Recognition: 2 theorem links
· Lean TheoremLearngene Search Across Multiple Datasets for Building Variable-Sized Models
Pith reviewed 2026-05-12 01:16 UTC · model grok-4.3
The pith
A search across datasets for common building blocks produces learngenes that initialize variable-sized models efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
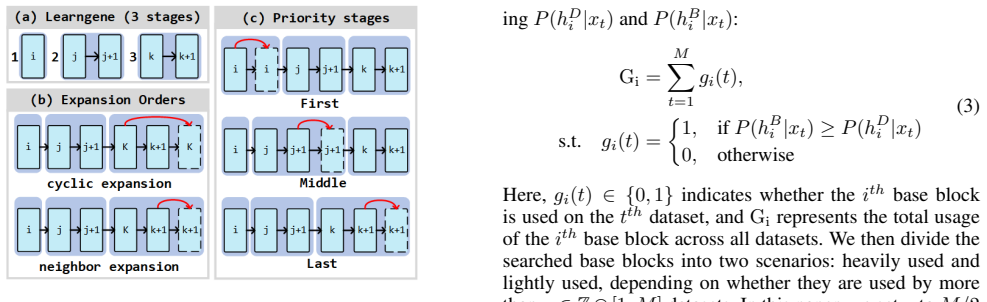
LSAMD turns the ancestry model into a super Ans-Net containing dataset-specific blocks and dataset adapters. It searches for the best path through this network for every dataset. The base blocks appearing in the highest number of these optimal paths are taken as learngenes. These learngenes initialize descendant networks of varying sizes for use on new tasks.
What carries the argument
Multi-dataset architecture search within the super Ans-Net with dataset adapters, using frequency of base block selection to extract learngenes.
If this is right
- Variable sized Des-Nets can be created from one set of learngenes without repeating full pretraining.
- Storage requirements drop because full models per dataset are replaced by shared learngenes plus adapters.
- Training costs fall as the learngene initialization speeds up the finetuning stage for new models.
- Performance on tested datasets remains comparable to separate pretrain-finetune pipelines.
Where Pith is reading between the lines
- The selected learngenes may capture dataset-agnostic features useful for other computer vision problems.
- Extending the search to include more diverse datasets could produce even more robust learngenes.
- Similar frequency-based extraction might apply to other model types beyond Vision Transformers.
Load-bearing premise
The most frequently selected base blocks across datasets will act as effective transferable learngenes for initializing strong models on new tasks or model sizes.
What would settle it
Evaluating the extracted learngenes on a dataset excluded from the multi-dataset search and observing lower performance than models trained from scratch or with single-dataset learngenes.
Figures






read the original abstract
Deep learning methods are widely used under diverse resource constraints, resulting in models of varying sizes, such as the Vision Transformer (ViT) series. Deploying these models typically requires costly pretraining and finetuning. The Learngene paradigm addresses this issue by extracting transferable components, called learngenes, from a pretrained ancestry model (Ans-Net) to initialize variable-sized descendant models (Des-Nets).Existing learngene extraction methods rely on a single dataset, limiting downstream performance. To address this limitation, we propose Learngene Search Across Multiple Datasets for Building Variable-Sized Models (LSAMD). LSAMD expands the Ans-Net into a searchable super Ans-Net with dataset-specific blocks and dataset adapters (DADs). During training, LSAMD searches for an optimal architecture path for each dataset. The base blocks most frequently selected across datasets are extracted as learngenes for initializing Des-Nets.Experiments on multiple datasets show that LSAMD achieves performance comparable to pretrain-finetune methods while significantly reducing storage and training costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LSAMD, which expands an ancestry model (Ans-Net) into a super Ans-Net incorporating dataset-specific blocks and dataset adapters (DADs). It runs per-dataset architecture search, designates the most frequently selected base blocks as learngenes, and uses these to initialize variable-sized descendant models (Des-Nets). The central claim is that this yields performance comparable to pretrain-finetune baselines while reducing storage and training costs across multiple datasets.
Significance. If the frequency-based extraction is shown to isolate genuinely transferable components via proper controls, the approach could meaningfully lower the cost of supporting variable model sizes under diverse resource constraints, extending the learngene paradigm beyond single-dataset limitations.
major comments (3)
- [§4] §4 (Experiments): The claim that LSAMD achieves comparable performance is stated without quantitative metrics, baselines, error bars, dataset details, or ablation results, leaving the central empirical assertion unsupported by visible evidence.
- [§3] §3 (Method): The assumption that blocks most frequently selected across datasets are transferable learngenes for unseen tasks or sizes is load-bearing but untested; no held-out task evaluation or size-extrapolation experiment is described.
- [§3.2 and §4] §3.2 and §4: No ablation compares frequency selection against random selection or single-dataset blocks, so it remains unclear whether multi-dataset frequency isolates intrinsic transferability rather than dataset-specific compatibility or search bias.
minor comments (1)
- [§3] Clarify the precise definition and role of DADs versus base blocks in the super Ans-Net construction to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional empirical detail and validation will strengthen the manuscript. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The claim that LSAMD achieves comparable performance is stated without quantitative metrics, baselines, error bars, dataset details, or ablation results, leaving the central empirical assertion unsupported by visible evidence.
Authors: We agree that the current presentation of results does not provide sufficient quantitative support in the main text. In the revised manuscript, Section 4 will be expanded to include detailed performance tables comparing LSAMD to pretrain-finetune baselines across all datasets, with reported metrics, standard deviations from multiple runs, complete dataset specifications, and the requested ablation studies. These additions will directly substantiate the comparability claim while quantifying the storage and training cost reductions. revision: yes
-
Referee: [§3] §3 (Method): The assumption that blocks most frequently selected across datasets are transferable learngenes for unseen tasks or sizes is load-bearing but untested; no held-out task evaluation or size-extrapolation experiment is described.
Authors: The frequency-based extraction is designed to surface blocks that demonstrate utility across diverse datasets, which we hypothesize promotes transferability. We acknowledge that explicit testing on held-out tasks and size extrapolation would provide stronger validation. In the revision, we will add a held-out dataset experiment (learngenes extracted from a subset of datasets and evaluated on the unseen dataset) together with Des-Net evaluations across a range of model sizes, including sizes outside the original search space. revision: yes
-
Referee: [§3.2 and §4] §3.2 and §4: No ablation compares frequency selection against random selection or single-dataset blocks, so it remains unclear whether multi-dataset frequency isolates intrinsic transferability rather than dataset-specific compatibility or search bias.
Authors: We agree that these controls are necessary to confirm the benefit of multi-dataset frequency. The revised Section 4 will include two new ablations: (1) frequency-selected blocks versus randomly sampled blocks from the super Ans-Net, and (2) multi-dataset frequency selection versus blocks obtained from single-dataset searches. Both will be evaluated by initializing variable-sized Des-Nets and measuring downstream performance to isolate the contribution of the proposed frequency mechanism. revision: yes
Circularity Check
No circularity: empirical frequency selection is not definitionally equivalent to transferability claim
full rationale
The paper defines LSAMD as an architecture search over a super Ans-Net augmented with per-dataset blocks and DADs, followed by frequency-based extraction of base blocks as learngenes. This extraction rule is an explicit, non-self-referential procedure (most frequent blocks across searched paths) and is not defined in terms of the downstream performance or transferability it is later claimed to deliver. No equations, fitted parameters, or self-citations are shown to reduce the central claim to its own inputs by construction. The reported performance equivalence is an external empirical comparison, not a tautological restatement of the selection step.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearThe base blocks most frequently selected across datasets are extracted as learngene for initializing Des-Nets.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLSAMD expands the Ans-Net into a searchable super Ans-Net with dataset-specific blocks and dataset adapters (DADs).
Reference graph
Works this paper leans on
- [1]
-
[2]
Bossard, L.; Guillaumin, M.; and Gool, L. V. 2014. Food-101 - Mining Discriminative Components with Random Forests. In European Conference on Computer Vision
work page 2014
-
[3]
Chen, G.; Zhao, X.; Chen, T.; and Cheng, Y. 2024. \ \ MoE-RBench\ \ : Towards Building Reliable Language Models with Sparse Mixture-of-Experts
work page 2024
-
[4]
Chen, Z.; Shen, Y.; Ding, M.; Chen, Z.; Zhao, H.; Learned-Miller, E. G.; and Gan, C. 2022. Mod-Squad: Designing Mixture of Experts As Modular Multi-Task Learners. ArXiv, abs/2212.08066
-
[5]
Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; and Vedaldi, A. 2013. Describing Textures in the Wild. 2014 IEEE Conference on Computer Vision and Pattern Recognition, 3606--3613
work page 2013
-
[6]
Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009. ImageNet: A large-scale hierarchical image database. 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248--255
work page 2009
-
[7]
Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; and Houlsby, N. 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ArXiv, abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Everingham, M.; Eslami, S. A.; Van Gool, L.; Williams, C. K.; Winn, J.; and Zisserman, A. 2015. The pascal visual object classes challenge: A retrospective. International journal of computer vision, 111(1): 98--136
work page 2015
-
[9]
Fedus, W.; Zoph, B.; and Shazeer, N. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120): 1--39
work page 2022
-
[10]
Fei-Fei, L.; Fergus, R.; and Perona, P. 2004. Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories. 2004 Conference on Computer Vision and Pattern Recognition Workshop, 178--178
work page 2004
-
[11]
Horn, G. V.; Aodha, O. M.; Song, Y.; Cui, Y.; Sun, C.; Shepard, A.; Adam, H.; Perona, P.; and Belongie, S. J. 2017. The iNaturalist Species Classification and Detection Dataset. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8769--8778
work page 2017
-
[12]
Jacobs, R. A.; Jordan, M. I.; Nowlan, S. J.; and Hinton, G. E. 1991. Adaptive Mixtures of Local Experts. Neural Computation, 3: 79--87
work page 1991
-
[13]
Krause, J.; Stark, M.; Deng, J.; and Fei-Fei, L. 2013. 3D Object Representations for Fine-Grained Categorization. 2013 IEEE International Conference on Computer Vision Workshops, 554--561
work page 2013
-
[14]
Krizhevsky, A. 2009. Learning Multiple Layers of Features from Tiny Images
work page 2009
-
[15]
Le, Y.; and Yang, X. S. 2015. Tiny ImageNet Visual Recognition Challenge
work page 2015
- [16]
- [17]
-
[18]
Nilsback, M.-E.; and Zisserman, A. 2008. Automated Flower Classification over a Large Number of Classes. 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, 722--729
work page 2008
-
[19]
M.; Vedaldi, A.; Zisserman, A.; and Jawahar, C
Parkhi, O. M.; Vedaldi, A.; Zisserman, A.; and Jawahar, C. V. 2012. Cats and dogs. 2012 IEEE Conference on Computer Vision and Pattern Recognition, 3498--3505
work page 2012
-
[20]
S.; Keysers, D.; and Houlsby, N
Riquelme, C.; Puigcerver, J.; Mustafa, B.; Neumann, M.; Jenatton, R.; Pinto, A. S.; Keysers, D.; and Houlsby, N. 2021. Scaling Vision with Sparse Mixture of Experts. In Neural Information Processing Systems
work page 2021
-
[21]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N. M.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q. V.; Hinton, G. E.; and Dean, J. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. ArXiv, abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Shi, B.; Xia, S.; Yang, X.; Chen, H.; Kou, Z.; and Geng, X. 2024. Building Variable-Sized Models via Learngene Pool. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 14946--14954
work page 2024
-
[23]
Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; and J'egou, H. 2020. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning
work page 2020
-
[24]
Wang, Q.; Yang, X.; Chen, H.; and Geng, X. 2024. Vision Transformers as Probabilistic Expansion from Learngene. In Forty-first International Conference on Machine Learning
work page 2024
- [25]
-
[26]
Wang, Q.-F.; Geng, X.; Lin, S.-X.; Xia, S.-Y.; Qi, L.; and Xu, N. 2022. Learngene: From open-world to your learning task. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 8557--8565
work page 2022
- [27]
-
[28]
Xia, S.; Zhang, M.; Yang, X.; Chen, R.; Chen, H.; and Geng, X. 2024 a . Transformer as Linear Expansion of Learngene. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 16014--16022
work page 2024
-
[29]
Xia, S.; Zu, Y.; Yang, X.; and Geng, X. 2024 b . Initializing variable-sized vision transformers from learngene with learnable transformation. Advances in Neural Information Processing Systems, 37: 43341--43366
work page 2024
-
[31]
Ye, H.; and Xu, D. 2023. TaskExpert: Dynamically Assembling Multi-Task Representations with Memorial Mixture-of-Experts. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 21771--21780
work page 2023
-
[32]
Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; and Torralba, A. 2017. Scene Parsing through ADE20K Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
work page 2017
-
[33]
Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; and Torralba, A. 2019. Semantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision, 127(3): 302--321
work page 2019
-
[34]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learngene: From open-world to your learning task , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[35]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Building Variable-Sized Models via Learngene Pool , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[36]
Advances in Neural Information Processing Systems , volume=
Initializing variable-sized vision transformers from learngene with learnable transformation , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Transformer as Linear Expansion of Learngene , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[38]
Forty-first International Conference on Machine Learning , year=
Vision Transformers as Probabilistic Expansion from Learngene , author=. Forty-first International Conference on Machine Learning , year=
-
[39]
arXiv preprint arXiv:2404.16897 , year=
Exploring Learngene via Stage-wise Weight Sharing for Initializing Variable-sized Models , author=. arXiv preprint arXiv:2404.16897 , year=
-
[40]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
MuIT: An End-to-End Multitask Learning Transformer , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2022
-
[41]
International Conference on Learning Representations , year=
Towards Impartial Multi-task Learning , author=. International Conference on Learning Representations , year=
-
[42]
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
End-To-End Multi-Task Learning With Attention , author=. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2019
-
[43]
Neural Information Processing Systems , year=
Variational Multi-Task Learning with Gumbel-Softmax Priors , author=. Neural Information Processing Systems , year=
-
[44]
Neural Information Processing Systems , year=
Learning Multiple Tasks with Multilinear Relationship Networks , author=. Neural Information Processing Systems , year=
-
[45]
IEEE Transactions on Knowledge and Data Engineering , year=
Learning Linear and Nonlinear Low-Rank Structure in Multi-Task Learning , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[46]
Which Tasks Should Be Learned Together in Multi-task Learning? , author=. ArXiv , year=
-
[47]
2019 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Many Task Learning With Task Routing , author=. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
work page 2019
-
[48]
2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Robust Learning Through Cross-Task Consistency , author=. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2020
-
[49]
European Conference on Computer Vision , year=
MTFormer: Multi-task Learning via Transformer and Cross-Task Reasoning , author=. European Conference on Computer Vision , year=
-
[50]
2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Pre-Trained Image Processing Transformer , author=. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2021
-
[51]
2021 IEEE International Intelligent Transportation Systems Conference (ITSC) , year=
Spatio-Temporal Multi-Task Learning Transformer for Joint Moving Object Detection and Segmentation , author=. 2021 IEEE International Intelligent Transportation Systems Conference (ITSC) , year=
work page 2021
-
[52]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Mod-Squad: Designing Mixtures of Experts As Modular Multi-Task Learners , author=. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2023
-
[53]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , author=. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
work page 2021
-
[54]
Adaptive Mixtures of Local Experts , author=. Neural Computation , year=
-
[55]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. ArXiv , year=
-
[56]
\ \ MoE-RBench\ \ : Towards Building Reliable Language Models with Sparse Mixture-of-Experts , author=. 2024 , url=
work page 2024
-
[57]
Neural Information Processing Systems , year=
Scaling Vision with Sparse Mixture of Experts , author=. Neural Information Processing Systems , year=
- [58]
-
[59]
Task-customized Masked Autoencoder via Mixture of Cluster-conditional Experts , author=. ArXiv , year=
-
[60]
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models , author=. ArXiv , year=
-
[61]
Alternating Gradient Descent and Mixture-of-Experts for Integrated Multimodal Perception , author=. ArXiv , year=
-
[62]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
TaskExpert: Dynamically Assembling Multi-Task Representations with Memorial Mixture-of-Experts , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
work page 2023
-
[63]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[64]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. ArXiv , year=
-
[65]
International Conference on Machine Learning , year=
Training data-efficient image transformers & distillation through attention , author=. International Conference on Machine Learning , year=
-
[66]
International Journal of Computer Vision , year=
ImageNet Large Scale Visual Recognition Challenge , author=. International Journal of Computer Vision , year=
-
[67]
Mod-Squad: Designing Mixture of Experts As Modular Multi-Task Learners , author=. ArXiv , year=
-
[68]
European Conference on Computer Vision , year=
Food-101 - Mining Discriminative Components with Random Forests , author=. European Conference on Computer Vision , year=
-
[69]
2013 IEEE International Conference on Computer Vision Workshops , year=
3D Object Representations for Fine-Grained Categorization , author=. 2013 IEEE International Conference on Computer Vision Workshops , year=
work page 2013
-
[70]
2004 Conference on Computer Vision and Pattern Recognition Workshop , year=
Learning Generative Visual Models from Few Training Examples: An Incremental Bayesian Approach Tested on 101 Object Categories , author=. 2004 Conference on Computer Vision and Pattern Recognition Workshop , year=
work page 2004
-
[71]
2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
The iNaturalist Species Classification and Detection Dataset , author=. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
work page 2018
-
[72]
Learning Multiple Layers of Features from Tiny Images , author=. 2009 , url=
work page 2009
-
[73]
2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing , year=
Automated Flower Classification over a Large Number of Classes , author=. 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing , year=
work page 2008
-
[74]
2012 IEEE Conference on Computer Vision and Pattern Recognition , year=
Cats and dogs , author=. 2012 IEEE Conference on Computer Vision and Pattern Recognition , year=
work page 2012
-
[75]
2014 IEEE Conference on Computer Vision and Pattern Recognition , year=
Describing Textures in the Wild , author=. 2014 IEEE Conference on Computer Vision and Pattern Recognition , year=
work page 2014
-
[76]
Tiny ImageNet Visual Recognition Challenge , author=
-
[77]
2009 IEEE Conference on Computer Vision and Pattern Recognition , year=
ImageNet: A large-scale hierarchical image database , author=. 2009 IEEE Conference on Computer Vision and Pattern Recognition , year=
work page 2009
-
[78]
Learngene: Inheriting Condensed Knowledge from the Ancestry Model to Descendant Models , author=. ArXiv , year=
-
[79]
International Journal of Computer Vision , volume=
Semantic understanding of scenes through the ade20k dataset , author=. International Journal of Computer Vision , volume=. 2019 , publisher=
work page 2019
-
[80]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
Scene Parsing through ADE20K Dataset , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[81]
International journal of computer vision , volume=
The pascal visual object classes challenge: A retrospective , author=. International journal of computer vision , volume=. 2015 , publisher=
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.