Recognition: no theorem link
CUDAHercules: Benchmarking Hardware-Aware Expert-level CUDA Optimization for LLMs
Pith reviewed 2026-05-12 03:19 UTC · model grok-4.3
The pith
Large language models produce CUDA code that compiles and passes tests but rarely matches the performance of human-expert optimizations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CUDAHercules shows that leading language models can generate CUDA that compiles and satisfies semantic validators yet consistently underperforms human-expert SOTA systems because they fail to recover the targeted optimization techniques required for peak performance on recent GPU architectures.
What carries the argument
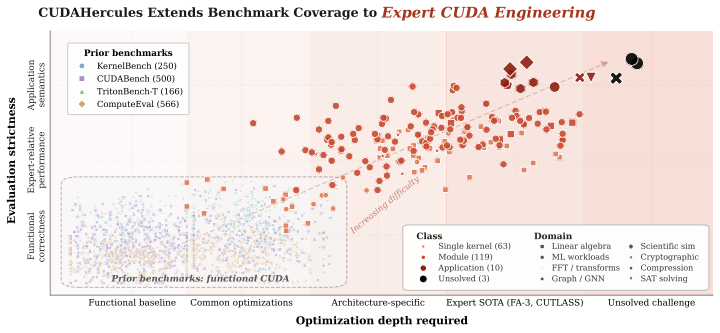
The CUDAHercules benchmark, which directly compares LLM-generated CUDA against end-to-end human-expert SOTA implementations across kernels to full applications using domain-specific semantic validators.
If this is right
- Application semantics reduce model success rates compared with isolated kernel tasks.
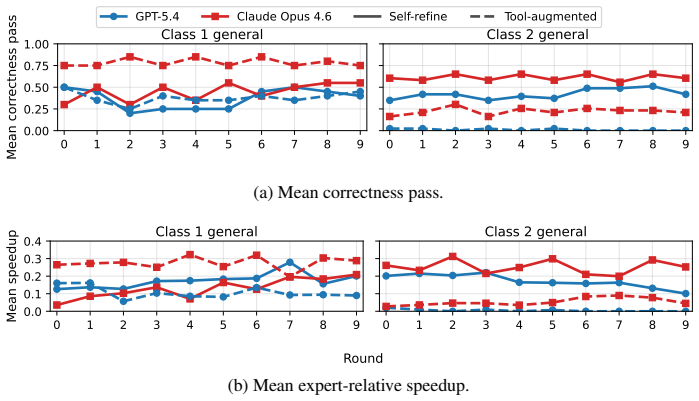
- Iterative or tool-augmented feedback improves functional correctness but often shifts outputs toward slower fallback implementations.
- Automated CUDA programming requires stronger hardware reasoning, better tool integration, and training objectives that link code to architecture-grounded performance.
- The benchmark includes unsolved challenge tasks to mark the current limits of model capability.
Where Pith is reading between the lines
- Hybrid workflows that pair LLMs with targeted human tuning may remain necessary for performance-critical CUDA sections until the gap narrows.
- Training data that includes optimization traces or hardware simulation feedback could help models internalize architecture-specific strategies.
- The benchmark structure could be adapted to measure AI progress in other low-level performance domains such as custom accelerator or FPGA programming.
Load-bearing premise
The assumption that human-expert SOTA systems represent the true optimal performance achievable and that the domain-specific semantic validators accurately confirm functional correctness without accepting suboptimal implementations.
What would settle it
An LLM that generates CUDA code achieving performance within a small margin of the human-expert SOTA baselines on the full CUDAHercules task set while passing all semantic validators.
Figures




read the original abstract
Large language models show promise for automated CUDA programming, however even the strongest coding models (e.g., Claude-Opus-4.6) may still fall short of expert-level, architecture-aware optimization. We introduce CUDAHercules, a benchmark that evaluates generated CUDA against end-to-end human-expert SOTA systems. It spans single kernels, module-level operators, full applications, and unsolved challenge tasks across Ampere, Hopper, and Blackwell GPUs, with end-to-end tasks gated by domain-specific semantic validators. Evaluating models such as Claude-Opus-4.6 and GPT-5.4 shows a large gap between runnable CUDA and expert CUDA engineering: models often compile and pass tests, but rarely recover the optimization strategies needed to match expert performance. Application semantics further reduce success, and iterative or tool-augmented feedback can improve correctness while drifting toward slow fallback implementations. These results show that automated CUDA programming remains far from fully solved and requires stronger hardware reasoning, better tool use, and training objectives that connect code understanding to hardware architecture-grounded intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CUDAHercules, a benchmark suite spanning single kernels, module-level operators, full applications, and unsolved challenges on Ampere/Hopper/Blackwell GPUs. It evaluates frontier LLMs (Claude-Opus-4.6, GPT-5.4) by comparing generated CUDA against end-to-end human-expert SOTA systems, with tasks gated by domain-specific semantic validators. The central finding is that models often produce code that compiles and passes validators but rarely recovers the hardware-aware optimizations needed to match expert performance; iterative/tool-augmented feedback improves pass rates yet tends to converge on slower fallbacks.
Significance. If the benchmark's validity holds, the work supplies concrete, multi-level evidence that current LLMs lack the architecture-grounded reasoning required for expert CUDA optimization. This is a timely contribution to automated high-performance computing, as the inclusion of real GPU hardware, unsolved tasks, and end-to-end applications could help track progress toward hardware-aware code generation. The direct comparison to external expert systems is a methodological strength.
major comments (2)
- [Abstract] Abstract: The claim of a 'large gap between runnable CUDA and expert CUDA engineering' is load-bearing on the assertion that the cited human-expert SOTA systems represent near-optimal performance. No evidence is supplied (e.g., comparison against independently derived faster kernels, roofline analysis, or theoretical bounds) to confirm these baselines are not themselves suboptimal on the target GPUs, which would directly affect the measured gap size.
- [Abstract] Abstract / Evaluation: The domain-specific semantic validators are presented as ensuring functional correctness, yet the manuscript provides no description of their predicate coverage, false-negative rate, or whether they can accept correct but suboptimal implementations that satisfy the validators. This directly impacts whether 'pass tests' results can be interpreted as evidence of missing optimizations rather than validator limitations.
minor comments (2)
- [Abstract] The abstract would benefit from explicit mention of the primary performance metric (e.g., kernel throughput, end-to-end latency, or speedup relative to expert baseline) used to quantify the gap.
- Consider adding a summary table in the results section that reports pass rates and performance ratios broken down by task category (kernel vs. application) and model to facilitate direct comparison.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive report. The two major comments identify areas where the manuscript's claims can be strengthened with additional justification and description. We address each point below and commit to revisions that directly respond to the concerns without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of a 'large gap between runnable CUDA and expert CUDA engineering' is load-bearing on the assertion that the cited human-expert SOTA systems represent near-optimal performance. No evidence is supplied (e.g., comparison against independently derived faster kernels, roofline analysis, or theoretical bounds) to confirm these baselines are not themselves suboptimal on the target GPUs, which would directly affect the measured gap size.
Authors: We acknowledge that the original manuscript does not include explicit roofline analysis, theoretical bounds, or comparisons to independently derived kernels for the expert SOTA baselines. These baselines are drawn from published expert implementations in the literature that are accepted as state-of-the-art for the respective tasks and architectures. To address the concern, the revised manuscript will add a dedicated paragraph in the Evaluation section discussing the expert baselines' performance relative to hardware peak where such information is available in the literature, and will explicitly frame the reported gap as relative to these published expert levels rather than absolute optimality. This clarification will be added without requiring new experiments. revision: yes
-
Referee: [Abstract] Abstract / Evaluation: The domain-specific semantic validators are presented as ensuring functional correctness, yet the manuscript provides no description of their predicate coverage, false-negative rate, or whether they can accept correct but suboptimal implementations that satisfy the validators. This directly impacts whether 'pass tests' results can be interpreted as evidence of missing optimizations rather than validator limitations.
Authors: The referee is correct that the manuscript lacks a detailed description of the validators. The validators are designed to verify semantic equivalence to reference outputs and are intentionally performance-agnostic, which means they can (and do) accept correct but suboptimal implementations. In the revised manuscript we will expand the Evaluation section with: (1) a summary of the key predicates covered by each validator, (2) an explicit statement that the validators do not enforce optimality, and (3) a brief discussion of potential false-negative risks based on the validator design. This addition will make the separation between correctness and optimization results clearer. revision: yes
Circularity Check
No circularity: empirical benchmark with external comparisons
full rationale
This is an empirical benchmark paper that introduces CUDAHercules to measure LLM-generated CUDA code against independently developed human-expert SOTA systems on specific GPUs. The abstract and described structure contain no derivations, equations, fitted parameters, or self-referential claims that reduce any result to the paper's own inputs by construction. Performance gaps are reported via direct measurement and semantic validators; the central claim does not rely on a derivation chain, uniqueness theorem, or ansatz imported from the authors' prior work. The study is self-contained against external human baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human-expert SOTA CUDA implementations represent the optimal achievable performance for the evaluated tasks.
- domain assumption Domain-specific semantic validators correctly determine functional equivalence for end-to-end tasks.
invented entities (1)
-
CUDAHercules benchmark suite
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Kevin: Multi-turn rl for generating cuda kernels, 2025.URL https://arxiv
Carlo Baronio, Pietro Marsella, Ben Pan, Simon Guo, and Silas Alberti. Kevin: Multi-turn rl for generating cuda kernels, 2025. URLhttps://arxiv.org/abs/2507.11948
-
[3]
Bringmann, John Tran, Wei Liu, Fung Xie, Michael Lightstone, and Humphrey Shi
Terry Chen, Zhifan Ye, Bing Xu, Zihao Ye, Timmy Liu, Ali Hassani, Tianqi Chen, Andrew Kerr, Haicheng Wu, Yang Xu, Yu-Jung Chen, Hanfeng Chen, Aditya Kane, Ronny Krashinsky, Ming-Yu Liu, Vinod Grover, Luis Ceze, Roger Bringmann, John Tran, Wei Liu, Fung Xie, Michael Lightstone, and Humphrey Shi. Avo: Agentic variation operators for autonomous evolutionary ...
-
[4]
Weinan Dai, Hanlin Wu, Qiying Yu, Huan ang Gao, Jiahao Li, Chengquan Jiang, Weiqiang Lou, Yufan Song, Hongli Yu, Jiaze Chen, Wei-Ying Ma, Ya-Qin Zhang, Jingjing Liu, Mingxuan Wang, Xin Liu, and Hao Zhou. Cuda agent: Large-scale agentic rl for high-performance cuda kernel generation, 2026. URLhttps://arxiv.org/abs/2602.24286
-
[5]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning, 2023. URLhttps://arxiv.org/abs/2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness, 2022. URL https://arxiv.org/ abs/2205.14135
work page internal anchor Pith review arXiv 2022
-
[7]
Gpu lossy compression for hpc can be versatile and ultra-fast
Yafan Huang, Sheng Di, Guanpeng Li, and Franck Cappello. Gpu lossy compression for hpc can be versatile and ultra-fast. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–20, New York, USA, 2025. Association for Computing Machinery. ISBN 9798400714665. doi: 10.1145/3712285.3759817. URL h...
- [8]
-
[9]
Tritonbench: Benchmarking large language model capabilities for generating triton operators
Jianwei Li, Shilin Li, Zhen Gao, Qian Shi, Yufei Li, Zhen Wang, Jiawei Huang, Haojie Wang, Jiayi Wang, Xinyu Han, et al. Tritonbench: Benchmarking large language model capabilities for generating triton operators. InFindings of the Association for Computational Linguistics: ACL 2025, pages 23053–23066, 2025
work page 2025
-
[10]
Shiyang Li, Ruiqi Tang, Jingyu Zhu, Ziyi Zhao, Xiaoli Gong, Wenwen Wang, Jin Zhang, and Pen-Chung Yew. Liberator: a data reuse framework for out-of-memory graph computing on gpus.IEEE Transactions on Parallel and Distributed Systems, 34(6):1954–1967, 2023. doi: 10.1109/TPDS.2023.3268662. 10
-
[11]
Shiyang Li, Zijian Zhang, Winson Chen, Yuebo Luo, Mingyi Hong, and Caiwen Ding. Stitchcuda: An automated multi-agents end-to-end gpu programing framework with rubric- based agentic reinforcement learning, 2026. URL https://arxiv.org/abs/2603. 02637
work page 2026
- [12]
-
[13]
Computeeval: Evaluating large language models for cuda code generation
NVIDIA. Computeeval: Evaluating large language models for cuda code generation. GitHub repository, 2025. URLhttps://github.com/NVIDIA/compute-eval
work page 2025
-
[14]
NVIDIA. Cutlass. GitHub repository, 2026. URL https://github.com/NVIDIA/ cutlass
work page 2026
- [15]
-
[16]
Muhammad Osama, Anton Wijs, and Armin Biere. Certified sat solving with gpu accelerated inprocessing.F ormal Methods in System Design, 62(1):79–118, 2024
work page 2024
-
[17]
Introducing gpt-5.4.https://openai.com/index/introducing-gpt-5-4/, 2026a
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelbench: Can llms write efficient gpu kernels?, 2025. URL https: //arxiv.org/abs/2502.10517
-
[18]
Ajay Panyala, Niri Govind, Karol Kowalski, Nicholas Bauman, Bo Peng, Himadri Pathak, Erdal Mutlu, Daniel Mejia Rodriguez, Sotiris Xantheas, and Sriram Krishnamoorthy. Ex- achem/exachem. [Computer Software]https://doi.org/10.11578/dc.20230628. 1, jun 2023. URLhttps://doi.org/10.11578/dc.20230628.1
-
[19]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
work page 2026
-
[20]
Flashattention-3: Fast and accurate attention with asynchrony and low-precision, 2024
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision, 2024. URL https://arxiv.org/abs/2407.08608
-
[21]
LangChain Team. LangChain, 2026. URL https://github.com/langchain-ai/ langchain
work page 2026
-
[22]
ThunderKittens Authors. Thunderkittens. GitHub repository, 2026. URL https://github. com/HazyResearch/ThunderKittens
work page 2026
-
[23]
Yuke Wang, Boyuan Feng, Zheng Wang, Tong Geng, Ang Li, Kevin Barker, and Yufei Ding. Mgg: Accelerating graph neural networks with fine-grained intra-kernel communication- computation pipelining on multi-gpu platforms. InUSENIX Symposium on Operating Systems Design and Implementation (OSDI’21), 2023
work page 2023
-
[24]
Tc-gnn: Accelerating sparse graph neural network computation via dense tensor core on gpus
Yuke Wang, Boyuan Feng, Zheng Wang, Guyue Huang, and Yufei Ding. Tc-gnn: Accelerating sparse graph neural network computation via dense tensor core on gpus. InUSENIX Annual Technical Conference, 2023
work page 2023
-
[25]
Ke Xu, Hekai Bu, Shuning Pan, Eric Lindgren, Yongchao Wu, Yong Wang, Jiahui Liu, Keke Song, Bin Xu, Yifan Li, Tobias Hainer, Lucas Svensson, Julia Wiktor, Rui Zhao, Hongfu Huang, Cheng Qian, Shuo Zhang, Zezhu Zeng, Bohan Zhang, Benrui Tang, Yang Xiao, Zihan Yan, Jiuyang Shi, Zhixin Liang, Junjie Wang, Ting Liang, Shuo Cao, Yanzhou Wang, Penghua Ying, Nan ...
-
[26]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, and Luis Ceze. Flashinfer: Efficient and customizable attention engine for llm inference serving, 2025. URL https://arxiv.org/ abs/2501.01005
-
[27]
Flashattention-4: Algorithm and kernel pipelining co-design for asymmetric hardware scaling,
Ted Zadouri, Markus Hoehnerbach, Jay Shah, Timmy Liu, Vijay Thakkar, and Tri Dao. Flashattention-4: Algorithm and kernel pipelining co-design for asymmetric hardware scaling,
- [28]
-
[29]
Zijian Zhang, Rong Wang, Shiyang Li, Yuebo Luo, Mingyi Hong, and Caiwen Ding. Cudaforge: An agent framework with hardware feedback for cuda kernel optimization, 2025. URL https: //arxiv.org/abs/2511.01884
-
[30]
Cudabench: Benchmarking llms for text-to-cuda generation.arXiv preprint arXiv:2603.02236, 2026
Jiace Zhu, Wentao Chen, Qi Fan, Zhixing Ren, Junying Wu, Xing Zhe Chai, Chotiwit Run- grueangwutthinon, Yehan Ma, and An Zou. Cudabench: Benchmarking llms for text-to-cuda generation, 2026. URLhttps://arxiv.org/abs/2603.02236. 12 A Task Catalog This appendix provides a detailed description of theCUDAHerculestask set. For each class, we describe the evalua...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.