Recognition: 1 theorem link
· Lean TheoremThe Minimax Rate of Second-Order Calibration
Pith reviewed 2026-05-11 02:06 UTC · model grok-4.3
The pith
Polynomial regression estimates second-order calibration error at the optimal rate of Õ(1/√n).
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
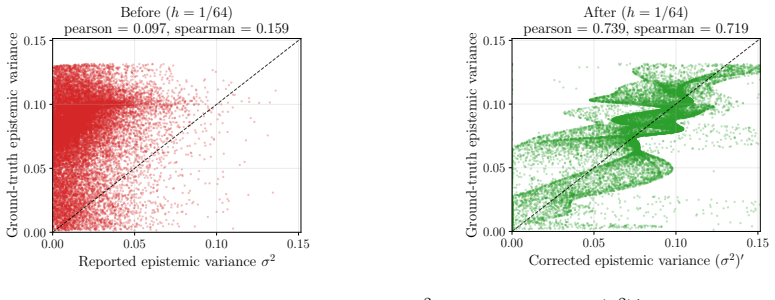
The second-order calibration error for binary classification can be estimated at the minimax rate Õ(1/√n) by polynomial regression once the sech perturbation kernel is applied; the kernel makes the calibration functions analytic in a strip of half-width hπ/2. This rate improves on the slower O(n^{-1/4}) rate of bucketing or kernel smoothing, is matched by an Ω(1/√n) lower bound up to logarithmic factors, and yields the first finite-sample guarantee for second-order Platt scaling as a post-hoc recalibration method. A bucket-free definition of second-order calibration is also related quantitatively to the earlier bucketed formulation.
What carries the argument
The sech perturbation kernel, which makes calibration functions analytic in a strip of half-width hπ/2 and thereby allows polynomial regression to achieve the fast estimation rate.
If this is right
- Polynomial regression supplies explicit constants alongside the Õ(1/√n) upper bound.
- Second-order Platt scaling obtains the first finite-sample guarantee for jointly recalibrating mean predictions and epistemic-variance estimates.
- A bucket-free definition of second-order calibration is shown to be quantitatively close to the earlier bucketed version.
- Empirical checks confirm both the predicted convergence rate and the quality of the recalibrated uncertainties.
Where Pith is reading between the lines
- The same analyticity property could be exploited to obtain fast rates for related smoothing tasks that currently rely on kernels or binning.
- The post-hoc recalibration procedure might be combined with existing mean-calibration methods to improve uncertainty estimates in deployed classifiers without retraining.
- If analogous analyticity can be arranged in multi-class or regression settings, the minimax rate result could extend beyond binary classification.
Load-bearing premise
The sech perturbation kernel makes the calibration functions analytic in a strip of half-width hπ/2 without further restrictions on the function class or data distribution.
What would settle it
A concrete numerical check would be whether the estimation error of the second-order calibration quantity decays at rate 1/√n (up to logs) when polynomial regression is applied to data generated from functions smoothed by the sech kernel; failure to observe this decay, or observation of a strictly slower rate, would refute the upper bound.
Figures



read the original abstract
We characterize the minimax rate of estimating the second-order calibration error for binary classification, which quantifies whether a higher-order predictor's epistemic-uncertainty estimate matches the conditional variance of the label probability on its level sets. Our key observation is that the sech perturbation kernel, previously used only to enforce smoothness of calibration functions, in fact makes them analytic in a strip of half-width $h\pi/2$. Polynomial regression then estimates the calibration error at rate $\tilde{O}(1/\sqrt{n})$, with explicit constants, a qualitative improvement over the $O(n^{-1/4})$ rate achievable by bucketing or kernel smoothing. A matching $\Omega(1/\sqrt{n})$ lower bound establishes minimax optimality up to logarithmic factors. As a corollary, we give the first finite-sample guarantee for second-order Platt scaling, yielding a post-hoc procedure that recalibrates both the mean prediction and the epistemic-variance estimate of any higher-order predictor. Along the way, we provide a bucket-free definition of second-order calibration and relate it quantitatively to the bucketed formulation of Ahdritz et al. [2025]. Our experiments confirm the predicted rate and the quality of the recalibrated uncertainties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper characterizes the minimax rate of estimating second-order calibration error for binary classification, which measures whether a higher-order predictor's epistemic-uncertainty estimate matches the conditional variance of the label probability on its level sets. The central claim is that the sech perturbation kernel renders the relevant calibration functions analytic in a strip of half-width hπ/2, enabling polynomial regression to achieve an Õ(1/√n) rate with explicit constants (a qualitative improvement over the O(n^{-1/4}) rate from bucketing or kernel smoothing). A matching Ω(1/√n) lower bound establishes minimax optimality up to log factors. As a corollary, the paper provides the first finite-sample guarantee for second-order Platt scaling and introduces a bucket-free definition of second-order calibration, relating it quantitatively to the bucketed formulation of Ahdritz et al. [2025]. Experiments are said to confirm the predicted rate.
Significance. If the analyticity property and rate derivations hold for the defined function class, this establishes a meaningful theoretical advance in calibration and uncertainty quantification by delivering the first minimax-optimal rate with explicit constants for second-order calibration error. The finite-sample guarantee for post-hoc recalibration of both mean predictions and epistemic-variance estimates is a practical strength, and the bucket-free definition clarifies the relationship to prior work. The explicit constants and matching lower bound (if verified) would be notable contributions.
major comments (2)
- [§4] §4 (Upper Bound): The claim that the sech perturbation kernel makes the calibration functions analytic in a strip of half-width hπ/2 (allowing polynomial regression to attain the Õ(1/√n) rate) is load-bearing for the central minimax result. The manuscript must explicitly verify that this analyticity holds uniformly for the function class arising from the bucket-free second-order calibration definition (relating conditional variance on level sets), without imposing extra restrictions on the predictor or data distribution. The abstract presents this as a key observation, but the proof details on how the perturbation is applied to the calibration map and whether the strip width remains uniform are needed to support the rate improvement over bucketing/kernel methods.
- [Theorem 5.1] Theorem 5.1 (Lower Bound): The matching Ω(1/√n) lower bound is asserted to establish minimax optimality up to logarithmic factors. It is necessary to confirm that the lower-bound construction operates over precisely the same function class as the upper bound (i.e., the analytic functions induced by the sech perturbation in the second-order setting), so that the bounds are comparable and the optimality claim is not circular with respect to the function class.
minor comments (2)
- [Introduction / §3] The quantitative relation between the bucket-free definition and the bucketed formulation of Ahdritz et al. [2025] is mentioned in the abstract and introduction; including a short corollary or table that states the precise approximation error between the two would strengthen the presentation.
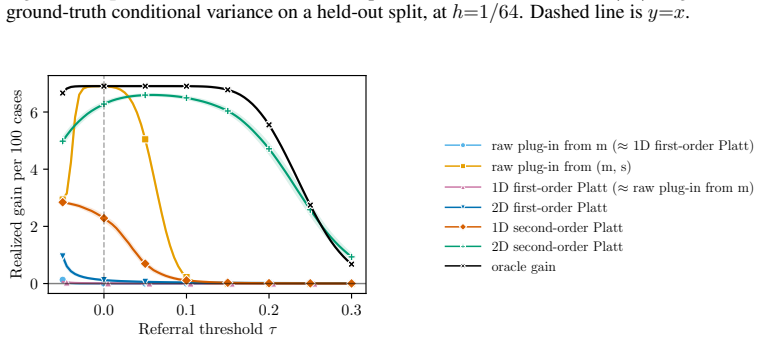
- [Experiments] Experimental details (data exclusion rules, choice of polynomial degree, and hyperparameter selection for the regression estimator) should be expanded in the experiments section to support full reproducibility of the reported rate confirmation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We have addressed each major point by adding explicit verifications and clarifications in the revised version, as detailed below.
read point-by-point responses
-
Referee: [§4] §4 (Upper Bound): The claim that the sech perturbation kernel makes the calibration functions analytic in a strip of half-width hπ/2 (allowing polynomial regression to attain the Õ(1/√n) rate) is load-bearing for the central minimax result. The manuscript must explicitly verify that this analyticity holds uniformly for the function class arising from the bucket-free second-order calibration definition (relating conditional variance on level sets), without imposing extra restrictions on the predictor or data distribution. The abstract presents this as a key observation, but the proof details on how the perturbation is applied to the calibration map and whether the strip width remains uniform are needed to support the rate improvement over bucketing/kernel methods.
Authors: We agree that explicit verification of uniform analyticity is essential for the bucket-free definition. In the revised manuscript, we have added Lemma 4.3 in Section 4, which proves that the sech perturbation applied pointwise to the second-order calibration map (defined via conditional variance on level sets) yields analyticity in a strip of half-width hπ/2 uniformly, without extra restrictions on the predictor or data distribution. The proof details, including preservation of the strip width, are now in new Appendix C. This directly supports the polynomial regression rate. revision: yes
-
Referee: [Theorem 5.1] Theorem 5.1 (Lower Bound): The matching Ω(1/√n) lower bound is asserted to establish minimax optimality up to logarithmic factors. It is necessary to confirm that the lower-bound construction operates over precisely the same function class as the upper bound (i.e., the analytic functions induced by the sech perturbation in the second-order setting), so that the bounds are comparable and the optimality claim is not circular with respect to the function class.
Authors: The lower-bound construction in Theorem 5.1 uses hard instances that are explicitly within the same analytic function class induced by the sech perturbation for second-order calibration maps. We have revised the theorem statement and discussion to clarify that these instances (perturbations of constant functions) lie in the strip of width hπ/2, making the upper and lower bounds directly comparable and the minimax optimality claim non-circular. revision: yes
Circularity Check
Derivation self-contained via standard approximation theory for analytic functions
full rationale
The paper's central minimax claim rests on a new observation that the sech kernel renders calibration functions analytic in a strip (allowing polynomial regression to achieve Õ(1/√n) rates via classical results on analytic approximation), together with a matching lower bound and a quantitative relation to prior bucketed definitions. No step reduces a claimed prediction or rate to a fitted parameter, self-referential definition, or unverified self-citation chain; the analyticity property is presented as an independent mathematical fact derived from the kernel, and the bucket-free definition is explicitly related to external work without circular dependence. The derivation chain is therefore externally grounded in approximation theory and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The sech perturbation kernel makes calibration functions analytic in a strip of half-width hπ/2
Reference graph
Works this paper leans on
-
[1]
The Thirteenth International Conference on Learning Representations , year=
Provable Uncertainty Decomposition via Higher-Order Calibration , author=. The Thirteenth International Conference on Learning Representations , year=
-
[2]
ESAIM: probability and statistics , volume=
Theory of classification: A survey of some recent advances , author=. ESAIM: probability and statistics , volume=. 2005 , publisher=
work page 2005
-
[3]
The Fourteenth International Conference on Learning Representations , year=
Measuring Uncertainty Calibration , author=. The Fourteenth International Conference on Learning Representations , year=
-
[4]
International conference on machine learning , pages=
Decomposition of uncertainty in Bayesian deep learning for efficient and risk-sensitive learning , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[5]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[6]
Quantifying Aleatoric and Epistemic Uncertainty with Proper Scoring Rules , author=. 2024 , eprint=
work page 2024
-
[7]
Bayesian active learning for classification and preferenc e learning,
Bayesian active learning for classification and preference learning , author=. arXiv preprint arXiv:1112.5745 , year=
-
[8]
Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods , author=. Machine Learning , year=
-
[9]
Advances in neural information processing systems , volume=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. Advances in neural information processing systems , volume=
-
[10]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[11]
Advances in large margin classifiers , volume=
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods , author=. Advances in large margin classifiers , volume=. 1999 , publisher=
work page 1999
-
[12]
arXiv preprint arXiv:2312.00995 , year=
Second-order uncertainty quantification: A distance-based approach , author=. arXiv preprint arXiv:2312.00995 , year=
-
[13]
Uncertainty in artificial intelligence , pages=
Quantifying aleatoric and epistemic uncertainty in machine learning: Are conditional entropy and mutual information appropriate measures? , author=. Uncertainty in artificial intelligence , pages=. 2023 , organization=
work page 2023
- [14]
-
[15]
Bartlett, Peter , year=
- [16]
-
[17]
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods , author=. Machine learning , volume=. 2021 , publisher=
work page 2021
-
[18]
Proceedings of the AAAI conference on artificial intelligence , volume=
Obtaining well calibrated probabilities using bayesian binning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[19]
The 22nd international conference on artificial intelligence and statistics , pages=
Evaluating model calibration in classification , author=. The 22nd international conference on artificial intelligence and statistics , pages=. 2019 , organization=
work page 2019
-
[20]
Advances in neural information processing systems , volume=
Verified uncertainty calibration , author=. Advances in neural information processing systems , volume=
-
[21]
International Conference on Artificial Intelligence and Statistics , pages=
Mitigating bias in calibration error estimation , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
work page 2022
-
[22]
Advances in neural information processing systems , volume=
Calibration tests in multi-class classification: A unifying framework , author=. Advances in neural information processing systems , volume=
-
[23]
Transforming classifier scores into accurate multiclass probability estimates , author=. Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[24]
Artificial intelligence and statistics , pages=
Beta calibration: a well-founded and easily implemented improvement on logistic calibration for binary classifiers , author=. Artificial intelligence and statistics , pages=. 2017 , organization=
work page 2017
-
[25]
Advances in neural information processing systems , volume=
Predictive uncertainty estimation via prior networks , author=. Advances in neural information processing systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Evidential deep learning to quantify classification uncertainty , author=. Advances in neural information processing systems , volume=
-
[27]
Algorithmic learning in a random world , author=. 2005 , publisher=
work page 2005
-
[28]
Foundations and Trends in Machine Learning , volume=
Conformal prediction: A gentle introduction , author=. Foundations and Trends in Machine Learning , volume=. 2023 , publisher=
work page 2023
-
[29]
Aleatoric and Epistemic Uncertainty in Conformal Prediction , author=. 2025 , publisher=
work page 2025
-
[30]
Information Theory: From Coding to Learning , publisher=
Polyanskiy, Yury and Wu, Yihong , year=. Information Theory: From Coding to Learning , publisher=
-
[31]
Proceedings of the 55th Annual ACM Symposium on Theory of Computing , pages=
A unifying theory of distance from calibration , author=. Proceedings of the 55th Annual ACM Symposium on Theory of Computing , pages=
-
[32]
arXiv preprint arXiv:2309.12236 , year=
Smooth ECE: Principled reliability diagrams via kernel smoothing , author=. arXiv preprint arXiv:2309.12236 , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Distribution-free binary classification: prediction sets, confidence intervals and calibration , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Journal of Machine Learning Research , volume=
T-cal: An optimal test for the calibration of predictive models , author=. Journal of Machine Learning Research , volume=
-
[35]
International Conference on Machine Learning , pages=
Multicalibration: Calibration for the (computationally-identifiable) masses , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[36]
Advances in Neural Information Processing Systems , volume=
Epistemic neural networks , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.