Recognition: no theorem link
Aggregation in conformal e-classification
Pith reviewed 2026-05-11 02:27 UTC · model grok-4.3
The pith
Conformal e-predictors can be aggregated more flexibly than standard conformal predictors while retaining validity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
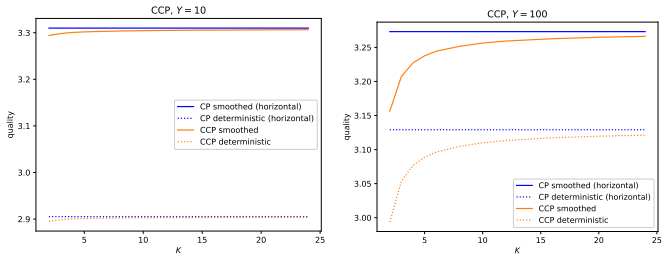
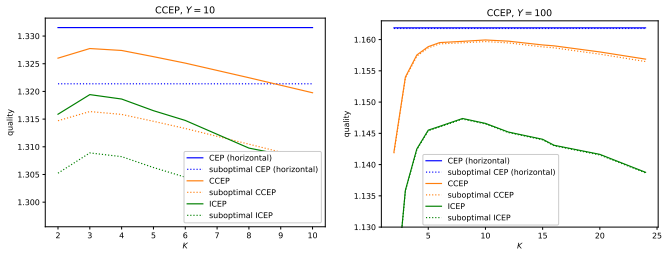
An important advantage of conformal e-predictors is that they are easier to aggregate without sacrificing their validity. The paper studies experimentally cross-conformal e-prediction, which is an existing method of aggregating conformal e-predictors, and its modifications that are conceptually simpler and more flexible.
What carries the argument
Cross-conformal e-prediction, the method that merges e-predictors trained on different data splits or folds to form a combined predictor.
If this is right
- Practitioners can combine several e-predictors to reach better efficiency without extra validity cost.
- The simpler modifications allow aggregation in settings where the original cross-conformal procedure is inconvenient to implement.
- Predictive performance and computational load can be balanced more directly in e-classification tasks.
- Validity remains approximately intact after aggregation, supporting reliable use in applications that require guarantees.
Where Pith is reading between the lines
- The flexibility of these methods could support incremental updating of predictors as new data arrives without full retraining.
- Similar aggregation ideas might apply to regression or other output types beyond classification.
- If the simpler variants scale to very large datasets, they could reduce the engineering effort needed for valid predictive systems.
Load-bearing premise
The observed behavior of the aggregation methods on the chosen datasets and tasks will continue to hold on new data and different classification problems.
What would settle it
Apply the same aggregation procedures to several fresh, unrelated classification datasets and measure whether the combined e-predictors violate their validity bounds substantially more often than the individual predictors do.
Figures







read the original abstract
Aggregating conformal predictors is a standard way of balancing their predictive and computational efficiency while retaining their validity, at least approximately. An important advantage of conformal e-predictors is that they are easier to aggregate without sacrificing their validity. This paper studies experimentally cross-conformal e-prediction, which is an existing method of aggregating conformal e-predictors, and its modifications that are conceptually simpler and more flexible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript experimentally studies cross-conformal e-prediction, an existing method for aggregating conformal e-predictors, along with conceptually simpler and more flexible modifications. It frames the ease of aggregation for e-predictors (without sacrificing validity) as background motivation for the experimental comparison.
Significance. If the experimental comparisons hold, the work could provide practical guidance on simpler aggregation strategies for conformal predictors, which is relevant for balancing validity guarantees with computational efficiency in machine learning applications. The experimental framing allows direct assessment of the proposed modifications relative to the existing cross-conformal approach.
minor comments (1)
- [Abstract] The abstract describes an experimental study but provides no details on datasets, baselines, error bars, or statistical tests, making it impossible to assess whether the data supports the claims about simplicity and flexibility.
Simulated Author's Rebuttal
We thank the referee for their positive review and recommendation of minor revision. We appreciate the acknowledgment that the experimental comparisons could offer practical guidance on aggregation strategies for conformal e-predictors.
Circularity Check
No significant circularity; experimental evaluation of existing methods
full rationale
The paper is framed as an experimental study of cross-conformal e-prediction (an existing method) and its modifications for aggregating conformal e-predictors. No derivations, equations, fitted parameters presented as predictions, or load-bearing self-citations are indicated in the provided abstract or description. The stated advantage of e-predictors for aggregation is background context rather than a new claim derived within the paper. The work is self-contained as empirical evaluation without reducing any central result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2411.11824 , year=
Anastasios N. Angelopoulos, Rina Foygel Barber, and Stephen Bates. Theoret- ical foundations of conformal prediction. Technical Report arXiv:2411.11824 [math.ST], arXiv.org e-Print archive, March
-
[2]
Aggregated conformal pre- diction
Lars Carlsson, Martin Eklund, and Ulf Norinder. Aggregated conformal pre- diction. In Lazaros Iliadis, Ilias Maglogiannis, Harris Papadopoulos, Spyros Sioutas, and Christos Makris, editors,AIAI Workshops, COPA 2014, volume 437 ofIFIP Advances in Information and Communication Technology, pages 231–240, Berlin,
work page 2014
-
[3]
Section 21.1 first appeared in the 4th edition (1932). Sander Greenland. Valid P-values behave exactly as they should: some mis- leading criticisms of P-values and their resolution with S-values.American Statistician, 73(S1):106–114,
work page 1932
-
[4]
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer.Algorithmic Learn- ing in a Random World
Revised version: arXiv:1912.13292v5. Vladimir Vovk, Alexander Gammerman, and Glenn Shafer.Algorithmic Learn- ing in a Random World. Springer, Cham, second edition,
-
[5]
21 A Some proofs A.1 Proof of Proposition 1 The argument of Vovk et al. (2022, Sect. 3.4.1, Remark 3.15) can be modified to cover this case as well (it is not covered by the original argument since the functionp∈[0,1]→ −lnptakes value∞atp:= 0, as mentioned at the end of the remark). Namely, we can replace the second displayed equation in Vovk et al. (2022...
work page 2022
-
[6]
Then (11) holds conditionally on the training set and, therefore, unconditionally
conditionally on the training set. Then (11) holds conditionally on the training set and, therefore, unconditionally. To show that there is a unique solution to (11), suppose there are two dif- ferent solutions. Then their arithmetic mean will provide a better value for the objective function in (11) by Jensen’s inequality. The value will be strictly bet-...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.