Recognition: 2 theorem links
· Lean TheoremDistributional Reinforcement Learning via the Cram\'er Distance
Pith reviewed 2026-05-12 00:55 UTC · model grok-4.3
The pith
By minimizing the squared Cramér distance between value distributions, C-DSAC outperforms standard SAC on robotic tasks through conservative updates on uncertain targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
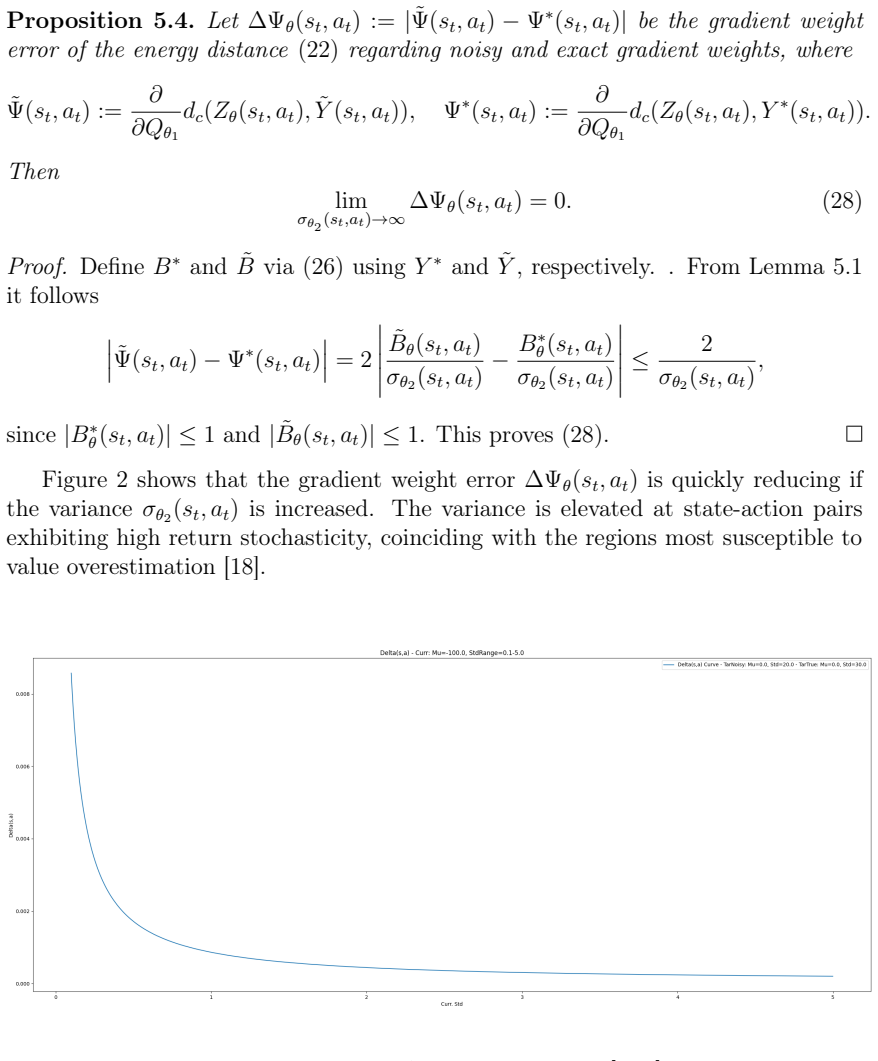
C-DSAC applies distributional reinforcement learning inside the Soft Actor-Critic framework by representing state-action values as distributions and minimizing the squared Cramér distance between the current prediction and the target distribution. On multiple robotic benchmarks the resulting policy exceeds the performance of baseline SAC and of other distributional algorithms, and the margin grows with task complexity. Analysis shows that the gains arise partly because high-variance target distributions produce more conservative Q-value updates that attenuate the effect of overestimated values.
What carries the argument
Minimizing the squared Cramér distance between predicted and target value distributions inside the Soft Actor-Critic loop, which automatically scales update size by target variance.
If this is right
- Performance exceeds both standard SAC and other distributional methods on the tested robotic benchmarks.
- The advantage becomes larger as environment complexity increases.
- High-variance target distributions automatically produce more conservative model updates.
- This mechanism reduces the influence of overestimated values during learning.
Where Pith is reading between the lines
- The same variance-based conservatism could be grafted onto other actor-critic algorithms to reduce overestimation without new hyperparameters.
- The approach may prove useful in real-world settings with higher uncertainty than the simulated robotic benchmarks.
- Explicit distribution modeling might serve as a general regularizer that improves sample efficiency across a wider range of reinforcement-learning problems.
Load-bearing premise
The performance gains come specifically from the Cramér distance and the variance-based conservatism rather than from other implementation choices or hyperparameter settings.
What would settle it
An ablation that keeps the distributional representation but swaps the squared Cramér distance for another metric such as Wasserstein distance, or that disables the variance-dependent step-size scaling, and then measures whether the reported advantage over SAC disappears.
Figures




read the original abstract
This paper explores the application of the Soft Actor-Critic (SAC) algorithm within a Distributional Reinforcement Learning setting and introduces an implementation of such algorithm named Cram\'er-based Distributional Soft Actor-Critic (C-DSAC). The novel approach employs distributional reinforcement learning to represent state-action values, and minimizes the squared Cram\'er distance for learning the distribution. Empirical results across various robotic benchmarks indicate that our algorithm surpasses the performance of baseline SAC and contemporary distributional methods, with the performance advantage becoming increasingly pronounced in high-complexity environments. To explain the efficiency of the new approach, we conduct an analysis showing that its superior performance is partly due to \textit{confidence-driven} Q-value updates: High-variance target distributions (low confidence in target) lead to more conservative model updates, thereby attenuating the impact of overestimated values. This work deepens the understanding of distributional reinforcement learning, offering insights into the algorithmic mechanisms governing convergence and value estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cramér-based Distributional Soft Actor-Critic (C-DSAC), extending SAC to a distributional setting by representing state-action values as distributions and minimizing the squared Cramér distance to target distributions. It reports that C-DSAC outperforms baseline SAC and other distributional RL methods on robotic benchmarks, with larger gains in high-complexity environments, and attributes this to a confidence-driven update rule in which high-variance target distributions produce more conservative Q-value updates that reduce overestimation.
Significance. If the performance gains are robust and causally linked to the proposed components, the work would advance understanding of distributional RL mechanisms in continuous control. The variance-based modulation idea offers a concrete, testable hypothesis about why distributional methods can stabilize learning, which could influence algorithm design beyond the specific benchmarks.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): The superiority claims over SAC and contemporary distributional methods are presented without reported details on the number of random seeds, standard errors, or statistical significance tests, so the reliability of the performance advantage cannot be assessed from the given results.
- [§5 (Analysis)] §5 (Analysis): The central explanatory claim—that superior performance arises from confidence-driven updates (high-variance targets yielding conservative model updates)—is not supported by isolating ablations. No controlled comparisons are described that hold the Cramér distance fixed while removing the variance weighting, or that compare C-DSAC against a standard distributional SAC baseline using the same distance but mean-based targets; without these, the causal attribution remains correlational.
minor comments (2)
- [Abstract] The abstract refers to 'contemporary distributional methods' without naming them; listing the specific baselines (e.g., in §4) would improve reproducibility.
- [Method] The precise definition of the squared Cramér distance and its implementation within the SAC actor-critic loop would benefit from an explicit equation or pseudocode block in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and outline the revisions we will incorporate to improve the clarity and rigor of the experimental and analytical sections.
read point-by-point responses
-
Referee: §4 (Experiments): The superiority claims over SAC and contemporary distributional methods are presented without reported details on the number of random seeds, standard errors, or statistical significance tests, so the reliability of the performance advantage cannot be assessed from the given results.
Authors: We agree that additional statistical details are necessary to allow readers to properly evaluate the reported performance gains. In the revised manuscript we will explicitly report that all experiments were run with 5 independent random seeds, include standard-error bars on all learning curves and tables in Section 4, and add paired t-tests (with p-values) comparing C-DSAC against each baseline. These changes will be placed in the experimental protocol subsection and the result tables. revision: yes
-
Referee: §5 (Analysis): The central explanatory claim—that superior performance arises from confidence-driven updates (high-variance targets yielding conservative model updates)—is not supported by isolating ablations. No controlled comparisons are described that hold the Cramér distance fixed while removing the variance weighting, or that compare C-DSAC against a standard distributional SAC baseline using the same distance but mean-based targets; without these, the causal attribution remains correlational.
Authors: Section 5 already demonstrates a consistent negative correlation between target variance and update magnitude across environments, together with visualizations of how high-variance targets attenuate overestimated values. Nevertheless, we acknowledge that isolating the variance-weighting component would strengthen the causal argument. In the revised version we will add two controlled ablations to Section 5: (1) a C-DSAC variant that retains the Cramér distance but replaces the variance-based weighting with uniform (mean) targets, and (2) a distributional SAC baseline that uses the identical Cramér distance yet employs mean-based targets. Results of these ablations will be reported alongside the original analysis. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The paper defines C-DSAC as SAC augmented with distributional value representations minimized under squared Cramér distance, then reports empirical superiority on robotic control suites. No equations, predictions, or uniqueness claims are shown to reduce by construction to fitted parameters, self-citations, or ansatzes imported from the authors' prior work. The interpretive analysis of 'confidence-driven' updates is post-hoc explanation of observed behavior rather than a load-bearing derivation that loops back to the inputs. Performance attribution therefore depends on external experimental results, not internal redefinition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The environment is a Markov decision process with well-defined transition and reward distributions.
- standard math The squared Cramér distance is a valid metric for comparing return distributions and yields stable gradients.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
minimizes the squared Cramér distance for learning the distribution... energy distance de(U,V):=∫(FU(x)−FV(x))²dx
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lim σ→∞ ∂C/∂Q =0 ... confidence-driven Q-value updates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bellemare, Will Dabney, and Rémi Munos
Marc G. Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforcement learning. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 449–458. JMLR.org, 2017
work page 2017
-
[2]
Bellemare, Will Dabney, and Mark Rowland.Distributional Rein- forcement Learning
Marc G. Bellemare, Will Dabney, and Mark Rowland.Distributional Rein- forcement Learning. MIT Press, 2023.http://www.distributional-rl.org, Accessed: 2023-09-15
work page 2023
-
[3]
Marc G. Bellemare, Ivo Danihelka, Will Dabney, Shakir Mohamed, Balaji Lak- shminarayanan, Stephan Hoyer, and Rémi Munos. The Cramer distance as a solution to biased Wasserstein gradients, 2017
work page 2017
-
[4]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Implicit quantile networks for distributional reinforcement learning, 2018
Will Dabney, Georg Ostrovski, David Silver, and Rémi Munos. Implicit quantile networks for distributional reinforcement learning, 2018
work page 2018
-
[6]
Will Dabney, Mark Rowland, Marc G. Bellemare, and Rémi Munos. Distribu- tional reinforcement learning with quantile regression. InAAAI Conference on Artificial Intelligence, 2017
work page 2017
-
[7]
Jingliang Duan, Yang Guan, Shengbo Eben Li, Yangang Ren, Qi Sun, and BO CHENG. Distributional soft actor-critic: Off-policy reinforcement learning for addressing value estimation errors.IEEE Transactions on Neural Networks and Learning Systems, 33(11):6584–6598, nov 2022
work page 2022
-
[8]
Implementation matters in deep policy gradients: A case study on PPO and TRPO, 2020
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, and Aleksander Madry. Implementation matters in deep policy gradients: A case study on PPO and TRPO, 2020
work page 2020
-
[9]
AlhusseinFawzi, MatejBalog, AjaHuang, ThomasHubert, BernardinoRomera- Paredes, Mohammadamin Barekatain, Alexander Novikov, Francisco J. R. Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, David Silver, Demis Hassabis, and Pushmeet Kohli. Discovering faster matrix multiplication algorithms with rein- forcement learning.Nature, 610:47 – 53, 2022. 31
work page 2022
-
[10]
Addressing function ap- proximation error in actor-critic methods
Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function ap- proximation error in actor-critic methods. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learn- ing, volume 80 ofProceedings of Machine Learning Research, pages 1587–1596. PMLR, 2018
work page 2018
-
[11]
Shixiang Shane Gu, Ethan Holly, Timothy P. Lillicrap, and Sergey Levine. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 3389–3396, Piscataway, NJ, USA, May 2017. IEEE
work page 2017
-
[12]
Soft actor- critic: Off-policy maximum entropy deep reinforcement learning with a stochas- tic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor- critic: Off-policy maximum entropy deep reinforcement learning with a stochas- tic actor. In Jennifer G. Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmäs- san, Stockholm, Sweden, July 10-15, 2018, volume ...
work page 2018
-
[13]
Soft actor-critic algorithms and applications, 2019
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, and Sergey Levine. Soft actor-critic algorithms and applications, 2019
work page 2019
-
[14]
Deep reinforcement learning with double Q-learning
Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double Q-learning. InProceedings of the Thirtieth AAAI Conference on Artificial Intelligence, AAAI’16, page 2094–2100. AAAI Press, 2016
work page 2094
-
[15]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Pre- cup, and David Meger. Deep reinforcement learning that matters. InAAAI Conference on Artificial Intelligence, 2017
work page 2017
-
[16]
Adam: A method for stochastic optimization
Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR), San Diega, CA, USA, 2015
work page 2015
-
[17]
Auto-Encoding Variational Bayes, 2022
Diederik P Kingma and Max Welling. Auto-Encoding Variational Bayes, 2022
work page 2022
-
[18]
Maxmin q- learning: Controlling the estimation bias of q-learning
Qingfeng Lan, Yangchen Pan, Alona Fyshe, and Martha White. Maxmin q- learning: Controlling the estimation bias of q-learning. InInternational Con- ference on Learning Representations, 2020
work page 2020
-
[19]
Alix Lhéritier and Nicolas Bondoux. A Cramér distance perspective on quantile regression based distributional reinforcement learning, 2022. 32
work page 2022
-
[20]
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning, 2019
work page 2019
-
[21]
DSAC: Distributional soft actor critic for risk-sensitive reinforcement learning, 2020
Xiaoteng Ma, Li Xia, Zhengyuan Zhou, Jun Yang, and Qianchuan Zhao. DSAC: Distributional soft actor critic for risk-sensitive reinforcement learning, 2020
work page 2020
-
[22]
Playing atari with deep reinforcement learning, 2013
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning, 2013
work page 2013
-
[23]
Timothy H. Muller, James L. Butler, Sebastijan Veselic, Bruno Miranda, Tim- othy Edward John Behrens, Zeb Kurth-Nelsfon, and Steven Wayne Kennerley. Distributional reinforcement learning in prefrontal cortex.Nature Neuroscience, 27:403 – 408, 2021
work page 2021
-
[24]
Daniel Wontae Nam, Younghoon Kim, and Chan Y. Park. GMAC: A distribu- tional perspective on actor-critic framework. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learn- ing, volume 139 ofProceedings of Machine Learning Research, pages 7930–7939. PMLR, 18–24 Jul 2021
work page 2021
-
[25]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback, 2022
work page 2022
-
[26]
Cosmin Paduraru, Daniel Jaymin Mankowitz, Gabriel Dulac-Arnold, Jerry Li, Nir Levine, Sven Gowal, and Todd Hester. Challenges of real-world rein- forcement learning: definitions, benchmarks and analysis.Machine Learning, 110:2419 – 2468, 2021
work page 2021
-
[27]
John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust region policy optimization, 2017
work page 2017
-
[28]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
work page 2017
-
[29]
Equivalence of distance-based and rkhs-based statistics in hypothesis testing
Dino Sejdinovic, Bharath Sriperumbudur, Arthur Gretton, and Kenji Fukumizu. Equivalence of distance-based and rkhs-based statistics in hypothesis testing. The Annals of Statistics, 41(5):2263–2291, 2013. 33
work page 2013
-
[30]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Intro- duction. The MIT Press, second edition, 2018
work page 2018
-
[31]
Issues in using function approximation for reinforcement learning
Sebastian Thrun and Anton Schwartz. Issues in using function approximation for reinforcement learning. In Michael Mozer, Paul Smolensky, David Touretzky, Jeffrey Elman, and Andreas Weigend, editors,Proceedings of the 1993 Connec- tionist Models Summer School, pages 255–263. Lawrence Erlbaum, 1993
work page 1993
-
[32]
More benefits of being distributional: Second-order bounds for reinforcement learning
Kaiwen Wang, Owen Oertell, Alekh Agarwal, Nathan Kallus, and Wen Sun. More benefits of being distributional: Second-order bounds for reinforcement learning. InProceedings of the 41st International Conference on Machine Learn- ing, volume 235 ofProceedings of Machine Learning Research, pages 51192– 51213. PMLR, 2024
work page 2024
-
[33]
The benefits of being distributional: Small-loss bounds for reinforcement learning, 2023
Kaiwen Wang, Kevin Zhou, Runzhe Wu, Nathan Kallus, and Wen Sun. The benefits of being distributional: Small-loss bounds for reinforcement learning, 2023
work page 2023
-
[34]
Cur- ran Associates Inc., Red Hook, NY, USA, 2019
Derek Yang, Li Zhao, Zichuan Lin, Tao Qin, Jiang Bian, and Tieyan Liu.Fully parameterized quantile function for distributional reinforcement learning. Cur- ran Associates Inc., Red Hook, NY, USA, 2019
work page 2019
-
[35]
A survey of reinforcement learning for large reasoning models, 2025
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, Yu Fu, Xingtai Lv, Yuchen Zhang, Sihang Zeng, Shang Qu, Haozhan Li, Shijie Wang, Yuru Wang, Xinwei Long, Fangfu Liu, Xiang Xu, Jiaze Ma, Xuekai Zhu, Ermo Hua, Yihao Liu, Zonglin Li, Huayu Chen, Xiaoye Qu, Yafu Li, Weize Chen, Zhenzhao Yua...
work page 2025
-
[36]
V M Zolotarev. Metric distances in spaces of random variables and their distri- butions.Mathematics of the USSR-Sbornik, 30(3):373, apr 1976. 34
work page 1976
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.