Recognition: 2 theorem links
· Lean TheoremFlexible Routing via Uncertainty Decomposition
Pith reviewed 2026-05-11 03:10 UTC · model grok-4.3
The pith
Decomposing uncertainty into reducible and irreducible components lets one router choose cheap models, oracles, or abstention and adapt to new costs without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that decomposing total uncertainty into its reducible and irreducible components via higher-order predictors yields a unified routing and abstention policy: predict with the weak model on low uncertainty, route to the oracle on high reducible uncertainty, and abstain on high irreducible uncertainty. This policy applies to any classification setting with multiple independent annotations per input, adapts to arbitrary loss and cost parameters through hyperparameter changes alone, and satisfies regret bounds against optimal per-task routers.
What carries the argument
Decomposition of total uncertainty into reducible uncertainty (resolvable by a stronger model) and irreducible uncertainty (inherent ambiguity) performed with higher-order predictors; this split drives the three-way decision and enables the regret analysis.
Load-bearing premise
Multiple independent annotations per input must exist to estimate the uncertainty components, and the reducible and irreducible uncertainties must not be too strongly correlated.
What would settle it
Measure actual regret against the optimal per-task router on a synthetic dataset constructed so that the decomposition is exact and the two uncertainty types are uncorrelated; if regret exceeds the stated bound or if the router fails to improve over a fixed policy, the central claim is false.
Figures

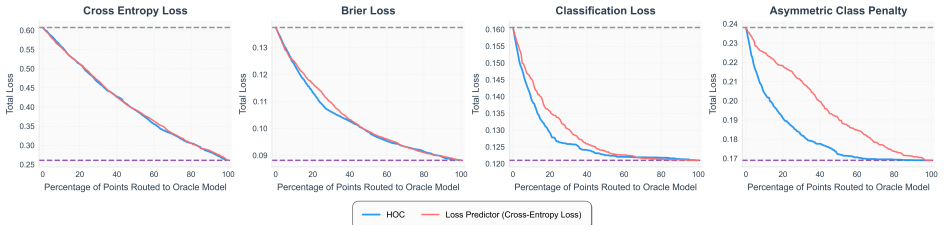

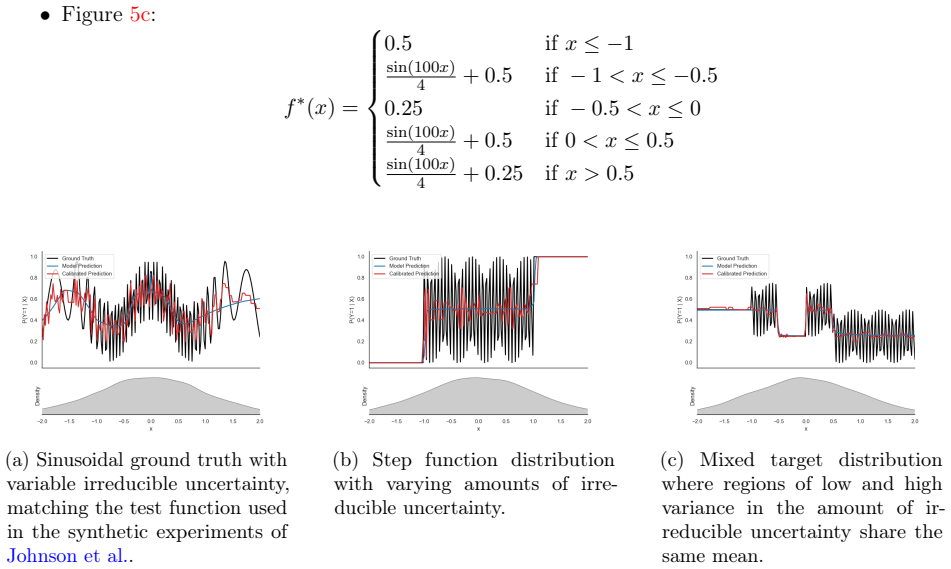






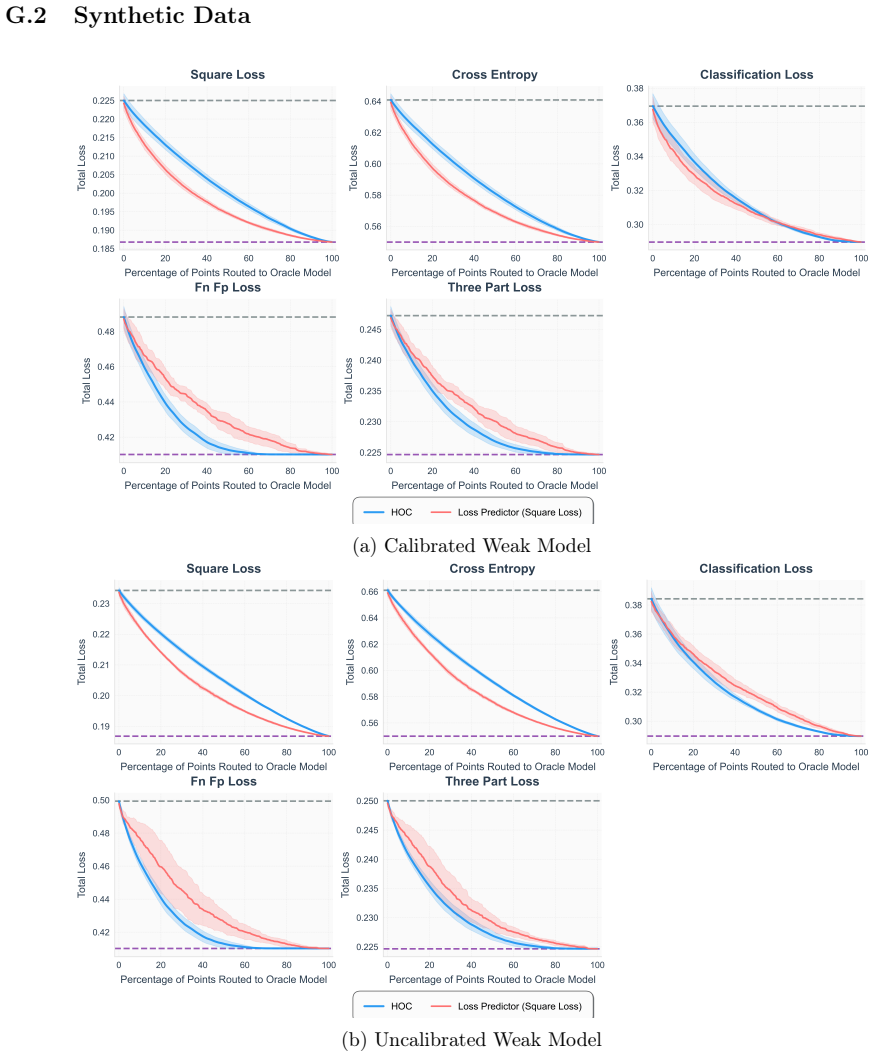
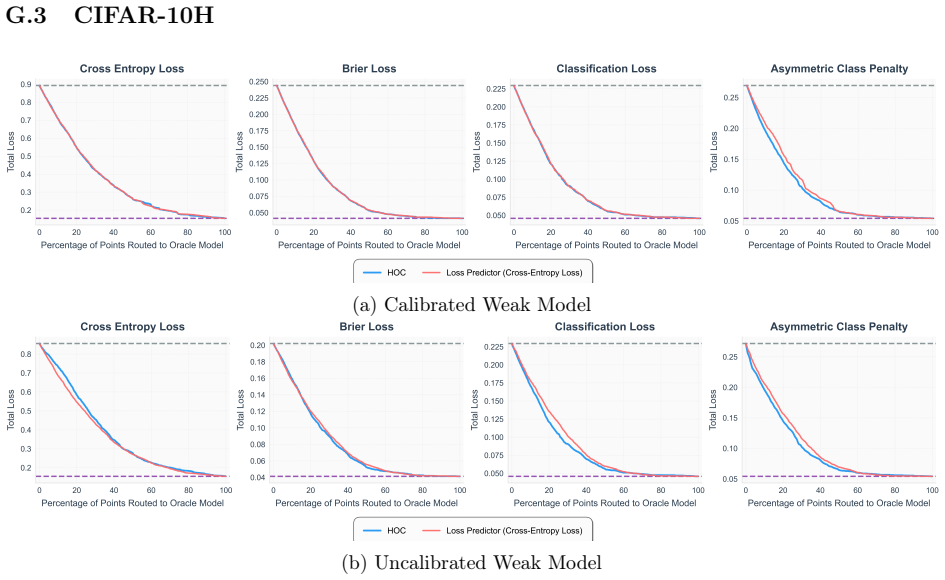



read the original abstract
A key strategy for balancing performance and cost in modern machine learning systems is to dynamically route queries to either a low-cost model or a more expensive oracle (such as a large pretrained model or human expert), an approach known as model routing. In this work we present a new uncertainty-aware router that (1) avoids unnecessary oracle calls on inherently ambiguous queries, and (2) adapts dynamically to different loss functions and cost parameters through simple hyperparameter changes, without retraining. Our method, applicable to any classification setting where multiple independent annotations per input are available, is based on decomposing total uncertainty into irreducible and reducible components using higher-order predictors [Ahdritz et al., 2025]. This enables a unified approach to both routing and abstention: predict with the weak model when uncertainty is low, route to the oracle when reducible uncertainty is high, and abstain when irreducible uncertainty is high. Our router comes with strong theoretical guarantees bounding regret relative to optimal task-specific routers. We conduct experiments on both synthetic and real-world datasets that demonstrate the benefits of our approach in suitable regimes -- in particular, whenever reducible and irreducible uncertainty are not too correlated.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an uncertainty-aware router for model routing in classification tasks with multiple independent annotations per input. It decomposes total uncertainty into irreducible and reducible components via higher-order predictors (building on Ahdritz et al. 2025), enabling dynamic decisions: use a weak model for low uncertainty, route to an oracle for high reducible uncertainty, and abstain for high irreducible uncertainty. The router adapts to different losses and costs via hyperparameters without retraining and includes theoretical regret bounds relative to optimal task-specific routers. Experiments on synthetic and real data demonstrate benefits when the uncertainty components are not highly correlated.
Significance. If the regret bounds and decomposition hold, the approach offers a flexible, unified framework for routing and abstention that avoids retraining and explicitly handles ambiguity, which could improve cost-performance tradeoffs in deployed ML systems. The explicit conditioning on low correlation between uncertainty components and the dependence on multiple annotations are clearly scoped, strengthening the claims where applicable.
minor comments (3)
- The abstract and introduction reference 'strong theoretical guarantees' for regret bounds; ensure the main text explicitly states the assumptions under which these bounds hold (e.g., independence of annotations) and includes a brief proof sketch or reference to the appendix for the key steps.
- In the experimental section, clarify how the correlation between reducible and irreducible uncertainty is measured and controlled in the synthetic data generation, as this directly impacts the reported benefits.
- Notation for the decomposed uncertainties (e.g., U_r and U_i) should be defined at first use in §3 and used consistently in the regret analysis to avoid ambiguity with total uncertainty U.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on uncertainty-aware routing and for recommending minor revision. We appreciate the recognition of the method's flexibility, theoretical guarantees, and applicability to settings with multiple annotations. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper's central method decomposes uncertainty via higher-order predictors explicitly cited to Ahdritz et al. 2025 (distinct authors) and applies the decomposition to a routing task with hyperparameter adaptation presented as external to training. Theoretical regret bounds are stated relative to optimal task-specific routers under the decomposition, with no equations or steps in the abstract or description reducing claims to self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations. Assumptions about low correlation between uncertainty components are explicitly conditioned rather than smuggled in, and the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- routing hyperparameters
axioms (1)
- domain assumption Multiple independent annotations per input are available
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decomposing total uncertainty into irreducible and reducible components using higher-order predictors... predict with the weak model when uncertainty is low, route to the oracle when reducible uncertainty is high, and abstain when irreducible uncertainty is high
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.1 (Higher-Order Calibration Implies Low Prediction-Only Routing Regret)... E[Cost(x,r(x,T);T) - Cost(x,rf(x,T);T)] ≤ Bϵ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Integrating expert judgment and algorithmic decision making: An indistinguishability framework
(document), 1, 4, 4.2, 4.1, 5, 5.1, 7 Rohan Alur, Loren Laine, Darrick K Li, Dennis Shung, Manish Raghavan, and Devavrat Shah. Integrating expert judgment and algorithmic decision making: An indistinguishability framework. arXiv preprint arXiv:2410.08783, 2024a. 2 Rohan Alur, Manish Raghavan, and Devavrat Shah. Human expertise in algorithmic prediction. A...
-
[2]
A large annotated corpus for learning natural language inference
2 Samuel Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. InProceedings of the 2015 conference on empirical methods in natural language processing, pages 632–642,
work page 2015
-
[3]
A unified approach to routing and cascading for llms.arXiv preprint arXiv:2410.10347, 2024
2 Jasper Dekoninck, Maximilian Baader, and Martin Vechev. A unified approach to routing and cascading for llms.arXiv preprint arXiv:2410.10347,
-
[5]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
URL http://arxiv.org/abs/1810.04805. E.1 Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Rühle, Laks VS Lakshmanan, and Ahmed Hassan Awadallah. Hybrid llm: Cost-efficient and quality-aware query routing. InThe Twelfth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Aurélien Garivier and Eric Moulines
2 Dujian Ding, Ankur Mallick, Shaokun Zhang, Chi Wang, Daniel Madrigal, Mirian Del Car- men Hipolito Garcia, Menglin Xia, Laks VS Lakshmanan, Qingyun Wu, and Victor Rühle. Best-route: Adaptive llm routing with test-time optimal compute.arXiv preprint arXiv:2506.22716,
-
[7]
Human-algorithm collab- oration: Achieving complementarity and avoiding unfairness
2 Kate Donahue, Alexandra Chouldechova, and Krishnaram Kenthapadi. Human-algorithm collab- oration: Achieving complementarity and avoiding unfairness. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1639–1656,
work page 2022
-
[8]
1, 2 Aravind Gollakota, Parikshit Gopalan, Aayush Karan, Charlotte Peale, and Udi Wieder. When does a predictor know its own loss? In6th Symposium on Foundations of Responsible Computing (FORC 2025), pages 22–1. Schloss Dagstuhl–Leibniz-Zentrum für Informatik,
work page 2025
-
[9]
P ., Reingold, O., and Wieder, U
2, 4.2 Parikshit Gopalan, Lunjia Hu, Michael P Kim, Omer Reingold, and Udi Wieder. Loss minimization through the lens of outcome indistinguishability.arXiv preprint arXiv:2210.08649, 2022a. 1, 2, 4.2 Parikshit Gopalan, Adam Tauman Kalai, Omer Reingold, Vatsal Sharan, and Udi Wieder. Om- nipredictors. In13th Innovations in Theoretical Computer Science Conf...
-
[10]
Levente Kocsis and Csaba Szepesvári
2, 6.1.2 Wittawat Jitkrittum, Harikrishna Narasimhan, Ankit Singh Rawat, Jeevesh Juneja, Congchao Wang, Zifeng Wang, Alec Go, Chen-Yu Lee, Pradeep Shenoy, Rina Panigrahy, et al. Universal model routing for efficient llm inference.arXiv preprint arXiv:2502.08773,
-
[11]
Johnson, Daniel Tarlow, David Duvenaud, and Chris J
2 Daniel D. Johnson, Daniel Tarlow, David Duvenaud, and Chris J. Maddison. Experts don’t cheat: Learning what you don’t know by predicting pairs. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Forty-first International Conference on Machine Learning, ICML 2024, Vien...
work page 2024
-
[12]
2 Christopher Mohri, Daniel Andor, Eunsol Choi, and Michael Collins. Learning to reject with a fixed predictor: Application to decontextualization.arXiv preprint arXiv:2301.09044,
-
[13]
Adver- sarial NLI: A new benchmark for natural language understanding
6.2 Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adver- sarial NLI: A new benchmark for natural language understanding. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2020a. E.1 Yixin Nie, Xiang Zhou, and Mohit Bansal. What can we...
work page 2020
-
[14]
Tight pair query lower bounds for matching and earth mover’s distance
doi: 10.1109/FOCS63196.2025.00084. 2 Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms from preference data. In The Thirteenth International Conference on Learning Representations,
-
[15]
The algorithmic automation problem: Prediction, triage, and human effort
E.1 Maithra Raghu, Katy Blumer, Greg Corrado, Jon Kleinberg, Ziad Obermeyer, and Sendhil Mul- lainathan. The algorithmic automation problem: Prediction, triage, and human effort.arXiv preprint arXiv:1903.12220,
-
[16]
Carrot: A cost aware rate optimal router, 2025
2 15 Seamus Somerstep, Felipe Maia Polo, Allysson Flavio Melo de Oliveira, Prattyush Mangal, Mírian Silva, Onkar Bhardwaj, Mikhail Yurochkin, and Subha Maity. Carrot: A cost aware rate optimal router.arXiv preprint arXiv:2502.03261,
-
[17]
1, 2 Clovis Varangot-Reille, Christophe Bouvard, Antoine Gourru, Mathieu Ciancone, Marion Schaeffer, and François Jacquenet. Doing more with less–implementing routing strategies in large language model-based systems: An extended survey.arXiv preprint arXiv:2502.00409,
-
[18]
A broad-coverage challenge corpus for sentence understanding through inference
2 Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics,
work page 2018
-
[19]
E Additional Experiment Discussion E.1 Dataset Details We detail each dataset and associated weak predictor architecture below. We do not perform any hparam optimization since we are not trying to obtain the best performing model in any setting, we mostly use defaults from other implementations. • Synthetic Data: A set of synthetic data functions with bas...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.