Recognition: 1 theorem link
· Lean TheoremExecuTorch -- A Unified PyTorch Solution to Run AI Models On-Device
Pith reviewed 2026-05-12 01:26 UTC · model grok-4.3
The pith
A PyTorch-native framework allows AI models to run on diverse edge devices without conversion or reimplementation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework provides a unified way to execute models on edge devices by maintaining PyTorch semantics, allowing pluggable backends for different compute environments, and supporting features like quantization, so that deployment behavior can be validated without leaving the PyTorch setting.
What carries the argument
Pluggable execution backends that customize for heterogeneous hardware while keeping the model's PyTorch semantics intact.
If this is right
- Researchers can test how models behave on target devices entirely within PyTorch.
- Optimizations such as quantization integrate directly into the deployment process.
- The approach works across scales from simple embedded devices to complex accelerators.
- Customization is possible for specific hardware without altering the core model code.
Where Pith is reading between the lines
- This setup could allow developers to design models with on-device constraints considered earlier in the process.
- It may simplify bringing AI capabilities to offline and low-latency applications on consumer hardware.
- Further extensions might include automatic selection of backends based on device capabilities.
Load-bearing premise
Pluggable backends and optimizations can be created to achieve seamless and efficient performance on every type of claimed hardware without forcing any model changes or use of external tools.
What would settle it
A case where a standard PyTorch model fails to deploy correctly on a supported device type without additional code or conversion steps outside the framework.
Figures





read the original abstract
Local execution of AI on edge devices is important for low latency and offline operation. However, deploying models on diverse hardware remains fragmented, often requiring model conversion or complete reimplementation outside the PyTorch ecosystem where the model was originally authored. We introduce ExecuTorch, a unified PyTorch-native deployment framework for edge AI. ExecuTorch enables seamless deployment of machine learning models across heterogeneous compute environments. It scales from embedded microcontrollers to complex system-on-chips (SoCs) with dedicated accelerators, powering devices ranging from wearables and smartphones to large compute clusters. ExecuTorch preserves PyTorch semantics while allowing customization, support for optimizations like quantization, and pluggable execution "backends". These features together enable fast experimentation, allowing researchers to validate deployment behavior entirely within PyTorch, bridging the gap between research and production.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ExecuTorch as a unified PyTorch-native deployment framework for edge AI. It claims to enable seamless deployment of ML models across heterogeneous hardware (from microcontrollers to SoCs with accelerators), preserve PyTorch semantics, support optimizations such as quantization, and provide pluggable backends, thereby allowing researchers to validate deployment behavior entirely within PyTorch and bridging research-to-production gaps.
Significance. If the framework's architecture and pluggable components deliver on the stated properties, ExecuTorch would address a practical fragmentation problem in on-device AI by keeping the development and deployment pipeline inside the PyTorch ecosystem. This could accelerate iteration for edge applications in wearables, smartphones, and embedded systems. The work is primarily a system description rather than a theoretical or empirical contribution, so its significance hinges on demonstrated adoption, reproducibility of the claimed seamlessness, and measurable performance gains over existing conversion-based approaches.
major comments (2)
- [Abstract] Abstract: The central claims that ExecuTorch 'enables seamless deployment' and 'scales from embedded microcontrollers to complex SoCs' while 'preserving PyTorch semantics' are presented without any benchmarks, latency/accuracy measurements, error analysis, or concrete implementation details. This absence is load-bearing because the manuscript's value rests on these assertions of seamlessness and scalability; without supporting evidence the claims cannot be evaluated.
- [Architecture / Design (inferred from abstract claims)] The description of pluggable execution backends and optimizations (quantization, etc.) does not include any concrete API signatures, backend registration mechanism, or example of how a model is lowered and executed without leaving the PyTorch environment. This detail is required to substantiate the 'PyTorch-native' and 'no model conversion' claims.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from a short table or bullet list enumerating the specific hardware targets and example models that have been tested, even at a high level.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript on ExecuTorch. The comments have helped us identify areas where additional evidence and implementation specifics can strengthen the presentation of the framework. We provide point-by-point responses below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims that ExecuTorch 'enables seamless deployment' and 'scales from embedded microcontrollers to complex SoCs' while 'preserving PyTorch semantics' are presented without any benchmarks, latency/accuracy measurements, error analysis, or concrete implementation details. This absence is load-bearing because the manuscript's value rests on these assertions of seamlessness and scalability; without supporting evidence the claims cannot be evaluated.
Authors: We agree that the abstract's high-level claims would be more compelling with supporting data. The original manuscript is primarily a system description and therefore emphasizes architecture over extensive empirical results, but we acknowledge the need for concrete evidence. In the revised version, we have added a dedicated 'Evaluation' section that reports latency and accuracy measurements across microcontrollers and SoCs, includes quantization error analysis, and provides specific implementation details illustrating how PyTorch semantics are preserved during deployment. These additions directly support the claims of seamlessness and scalability. revision: yes
-
Referee: [Architecture / Design (inferred from abstract claims)] The description of pluggable execution backends and optimizations (quantization, etc.) does not include any concrete API signatures, backend registration mechanism, or example of how a model is lowered and executed without leaving the PyTorch environment. This detail is required to substantiate the 'PyTorch-native' and 'no model conversion' claims.
Authors: The referee is correct that the initial manuscript presented the pluggable backends and optimizations at a conceptual level. To address this, the revised manuscript now includes explicit API signatures for backend registration and model lowering in the 'Architecture' section. We have also added pseudocode and a step-by-step example demonstrating how a model is exported from PyTorch, optimized (including quantization), and executed on-device using pluggable backends, all without leaving the PyTorch environment or requiring separate model conversion. This makes the PyTorch-native properties concrete and verifiable. revision: yes
Circularity Check
No significant circularity in software framework description
full rationale
The paper is a descriptive account of the ExecuTorch framework architecture, APIs, pluggable backends, and deployment workflow for PyTorch models on edge hardware. It contains no mathematical derivations, equations, fitted parameters, predictions, or uniqueness theorems. No self-citations are invoked to justify load-bearing claims that reduce to prior author work. The central claims concern system design choices and intended semantics preservation, which are presented directly without reduction to inputs by construction. The work is self-contained as a software engineering contribution.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
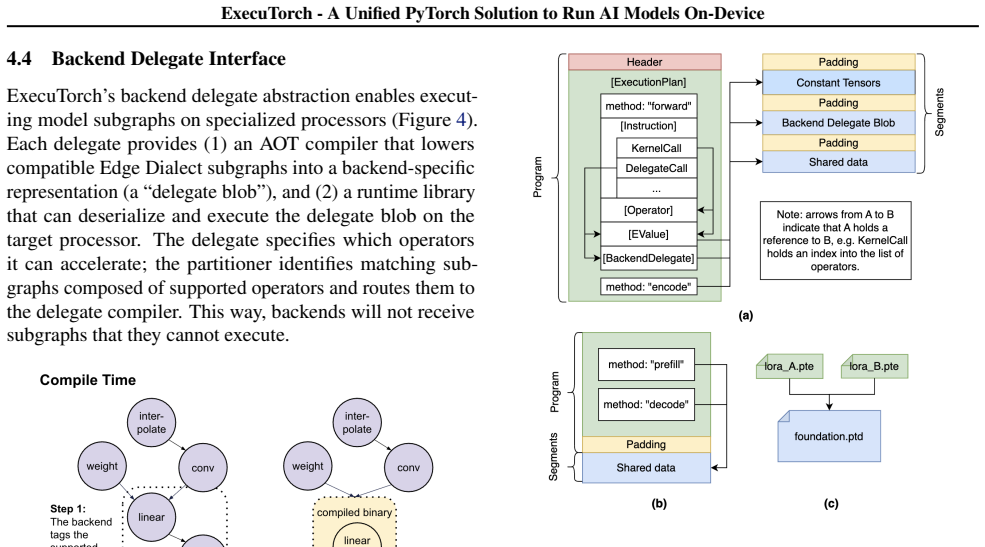
ExecuTorch implements infrastructure for backend delegation... torch.export converts models into hardware-agnostic AOT graphs built from a small set of <300 Core ATen primitives
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Usiang the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Ansel, Jason and Yang, Edward and He, Horace and Gimelshein, Natalia and Jain, Animesh and Voznesensky, Michael and Bao, Bin and Bell, Peter and Berard, David and Burovski, Evgeni and Chauhan, Geeta and Chourdia, Anjali and Constable, Will and Desmaison, Alban and DeVito, Zachary and Ellison, Elias and Feng, Will and Gong, Jiong and Gschwind, Michael and ...
-
[10]
Reed and Zachary DeVito and Horace He and Ansley Ussery and Jason Ansel , title =
James K. Reed and Zachary DeVito and Horace He and Ansley Ussery and Jason Ansel , title =. CoRR , volume =. 2021 , url =. 2112.08429 , timestamp =
- [11]
- [12]
- [13]
-
[14]
PyTorch 2 Export Quantization-Aware Training (QAT) , author =. 2025 , url =
work page 2025
- [15]
-
[16]
PyTorch 1.9 Release, including torch.linalg and Mobile Interpreter , author =. 2021 , url =
work page 2021
-
[17]
GitHub repository , howpublished =
Bai, Junjie and Lu, Fang and Zhang, Ke and others , title =. GitHub repository , howpublished =. 2019 , publisher =
work page 2019
-
[18]
How Much RAM is in Smartphones? , url =
-
[19]
ML Engineer comparison of Pytorch, TensorFlow, JAX, and Flax , author =. 2024 , url =
work page 2024
-
[20]
Awni Hannun and Jagrit Digani and Angelos Katharopoulos and Ronan Collobert , title =
-
[21]
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
work page 2023
- [22]
-
[23]
SpinQuant: LLM quantization with learned rotations , author=. 2025 , eprint=
work page 2025
-
[24]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration , author=. 2024 , eprint=
work page 2024
-
[25]
TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems , author=. 2021 , eprint=
work page 2021
-
[26]
TensorFlow: A system for large-scale machine learning , author=. 2016 , eprint=
work page 2016
-
[27]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author=. 2019 , eprint=
work page 2019
-
[28]
Caffe: Convolutional Architecture for Fast Feature Embedding , author=. 2014 , eprint=
work page 2014
- [29]
- [30]
-
[31]
Early vs Late Fusion in Multimodal Convolutional Neural Networks , year=
Gadzicki, Konrad and Khamsehashari, Razieh and Zetzsche, Christoph , booktitle=. Early vs Late Fusion in Multimodal Convolutional Neural Networks , year=
-
[32]
2019 IEEE international symposium on high performance computer architecture (HPCA) , pages=
Machine learning at facebook: Understanding inference at the edge , author=. 2019 IEEE international symposium on high performance computer architecture (HPCA) , pages=. 2019 , organization=
work page 2019
-
[33]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers , author=. 2023 , eprint=
work page 2023
-
[34]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
work page 2020
-
[35]
XNNPACK: High-efficiency floating-point neural network inference operators for mobile and server platforms , author =. 2019 , note =
work page 2019
-
[36]
KleidiAI: Open-source micro-kernel library for AI workloads on Arm CPUs , author =. 2024 , note =
work page 2024
-
[37]
Core ML: Machine Learning Framework for Apple Platforms , author =. 2023 , note =
work page 2023
-
[38]
Tensor Operator Set Architecture (TOSA) Specification v1.0.1 , author =. 2023 , note =
work page 2023
-
[39]
Arm Ethos-U Ecosystem: MicroNPUs and Software for Efficient Edge AI , author =. 2024 , note =
work page 2024
- [40]
- [41]
- [42]
-
[43]
Wang, Tianyu and Guo, Jinyang and Zhang, Bowen and Yang, Ge and Li, Dong , title =. Mathematics , volume =. 2025 , publisher =. doi:10.3390/math13111878 , issn =
-
[44]
and Helzer, Jarrod and Pfeffer, Michael A
Ng, Madelena Y. and Helzer, Jarrod and Pfeffer, Michael A. and Seto, Tina and Hernandez-Boussard, Tina , title =. Journal of the American Medical Informatics Association , volume =. 2025 , month =. doi:10.1093/jamia/ocaf005 , issn =
-
[45]
Kuo, Tsung-Ting and Kim, Jihoon and Gabriel, Rodney A. , title =. Journal of the American Medical Informatics Association , volume =. 2020 , month =. doi:10.1093/jamia/ocz214 , pmid =
-
[46]
and Su, Chang and Walker, Peter and Bian, Jiang and Wang, Fei , title =
Xu, Jie and Glicksberg, Benjamin S. and Su, Chang and Walker, Peter and Bian, Jiang and Wang, Fei , title =. Journal of Healthcare Informatics Research , volume =. 2021 , month =. doi:10.1007/s41666-020-00082-4 , pmid =
-
[47]
Sperling, N. and Ernst, R. , title =. 2024 IEEE 99th Vehicular Technology Conference (VTC Spring) , year =
work page 2024
-
[48]
Nigade, Vinod and Bauszat, Pablo and Bal, Henri E. and Wang, Lin , title =. Real-Time Systems , volume =. 2024 , publisher =
work page 2024
-
[49]
2024 IEEE 30th Real-Time and Embedded Technology and Applications Symposium (RTAS) , year =
Kang, Woosung and Lee, Jinkyu and Lee, Youngmoon and Oh, Sangeun and Lee, Kilho and Chwa, Hoon Sung , title =. 2024 IEEE 30th Real-Time and Embedded Technology and Applications Symposium (RTAS) , year =. doi:10.1109/RTAS61025.2024.00037 , address =
-
[50]
Pons, Mario and Valenzuela, Estuardo and Rodr. Utilization of. Sensors , volume =. 2023 , month = apr, doi =
work page 2023
-
[51]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Vasu, Pavan Kumar Anasosalu and Gabriel, James and Zhu, Jeff and Tuzel, Oncel and Ranjan, Anurag , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
work page 2023
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Vasu, Pavan Kumar Anasosalu and Pouransari, Hadi and Faghri, Fartash and Vemulapalli, Raviteja and Tuzel, Oncel , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
work page 2024
-
[53]
Ahsan, S. M. Mojahidul and Hoque, Tamzidul and Hasan, Md Sakib and Chowdhury, Mrittika and Dhungel, Anurag , title =. AI-Enabled Electronic Circuit and System Design , editor =. 2025 , publisher =. doi:10.1007/978-3-031-71436-8_14 , isbn =
-
[54]
Proceedings of Machine Learning and Systems , volume =
David, Robert and Duke, Jared and Jain, Advait and Reddi, Vijay Janapa and Jeffries, Nat and Li, Jian and Kreeger, Nick and Nappier, Ian and Natraj, Meghna and Regev, Shlomi and Rhodes, Rocky and Wang, Tiezhen and Warden, Pete , title =. Proceedings of Machine Learning and Systems , volume =. 2021 , editor =
work page 2021
-
[55]
2017 , organization =
work page 2017
-
[56]
2018 , month = dec, howpublished =
work page 2018
-
[57]
13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18) , year =
Tianqi Chen and Thierry Moreau and Ziheng Jiang and Lianmin Zheng and Eddie Yan and Haichen Shen and Meghan Cowan and Leyuan Wang and Yuwei Hu and Luis Ceze and Carlos Guestrin and Arvind Krishnamurthy , title =. 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18) , year =
-
[58]
Proceedings of Machine Learning and Systems , year =
Jiang, Xiaotang and Wang, Huan and Chen, Yiliu and Wu, Ziqi and Wang, Lichuan and Zou, Bin and Yang, Yafeng and Cui, Zongyang and Cai, Yu and Yu, Tianhang and Lv, Chengfei and Wu, Zhihua , title =. Proceedings of Machine Learning and Systems , year =
-
[59]
2023 , month = mar, publisher =
Gerganov, Georgi , title =. 2023 , month = mar, publisher =
work page 2023
-
[60]
CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs , url =. 2025 , date =
work page 2025
-
[61]
2019 , month = oct, organization =
work page 2019
- [62]
-
[63]
ExecuTorch: Bringing Efficient On-Device ML to the Meta Family of Apps , date =
-
[64]
Local-Global Attention: An Adaptive Mechanism for Multi-Scale Feature Integration , author=. 2024 , eprint=
work page 2024
-
[65]
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
work page 2023
- [66]
-
[67]
TorchAO: PyTorch-Native Training-to-Serving Model Optimization , author=
-
[68]
Championing Open-source Development in ML Workshop @ ICML25 , year=
Control Flow Operators in PyTorch , author=. Championing Open-source Development in ML Workshop @ ICML25 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.