpropagation for large language models,
Y . Wang, H. Shi, L. Han, D. N. Metaxas, and H. Wang, “BLob: Bayesian low-rank adaptation by backpropagation for large language models,” inThe 38-th Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[47]
C. Meo, K. Sycheva, A. Goyal, and J. Dauwels, “Bayesian-loRA: LoRA based parameter efficient fine-tuning using optimal quantization levels and rank values trough differentiable bayesian gates,” in2nd Workshop on Advancing Neural Network Training: Computational Efficiency, Scal- ability, and Resource Optimization (WANT@ICML 2024), 2024
work page 2024
-
[48]
The training process of many deep networks explores the same low-dimensional manifold,
J. Mao, I. Griniasty, H. K. Teoh, R. Ramesh, R. Yang, M. K. Transtrum, J. P. Sethna, and P. Chaudhari, “The training process of many deep networks explores the same low-dimensional manifold,”Proceedings of the National Academy of Sciences, vol. 121, no. 12, p. e2310002121, 2024
work page 2024
-
[49]
Bayesian deep learning via subnetwork inference,
E. Daxberger, E. Nalisnick, J. U. Allingham, J. Antor ´an, and J. M. Hern´andez-Lobato, “Bayesian deep learning via subnetwork inference,” inICML, 2021
work page 2021
-
[50]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019. 13
work page 2019
-
[51]
Position: Curvature matrices should be democratized via linear operators,
F. Dangel, R. Eschenhagen, W. Ormaniec, A. Fernandez, L. Tatzel, and A. Kristiadi, “Position: Curvature matrices should be democratized via linear operators,”arXiv 2501.19183, 2025
-
[52]
Asdl: A unified interface for gradient preconditioning in pytorch,
K. Osawa, S. Ishikawa, R. Yokota, S. Li, and T. Hoefler, “Asdl: A unified interface for gradient preconditioning in pytorch,” 2023. [Online]. Available: https://arxiv.org/abs/2305.04684
-
[53]
Transformers: State-of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. Le Scao, S. Gugger, M. Drame, Q. Lhoest, and A. Rush, “Transformers: State-of-the-art natural language processing,” inProceedings of the 2020 Conference on Empirical Method...
work page 2020
-
[54]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017. 1 Supplementary Material for: Bayesian Fine-tuning in Projected Subspaces Viktar Dubovik, Patryk Marszałek, Jacek Tabor, and Tomas...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.