Recognition: 2 theorem links
· Lean TheoremSusceptibilities and Patterning: A Primer on Linear Response in Bayesian Learning
Pith reviewed 2026-05-11 02:06 UTC · model grok-4.3
The pith
The susceptibility matrix functions as the Jacobian mapping changes in data distributions to shifts in structural coordinates of Bayesian neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Susceptibility of an observable φ to a data perturbation is defined as the derivative of its posterior expectation; by the fluctuation-dissipation theorem this equals the corresponding posterior covariance. When φ is chosen as a per-sample loss the result is the influence matrix, while component-localized observables produce the structural susceptibility matrix. The latter matrix is proportional to the Jacobian of the map from data distributions to structural coordinates, and its pseudo-inverse supplies a first-order solution to the patterning problem of finding data perturbations that realize a prescribed structural shift.
What carries the argument
The susceptibility matrix, obtained either as the derivative of a posterior expectation or as a posterior covariance, that serves as the Jacobian between data distributions and structural coordinates.
If this is right
- Empirical estimators for susceptibilities can be computed from posterior samples without additional model training.
- The influence matrix recovers the Bayesian influence function as a special case.
- Structural susceptibilities pair individual model components with specific data patterns through covariance terms.
- Pseudo-inverse application gives an explicit linear formula for data perturbations that target desired structural adjustments.
- The construction connects posterior geometry to the loss landscape via linear response.
Where Pith is reading between the lines
- The same framework could be tested on non-neural models such as Bayesian linear regression to check whether the Jacobian interpretation holds outside deep networks.
- One could compare the linearized patterning solutions against full nonlinear optimization of data perturbations on held-out tasks to measure the range of validity.
- Structural susceptibilities might be used to generate targeted data augmentations that steer component activations in deployed models.
- The approach suggests a route to sensitivity analysis in continual learning settings where data distributions shift over time.
Load-bearing premise
The fluctuation-dissipation theorem applies directly to the posterior distribution arising in Bayesian neural network training, and structural coordinates are well-defined with the relevant map being differentiable.
What would settle it
For a small Bayesian neural network, compute the empirical susceptibility matrix and its pseudo-inverse, apply the predicted data perturbation, and verify whether the observed change in structural coordinates matches the first-order prediction within the linear regime.
Figures

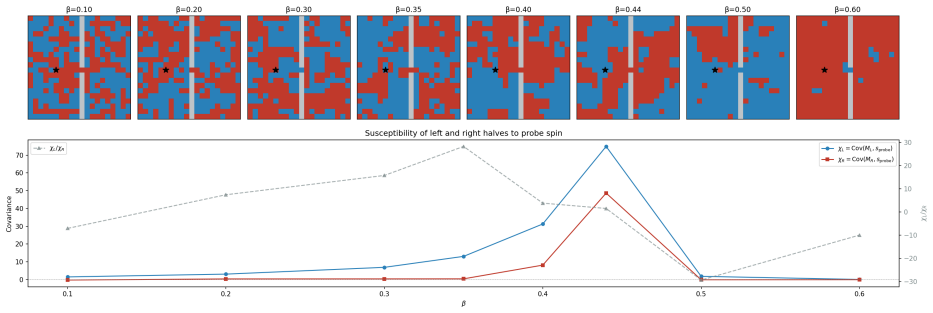

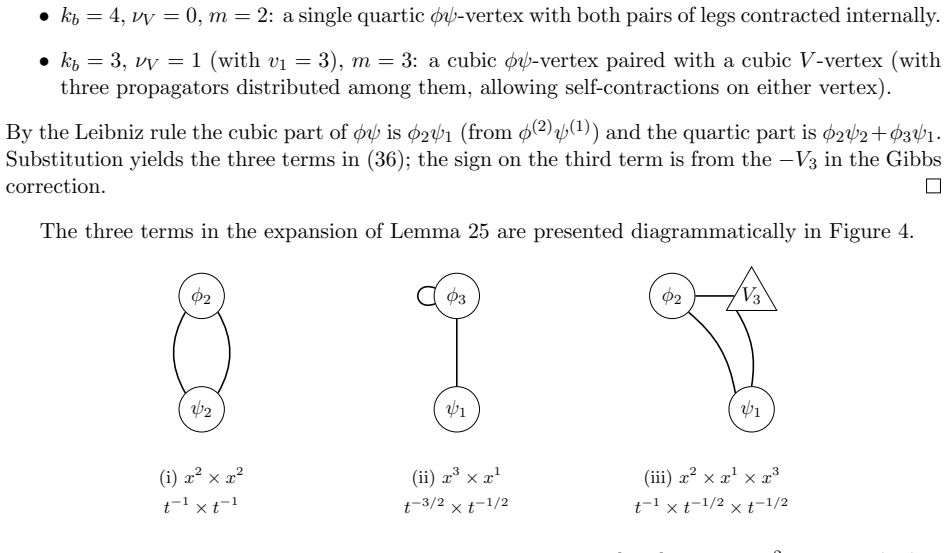
read the original abstract
These notes introduce the theory of susceptibilities as developed in [arXiv:2504.18274, arXiv:2601.12703] for interpreting neural networks. The susceptibility of an observable $\phi$ to a data perturbation is defined as a derivative of a posterior expectation, which by the fluctuation--dissipation theorem equals a posterior covariance. Different choices of $\phi$ yield different objects: per-sample losses give the influence matrix (the Bayesian influence function of [arXiv:2509.26544]), while component-localized observables give the structural susceptibility matrix that pairs model components with data patterns. The susceptibility matrix is (up to a factor of $n\beta$) the Jacobian of the map from data distributions to structural coordinates; its pseudo-inverse provides a linearized solution to the patterning problem of [arXiv:2601.13548]: finding data perturbations that produce a desired structural change. We motivate the theory from its statistical-mechanical foundations, then give a detailed exposition of susceptibilities, their empirical estimators, and their connection to the geometry of the loss landscape.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a primer introducing the theory of susceptibilities for interpreting Bayesian neural networks, developed from prior works. It defines the susceptibility of an observable φ to data perturbations as the derivative of its posterior expectation under the Gibbs posterior; by the fluctuation-dissipation theorem this equals a posterior covariance. Per-sample losses yield the influence matrix (Bayesian influence function), while component-localized observables yield the structural susceptibility matrix. The latter is (up to a factor of nβ) the Jacobian of the map from data distributions to structural coordinates; its pseudo-inverse supplies a linearized solution to the patterning problem of finding data perturbations that induce a desired structural change. The exposition motivates the framework from statistical-mechanical foundations, details empirical estimators, and connects the objects to loss-landscape geometry.
Significance. If the identifications hold, the work supplies a coherent linear-response framework that links Bayesian posteriors over neural-network parameters to interpretable structural coordinates via data perturbations. The explicit connection between the susceptibility matrix and the Jacobian of the data-to-structure map, together with the pseudo-inverse patterning operator, offers a concrete computational handle on how changes in the training distribution affect model components. The provision of empirical estimators and the grounding in loss-landscape geometry are practical strengths that could support downstream applications in model auditing and data design.
minor comments (3)
- The abstract states that the susceptibility matrix is the Jacobian 'up to a factor of nβ' but does not define n or β at that point; a parenthetical reminder of their meanings (sample size and inverse temperature) would improve readability for readers who begin with the abstract.
- The patterning problem is referenced via arXiv:2601.13548 without a one-sentence recap of its precise formulation; adding a brief inline definition would make the claim about the pseudo-inverse self-contained.
- Empirical estimators are mentioned in the abstract and presumably detailed later; a short pseudocode block or explicit formula for the Monte-Carlo estimator of the structural susceptibility matrix would help readers implement the method.
Simulated Author's Rebuttal
We thank the referee for the careful and accurate summary of the manuscript, the positive assessment of its significance, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
Susceptibility-to-Jacobian identification is definitional by construction
specific steps
-
self definitional
[Abstract]
"The susceptibility of an observable ϕ to a data perturbation is defined as a derivative of a posterior expectation, which by the fluctuation--dissipation theorem equals a posterior covariance. ... component-localized observables give the structural susceptibility matrix ... The susceptibility matrix is (up to a factor of nβ) the Jacobian of the map from data distributions to structural coordinates"
Susceptibility is defined precisely as the indicated derivative of a posterior expectation under data perturbation. Structural coordinates are the posterior expectations of the component-localized observables. The matrix of these derivatives is therefore the Jacobian matrix by definition, rendering the stated equivalence tautological rather than a non-trivial result obtained from the statistical-mechanical motivation or loss-landscape geometry.
full rationale
The paper is an expository primer on concepts from prior self-authored works. Its central claim equates the susceptibility matrix to the Jacobian of the data-to-structural map. This reduces directly to the paper's own definition of susceptibility as the derivative of a posterior expectation (with structural coordinates arising from the same observables), plus invocation of the fluctuation-dissipation theorem. No independent derivation or external benchmark is supplied for this equivalence within the present manuscript; the identification holds by the definitional setup rather than as a derived prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fluctuation-dissipation theorem holds for the posterior distribution in Bayesian learning
invented entities (2)
-
structural susceptibility matrix
no independent evidence
-
structural coordinates
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
- [4]
- [5]
- [6]
-
[7]
B. Gerraty and D. Murfet. Expectations and the exceptional divisor. In preparation, 2026
work page 2026
-
[8]
G. Wang and D. Murfet. Patterning: The dual of interpretability.arXiv:2601.13548, 2026
-
[9]
D. Gromoll and W. Meyer. On differentiable functions with isolated critical points.Topology, 8:361–369, 1969
work page 1969
- [10]
-
[11]
Watanabe.Algebraic Geometry and Statistical Learning Theory
S. Watanabe.Algebraic Geometry and Statistical Learning Theory. Cambridge University Press, 2009
work page 2009
- [12]
-
[13]
H. B. Callen.Thermodynamics and an Introduction to Thermostatistics. John Wiley & Sons, 2nd edition, 1985. 32
work page 1985
-
[14]
R. Kubo. The fluctuation-dissipation theorem.Reports on Progress in Physics, 29(1):255–284, 1966
work page 1966
-
[15]
P. S. Laplace. Memoir on the probability of the causes of events.Statistical Science, 1(3):364– 378, 1986. Translation by S. M. Stigler ofM´ emoire sur la probabilit´ e des causes par les ´ ev` enements(1774)
work page 1986
-
[16]
C. M. Bender and S. A. Orszag.Advanced Mathematical Methods for Scientists and Engineers. Springer, 1999
work page 1999
-
[17]
L. Tierney and J. B. Kadane. Accurate approximations for posterior moments and marginal densities.Journal of the American Statistical Association, 81(393):82–86, 1986
work page 1986
-
[18]
M. Welling and Y. W. Teh. Bayesian learning via stochastic gradient Langevin dynamics. In Proceedings of the 28th International Conference on Machine Learning, pages 681–688, 2011
work page 2011
-
[19]
J. Hoogland, G. Wang, M. Farrugia-Roberts, L. Carroll, S. Wei, and D. Murfet. Loss landscape degeneracy and stagewise development in transformers.arXiv:2402.02364, 2024
- [20]
- [21]
-
[22]
C. Elliott and D. Murfet. Linear response estimators for singular statistical models.arXiv preprint, 2026
work page 2026
-
[23]
R. Giordano, T. Broderick, and M. I. Jordan. Covariances, robustness, and variational Bayes. Journal of Machine Learning Research, 19(51):1–49, 2018
work page 2018
-
[24]
R. Giordano and T. Broderick. The Bayesian infinitesimal jackknife for variance. arXiv:2305.06466, 2024
- [25]
-
[26]
R. Penrose. On best approximate solutions of linear matrix equations.Mathematical Proceed- ings of the Cambridge Philosophical Society, 52(1):17–19, 1956
work page 1956
-
[27]
F. R. Hampel. The influence curve and its role in robust estimation.Journal of the American Statistical Association, 69(346):383–393, 1974
work page 1974
- [28]
-
[29]
R. Salazar, W. Troiani, B. Snikkers, and D. Murfet. Susceptibilities for Turing machines. In preparation, 2026
work page 2026
-
[30]
R. E. Kass, L. Tierney, and J. B. Kadane. The validity of posterior expansions based on Laplace’s method. In S. Geisser, J. S. Hodges, S. J. Press, and A. Zellner, editors,Bayesian and Likelihood Methods in Statistics and Econometrics: Essays in Honor of George A. Barnard, pages 473–488. North-Holland, Amsterdam, 1990. 33
work page 1990
-
[31]
Wong.Asymptotic Approximations of Integrals
R. Wong.Asymptotic Approximations of Integrals. SIAM, Philadelphia, classics edition, 2001
work page 2001
- [32]
-
[33]
Z. Shun and P. McCullagh. Laplace approximation of high dimensional integrals.Journal of the Royal Statistical Society. Series B (Methodological), 57(4):749–760, 1995. 34
work page 1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.