Recognition: 2 theorem links
· Lean TheoremInterpreting Reinforcement Learning Agents with Susceptibilities
Pith reviewed 2026-05-11 02:43 UTC · model grok-4.3
The pith
Susceptibilities applied to regret detect internal stages of RL agent development in parameter space that cannot be seen from the learned policy alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Susceptibilities, defined as the response of posterior expectation values of observables to perturbations of the loss, when generalized to the regret incurred by a reinforcement learning agent, reveal features of the model's development in parameter space that cannot be detected by studying the development of the learned policy alone, as shown in a gridworld model with non-trivial stagewise progress.
What carries the argument
Susceptibilities, which quantify the sensitivity of posterior expectations of observables to small changes in the loss (here generalized to regret).
If this is right
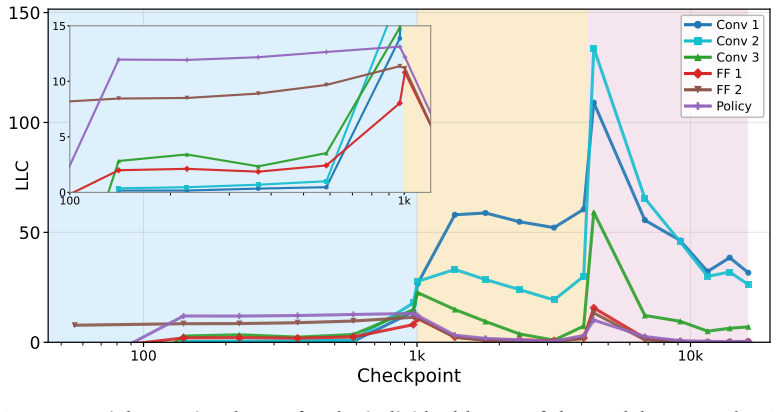
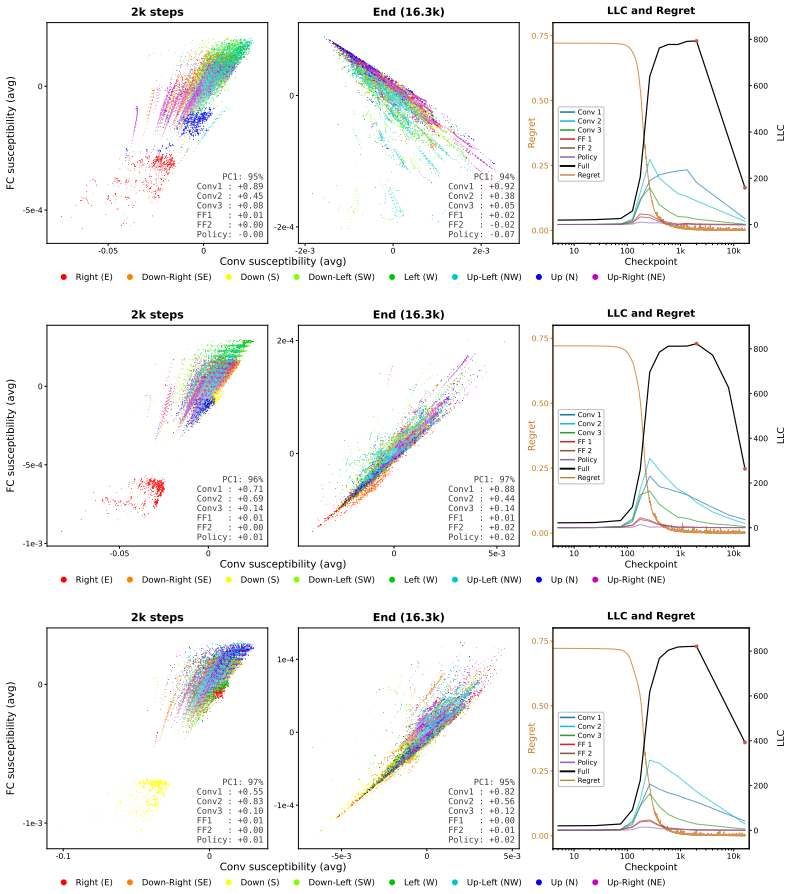
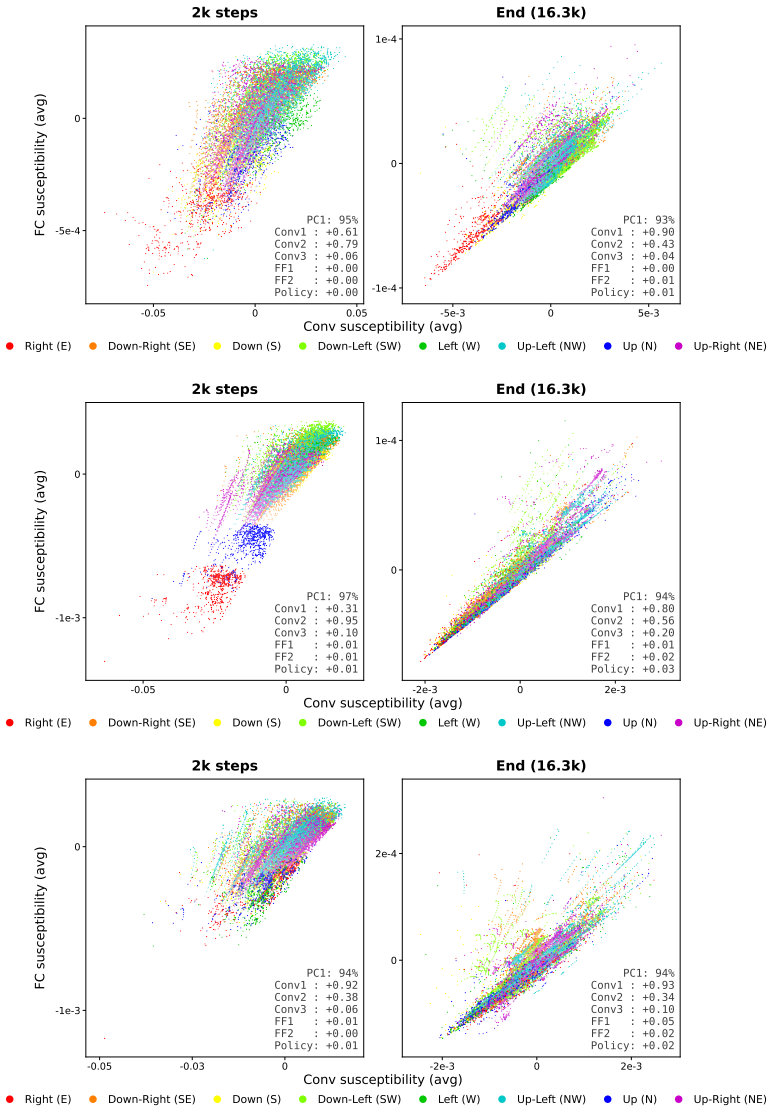
- In the gridworld, susceptibilities pick up stagewise internal changes during training.
- These changes are invisible when tracking only the policy's performance over time.
- Activation steering can be used to confirm that the susceptibility signals correspond to real internal features.
- The same construction is proposed as a route to interpretability in RLHF post-training.
Where Pith is reading between the lines
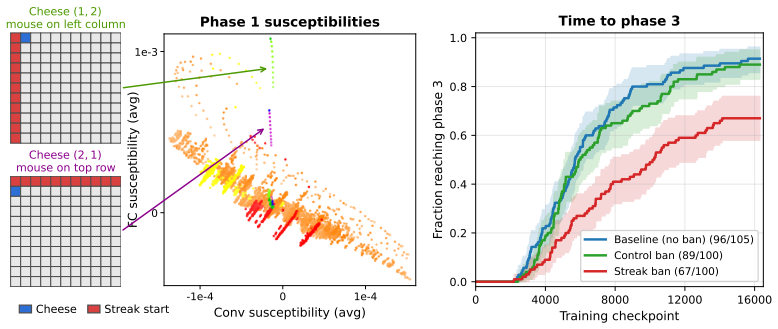
- If susceptibilities work in this gridworld, they could be applied to compare two agents that reach similar final policies but took different internal routes.
- The method might help diagnose when an agent's learning trajectory diverges from expectations even if its final behavior looks normal.
- Testing the same observables on larger environments would show whether the hidden parameter-space stages persist beyond toy settings.
Load-bearing premise
The simple gridworld model with non-trivial stagewise development is representative enough that the susceptibilities technique will generalize usefully to regret in deep RL agents and to RLHF post-training.
What would settle it
In a deeper RL agent or actual RLHF run, compute the susceptibilities and check whether they still identify parameter-space features that activation steering cannot confirm or that are already visible from the policy's learning curve alone.
Figures











read the original abstract
Susceptibilities are a technique for neural network interpretability that studies the response of posterior expectation values of observables to perturbations of the loss. We generalize this construction to the setting of the regret in deep reinforcement learning and investigate the utility of susceptibilities in a simple gridworld model that nevertheless exhibits non-trivial stagewise development. We argue that susceptibilities reveal internal features of the development of the model in parameter space that one cannot detect purely by studying the development of the learned policy. We validate these results with activation-steering, and discuss the framework's extension to RLHF post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper generalizes susceptibilities—a technique that studies the response of posterior expectation values of observables to perturbations of the loss—to the setting of regret in deep reinforcement learning. Using a simple gridworld model that exhibits non-trivial stagewise development, the authors argue that susceptibilities reveal internal features of model development in parameter space that cannot be detected purely by studying the learned policy. Results are validated via activation-steering, and potential extensions to RLHF post-training are discussed.
Significance. If the susceptibilities approach proves robust, it could supply a new interpretability lens for RL that distinguishes parameter-space developmental trajectories from observable policy behavior, with possible utility for diagnosing training dynamics in RLHF. The toy gridworld allows controlled demonstration of stagewise effects, but the significance hinges on whether the method isolates genuinely hidden features beyond standard regret or policy metrics.
major comments (2)
- [Gridworld Experiments] The central claim—that susceptibilities detect parameter-space features invisible to policy analysis—rests on the gridworld results, yet the manuscript provides no quantitative comparison (e.g., mutual information or divergence metrics) between susceptibility-derived features and those obtainable from policy trajectories or standard RL diagnostics such as per-stage regret curves.
- [Validation and Activation Steering] Activation-steering validation is performed exclusively within the same toy gridworld; this does not address whether the technique isolates information beyond what careful inspection of the learned policy or conventional RL metrics already reveal in high-dimensional deep RL or RLHF regimes where parameter and policy trajectories are more entangled.
minor comments (2)
- [Abstract] The abstract states the generalization and gridworld results but supplies no equations, quantitative metrics, error bars, or details on how susceptibilities are computed for regret; adding these would improve readability.
- [Discussion] The discussion of extension to RLHF post-training is high-level; concrete challenges (e.g., scaling of posterior expectations or choice of observables) or a small-scale RLHF pilot would clarify feasibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and note planned changes to the manuscript.
read point-by-point responses
-
Referee: [Gridworld Experiments] The central claim—that susceptibilities detect parameter-space features invisible to policy analysis—rests on the gridworld results, yet the manuscript provides no quantitative comparison (e.g., mutual information or divergence metrics) between susceptibility-derived features and those obtainable from policy trajectories or standard RL diagnostics such as per-stage regret curves.
Authors: We agree that the current presentation relies primarily on qualitative comparison and visualization. In the revised manuscript we will add explicit quantitative comparisons, including mutual information between susceptibility maps and policy-derived features as well as divergence metrics that contrast stage detection from susceptibilities against per-stage regret curves. These additions will directly quantify the incremental information provided by the susceptibilities approach. revision: yes
-
Referee: [Validation and Activation Steering] Activation-steering validation is performed exclusively within the same toy gridworld; this does not address whether the technique isolates information beyond what careful inspection of the learned policy or conventional RL metrics already reveal in high-dimensional deep RL or RLHF regimes where parameter and policy trajectories are more entangled.
Authors: The gridworld was selected precisely because it permits controlled observation of stagewise parameter-space development that remains hidden under policy inspection. Activation steering is used to validate the susceptibilities within this transparent setting. The manuscript does not claim or provide empirical results for high-dimensional RLHF; we will revise the discussion to state this scope limitation more explicitly while retaining the toy-model demonstration as a proof of concept. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines susceptibilities via the response of posterior expectations to loss perturbations, explicitly generalizes the construction to regret, and then empirically demonstrates its utility on a gridworld with stagewise development. The claim that susceptibilities detect parameter-space features invisible to policy inspection is supported by direct comparison in the toy setting plus independent activation-steering validation, not by any reduction to fitted parameters or self-referential definitions. No load-bearing step equates a prediction to its own inputs by construction, and no self-citation chain is invoked to force uniqueness.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The response of posterior expectation values to perturbations of the loss can be generalized to perturbations of the regret in deep RL.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe generalize this construction to the setting of the regret in deep reinforcement learning and investigate the utility of susceptibilities in a simple gridworld model...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearthe LLC estimator tracks this stagewise development. Phase transitions are accompanied by rapid increases in the LLC...
Reference graph
Works this paper leans on
-
[1]
Stagewise Reinforcement Learning and the Geometry of the Regret Landscape , author=. 2026 , eprint=
work page 2026
- [2]
-
[3]
Improving Generalization for Temporal Difference Learning: The Successor Representation , author=. Neural Computation , volume=. 1993 , publisher=
work page 1993
-
[4]
Understanding and Controlling a Maze-Solving Policy Network , author=. 2023 , eprint=
work page 2023
-
[5]
From Lists to Emojis: How Format Bias Affects Model Alignment , author=. 2025 , eprint=
work page 2025
-
[6]
Scaling Laws for Reward Model Overoptimization , author=. 2022 , eprint=
work page 2022
-
[7]
Loose lips sink ships: Mitigating Length Bias in Reinforcement Learning from Human Feedback , author=. 2023 , eprint=
work page 2023
-
[8]
Omohundro, Stephen M. , year =. The Basic. Artificial Intelligence Safety and Security , pages =. doi:10.1201/9781351251389-3 , keywords =
- [9]
- [10]
- [11]
-
[12]
Proceedings of the 39th International Conference on Machine Learning , pages =
Goal Misgeneralization in Deep Reinforcement Learning , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
work page 2022
-
[13]
Foundational Challenges in Assuring Alignment and Safety of Large Language Models , author=. 2024 , eprint=
work page 2024
-
[14]
Algebraic geometry and statistical learning theory , author=. 2009 , series=
work page 2009
-
[15]
Asymptotic normality of posterior distributions , author=. Bayes theory , pages=. 1983 , publisher=
work page 1983
-
[16]
2007 IEEE Symposium on Foundations of Computational Intelligence , pages=
Almost all learning machines are singular , author=. 2007 IEEE Symposium on Foundations of Computational Intelligence , pages=. 2007 , organization=
work page 2007
- [17]
-
[18]
Watanabe, Sumio , journal=. A widely applicable. 2013 , publisher=
work page 2013
-
[19]
Liam Carroll , title =
-
[20]
The 28th International Conference on Artificial Intelligence and Statistics , year=
The Local Learning Coefficient: A Singularity-Aware Complexity Measure , author=. The 28th International Conference on Artificial Intelligence and Statistics , year=
-
[21]
ICML 2024 Workshop on Mechanistic Interpretability , year=
Using Degeneracy in the Loss Landscape for Mechanistic Interpretability , author=. ICML 2024 Workshop on Mechanistic Interpretability , year=
work page 2024
-
[22]
The Thirteenth International Conference on Learning Representations , year=
Differentiation and Specialization of Attention Heads via the Refined Local Learning Coefficient , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
Higher and derived stacks: A global overview , Volume =
To. Higher and derived stacks: A global overview , Volume =. Proc. Sympos. Pure Math , Pages =
-
[24]
Derived algebraic geometry , Url =
To. Derived algebraic geometry , Url =. EMS Surv. Math. Sci. , Mrclass =. 2014 , Bdsk-Url-1 =. doi:10.4171/EMSS/4 , Fjournal =
- [25]
-
[26]
A study in derived algebraic geometry
Gaitsgory, Dennis and Rozenblyum, Nick , Isbn =. A study in derived algebraic geometry
-
[27]
The moduli space of curves , pages=
Enumeration of rational curves via torus actions , author=. The moduli space of curves , pages=. 1995 , publisher=
work page 1995
-
[28]
Compositio Mathematica , volume=
Contact loci in arc spaces , author=. Compositio Mathematica , volume=. 2004 , publisher=
work page 2004
-
[29]
Inventiones Mathematicae , volume=
Jet schemes of locally complete intersection canonical singularities , author=. Inventiones Mathematicae , volume=. 2001 , publisher=
work page 2001
-
[30]
Higher Deformation Quantization for
Elliott, Chris and Gwilliam, Owen and Williams, Brian R , journal =. Higher Deformation Quantization for
-
[31]
Impanga Lecture notes on log canonical thresholds , author =. 2011 , url =
work page 2011
-
[32]
Popa, Mihnea , year =. The
-
[33]
Pridham, J. P. , TITLE =. Adv. Math. , FJOURNAL =. 2010 , NUMBER =. doi:10.1016/j.aim.2009.12.009 , URL =
- [34]
-
[35]
Kapranov, M. , TITLE =. Compositio Math. , FJOURNAL =. 1999 , NUMBER =. doi:10.1023/A:1000664527238 , URL =
-
[36]
Elliott, Chris and Safronov, Pavel and Williams, Brian R. , TITLE =. Selecta Math. (N.S.) , FJOURNAL =. 2022 , NUMBER =. doi:10.1007/s00029-022-00786-y , URL =
-
[37]
Renormalization and Effective Field Theory , Volume =
Kevin Costello , Optseries =. Renormalization and Effective Field Theory , Volume =
-
[38]
Factorization algebras in quantum field theory
Costello, Kevin and Gwilliam, Owen , Date-Added =. Factorization algebras in quantum field theory. Vol. 2 , Url =. 2018 , Bdsk-Url-1 =
work page 2018
-
[39]
Homotopy over the complex numbers and generalized de
Simpson, Carlos , Journal =. Homotopy over the complex numbers and generalized de
-
[40]
Simpson, Carlos and Teleman, Constantin , Journal =. De
-
[41]
Simpson, Carlos , Booktitle =. The
-
[42]
Zhongtian Chen and Edmund Lau and Jake Mendel and Susan Wei and Daniel Murfet , year=. Dynamical versus
-
[43]
Dynamics of Transient Structure in In-Context Linear Regression Transformers , author=. 2025 , eprint=
work page 2025
-
[44]
Mitigating Goal Misgeneralization via Minimax Regret , year =
Abdel Sadek, Karim and Farrugia-Roberts, Matthew and Erlebach, Hannah and de Witt, Christian Schroeder and Krueger, David and Anwar, Usman and Dennis, Michael D , booktitle=. Mitigating Goal Misgeneralization via Minimax Regret , year =
-
[45]
Bad Habits: Policy Confounding and Out-of-Trajectory Generalization in RL , author =. EWRL23 , OPTseries =
-
[46]
Equivalence between policy gradients and soft Q-learning
John Schulman and Xi Chen and Pieter Abbeel , year=. Equivalence between policy gradients and soft. 1704.06440 , archivePrefix=
- [47]
-
[48]
Reinforcement learning and control as probabilistic inference: Tutorial and review , author=. 2018 , eprint=
work page 2018
-
[49]
Asymptotic freedom in the. J. Geom. Phys. , Mrclass =. 2018 , Bdsk-Url-1 =. doi:10.1016/j.geomphys.2017.08.009 , Eprint =
-
[50]
Applied Mathematical Sciences , volume=
Information Geometry and Its Applications , author=. Applied Mathematical Sciences , volume=. 2016 , publisher=
work page 2016
-
[51]
Probabilistic inference for solving discrete and continuous state
Toussaint, Marc and Storkey, Amos , booktitle=. Probabilistic inference for solving discrete and continuous state
-
[52]
RL Perceptron: Generalization Dynamics of Policy Learning in High Dimensions , author=. Physical Review X , volume=. 2025 , publisher=
work page 2025
-
[53]
The Thirteenth International Conference on Learning Representations , year=
Flat Reward in Policy Parameter Space Implies Robust Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[54]
Asymptotic behavior of free energy when optimal probability distribution is not unique , author=. Neurocomputing , volume=. 2022 , publisher=
work page 2022
-
[55]
Roberts, Gareth O and Tweedie, Richard L , journal=. Exponential convergence of
-
[56]
Resolution of singularities of an algebraic variety over a field of characteristic zero:
Hironaka, Heisuke , journal=. Resolution of singularities of an algebraic variety over a field of characteristic zero:
-
[57]
Bayesian learning via stochastic gradient
Welling, Max and Teh, Yee W , booktitle=. Bayesian learning via stochastic gradient
-
[58]
arXiv preprint 2507.21449 , year=
From Global to Local: A Scalable Benchmark for Local Posterior Sampling , author=. arXiv preprint 2507.21449 , year=
-
[59]
Balasubramanian, Vijay , title =. Neural Computation , volume =. 1997 , month =. doi:10.1162/neco.1997.9.2.349 , url =
-
[60]
Statistical mechanics of learning from examples , author=. Physical review A , volume=. 1992 , publisher=
work page 1992
-
[61]
Advances in Neural Information Processing Systems , volume=
The promises and pitfalls of stochastic gradient Langevin dynamics , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
The Journal of Machine Learning Research , volume=
Consistency and fluctuations for stochastic gradient Langevin dynamics , author=. The Journal of Machine Learning Research , volume=. 2016 , publisher=
work page 2016
-
[63]
Proceedings of the 39th International Conference on Machine Learning , pages =
Cliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
work page 2022
-
[64]
and Hutter, Marcus and Osborne, Michael A
Cohen, Michael K. and Hutter, Marcus and Osborne, Michael A. , title =. AI Magazine , volume =. doi:https://doi.org/10.1002/aaai.12064 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/aaai.12064 , abstract =
-
[65]
Foundations of Reinforcement Learning and Interactive Decision Making , author=. ArXiv , year=
-
[66]
Michael Munn and Wei, Susan , booktitle=. A. 2025 , url=
work page 2025
-
[67]
General duality between optimal control and estimation , year=
Todorov, Emanuel , booktitle=. General duality between optimal control and estimation , year=
-
[68]
A new approach to linear filtering and prediction problems , journal=
Kalman, Rudolph Emil , year=. A new approach to linear filtering and prediction problems , journal=
- [69]
-
[70]
High-dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning , year=
Loss landscape geometry reveals stagewise development of transformers , author=. High-dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning , year=
work page 2024
-
[71]
Bissiri, P. G. and Holmes, C. C. and Walker, S. G. , title =. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =. doi:https://doi.org/10.1111/rssb.12158 , url =. https://rss.onlinelibrary.wiley.com/doi/pdf/10.1111/rssb.12158 , year =
-
[72]
Zhang, Tong , journal=. From. 2006 , publisher=
work page 2006
-
[73]
International Conference on Optimization and Learning , pages=
Evidence on the Regularisation Properties of Maximum-Entropy Reinforcement Learning , author=. International Conference on Optimization and Learning , pages=. 2024 , organization=
work page 2024
-
[74]
International Conference on Machine Learning , year=
Model-agnostic Measure of Generalization Difficulty , author=. International Conference on Machine Learning , year=
-
[75]
Trajectory Entropy Reinforcement Learning for Predictable and Robust Control , author=. ArXiv , year=
-
[76]
The Pitfalls of Simplicity Bias in Neural Networks , booktitle =
Harshay Shah and Kaustav Tamuly and Aditi Raghunathan and Prateek Jain and Praneeth Netrapalli , editor =. The Pitfalls of Simplicity Bias in Neural Networks , booktitle =. 2020 , url =
work page 2020
-
[77]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Do we always need the simplicity bias? Looking for optimal inductive biases in the wild , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[78]
Deep learning generalizes because the parameter-function map is biased towards simple functions , author=. ArXiv , year=
-
[79]
Superintelligence: Paths, Dangers, Strategies , author =. 2014 , publisher =
work page 2014
-
[80]
International Conference on Learning Representations , year=
Logic and the 2-Simplicial Transformer , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.