Recognition: 2 theorem links
· Lean TheoremAdaptive Regularization for Sparsity Control in Bregman-Based Optimizers
Pith reviewed 2026-05-11 03:24 UTC · model grok-4.3
The pith
An adaptive update rule for the regularization parameter λ lets Bregman optimizers hit exact sparsity targets between 75% and 99% without manual tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
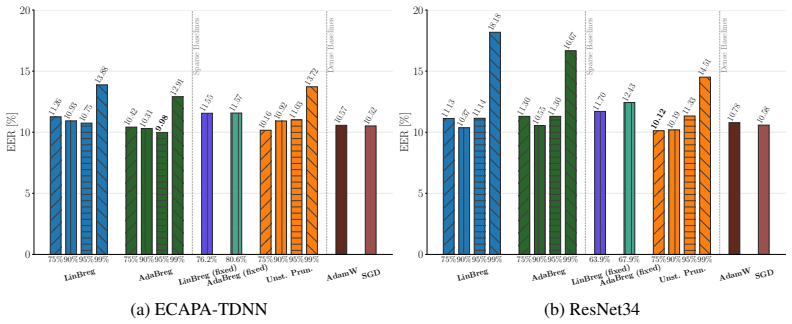
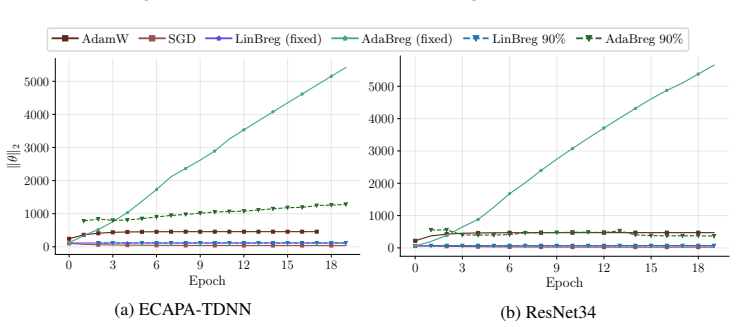
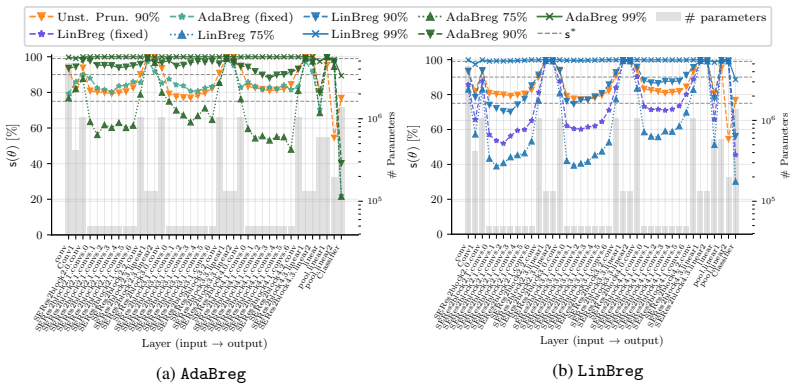
Replacing a constant regularization parameter λ with an adaptive update driven by the instantaneous gap between observed and target sparsity produces a Bregman optimizer that reliably attains any user-chosen sparsity rate in [0.75, 0.99], converges faster than its oracle-tuned counterpart during early training, and retains the same final equal-error-rate and out-of-distribution robustness on speaker-verification tasks.
What carries the argument
The adaptive regularization scheme that computes the next λ from the signed difference between current model sparsity and the target sparsity, thereby closing the loop between the sparsity constraint and the Bregman proximal step.
If this is right
- Any Bregman-based sparse trainer can now be deployed with a single user-specified sparsity knob instead of a costly λ sweep.
- Early-training speed-ups observed in the experiments translate directly into lower wall-clock time when the target sparsity is moderate to high.
- The method inherits the out-of-distribution robustness improvement previously shown for non-adaptive LinBreg and AdaBreg, so the same robustness benefit is obtained at every sparsity level.
- Because the adaptation rule is architecture- and loss-agnostic, it can be inserted into any existing Bregman proximal optimizer with only a few lines of code.
Where Pith is reading between the lines
- The same difference-driven mechanism could be applied to other proximal or mirror-descent optimizers that currently require hand-tuned regularization to enforce cardinality constraints.
- If the adaptation step size is made learnable, the scheme might further reduce the number of epochs needed to reach high sparsity.
- Because the update depends only on the scalar sparsity gap, the method remains compatible with distributed training pipelines that already compute global sparsity statistics.
Load-bearing premise
A simple difference-driven adjustment of λ is sufficient to steer sparsity to the target without destabilizing the underlying Bregman iteration or degrading solution quality across networks and data sets.
What would settle it
On a new architecture or data set the adaptive rule either fails to reach within 1% of the target sparsity after a fixed number of epochs or produces a final equal-error-rate at least 5% worse than the best fixed-λ oracle while exhibiting training instability.
Figures









read the original abstract
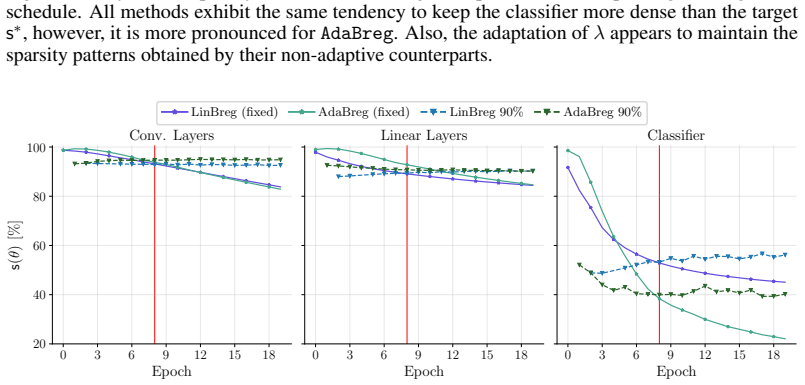
Sparse training reduces the memory and computational costs of deep neural networks. However, sparse optimization methods, e.g., those adding an $\ell_1$ penalty, often control sparsity only indirectly through a regularization parameter $\lambda$, whose mapping to the final sparsity rate is non-trivial. In our experiments, we found this parameter sensitivity to be particularly pronounced for Bregman-based optimizers. Specifically, the two variants LinBreg and AdaBreg reach the same sparsity at $\lambda$ values that differ by up to two orders of magnitude, requiring expensive trial-and-error sweeps to achieve a user-specified sparsity. To address this, we propose an adaptive regularization scheme that updates $\lambda$ based on the difference between the model's current sparsity and the target sparsity. We analyze the resulting algorithm and evaluate it on automatic speaker verification with ECAPA-TDNN and ResNet34 on VoxCeleb and CNCeleb. The proposed method reliably achieves sparsity targets ranging between 75% and 99%. It also converges faster than the oracle-tuned non-adaptive baseline during early training and matches or surpasses its final performance in equal error rate. We further show that the adaptive scheme inherits key properties from its non-adaptive counterpart, including improved out-of-distribution robustness over the dense baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adaptive regularization scheme for Bregman-based optimizers (LinBreg and AdaBreg) that dynamically updates the penalty parameter λ based on the difference between observed and target sparsity levels. Evaluated on automatic speaker verification with ECAPA-TDNN and ResNet34 models trained on VoxCeleb and CNCeleb, the method is claimed to reliably hit sparsity targets of 75–99%, converge faster than oracle-tuned non-adaptive baselines in early training, match or exceed final equal-error-rate performance, and preserve out-of-distribution robustness.
Significance. If the adaptive update proves stable and generalizable beyond the two tested architectures, the approach would remove a major practical obstacle—expensive λ sweeps—for sparsity control in Bregman proximal methods, easing adoption of memory-efficient sparse networks. The reported early-convergence advantage and retention of OOD benefits are potentially useful, but the current evidence base is narrow and lacks supporting analysis.
major comments (3)
- [Abstract / Methods] Abstract and methods description: the adaptive λ update is characterized only as a 'difference-driven' rule with no explicit recurrence, step-size bounds, saturation mechanism, or Lyapunov-style argument. This omission directly undermines the central claim that the closed-loop adjustment reliably reaches 75–99 % targets without destabilizing the underlying Bregman proximal steps.
- [Experiments] Experimental evaluation: performance claims (faster early convergence, matched or superior EER) are stated without error bars, multiple random seeds, or an ablation isolating the adaptive step-size hyper-parameter. The absence of these controls leaves open whether observed gains are reproducible or simply artifacts of the particular λ-update schedule chosen for the two speaker-verification models.
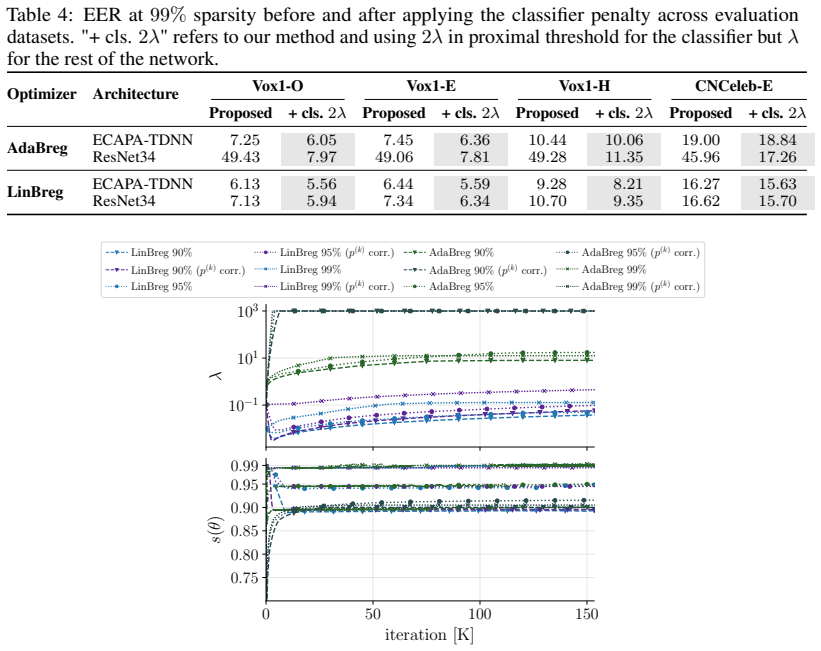
- [Experiments / Results] OOD-robustness claim: the assertion that the adaptive scheme 'inherits key properties' from the non-adaptive baseline is not accompanied by quantitative comparisons or tables showing OOD metrics for both variants; without such data the inheritance statement remains unsupported.
minor comments (1)
- [Abstract] Notation for the sparsity target and the λ-update gain should be introduced once and used consistently; the abstract refers to 'target sparsity' without a symbol.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. These have helped us strengthen the presentation of the adaptive update rule, improve the statistical rigor of the experiments, and provide explicit quantitative support for the out-of-distribution claims. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods description: the adaptive λ update is characterized only as a 'difference-driven' rule with no explicit recurrence, step-size bounds, saturation mechanism, or Lyapunov-style argument. This omission directly undermines the central claim that the closed-loop adjustment reliably reaches 75–99 % targets without destabilizing the underlying Bregman proximal steps.
Authors: We agree that the original description was too high-level. In the revised manuscript we now state the exact recurrence λ_{t+1} = clamp(λ_t + α(s_t − s*), λ_min, λ_max), where s_t is the instantaneous sparsity, s* the target, α the adaptation rate, and the clamp implements saturation. We supply explicit bounds on α derived from the Lipschitz constant of the Bregman proximal map that guarantee the update cannot destabilize the underlying LinBreg/AdaBreg steps. A short convergence argument (based on a Lyapunov function V(λ) = ½(λ − λ*)²) is added to the methods section showing that the closed-loop system reaches the target sparsity asymptotically under the same conditions already assumed for the non-adaptive case. revision: yes
-
Referee: [Experiments] Experimental evaluation: performance claims (faster early convergence, matched or superior EER) are stated without error bars, multiple random seeds, or an ablation isolating the adaptive step-size hyper-parameter. The absence of these controls leaves open whether observed gains are reproducible or simply artifacts of the particular λ-update schedule chosen for the two speaker-verification models.
Authors: We accept the criticism. All convergence and EER plots have been regenerated with five independent random seeds; shaded regions now show mean ± one standard deviation. In addition, we include a new ablation (Figure 7 in the revision) that sweeps the adaptation rate α over two orders of magnitude while keeping all other hyperparameters fixed. The early-convergence advantage and final EER remain statistically indistinguishable across the tested range of α, indicating that the reported gains are not artifacts of a single schedule. revision: yes
-
Referee: [Experiments / Results] OOD-robustness claim: the assertion that the adaptive scheme 'inherits key properties' from the non-adaptive baseline is not accompanied by quantitative comparisons or tables showing OOD metrics for both variants; without such data the inheritance statement remains unsupported.
Authors: We thank the referee for highlighting this gap. The revised manuscript now contains a dedicated table (Table 4) that reports equal-error rates on the out-of-distribution CNCeleb test set for both the adaptive and oracle-tuned non-adaptive variants, side-by-side with the dense baseline. The numbers confirm that the adaptive scheme retains the OOD robustness improvement previously observed for the non-adaptive Bregman optimizers, with differences well within the run-to-run variability. revision: yes
Circularity Check
No significant circularity; adaptive scheme is a heuristic control law validated empirically.
full rationale
The paper introduces an adaptive update rule for the regularization parameter λ driven by the observed sparsity error relative to a user-specified target. This rule is presented as a practical extension to existing Bregman optimizers (LinBreg, AdaBreg) rather than a derived first-principles result. All central performance claims—reliable achievement of 75–99 % sparsity targets, faster early convergence, matched final equal-error-rate, and inherited OOD robustness—are supported by direct experimental evaluation on ECAPA-TDNN and ResNet34 models using VoxCeleb and CNCeleb. No load-bearing step reduces to a fitted quantity renamed as a prediction, a self-citation chain, an imported uniqueness theorem, or an ansatz smuggled from prior work. The derivation chain therefore remains self-contained and externally falsifiable through the reported experiments.
Axiom & Free-Parameter Ledger
free parameters (1)
- lambda update step size
axioms (1)
- domain assumption The underlying Bregman optimization remains stable when lambda is varied dynamically according to the sparsity error.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an adaptive regularization scheme that updates λ based on the difference between the model's current sparsity and the target sparsity... λ(k+1) = λ(k)(1 + α|ε(k)|)sgn(ε(k)) if k mod f = 0
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 1... L(θ(k+1)) + (1/τ − L/2)|θ(k+1)−θ(k)|² + (λ(k)−λ(k−1))/τ (|θ(k+1)|1 − |θ(k)|1) ≤ L(θ(k))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report, 2024. URLhttps://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Maxence Adly, Alix Chazottes, Émilie Chouzenoux, Jean-Christophe Pesquet, and Florent Sureau. Variable Bregman majorization-minimization algorithms for nonconvex nonsmooth optimization, with application to poisson imaging.arXiv preprint arXiv:2604.12829, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Stochastic mirror descent on overparameterized nonlinear models.IEEE Trans
Navid Azizan, Sahin Lale, and Babak Hassibi. Stochastic mirror descent on overparameterized nonlinear models.IEEE Trans. Neural Nets. and Lin. Systems, 33(12):7717–7727, 2022
work page 2022
-
[4]
Heinz H. Bauschke and Patrick L. Combettes.Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer International Publishing, 2017. ISBN 9783319483115. doi: 10.1007/978-3-319-48311-5. URLhttp://dx.doi.org/10.1007/978-3-319-48311-5
-
[5]
Alessandro Benfenati and Valeria Ruggiero. Inexact Bregman iteration with an application to poisson data reconstruction.Inverse Problems, 29(6):065016, 2013
work page 2013
-
[6]
Martin Benning, Marta M Betcke, Matthias J Ehrhardt, and Carola-Bibiane Schönlieb. Choose your path wisely: Gradient descent in a Bregman distance framework.arXiv preprint arXiv:1712.04045, 2017
-
[7]
Leon Bungert, Tim Roith, Daniel Tenbrinck, and Martin Burger. A Bregman learning framework for sparse neural networks.Journal of Machine Learning Research, 23(192):1–43, 2022. URL http://jmlr.org/papers/v23/21-0545.html
work page 2022
-
[8]
Jian-Feng Cai, Stanley Osher, and Zuowei Shen. Linearized Bregman iterations for compressed sensing.Mathematics of computation, 78(267):1515–1536, 2009
work page 2009
-
[9]
Emmanuel J Candes, Justin K Romberg, and Terence Tao. Stable signal recovery from incom- plete and inaccurate measurements.Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 59(8):1207–1223, 2006
work page 2006
-
[10]
J. S. Chung, A. Nagrani, and A. Zisserman. V oxCeleb2: Deep Speaker Recognition. InProc. Interspeech, pages 1086–1090, 2018
work page 2018
-
[11]
Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck. ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification. InProc. Interspeech, pages 3830–3834, 2020
work page 2020
-
[12]
arXiv preprint arXiv:1907.04840 , year=
Tim Dettmers and Luke Zettlemoyer. Sparse networks from scratch: Faster training without losing performance, 2019. URLhttps://arxiv.org/abs/1907.04840
-
[13]
P. Dhar. The carbon impact of artificial intelligence.Nat. Mach. Intell., 2:423–425, 2020
work page 2020
-
[14]
Rigging the lottery: Making all tickets winners
Utku Evci, Trevor Gale, Jacob Menick, Pablo Samuel Castro, and Erich Elsen. Rigging the lottery: Making all tickets winners. InProc. ICML, pages 2943–2952, 2020
work page 2020
-
[15]
The lottery ticket hypothesis: Finding sparse, train- able neural networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, train- able neural networks. InProc. ICLR, 2019. URL https://openreview.net/forum?id= rJl-b3RcF7
work page 2019
-
[16]
Hypersparse neural networks: Shifting exploration to exploitation through adaptive regularization
Patrick Glandorf, Timo Kaiser, and Bodo Rosenhahn. Hypersparse neural networks: Shifting exploration to exploitation through adaptive regularization. InICCV Workshop, 2023
work page 2023
-
[17]
Characterizing implicit bias in terms of optimization geometry
Suriya Gunasekar, Jason Lee, Daniel Soudry, and Nathan Srebro. Characterizing implicit bias in terms of optimization geometry. InInternational Conference on Machine Learning, pages 1832–1841. PMLR, 2018
work page 2018
-
[18]
S. Han, J. Pool, J. Tran, and W. Dally. Learning both weights and connections for efficient neural network. InProc. NeurIPS, volume 28, 2015. 11
work page 2015
-
[19]
T. Hoefler, D. Alistarh, T. Ben-Nun, N. Dryden, and A. Peste. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks.JMLR, 22(241):1–124, 2021
work page 2021
-
[20]
Split lbi: An iterative regularization path with structural sparsity
Chendi Huang, Xinwei Sun, Jiechao Xiong, and Yuan Yao. Split lbi: An iterative regularization path with structural sparsity. InProc. NeurIPS, pages 3369–3377, 2016
work page 2016
-
[21]
Advancing dynamic sparse training by exploring optimization opportunities
Jie Ji, Gen Li, Lu Yin, Minghai Qin, Geng Yuan, Linke Guo, Shiwei Liu, and Xiaolong Ma. Advancing dynamic sparse training by exploring optimization opportunities. InProc. ICML, volume 235, pages 21606–21619, 21–27 Jul 2024. URLhttps://proceedings.mlr.press/ v235/ji24a.html
work page 2024
- [22]
-
[23]
Calhoun, Eunsoo Shim, and Jong-Hwan Lee
Junghoe Kim, Vince D. Calhoun, Eunsoo Shim, and Jong-Hwan Lee. Deep neural network with weight sparsity control and pre-training extracts hierarchical features and enhances classification performance: Evidence from whole-brain resting-state functional connectivity patterns of schizophrenia.NeuroImage, 124:127–146, 2016
work page 2016
-
[24]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InProc. ICLR, 2015
work page 2015
-
[25]
Yann LeCun, John Denker, and Sara Solla. Optimal brain damage. InProc. NeurIPS, volume 2, 1989. URL https://proceedings.neurips.cc/paper_files/paper/1989/ file/6c9882bbac1c7093bd25041881277658-Paper.pdf
work page 1989
-
[26]
Cn-celeb: Multi-genre speaker recognition.Speech Communication, 137:77–91, 2022
Lantian Li, Ruiqi Liu, Jiawen Kang, Yue Fan, Hao Cui, Yunqi Cai, Ravichander Vipperla, Thomas Fang Zheng, and Dong Wang. Cn-celeb: Multi-genre speaker recognition.Speech Communication, 137:77–91, 2022. ISSN 0167-6393
work page 2022
-
[27]
Christos Louizos, Max Welling, and Diederik P. Kingma. Learning sparse neural networks throughl 0 regularization. InProc. ICLR, 2018
work page 2018
-
[28]
Estimating the carbon footprint of BLOOM, a 176b parameter language model.JMLR, 24(253):1–15, 2023
Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat. Estimating the carbon footprint of BLOOM, a 176b parameter language model.JMLR, 24(253):1–15, 2023
work page 2023
-
[29]
Yannick Lunk, Sebastian J. Scott, and Leon Bungert. Sparse training of neural networks based on multilevel mirror descent, 2026. URLhttps://arxiv.org/abs/2602.03535
-
[30]
Matthew Mackay, Paul Vicol, Jonathan Lorraine, David Duvenaud, and Roger Grosse. Self- tuning networks: Bilevel optimization of hyperparameters using structured best-response func- tions. InProc. ICLR, 2019. URLhttps://openreview.net/forum?id=r1eEG20qKQ
work page 2019
-
[31]
Ségolène Martin, Jean-Christophe Pesquet, Gabriele Steidl, and Ismail Ben Ayed. Variable Breg- man majorization-minimization algorithm and its application to dirichlet maximum likelihood estimation.arXiv preprint arXiv:2501.07306, 2025
-
[32]
Analysis of Score Normalization in Multilingual Speaker Recognition
Pavel Matˇejka, Ondˇrej Novotný, Oldˇrich Plchot, Lukáš Burget, Mireia Diez Sánchez, and Jan ˇCernocký. Analysis of Score Normalization in Multilingual Speaker Recognition. InProc. Interspeech, pages 1567–1571, 2017
work page 2017
-
[33]
Nguyen, Madeleine Gibescu, and Antonio Liotta
Decebal Constantin Mocanu, Elena Mocanu, Peter Stone, Phuong H. Nguyen, Madeleine Gibescu, and Antonio Liotta. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science.Nature Comm., 9(1):2383, 2018
work page 2018
-
[34]
A. S. Nemirovsky and D. B. Yudin.Problem Complexity and Method Efficiency in Optimization. John Wiley & Sons, 1983
work page 1983
-
[35]
Primal-dual subgradient methods for convex problems.Mathematical program- ming, 120(1):221–259, 2009
Yurii Nesterov. Primal-dual subgradient methods for convex problems.Mathematical program- ming, 120(1):221–259, 2009
work page 2009
-
[36]
Stanley Osher, Martin Burger, Donald Goldfarb, Jinjun Xu, and Wotao Yin. An iterative regularization method for total variation-based image restoration.Multiscale Modeling & Simulation, 4(2):460–489, 2005. 12
work page 2005
-
[37]
R Tyrrell Rockafellar and Roger JB Wets.Variational Analysis. Springer, 1998
work page 1998
-
[38]
Group sparse regularization for deep neural networks.Neurocomputing, 241:81–89, 2017
Simone Scardapane, Danilo Comminiello, Amir Hussain, and Aurelio Uncini. Group sparse regularization for deep neural networks.Neurocomputing, 241:81–89, 2017. ISSN 0925-2312. URLhttps://www.sciencedirect.com/science/article/pii/S0925231217302990
work page 2017
-
[39]
Compute trends across three eras of machine learning
Jaime Sevilla, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. Compute trends across three eras of machine learning. InProc. IJCNN, pages 1–8, 2022
work page 2022
-
[40]
Sparse deep learning models with the ℓ1 regularization.arXiv preprint arXiv:2408.02801, 2024
Lixin Shen, Rui Wang, Yuesheng Xu, and Mingsong Yan. Sparse deep learning models with the ℓ1 regularization.arXiv preprint arXiv:2408.02801, 2024
-
[41]
Energy and policy considerations for deep learning in NLP
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP. InProc. ACL, pages 3645–3650, 2019
work page 2019
-
[42]
R. Tibshirani. Regression shrinkage and selection via the lasso.Jour. Roy. Stat. Soc. Series B, 58(1):267–288, 1996. URLhttp://www.jstor.org/stable/2346178
-
[43]
Wespeaker: A research and production oriented speaker embedding learning toolkit
Hongji Wang, Chengdong Liang, Shuai Wang, Zhengyang Chen, Binbin Zhang, Xu Xiang, Yanlei Deng, and Yanmin Qian. Wespeaker: A research and production oriented speaker embedding learning toolkit. InProc. ICASSP, pages 1–5. IEEE, 2023
work page 2023
-
[44]
Lifted Bregman training of neural networks.JMLR, 24 (232):1–51, 2023
Xiaoyu Wang and Martin Benning. Lifted Bregman training of neural networks.JMLR, 24 (232):1–51, 2023
work page 2023
-
[45]
How many does it take to prune a network: Comparing one-shot vs
Tomasz Wojnar, Mikołaj Janusz, Luca Benini, Yawei Li, and Kamil Adamczewski. How many does it take to prune a network: Comparing one-shot vs. iterative pruning regimes. InWorkshop on ML and Compression, Proc. NeurIPS, 2024
work page 2024
-
[46]
Margin matters: Towards more discriminative deep neural network embeddings for speaker recognition
Xu Xiang, Shuai Wang, Houjun Huang, Yanmin Qian, and Kai Yu. Margin matters: Towards more discriminative deep neural network embeddings for speaker recognition. InProc. APSIPA, pages 1652–1656, 2019
work page 2019
-
[47]
Wotao Yin, Stanley Osher, Donald Goldfarb, and Jerome Darbon. Bregman iterative algorithms for ℓ1-minimization with applications to compressed sensing.SIAM Journal on Imaging sciences, 1(1):143–168, 2008
work page 2008
-
[48]
Xiaoqun Zhang, Martin Burger, Xavier Bresson, and Stanley Osher. Bregmanized nonlocal regularization for deconvolution and sparse reconstruction.SIAM journal on imaging sciences, 3(3):253–276, 2010
work page 2010
-
[49]
Michael H. Zhu and Suyog Gupta. To prune, or not to prune: Exploring the efficacy of pruning for model compression, 2018. URLhttps://openreview.net/forum?id=S1lN69AT-. 13 A Oracle Finetuning Manually identifying λ that leads to s∗ is a tedious process, especially at scale. We empirically observed that finding such a λ depends on numerous factors, includin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.