Recognition: no theorem link
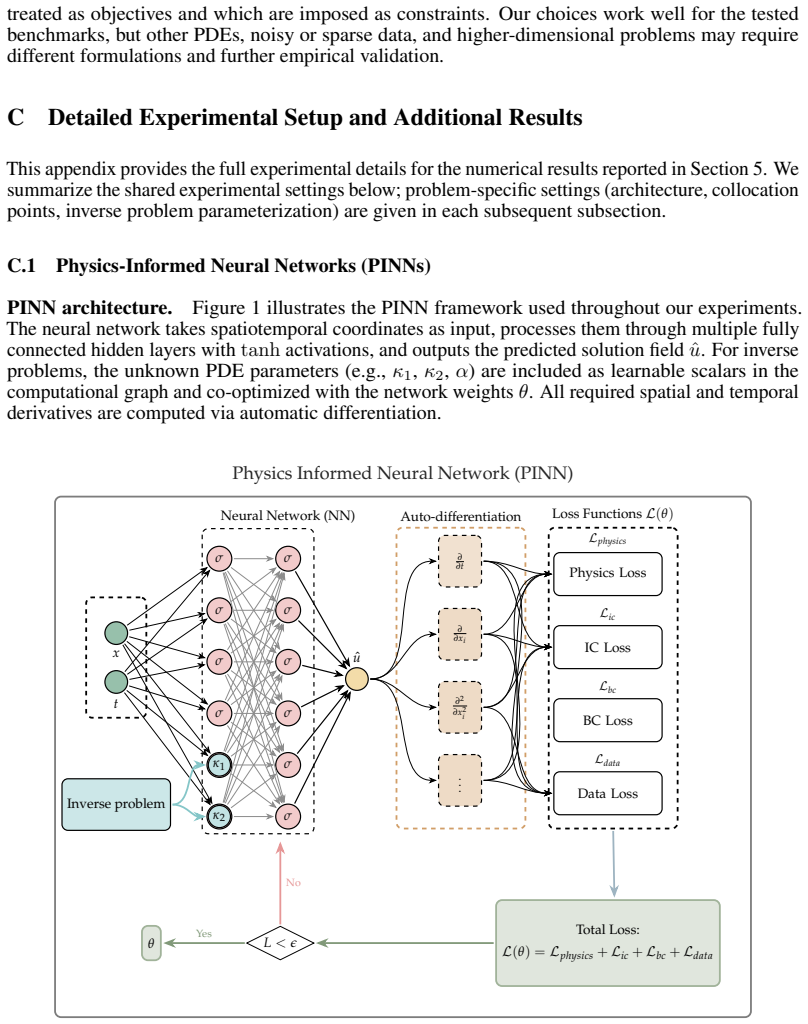
AdamFLIP: Adaptive Momentum Feedback Linearization Optimization for Hard Constrained PINN Training
Pith reviewed 2026-05-12 00:47 UTC · model grok-4.3
The pith
AdamFLIP reformulates PINN training as an equality-constrained optimization problem by using feedback linearization to drive constraint residuals into stable linear contraction dynamics before applying Adam adaptation to the Lagrangian.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdamFLIP computes the Lagrange multiplier as a feedback input that locally drives these residuals toward stable linear contraction dynamics. AdamFLIP then applies Adam-style first- and second-moment adaptation to the resulting feedback-linearized Lagrangian gradient, combining principled constraint handling with the scalability and robustness of adaptive neural-network optimization.
What carries the argument
Feedback linearization of the constraint residual dynamics, which produces a controlled linear contraction that is then optimized by Adam on the Lagrangian gradient.
If this is right
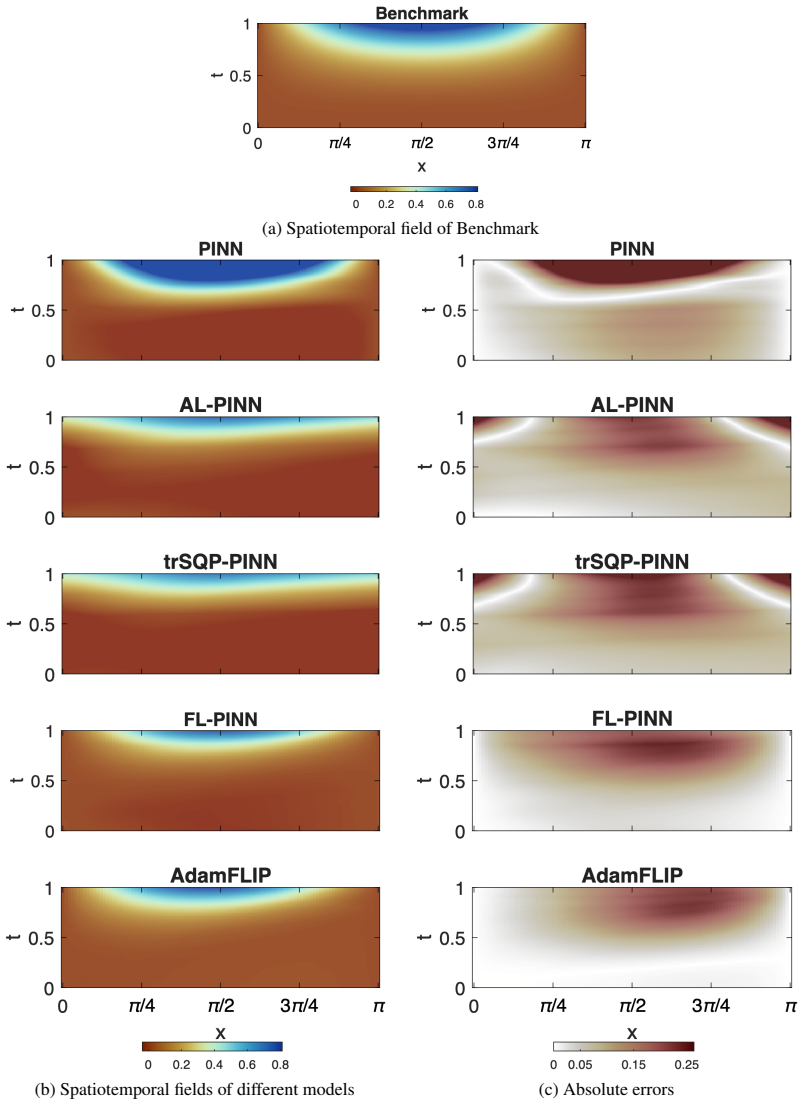
- The method yields lower solution errors than both standard soft-constrained PINNs and existing hard-constrained optimizers on forward and inverse PDE problems.
- Hard constraint satisfaction is achieved without manual loss-weight balancing, reducing sensitivity to hyper-parameters.
- The approach remains computationally scalable because it retains Adam-style moment adaptation on the modified gradient.
- Improved satisfaction of initial and boundary conditions follows directly from driving residuals to contraction dynamics rather than penalizing them.
Where Pith is reading between the lines
- The same feedback-linearization step could be applied to other equality-constrained neural-network training tasks outside PDEs, such as physics-informed generative models.
- If the contraction rate can be adapted online, training speed on stiff PDEs might increase without sacrificing final accuracy.
- The framework naturally supports mixed hard and soft constraints by treating only selected residuals with feedback linearization while leaving others in the loss.
Load-bearing premise
The feedback linearization produces a stable linear contraction dynamics for the constraint residuals that can be maintained throughout training while the Adam adaptation remains effective on the resulting Lagrangian gradient.
What would settle it
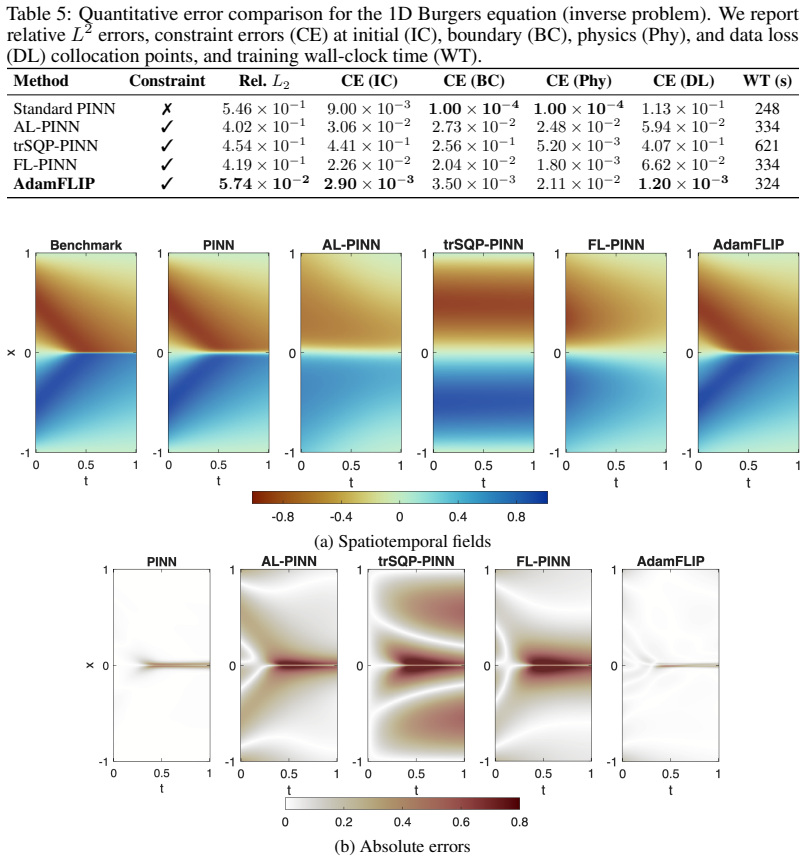
On the Navier-Stokes benchmark, failure to reduce relative L2 error by more than two thirds compared to the next best method, or observation that the constraint residuals do not contract according to the predicted linear dynamics during training.
Figures





read the original abstract
Physics-informed neural networks (PINNs) provide a flexible framework for solving forward and inverse problems governed by partial differential equations (PDEs), but standard PINN training typically relies on soft penalty formulations that combine PDE residuals, data mismatch, and initial/boundary conditions using manually chosen weights. This often leads to ill-conditioning, sensitivity to loss weights, and poor constraint satisfaction. In this work, we reformulate PINN training as an equality-constrained optimization problem and propose a novel Adaptive Momentum Feedback Linearization Optimization for Hard Constrained PINN (AdamFLIP). The key idea is to view the constraint residuals as the output of a controlled dynamical system and to compute the Lagrange multiplier as a feedback input that locally drives these residuals toward stable linear contraction dynamics. AdamFLIP then applies Adam-style first- and second-moment adaptation to the resulting feedback-linearized Lagrangian gradient, combining principled constraint handling with the scalability and robustness of adaptive neural-network optimization. We test AdamFLIP on a range of benchmark forward and inverse PDE problem, and it consistently outperforms both the standard soft-constrained PINN and state-of-the-art constrained optimizers. Specifically, on the Navier--Stokes equations benchmark, AdamFLIP \textbf{reduces relative $L_2$ error by more than two thirds} for the predicted solution compared to the next best method. Our AdamFLIP framework provides an effective and computationally scalable hard constraint optimization method for PINN training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce AdamFLIP for hard-constrained PINN training by reformulating it as equality-constrained optimization. It computes Lagrange multipliers using feedback linearization to drive constraint residuals to stable linear contraction dynamics, then optimizes the Lagrangian gradient with Adam. On benchmarks including Navier-Stokes, it outperforms soft PINNs and other methods, reducing relative L2 error by more than two thirds on Navier-Stokes.
Significance. If the contraction dynamics are preserved under adaptive updates, this provides a principled hard-constraint method combining feedback control with adaptive optimization, potentially improving PINN accuracy and robustness for PDEs. The reported error reduction on Navier-Stokes indicates significant practical impact if reproducible and if the stability assumption holds.
major comments (3)
- [Feedback linearization and Lagrangian gradient construction] The feedback linearization computes a Lagrange multiplier to enforce linear contraction on residuals, but the manuscript provides no analysis or verification showing that this closed-loop contraction persists when Adam updates alter the network parameters and thus the residual Jacobian (central to the hard-constraint claim).
- [Navier-Stokes experiments and results] The Navier-Stokes result (more than two-thirds relative L2 error reduction) is load-bearing for the performance claims, yet no metrics are reported on residual contraction rates or constraint violation norms during training to confirm the dynamics remain linear and contracting rather than reverting to an adaptive soft penalty.
- [Method hyperparameters and experimental setup] The feedback gain and contraction rate are free parameters whose selection is not analyzed for sensitivity; if chosen after seeing benchmark performance, this undermines the generality of the outperformance claims over soft-constrained PINNs and other optimizers.
minor comments (2)
- [Abstract] Abstract contains a grammatical error: 'a range of benchmark forward and inverse PDE problem' should read 'problems'.
- [Overall presentation] Notation for the feedback law, Lagrange multiplier, and Adam moment estimates could be clarified with explicit equations to distinguish the linearization step from the adaptive gradient update.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments point by point below, providing clarifications and indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: The feedback linearization computes a Lagrange multiplier to enforce linear contraction on residuals, but the manuscript provides no analysis or verification showing that this closed-loop contraction persists when Adam updates alter the network parameters and thus the residual Jacobian (central to the hard-constraint claim).
Authors: We agree that the manuscript lacks a formal analysis proving that the contraction dynamics are preserved globally under the Adam updates, which modify the network parameters and thus the residual Jacobian at each step. The method recomputes the Lagrange multiplier at every iteration using the current Jacobian to enforce the local linear contraction, but the adaptive momentum in Adam introduces an approximation. This is a limitation of the current theoretical treatment. In the revised version, we will add a section discussing the local nature of the feedback linearization and include empirical evidence by reporting the evolution of the residual norms to show that the constraints remain well-satisfied throughout training. revision: partial
-
Referee: The Navier-Stokes result (more than two-thirds relative L2 error reduction) is load-bearing for the performance claims, yet no metrics are reported on residual contraction rates or constraint violation norms during training to confirm the dynamics remain linear and contracting rather than reverting to an adaptive soft penalty.
Authors: The referee correctly notes the absence of such metrics in the manuscript. To substantiate the hard-constraint enforcement, we will include additional plots in the revised manuscript showing the PDE residual norms and the achieved contraction rates over the course of training for the Navier-Stokes benchmark. These will demonstrate that the residuals are driven to zero in a manner consistent with the designed linear dynamics rather than behaving as a soft penalty. revision: yes
-
Referee: The feedback gain and contraction rate are free parameters whose selection is not analyzed for sensitivity; if chosen after seeing benchmark performance, this undermines the generality of the outperformance claims over soft-constrained PINNs and other optimizers.
Authors: We selected the feedback gain and contraction rate based on theoretical considerations for stability (ensuring the contraction rate is positive and the gain is sufficiently large) and preliminary experiments on simpler PDEs before evaluating on the full benchmarks. However, we acknowledge that a dedicated sensitivity analysis would strengthen the claims. In the revision, we will add a sensitivity study varying these parameters on the Navier-Stokes problem and report the resulting performance variations to confirm robustness. revision: yes
Circularity Check
No significant circularity; derivation introduces independent feedback-linearized optimizer validated empirically
full rationale
The paper's central construction defines a feedback law that enforces linear contraction dynamics on residuals by design (standard feedback linearization), then applies Adam to the resulting Lagrangian gradient. This is not self-definitional or a fitted input renamed as prediction; the contraction property follows directly from the chosen feedback gain and is not claimed as an emergent result. Performance claims rest on benchmark comparisons rather than any self-citation chain or uniqueness theorem imported from prior author work. No load-bearing step reduces to its own inputs by construction, and the method remains falsifiable via external PDE benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- feedback gain / contraction rate
- Adam hyperparameters (beta1, beta2, epsilon)
axioms (2)
- domain assumption The map from network parameters to PDE residuals admits a locally linearizable controlled dynamics
- domain assumption The Lagrange multiplier computed via feedback linearization yields a gradient that can be safely adapted by Adam without violating constraint satisfaction
Reference graph
Works this paper leans on
-
[1]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[2]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[3]
Salvatore Cuomo, Vincenzo Schiano Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics–informed neural networks: Where we are and what’s next.Journal of Scientific Computing, 92(3):88, 2022
work page 2022
-
[4]
Shengze Cai, Zhiping Mao, Zhicheng Wang, Minglang Yin, and George Em Karniadakis. Physics-informed neural networks (pinns) for fluid mechanics: A review.Acta Mechanica Sinica, 37(12):1727–1738, 2021
work page 2021
-
[5]
Jiangtao Guo, Hao Zhu, Yujie Yang, and Chenrui Guo. Advances in physics-informed neural networks for solving complex partial differential equations and their engineering applications: A systematic review.Engineering Applications of Artificial Intelligence, 161:112044, 2025
work page 2025
-
[6]
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021
work page 2021
-
[7]
Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks.Advances in neural information processing systems, 34:26548–26560, 2021
work page 2021
-
[8]
An expert’s guide to training physics-informed neural networks.arXiv preprint arXiv:2308.08468, 2023
Sifan Wang, Shyam Sankaran, Hanwen Wang, and Paris Perdikaris. An expert’s guide to training physics-informed neural networks.arXiv preprint arXiv:2308.08468, 2023
-
[9]
Suryanarayana Maddu, Dominik Sturm, Christian L Müller, and Ivo F Sbalzarini. Inverse dirichlet weighting enables reliable training of physics informed neural networks.Machine Learning: Science and Technology, 3(1):015026, 2022
work page 2022
-
[10]
Kailai Xu and Eric Darve. Trust region method for coupled systems of pde solvers and deep neural networks.arXiv preprint arXiv:2105.07552, 2021
-
[11]
Yongcun Song, Xiaoming Yuan, and Hangrui Yue. The admm-pinns algorithmic framework for nonsmooth pde-constrained optimization: A deep learning approach.SIAM Journal on Scientific Computing, 46(6):C659–C687, 2024
work page 2024
- [12]
-
[13]
Hwijae Son, Sung Woong Cho, and Hyung Ju Hwang. Enhanced physics-informed neural net- works with augmented lagrangian relaxation method (al-pinns).Neurocomputing, 548:126424, 2023
work page 2023
-
[14]
Qifeng Hu, Shamsulhaq Basir, and Inanc Senocak. Conditionally adaptive augmented la- grangian method for physics-informed learning of forward and inverse problems.arXiv preprint arXiv:2508.15695, 2025. 10
-
[15]
Xiaoran Cheng and Sen Na. Physics-informed neural networks with trust-region sequential quadratic programming.arXiv preprint arXiv:2409.10777, 2024
-
[16]
Isaac E Lagaris, Aristidis Likas, and Dimitrios I Fotiadis. Artificial neural networks for solving ordinary and partial differential equations.IEEE transactions on neural networks, 9(5):987– 1000, 1998
work page 1998
-
[17]
Neural networks with physics-informed architectures and constraints for dynamical systems modeling
Franck Djeumou, Cyrus Neary, Eric Goubault, Sylvie Putot, and Ufuk Topcu. Neural networks with physics-informed architectures and constraints for dynamical systems modeling. In Learning for Dynamics and Control Conference, pages 263–277. PMLR, 2022
work page 2022
-
[18]
Christopher Straub, Philipp Brendel, Vlad Medvedev, and Andreas Rosskopf. Hard-constraining neumann boundary conditions in physics-informed neural networks via fourier feature embed- dings.arXiv preprint arXiv:2504.01093, 2025
-
[19]
Physical informed neural networks with soft and hard boundary constraints for solving advection- diffusion equations using fourier expansions.Computers & Mathematics with Applications, 159:60–75, 2024
work page 2024
-
[20]
Hao Chen, Gonzalo E Constante Flores, and Can Li. Physics-informed neural networks with hard linear equality constraints.Computers & Chemical Engineering, 189:108764, 2024
work page 2024
-
[21]
The Sample Average Approximation Method for Stochastic Discrete Optimization,
James Kotary, Ferdinando Fioretto, Pascal Van Hentenryck, and Bryan Wilder. End-to-end constrained optimization learning: A survey.arXiv preprint arXiv:2103.16378, 2021
-
[22]
A comprehensive survey on safe reinforcement learning
Javier Garcıa and Fernando Fernández. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research, 16(1):1437–1480, 2015
work page 2015
-
[23]
Yatin Nandwani, Abhishek Pathak, and Parag Singla. A primal dual formulation for deep learning with constraints.Advances in neural information processing systems, 32, 2019
work page 2019
-
[24]
Responsive safety in reinforcement learning by pid lagrangian methods
Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforcement learning by pid lagrangian methods. InInternational conference on machine learning, pages 9133–9143. PMLR, 2020
work page 2020
-
[25]
Albert S Berahas, Frank E Curtis, Daniel Robinson, and Baoyu Zhou. Sequential quadratic optimization for nonlinear equality constrained stochastic optimization.SIAM Journal on Optimization, 31(2):1352–1379, 2021
work page 2021
-
[26]
Youngjae Min and Navid Azizan. Hardnet: Hard-constrained neural networks with universal approximation guarantees.arXiv preprint arXiv:2410.10807, 2024
-
[27]
Panagiotis D Grontas, Antonio Terpin, Efe C Balta, Raffaello D’Andrea, and John Lygeros. Pinet: Optimizing hard-constrained neural networks with orthogonal projection layers.arXiv preprint arXiv:2508.10480, 2025
-
[28]
Constrained optimization from a control perspective via feedback linearization
Runyu Zhang, Arvind Raghunathan, Jeff S Shamma, and Na Li. Constrained optimization from a control perspective via feedback linearization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[29]
Runyu Zhang, Gioele Zardini, Asuman Ozdaglar, Jeff Shamma, and Na Li. Zeroth-order constrained optimization from a control perspective via feedback linearization.arXiv preprint arXiv:2509.24056, 2025
-
[30]
Vito Cerone, Sophie M Fosson, Simone Pirrera, and Diego Regruto. A new framework for constrained optimization via feedback control of lagrange multipliers.IEEE Transactions on Automatic Control, 2025
work page 2025
-
[31]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Shirong Li and Xinlong Feng. Dynamic weight strategy of physics-informed neural networks for the 2d navier–stokes equations.Entropy, 24(9):1254, 2022
work page 2022
-
[33]
Pratik Rathore, Weimu Lei, Zachary Frangella, Lu Lu, and Madeleine Udell. Challenges in training pinns: A loss landscape perspective.arXiv preprint arXiv:2402.01868, 2024. 11
-
[34]
Understanding the difficulty of solving cauchy problems with pinns
Tao Wang, Bo Zhao, Sicun Gao, and Rose Yu. Understanding the difficulty of solving cauchy problems with pinns. In6th Annual Learning for Dynamics & Control Conference, pages 453–465. PMLR, 2024
work page 2024
-
[35]
Tim De Ryck, Ameya D Jagtap, and Siddhartha Mishra. Error estimates for physics-informed neural networks approximating the navier–stokes equations.IMA Journal of Numerical Analysis, 44(1):83–119, 2024
work page 2024
-
[36]
On the convergence of adam and beyond
Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond. In International Conference on Learning Representations, 2018
work page 2018
-
[37]
Jorge Nocedal and Stephen J Wright.Numerical optimization. Springer, 2006
work page 2006
-
[38]
A review of constraint qualifications in finite-dimensional spaces.Siam Review, 15(3):639–654, 1973
David W Peterson. A review of constraint qualifications in finite-dimensional spaces.Siam Review, 15(3):639–654, 1973
work page 1973
-
[39]
Yuri Luchko. Initial-boundary-value problems for the generalized multi-term time-fractional diffusion equation.Journal of Mathematical Analysis and Applications, 374(2):538–548, 2011
work page 2011
-
[40]
Lie point symmetry data aug- mentation for neural PDE solvers
Johannes Brandstetter, Max Welling, and Daniel E Worrall. Lie point symmetry data aug- mentation for neural PDE solvers. InInternational Conference on Machine Learning, pages 2241–2256. PMLR, 2022
work page 2022
-
[41]
T. Akhound-Sadegh, L. Perreault-Levasseur, J. Brandstetter, M. Welling, and S. Ravanbakhsh. Lie point symmetry and physics-informed networks. InAdvances in Neural Information Processing Systems, volume 36, pages 42468–42481, 2023
work page 2023
- [42]
-
[43]
Utkarsh Utkarsh, Pengfei Cai, Alan Edelman, Rafael Gomez-Bombarelli, and Christopher Vin- cent Rackauckas. Physics-constrained flow matching: Sampling generative models with hard constraints.arXiv preprint arXiv:2506.04171, 2025. A Related Works: Constrained Optimization Methods for PINN, and comparison with AdamFLIP In this section, we review recent cons...
-
[44]
is a coordinatewise convex combination of g◦2 1 , . . . , g◦2 t . Hence, by Assumption 1, for every coordinatej, 0≤˜vt,j ≤G 2. The monotone second-moment estimate is defined by ¯vt = max elem {¯vt−1,˜vt}. Thus0≤¯v t,j ≤G 2 for allt, j. Since Dt = diag 1√¯vt−1 +δ , 30 we have, for every coordinatej, 1 G+δ ≤ 1√¯vt−1,j +δ ≤ 1 δ . This proves the uniform metr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.