A Simulated Federated Analysis of MS-Induced Brain Lesions
Pith reviewed 2026-05-12 01:18 UTC · model grok-4.3
The pith
A simulation framework emulates federated analysis of MS brain lesions on synthetic cohorts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors construct a simulation framework that emulates federated workflows for MS lesion analysis. Synthetic cohorts are generated to reflect the heterogeneity and demographics of real MS cases, combined with public imaging data. Federated variants of segmentation, survival analysis, and PCA operate across isolated sites with secure aggregation of outputs, replicating site-specific preprocessing and data governance without sharing raw records.
What carries the argument
The simulation framework that emulates a federation of high-fidelity synthetic MS cohorts together with real imaging data to run distributed segmentation, survival analysis, and PCA under realistic governance and secure aggregation rules.
If this is right
- Federated methods for MS lesion segmentation and clinical analysis can be developed and tuned without direct access to sensitive patient records.
- Different federated aggregation strategies can be benchmarked side-by-side on identical synthetic cohorts that preserve realistic data distributions.
- The framework supports repeatable evaluation of privacy-preserving techniques for both imaging and tabular clinical tasks in a multi-site setting.
- New federated algorithms can be stress-tested against the specific heterogeneity patterns built into the MS synthetic cohorts before real-world deployment.
Where Pith is reading between the lines
- The same simulation approach could be extended to other privacy-sensitive domains such as oncology or cardiology by regenerating synthetic cohorts with matching disease statistics.
- Adding support for federated deep learning models on the imaging component would expose practical issues like communication overhead that are only hinted at in the current segmentation task.
- Periodic updates to the synthetic cohort generator using fresh real-world summary statistics could keep the testbed aligned with evolving MS patient populations.
Load-bearing premise
The synthetic cohorts accurately mirror the complexity, heterogeneity, and demographics of real MS datasets while the simulation faithfully reproduces authentic federated workflows including site-specific preprocessing and secure aggregation.
What would settle it
Comparing lesion segmentation accuracy, survival model outputs, or PCA components obtained from the simulation against the same tasks run on actual multi-center MS clinical datasets would reveal whether the synthetic data and workflow replication match real conditions closely enough.
Figures



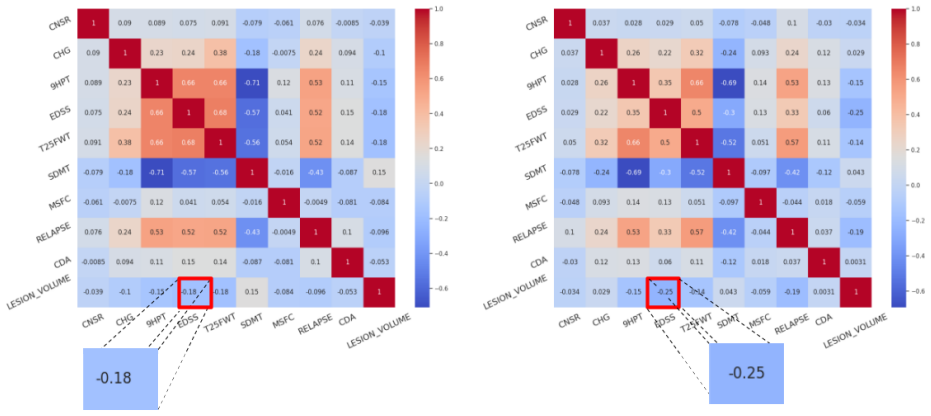

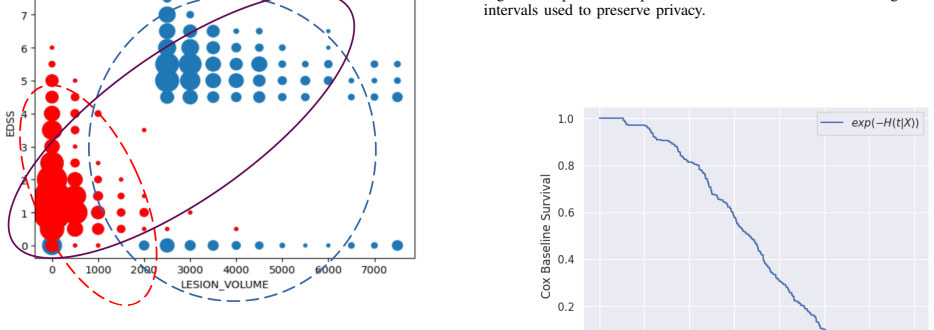

read the original abstract
Federated techniques such as federated learning and federated analysis have emerged as a powerful paradigm for enabling multi-center research on sensitive clinical data while preserving patient privacy. In this study, we introduce a simulation framework that emulates a real-world federated research project focused on the analysis of multiple sclerosis (MS) patient data. The project comprises two components: an image segmentation task and a clinical data analysis task, where federated variants of survival analysis and Principal Component Analysis (PCA) are employed. To capture the complexity and heterogeneity of real clinical datasets, we construct a federation of high-fidelity synthetic cohorts designed to mirror MS-related clinical and demographic characteristics, while the imaging component leverages publicly available real-world datasets. Our simulation replicates key elements of authentic federated workflows, including distributed data governance, site-specific preprocessing, model training across isolated nodes, and the secure aggregation of analytical outputs. This framework provides a realistic testbed for developing, evaluating, and benchmarking federated learning methods in the context of MS research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a simulation framework for federated analysis of multiple sclerosis (MS) data. It comprises an image segmentation task leveraging public real-world datasets and a clinical analysis task using high-fidelity synthetic cohorts designed to replicate MS-related clinical and demographic characteristics. Federated variants of survival analysis and PCA are applied, with the overall workflow emulating real federated elements including site-specific preprocessing, distributed governance, model training on isolated nodes, and secure aggregation of outputs. The framework is presented as a realistic testbed for developing, evaluating, and benchmarking federated learning methods in MS research.
Significance. If the synthetic cohorts and workflows were shown to accurately capture real MS heterogeneity, missingness patterns, and site biases, the framework could serve as a useful privacy-preserving platform for testing federated algorithms on clinically relevant tasks. The dual focus on imaging and tabular clinical analysis broadens potential applicability. However, the current lack of any quantitative fidelity checks or benchmarking results means the work remains a high-level descriptive construction whose practical value for the claimed use case is not yet demonstrated.
major comments (2)
- [Abstract] Abstract: The central claim that the framework 'provides a realistic testbed' rests on the assertion that 'high-fidelity synthetic cohorts' mirror real MS clinical and demographic complexity. No statistical comparisons (e.g., distributional distances, correlation structures, or outcome concordance metrics) against any real MS reference dataset are reported, leaving open the possibility that unmodeled heterogeneity or site-specific biases could alter federated convergence or privacy behavior.
- [Abstract] Abstract and overall manuscript structure: No validation results, error analysis, implementation details, or benchmarking outcomes (federated vs. centralized) are provided to demonstrate that the simulated workflows function as intended or produce comparable results to real federated deployments. This absence directly undermines the utility of the framework for the stated purpose of developing and evaluating federated methods.
minor comments (1)
- [Abstract] Abstract: The description of the two tasks (image segmentation and clinical analysis) would benefit from explicit mention of the number of sites, cohort sizes, or specific preprocessing steps to allow readers to assess the scale of the simulation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, clarifying the intended scope of the simulation framework while agreeing to strengthen the presentation with additional details on data construction and implementation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the framework 'provides a realistic testbed' rests on the assertion that 'high-fidelity synthetic cohorts' mirror real MS clinical and demographic complexity. No statistical comparisons (e.g., distributional distances, correlation structures, or outcome concordance metrics) against any real MS reference dataset are reported, leaving open the possibility that unmodeled heterogeneity or site-specific biases could alter federated convergence or privacy behavior.
Authors: We appreciate the referee drawing attention to this aspect of our claim. The synthetic cohorts were generated using parameters and distributions drawn from published MS clinical studies and real-world datasets to replicate key characteristics including age, sex, lesion load, EDSS scores, and survival outcomes. Explicit quantitative fidelity metrics were not reported in the original manuscript because the primary focus was on emulating the federated workflow rather than validating the data generator itself. We agree that adding such checks would better support the 'high-fidelity' description. In revision we will include a new subsection with basic statistical summaries (means, variances, and selected correlation structures) compared against reference statistics from the literature and public MS cohorts. revision: partial
-
Referee: [Abstract] Abstract and overall manuscript structure: No validation results, error analysis, implementation details, or benchmarking outcomes (federated vs. centralized) are provided to demonstrate that the simulated workflows function as intended or produce comparable results to real federated deployments. This absence directly undermines the utility of the framework for the stated purpose of developing and evaluating federated methods.
Authors: The manuscript centers on describing a simulation framework that replicates authentic federated elements (site-specific preprocessing, isolated node training, and secure aggregation). Because the underlying data are fully synthetic and controlled by the authors, centralized and federated results are identical by construction once the aggregation step is correctly implemented; thus a separate benchmarking comparison was not performed. We acknowledge that more concrete implementation details and illustrative outputs would improve the paper's utility as a testbed. In the revised version we will expand the Methods section with pseudocode for the federated PCA and survival analysis procedures, plus example numerical outputs from the simulation runs to demonstrate that the workflows execute as described. revision: partial
Circularity Check
No circularity: descriptive framework with no derivations or self-referential predictions
full rationale
The paper introduces a simulation framework for federated MS analysis using synthetic cohorts and real imaging data. No equations, predictions, or first-principles results are claimed anywhere in the provided text. The synthetic cohort construction is presented as a design choice to emulate real data heterogeneity and workflows (site-specific preprocessing, secure aggregation, survival analysis, PCA), without any fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The central claim of providing a realistic testbed rests on descriptive construction rather than any derivation chain that reduces to its inputs. This is a standard framework paper; concerns about validation of synthetic fidelity are correctness issues, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://arxiv.org/abs/ 2006.08997
M. Andreux, A. Manoel, R. Menuet, C. Saillard, and C. Simpson. Feder- ated survival analysis with discrete-time cox models. arXiv:2006.08997,
-
[2]
International Workshop on Federated Learning for User Privacy and Data Confidentiality in conjunction with ICML 2020
work page 2020
-
[3]
Register & unregister datasets
Apheris. Register & unregister datasets. https://www.apheris.com/docs/ gateway/latest/data-custodian/register-and-unregister-datasets.html. Ac- cessed: 2025-12-04
work page 2025
-
[4]
L. Bai, D. Wang, H. Wang, M. Barnett, M. Cabezas, W. Cai, F. Cala- mante, K. Kyle, D. Liu, L. Ly, A. Nguyen, C.-C. Shieh, R. Sullivan, G. Zhan, W. Ouyang, and C. Wang. Improving multiple sclerosis lesion segmentation across clinical sites: A federated learning approach with noise-resilient training.Artificial Intelligence in Medicine, 152:102872, 2024
work page 2024
-
[5]
O. Choudhury, E. Trautmann, I. Hales, J.-T. Prieto, and U. Ratan. Federated learning-based protein language models with apheris on aws. AWS for Industries blog, August 2025. Accessed 2025
work page 2025
-
[6]
D. R. Cox. Regression models and life-tables.Journal of the Royal Statistical Society: Series B (Methodological), 34(2):187–220, 1972
work page 1972
-
[7]
A. R. Elkordy, Y . H. Ezzeldin, S. Han, S. Sharma, C. He, S. Mehrotra, and S. Avestimehr. Federated analytics: A survey.APSIPA Transactions on Signal and Information Processing, 12(1):e4, 2023
work page 2023
-
[8]
F. Guarnera, A. Rondinella, E. Crispino, G. Russo, C. D. Lorenzo, D. Maimone, F. Pappalardo, and S. Battiato. MSLesSeg: baseline and benchmarking of a new Multiple Sclerosis Lesion Segmentation dataset, 6 2025
work page 2025
- [9]
-
[10]
I. Hagestedt, I. Hales, E. Boernert, H. R. Roth, M. A. Hoeh, R. R ¨ohm, E. Dobson, and J. T. Prieto. Toward a tipping point in federated learning in healthcare and life sciences.Patterns, 5(11):101077, 2024
work page 2024
-
[11]
S. Hindawi, B. Szubstarski, E. Boernert, B. Tackenberg, and J. Wuerfel. Federated learning for lesion segmentation in multiple sclerosis: a real- world multi-center feasibility study.Frontiers in Neurology, V olume 16 - 2025, 2025
work page 2025
-
[12]
F. Isensee, P. F. Jaeger, S. A. A. Kohl, J. Petersen, and K. H. Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation.Nature Methods, 18(2):203–211, 2021
work page 2021
-
[13]
F. Isensee, J. Petersen, A. Klein, D. Zimmerer, P. F. Jaeger, S. Kohl, J. Wasserthal, G. Koehler, T. Norajitra, S. Wirkert, and K. H. Maier- Hein. nnu-net: Self-adapting framework for u-net-based medical image segmentation, 2018
work page 2018
-
[14]
I. T. Jolliffe.Principal Component Analysis. Springer Series in Statistics. Springer-Verlag, 2nd edition, 2002
work page 2002
-
[15]
E. L. Kaplan and P. Meier. Individual nonparametric estimation from in- complete observations.Journal of the American Statistical Association, 53(282):457–481, 1958
work page 1958
-
[16]
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas. Communication-efficient learning of deep networks from decentralized data. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), pages 1273–1282. PMLR, 2017
work page 2017
-
[17]
F. Niro, M. Di Renzo, P. Agnello, M. Petyx, G. Ciaramella, F. Martinelli, M. Cesarelli, A. Santone, and F. Mercaldo. A privacy-preserving method for explainable multiple sclerosis detection through federated machine learning. In E. Rodol `a, F. Galasso, and I. Masi, editors,Image Analysis and Processing - ICIAP 2025 Workshops, pages 29–40, Cham, 2026. Spr...
work page 2025
-
[18]
J. Oh, J. Smolders, F. Buijs, J. Federer-Gsponer, G. M. zu H ¨orste, M. Mamdani, C. Perrone, D. L. Mowery, T. K ¨uhnel, K. van Tulder, C. Testa, M. C. Elze, R. Pedotti, L. Kaczmarek, V . Sharma, A. Tacken- berg, Bj ¨orn abd Bar-Or, and H. Wiendl. Integrating multicentre data to explore rwpirma: Results from the intonate-ms consortium. InECTRIMS 2025, Barc...
work page 2025
-
[19]
J. Oh, J. Smolders, F. Buijs, R. Pedotti, F. Dahlke, L. Kaczmarek, A. Kemmisetti, V . Sharma, D. Heinzmann, B. Tackenberg, A. Bar-Or, and H. Wiendl. Utility and implementation of a federated research infrastructure to assess lack of disease stability as a real-world surrogate of PIRA, by combining MS clinical trial and real-world cohort data (the INTONATE...
work page 2023
-
[20]
J. Oh, J. Smolders, F. Buijs, R. Pedotti, F. Dahlke, L. Kaczmarek, A. Kemmisetti, V . Sharma, D. Heinzmann, B. Tackenberg, et al. Utility and implementation of a federated research infrastructure to assess lack of disease stability as a real-world surrogate of pira, by combining ms clinical trial and real-world cohort data (the intonate-ms consortium). Mu...
work page 2023
-
[21]
A. Pirmani, E. De Brouwer, A. Arany, M. Oldenhof, A. Passemiers, A. Faes, T. Kalincik, S. Ozakbas, R. Gouider, B. Willekens, D. Ho- rakova, E. K. Havrdova, F. Patti, A. Prat, A. Lugaresi, V . Tomassini, P. Grammond, E. Cartechini, I. Roos, C. Boz, R. Alroughani, M. P. Am- ato, K. Buzzard, J. Lechner-Scott, J. Guimar ˜aes, C. Solaro, O. Gerlach, A. Soysal,...
work page 2025
-
[22]
A. Pirmani, E. De Brouwer, L. Geys, T. Parciak, Y . Moreau, and L. Peeters. The journey of data within a global data sharing initiative: A federated 3-layer data analysis pipeline to scale up multiple sclerosis research.JMIR Medical Informatics, 11:e48030, 2023
work page 2023
-
[23]
E. H. Simpson. The interpretation of interaction in contingency tables. Journal of the Royal Statistical Society, Series B, 13(2):238–241, 1951
work page 1951
-
[24]
M. Trojano, P. Iaffaldano, M. Copetti, J. Drahota, L. Forsberg, E. F. Mouresan, L. Pontieri, T. Spelman, N. Toschi, H. Butzkueven, A. Glaser, J. Hillert, D. Horakova, M. Magyari, S. Vukusic, G. Lucisano, and T. Kalincik. Big multiple sclerosis data network: novel modelling approaches for real-world data analysis.Journal of Neurology, 272(12):754, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.