Recognition: 2 theorem links
· Lean TheoremADKO: Agentic Decentralized Knowledge Optimization
Pith reviewed 2026-05-11 03:36 UTC · model grok-4.3
The pith
Decentralized agents can collaborate on black-box optimization by sharing compact knowledge tokens instead of raw data or models, while keeping cumulative regret sublinear under bounded information losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ADKO lets autonomous agents solve black-box optimization collaboratively by each maintaining a private Gaussian process surrogate and exchanging only knowledge tokens that contain directional signals, advantage scores, and optional language-model insights. The analysis decomposes cumulative regret into GP error, LM bias, LM noise, and compression loss, then states necessary and sufficient conditions on these terms that guarantee the regret remains sublinear. A fidelity-aware pruning procedure is introduced to discard low-information tokens while respecting a memory budget.
What carries the argument
The knowledge token, a compact lossy summary carrying directional signals, advantage scores, and optional language-model insights that transmits information across agents without exposing raw data or model parameters.
If this is right
- When the four regret components satisfy the stated bounds, the joint optimization achieves sublinear cumulative regret.
- Agents can pursue heterogeneous objectives while preserving privacy and limiting communication to token exchanges.
- Fidelity-aware pruning keeps high-information tokens under a fixed memory budget without harming the regret guarantee.
- The same token mechanism unifies Gaussian-process upper-confidence-bound search with decentralized learning and language-model guidance.
Where Pith is reading between the lines
- The dual-loss decomposition could be reused in other compressed-communication settings where agents must trade information quality against bandwidth.
- Tighter language-model error bounds, if achieved, would directly tighten the overall regret rate without changing the token format.
- Scaling the number of agents would require checking whether the per-agent token budget still satisfies the sublinear-regret conditions derived in the paper.
Load-bearing premise
The mutual-information fidelity of token compression and the bias-noise split of language-model error can be bounded so that their total contribution still permits sublinear regret.
What would settle it
An experiment on a standard benchmark in which token compression fidelity is deliberately lowered below the paper's necessary threshold and cumulative regret is then observed to grow linearly rather than sublinearly.
Figures







read the original abstract
We present Agentic Decentralized Knowledge Optimization (ADKO), a framework for collaborative black-box optimization across autonomous agents that achieves sample efficiency, privacy preservation, heterogeneous-objective handling, and communication efficiency. Each agent maintains a private Gaussian Process (GP) surrogate trained on local data and communicates only through knowledge tokens-compact, lossy summaries containing directional signals, advantage scores, and optional language-model (LM) insights-without sharing raw data or model parameters. ADKO unifies GP-Upper Confidence Bound (GP-UCB), parallel Bayesian optimization, decentralized learning, and LM-guided discovery. We provide the first formal analysis of dual information loss: token compression, quantified via mutual-information-based fidelity, and LM approximation error, decomposed into bias and stochastic noise. Our main result shows cumulative regret decomposes into GP error, LM bias, LM noise, and compression loss, with necessary and sufficient conditions for sublinear regret. We also propose fidelity-aware token pruning to preserve high-information tokens under memory budget. Experiments on neural architecture search and scientific discovery validate the theory and show consistent improvements over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ADKO framework for collaborative black-box optimization among autonomous agents. Each agent maintains a private Gaussian Process surrogate and communicates only via compact knowledge tokens containing directional signals, advantage scores, and optional language-model insights. The central theoretical claim is a decomposition of cumulative regret into GP error, LM bias, LM noise, and compression loss, together with necessary and sufficient conditions for sublinear regret derived from mutual-information fidelity of token compression and a bias/stochastic-noise split of LM error. The work also proposes fidelity-aware token pruning and reports experimental results on neural architecture search and scientific discovery tasks.
Significance. If the regret decomposition and sublinear-regret conditions can be rigorously established, the framework would offer a useful synthesis of decentralized Bayesian optimization, parallel BO, and LM-guided search while preserving privacy and communication efficiency. The explicit treatment of dual information loss (compression fidelity and LM approximation error) provides a structured lens for analyzing such systems. The experimental improvements over baselines are suggestive but cannot yet be weighed against the theoretical claims.
major comments (3)
- [Abstract] Abstract: The main result asserts that cumulative regret decomposes into GP error, LM bias, LM noise, and compression loss with necessary and sufficient conditions for sublinear regret, yet supplies no derivation, proof sketch, or reference to any equation or theorem. This is the load-bearing claim of the paper.
- [Theoretical analysis] Theoretical analysis: The bounding step that combines mutual-information-based token-compression fidelity with the bias/stochastic-noise decomposition of LM error is asserted to permit sublinear regret under the stated conditions, but no explicit bounds, inequalities, or proof outline are provided to substantiate that the sum remains sublinear.
- [Experiments] Experiments: Results on neural architecture search and scientific discovery are reported without error bars, standard deviations across runs, or statistical significance tests, undermining any claim of consistent improvement over baselines.
minor comments (2)
- [Abstract] The assertion of providing 'the first formal analysis' of dual information loss should be accompanied by a concise related-work discussion to justify the novelty claim.
- [Notation] Notation for knowledge tokens, directional signals, and advantage scores is introduced informally; explicit mathematical definitions would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major point below and commit to revisions that will strengthen the presentation of the theoretical results and experimental evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The main result asserts that cumulative regret decomposes into GP error, LM bias, LM noise, and compression loss with necessary and sufficient conditions for sublinear regret, yet supplies no derivation, proof sketch, or reference to any equation or theorem. This is the load-bearing claim of the paper.
Authors: We agree that the abstract should explicitly direct readers to the formal statement. In the revised version we will reference Theorem 4.1 (regret decomposition) and the associated sublinear-regret conditions directly in the abstract, and we will insert a concise proof sketch in Section 4 that outlines the key bounding steps. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis: The bounding step that combines mutual-information-based token-compression fidelity with the bias/stochastic-noise decomposition of LM error is asserted to permit sublinear regret under the stated conditions, but no explicit bounds, inequalities, or proof outline are provided to substantiate that the sum remains sublinear.
Authors: We acknowledge that the current theoretical section would benefit from greater explicitness. The revised manuscript will include the full set of inequalities that combine the mutual-information fidelity bound with the bias-plus-stochastic-noise decomposition of LM error, together with a proof outline demonstrating that the sum is sublinear under the stated conditions on compression fidelity and LM error. The complete derivations will remain in the appendix but will be clearly signposted from the main text. revision: yes
-
Referee: [Experiments] Experiments: Results on neural architecture search and scientific discovery are reported without error bars, standard deviations across runs, or statistical significance tests, undermining any claim of consistent improvement over baselines.
Authors: We agree that reporting statistical variability is essential. In the revision we will repeat all experiments with at least five independent random seeds, report means accompanied by standard deviations and error bars, and add paired statistical significance tests (e.g., t-tests) against each baseline to substantiate the observed improvements. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The central claim is a regret decomposition (GP error + LM bias + LM noise + compression loss) with necessary-and-sufficient conditions for sublinear regret, derived from mutual-information fidelity of token compression and a bias/stochastic-noise split of LM approximation error. No equations, self-citations, or fitted inputs are shown reducing the result to its own definitions by construction. The analysis treats the bounding steps as independent assumptions that can be externally falsified, with no load-bearing self-citation chain or ansatz smuggling visible in the stated framework. This is the normal honest outcome for a paper whose formal result remains open to verification outside its own fitted values.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our main result shows cumulative regret decomposes into GP error, LM bias, LM noise, and compression loss, with necessary and sufficient conditions for sublinear regret.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
token fidelity η_k = I(f_j(θ_k);k)/H(f_j(θ_k)) ∈ [0,1]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On bayesian methods for seeking the extremum
Jonas Moˇckus. On bayesian methods for seeking the extremum. InIFIP Technical Conference on Optimization Techniques, pages 400–404. Springer, 1974
work page 1974
-
[2]
Donald R Jones, Matthias Schonlau, and William J Welch. Efficient global optimization of expensive black-box functions.Journal of Global optimization, 13(4):455–492, 1998
work page 1998
-
[3]
Gaussian process optimization in the bandit setting: No regret and experimental design,
Niranjan Srinivas, Andreas Krause, Sham M Kakade, and Matthias Seeger. Gaussian pro- cess optimization in the bandit setting: No regret and experimental design.arXiv preprint arXiv:0912.3995, 2009
-
[4]
Prototyping dynamics: sharing multiple designs improves exploration, group rapport, and results
Steven Dow, Julie Fortuna, Dan Schwartz, Beth Altringer, Daniel Schwartz, and Scott Klemmer. Prototyping dynamics: sharing multiple designs improves exploration, group rapport, and results. InProceedings of the SIGCHI conference on human factors in computing systems, pages 2807–2816, 2011
work page 2011
-
[5]
Coordinated multi-robot exploration through unsuper- vised clustering of unknown space
Agusti Solanas and Miguel Angel Garcia. Coordinated multi-robot exploration through unsuper- vised clustering of unknown space. In2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)(IEEE Cat. No. 04CH37566), volume 1, pages 717–721. IEEE, 2004
work page 2004
-
[6]
Florim Hamiti, Martin Breidenbach, Naguib Heiba, Aynur Guluzade, Yehya Mohamad, and Carlos A Velasco. A data space infrastructure supporting the integration of clinical data nodes and cancer registries to improve personalized medicine. InProceedings of the 11th Interna- tional Conference on Software Development and Technologies for Enhancing Accessibility...
work page 2024
-
[7]
Automating model search for large scale machine learning
Evan R Sparks, Ameet Talwalkar, Daniel Haas, Michael J Franklin, Michael I Jordan, and Tim Kraska. Automating model search for large scale machine learning. InProceedings of the Sixth ACM Symposium on Cloud Computing, pages 368–380, 2015
work page 2015
-
[8]
Batch bayesian optimization via local penalization
Javier González, Zhenwen Dai, Philipp Hennig, and Neil Lawrence. Batch bayesian optimization via local penalization. InArtificial intelligence and statistics, pages 648–657. PMLR, 2016
work page 2016
-
[9]
Differentially private bayesian optimization
Matt Kusner, Jacob Gardner, Roman Garnett, and Kilian Weinberger. Differentially private bayesian optimization. InInternational conference on machine learning, pages 918–927. PMLR, 2015
work page 2015
-
[10]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. Pmlr, 2017
work page 2017
-
[11]
Large language models as optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[12]
Large Language Models to Enhance Bayesian Optimization
Tennison Liu, Nicolás Astorga, Nabeel Seedat, and Mihaela van der Schaar. Large language models to enhance bayesian optimization.arXiv preprint arXiv:2402.03921, 2024
-
[13]
Eric Brochu, Vlad M Cora, and Nando De Freitas. A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning.arXiv preprint arXiv:1012.2599, 2010
work page Pith review arXiv 2010
-
[14]
Peter Auer. Using confidence bounds for exploitation-exploration trade-offs.Journal of machine learning research, 3(Nov):397–422, 2002
work page 2002
-
[15]
On information gain and regret bounds in gaussian process bandits
Sattar Vakili, Kia Khezeli, and Victor Picheny. On information gain and regret bounds in gaussian process bandits. In Arindam Banerjee and Kenji Fukumizu, editors,Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 of Proceedings of Machine Learning Research, pages 82–90. PMLR, 13–15 Apr 2021
work page 2021
-
[16]
Multi-fidelity bayesian optimisation with continuous approximations
Kirthevasan Kandasamy, Gautam Dasarathy, Jeff Schneider, and Barnabás Póczos. Multi-fidelity bayesian optimisation with continuous approximations. InInternational conference on machine learning, pages 1799–1808. PMLR, 2017. 11
work page 2017
-
[17]
Bayesian optimization in a billion dimensions via random embeddings.J
Ziyu Wang, Frank Hutter, Masrour Zoghi, David Matheson, and Nando De Freitas. Bayesian optimization in a billion dimensions via random embeddings.J. Artif. Int. Res., 55(1):361–387, January 2016
work page 2016
-
[18]
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local bayesian optimization.Advances in neural information processing systems, 32, 2019
work page 2019
-
[19]
Kriging is well-suited to paral- lelize optimization
David Ginsbourger, Rodolphe Le Riche, and Laurent Carraro. Kriging is well-suited to paral- lelize optimization. InComputational intelligence in expensive optimization problems, pages 131–162. Springer, 2010
work page 2010
-
[20]
Practical bayesian optimization of machine learning algorithms
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. In F. Pereira, C.J. Burges, L. Bottou, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume 25. Curran Associates, Inc., 2012
work page 2012
-
[21]
Javad Azimi, Ali Jalali, and Xiaoli Fern. Hybrid batch bayesian optimization.arXiv preprint arXiv:1202.5597, 2012
-
[22]
Thomas Desautels, Andreas Krause, and Joel W Burdick. Parallelizing exploration-exploitation tradeoffs in gaussian process bandit optimization.The Journal of Machine Learning Research, 15(1):3873–3923, 2014
work page 2014
-
[23]
Xubo Yue, Yang Liu, Albert S Berahas, Blake N Johnson, and Raed Al Kontar. Collaborative and distributed bayesian optimization via consensus.IEEE Transactions on Automation Science and Engineering, 22:11343–11355, 2025
work page 2025
-
[24]
Dan Alistarh, Demjan Grubic, Jerry Li, Ryota Tomioka, and Milan V ojnovic. Qsgd: Communication-efficient sgd via gradient quantization and encoding.Advances in neural information processing systems, 30, 2017
work page 2017
-
[25]
Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Federated learning: Chal- lenges, methods, and future directions.IEEE signal processing magazine, 37(3):50–60, 2020
work page 2020
-
[26]
Scaffold: Stochastic controlled averaging for federated learning
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for federated learning. In International conference on machine learning, pages 5132–5143. PMLR, 2020
work page 2020
-
[27]
Jack Goetz, Kshitiz Malik, Duc Bui, Seungwhan Moon, Honglei Liu, and Anuj Kumar. Active federated learning.arXiv preprint arXiv:1909.12641, 2019
-
[28]
Honglan Huang, Wei Shi, Yanghe Feng, Chaoyue Niu, Guangquan Cheng, Jincai Huang, and Zhong Liu. Active client selection for clustered federated learning.IEEE Transactions on Neural Networks and Learning Systems, 35(11):16424–16438, 2024
work page 2024
-
[29]
Hamid Taghavifar, Chuan Hu, Chongfeng Wei, Ardashir Mohammadzadeh, and Chunwei Zhang. Behaviorally-aware multi-agent rl with dynamic optimization for autonomous driving.IEEE Transactions on Automation Science and Engineering, 22:10672–10683, 2025
work page 2025
-
[30]
Angelia Nedic and Asuman Ozdaglar. Distributed subgradient methods for multi-agent opti- mization.IEEE Transactions on automatic control, 54(1):48–61, 2009
work page 2009
-
[31]
Zhanhong Jiang, Aditya Balu, Chinmay Hegde, and Soumik Sarkar. Collaborative deep learning in fixed topology networks.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[32]
Liangqi Yuan, Ziran Wang, Lichao Sun, Philip S. Yu, and Christopher G. Brinton. Decentralized federated learning: A survey and perspective.IEEE Internet of Things Journal, 11(21):34617– 34638, 2024
work page 2024
-
[33]
Enrique Tomás Martínez Beltrán, Mario Quiles Pérez, Pedro Miguel Sánchez Sánchez, Ser- gio López Bernal, Gérôme Bovet, Manuel Gil Pérez, Gregorio Martínez Pérez, and Alberto Huer- tas Celdrán. Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges.IEEE Communications Surveys & Tutorials, 25(4):2983–3013, 2023. 12
work page 2023
-
[34]
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments.Advances in neural information processing systems, 30, 2017
work page 2017
-
[35]
The surprising effectiveness of ppo in cooperative multi-agent games
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and YI WU. The surprising effectiveness of ppo in cooperative multi-agent games. In S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 24611–24624. Curran Associates, Inc., 2022
work page 2022
-
[36]
Angelica Chen, David Dohan, and David So. Evoprompting: Language models for code-level neural architecture search.Advances in neural information processing systems, 36:7787–7817, 2023
work page 2023
-
[37]
Mathematical discoveries from program search with large language models
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024
work page 2024
-
[38]
Shuvayan Brahmachary, Subodh M. Joshi, Aniruddha Panda, Kaushik Koneripalli, Arun Kumar Sagotra, Harshil Patel, Ankush Sharma, Ameya D. Jagtap, and Kaushic Kalyanaraman. Large language model-based evolutionary optimizer: Reasoning with elitism.Neurocomputing, 622:129272, 2025
work page 2025
-
[39]
Transformers can do bayesian inference, 2024
Samuel Müller, Noah Hollmann, Sebastian Pineda Arango, Josif Grabocka, and Frank Hutter. Transformers can do bayesian inference.arXiv preprint arXiv:2112.10510, 2021
-
[40]
Emergent au- tonomous scientific research capabilities of large lan- guage models
Daniil A Boiko, Robert MacKnight, and Gabe Gomes. Emergent autonomous scientific research capabilities of large language models.arXiv preprint arXiv:2304.05332, 2023
-
[41]
M., Cox, S., Schilter, O., Baldassari, C., White, A
Andres M Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. Chemcrow: Augmenting large-language models with chemistry tools.arXiv preprint arXiv:2304.05376, 2023
-
[42]
Towards scientific intelligence: A survey of llm-based scientific agents, 2026
Shuo Ren, Can Xie, Pu Jian, Zhenjiang Ren, Chunlin Leng, and Jiajun Zhang. Towards scientific intelligence: A survey of llm-based scientific agents, 2026
work page 2026
-
[43]
Yu Li, Lehui Li, Zhihao Wu, Qingmin Liao, Jianye HAO, Kun Shao, and Fengli Xu. Agentswift: Efficient llm agent design via value-guided hierarchical search.Proceedings of the AAAI Conference on Artificial Intelligence, 40(38):31843–31851, Mar. 2026
work page 2026
-
[44]
Oscagent: Accelerating the discovery of organic solar cells with llm agents, 2026
Zhaolin Hu, Zhiliang Wu, Hehe Fan, and Yi Yang. Oscagent: Accelerating the discovery of organic solar cells with llm agents, 2026
work page 2026
-
[45]
The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
Kyle Swanson, Wesley Wu, Nash L Bulaong, John E Pak, and James Zou. The virtual lab of ai agents designs new sars-cov-2 nanobodies.Nature, 646(8085):716–723, 2025
work page 2025
-
[46]
Gridmind: Llms-powered agents for power system analysis and operations
Hongwei Jin, Kibaek Kim, and Jonghwan Kwon. Gridmind: Llms-powered agents for power system analysis and operations. InProceedings of the SC’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 560– 568, 2025
work page 2025
-
[47]
James Kennedy and Russell Eberhart. Particle swarm optimization. InProceedings of ICNN’95- international conference on neural networks, volume 4, pages 1942–1948. ieee, 1995
work page 1942
-
[48]
Alliot Nagle, Adway Girish, Marco Bondaschi, Michael Gastpar, Ashok Vardhan Makkuva, and Hyeji Kim. Fundamental limits of prompt compression: A rate-distortion framework for black- box language models.Advances in Neural Information Processing Systems, 37:94934–94970, 2024
work page 2024
-
[49]
Sean I Young. Radio: rate-distortion optimization for large language model compression.arXiv preprint arXiv:2505.03031, 2025. 13
-
[50]
Learning is forgetting; llm training as lossy compression
Henry Conklin, Tom Hosking, Tan Yi-Chern, Jonathan D Cohen, Sarah-Jane Leslie, Thomas L Griffiths, Max Bartolo, and Seraphina Goldfarb-Tarrant. Learning is forgetting; llm training as lossy compression. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[51]
Yongjia Yang, Jinyu Zhan, Wei Jiang, Yucheng Jiang, and Antai Yu. Neural architecture search for resource constrained hardware devices: A survey.IET Cyber-Physical Systems: Theory & Applications, 8(3):149–159, 2023
work page 2023
-
[52]
Riley Hickman, Priyansh Parakh, Austin Cheng, Qianxiang Ai, Joshua Schrier, Matteo Aldeghi, and Alán Aspuru-Guzik. Olympus, enhanced: benchmarking mixed-parameter and multi- objective optimization in chemistry and materials science.ChemRxiv, 2023(0518), 2023
work page 2023
-
[53]
Variational learning of inducing variables in sparse gaussian processes
Michalis Titsias. Variational learning of inducing variables in sparse gaussian processes. In David van Dyk and Max Welling, editors,Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, volume 5 ofProceedings of Machine Learning Research, pages 567–574, Hilton Clearwater Beach Resort, Clearwater Beach, Florida USA...
-
[54]
Collabo- rative bayesian optimization with fair regret
Rachael Hwee Ling Sim, Yehong Zhang, Bryan Kian Hsiang Low, and Patrick Jaillet. Collabo- rative bayesian optimization with fair regret. InInternational Conference on Machine Learning, pages 9691–9701. PMLR, 2021
work page 2021
-
[55]
Combining bayesian optimiza- tion and lipschitz optimization.Machine Learning, 109(1):79–102, 2020
Mohamed Osama Ahmed, Sharan Vaswani, and Mark Schmidt. Combining bayesian optimiza- tion and lipschitz optimization.Machine Learning, 109(1):79–102, 2020
work page 2020
-
[56]
Randomized gossip algorithms.IEEE transactions on information theory, 52(6):2508–2530, 2006
Stephen Boyd, Arpita Ghosh, Balaji Prabhakar, and Devavrat Shah. Randomized gossip algorithms.IEEE transactions on information theory, 52(6):2508–2530, 2006
work page 2006
-
[57]
Weight sharing for hyperparameter optimization in federated learning
Mikhail Khodak, Tian Li, Liam Li, M Balcan, Virginia Smith, and Ameet Talwalkar. Weight sharing for hyperparameter optimization in federated learning. InInt. Workshop on Federated Learning for User Privacy and Data Confidentiality in Conjunction with ICML, volume 2020, 2020
work page 2020
-
[58]
Federated bayesian optimization via thompson sampling
Zhongxiang Dai, Bryan Kian Hsiang Low, and Patrick Jaillet. Federated bayesian optimization via thompson sampling. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 9687–9699. Curran Associates, Inc., 2020
work page 2020
-
[59]
Geoffrey E. Hinton. Training products of experts by minimizing contrastive divergence.Neural Computation, 14(8):1771–1800, Aug 2002
work page 2002
-
[60]
Yanshuai Cao and David J. Fleet. Generalized product of experts for automatic and principled fusion of gaussian process predictions, 2014
work page 2014
-
[61]
based on every experiment I have personally run, what performance do I expect here?
Maximilian Balandat, Brian Karrer, Daniel Jiang, Samuel Daulton, Ben Letham, Andrew G Wil- son, and Eytan Bakshy. Botorch: A framework for efficient monte-carlo bayesian optimization. Advances in neural information processing systems, 33:21524–21538, 2020. 14 A Methodological Comparison Table 1 highlights that ADKO is the only method that simultaneously s...
work page 2020
-
[62]
this failure was due to phase separation, not insufficient temperature
Birth (Step 6 — Token Encoding).After executing experiment θt i and observing yt i, agent i’s LM interprets the result in context—reading any accumulated token memory about the surrounding region and distilling the outcome into a structured token kt i. The binary label st i (SUCCESS/FAIL ) strips the raw value away, preserving privacy. The advantage score...
-
[63]
Those neighbours do not need to be active at the same time as tokens persist in memory across rounds
Propagation (Step 7 — Broadcasting).The token is immediately broadcast to all graph neighbours j∈ N i. Those neighbours do not need to be active at the same time as tokens persist in memory across rounds. Over multiple rounds, tokens propagateacross the graph: a token born at agent 0 reaches agent 3 in two rounds if the shortest path is two hops. The Fied...
-
[64]
Aggregation (Step 1 — Token Aggregation).At the start of each round, agent i merges incoming tokens from neighbors with its own memory. This is not passive accumulation: fidelity- aware pruning actively maintains the quality of the memory by discarding tokens that are either low-fidelity (near-contextual baseline, ambiguous outcomes), stale (from many rou...
-
[65]
Influence (Steps 2–4 — Candidate Generation and Selection).Token memory shapes agent i’s behavior in two ways. First, the LM reads the memory when proposing candidates in Step 2: a well-calibrated LM will bias its suggestions away from regions with many failure tokens and toward regions with many success tokens, before any explicit scoring happens. Second...
-
[66]
Feedback (Step 8 — GP Update).After execution, the GP is updated with the new private observation. If the agent followed a peer success to a new region and found success itself, the GP learns the new peak and future candidates will be drawn there. If the agent followed a peer success but found failure (because objectives are heterogeneous and what works f...
-
[67]
By the Azuma–Hoeffding inequality for sub-Gaussian martingales, with probability≥1−δ/(2N): TX t=1 ξt ≤σ 0 p 2Tlog(2N/δ). Step 7: Summing token compression terms.At each round, the compression gap contributes at most (λ+γ)C S(1−¯ηt i). Under fidelity-aware pruning (A5), Proposition 4 (below) gives ¯ηt i ≥¯ηmin for a constant¯ηmin →1asB→ ∞. Hence: P t(λ+γ)C...
work page 2026
-
[68]
At round 6, the DMF agent proposes an experiment that achieves 93.79% yield, with the rationale: “One-step from peer iodide/Bpin/SPhos success: keep reactive iodide and bulky biaryl ligand, but test alkoxide in DMF . ”It then broadcasts:“Heteroaryl iodides couple efficiently in DMF with bulky electron-rich biaryl phosphines like SPhos and alkoxide base, w...
-
[69]
At round 7, the THF agent proposes an experiment that achieves 95.34% yield, with the rationale: “Mirrors peer iodide/Bpin/lithium isopropoxide/SPhos success; keeps reactive C–I bond and bulky biaryl phosphine. ”It then broadcasts:“Heteroaryl iodides couple efficiently in THF with aryl Bpin esters when paired with a bulky electron-rich biaryl phosphine an...
-
[70]
At round 9, the MeOH agent proposes an experiment that achieves 100.00% yield, with the rationale:“Mirrors peer iodide+Bpin+LiOiPr+SPhos success; MeOH may still support this bulky biaryl phosphine/alkoxide activation. ” G LLM module: architecture, prompts, and behavior This appendix specifies the auxiliary LLM module used by ADKO-LLM and analyzes its obse...
-
[71]
Sanitize the LLM batch: drop tuples that are infeasible, already observed by agent i, or already in the pool
-
[72]
Take the surviving LLM picks, up toK LLM =min(10,|batch|)
-
[73]
Uniformly random-fill fromX i \ C t i until|C t i |=K tot. The pool is then scored byµ+βσ+λG−γΛ exactly as in non-LLM ADKO; the four-term acquisition is unchanged. The LLM’s action is therefore purelycompositional: it can include points the score would not have surfaced (although in this experiment non-LLM ADKO covers the full unobserved space) and it can...
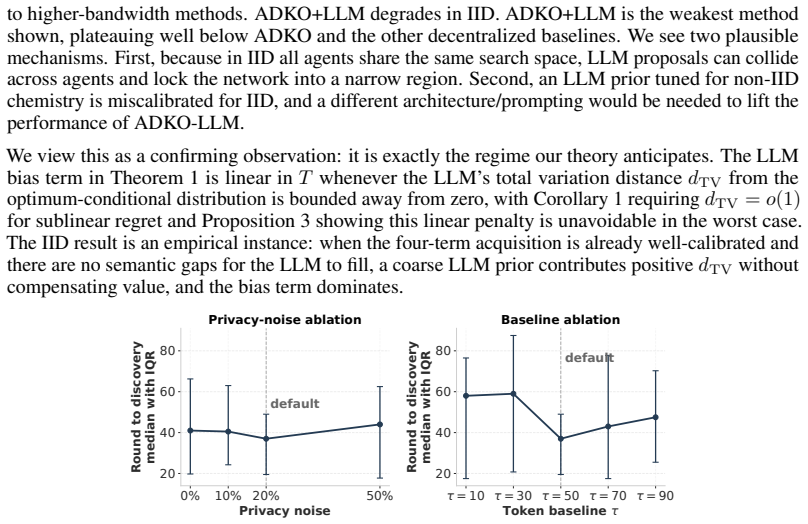
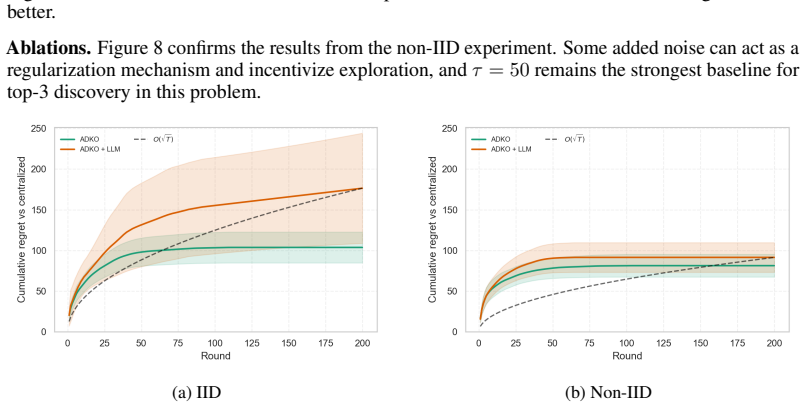
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.