Recognition: no theorem link
Online UAV Trajectory Planning Under QoS Constraints to Mobile Users in Urban Environments
Pith reviewed 2026-05-12 01:00 UTC · model grok-4.3
The pith
Reinforcement learning enables a UAV to plan trajectories in real time while satisfying QoS constraints for mobile users in urban settings with fronthaul limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that an online RL-based method can update the UAV position each time slot while jointly allocating QoS-aware bandwidth and power under total constraints to maximize throughput, all while ensuring the instantaneous data rate meets minimum thresholds for each user and respecting the fronthaul capacity from the HAP.
What carries the argument
An online reinforcement learning agent that observes user positions and channel states to decide UAV movement, bandwidth splitting, and power allocation at each time slot.
Load-bearing premise
The models of urban blockages and user mobility patterns in the simulations are representative enough that the RL policy will work effectively in actual deployments.
What would settle it
Comparing the data rates and constraint satisfaction in a real urban testbed with moving users against the simulation predictions for the same RL policy.
Figures


read the original abstract
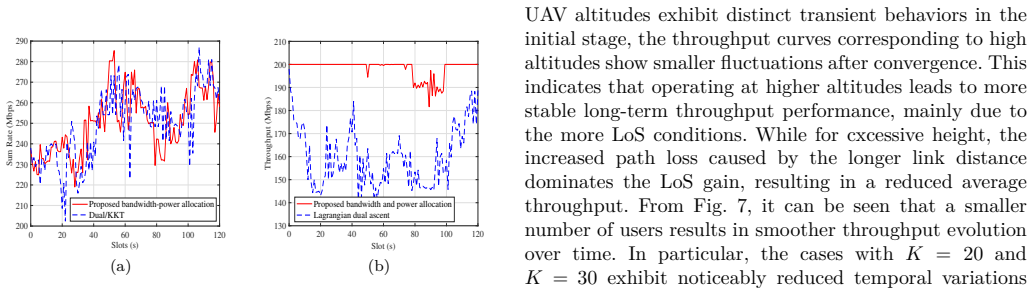
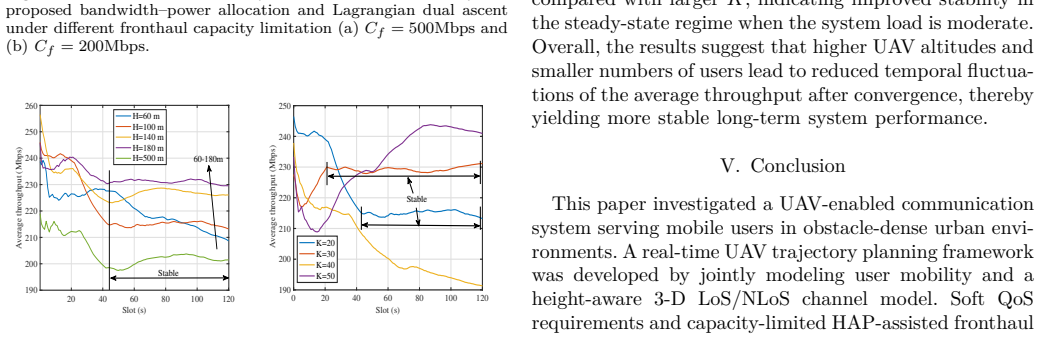
This paper studies real-time trajectory planning and radio resource allocation for a single uncrewed aerial vehicle (UAV) serving multiple mobile ground users in an urban environment. The downlink system considers heterogeneous user mobility, where independent users and group users coexist and interact. To ensure reliable communication, quality-of-service (QoS) constraints are imposed by requiring the instantaneous data rate of each user to satisfy a minimum threshold whenever feasible. A capacity limited high-altitude platform (HAP)-assisted wireless fronthaul is further considered to capture practical network-side transmission limitations. Under these constraints, the UAV updates its position at each time slot, while QoS-aware bandwidth and power are jointly allocated under total bandwidth and transmit power constraints to maximize system throughput. Due to user mobility and urban blockages, the resulting problem is highly nonconvex and time-varying. An online reinforcement learning (RL) based approach is adopted for real-time UAV trajectory optimization. Simulation results show that the proposed method satisfies the QoS, fronthaul, and radio resource constraints and achieves a balanced trade-off between throughput and user fairness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies real-time UAV trajectory planning and joint radio resource allocation for a single UAV serving heterogeneous mobile ground users (independent and group users) in urban environments. It imposes instantaneous QoS rate thresholds, capacity-limited HAP-assisted fronthaul, and total bandwidth/power constraints, formulates the resulting nonconvex time-varying problem, and solves it via an online RL policy that updates UAV position and allocates resources to maximize throughput while balancing fairness. Simulations are claimed to demonstrate that the policy satisfies all constraints and achieves the desired trade-off.
Significance. If the simulation results hold, the work provides a practical online RL solution for a timely problem in UAV-assisted networks under realistic constraints and heterogeneous mobility. The integration of fronthaul limits with QoS-aware allocation and the use of RL to handle dynamics are strengths; simulation validation of constraint satisfaction offers initial evidence of feasibility for real-time deployment.
major comments (2)
- Simulation results (as summarized in abstract): the central claim that the RL policy satisfies QoS, fronthaul, and radio resource constraints while balancing throughput and fairness rests on a specific urban blockage model and heterogeneous mobility traces; no sensitivity analysis, alternative traces, or out-of-distribution testing is reported, which is load-bearing because deviations in real blockage statistics or mobility can cause QoS violations even if the policy succeeds in the training simulator.
- RL formulation (abstract and method description): the state/action spaces, reward design, and mechanism for enforcing instantaneous QoS/fronthaul constraints within the online RL agent are not detailed enough to evaluate how the nonconvex time-varying problem is mapped to a learnable policy, undermining assessment of why the approach succeeds where conventional optimization would fail.
minor comments (1)
- Abstract: could include one or two key quantitative metrics (e.g., achieved rate margins or fairness index values) to make the simulation claims more concrete rather than qualitative.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable comments on our manuscript. We appreciate the recognition of the practical relevance of our RL-based approach for UAV trajectory planning under realistic constraints. Below, we provide point-by-point responses to the major comments and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: Simulation results (as summarized in abstract): the central claim that the RL policy satisfies QoS, fronthaul, and radio resource constraints while balancing throughput and fairness rests on a specific urban blockage model and heterogeneous mobility traces; no sensitivity analysis, alternative traces, or out-of-distribution testing is reported, which is load-bearing because deviations in real blockage statistics or mobility can cause QoS violations even if the policy succeeds in the training simulator.
Authors: We agree with the referee that the lack of sensitivity analysis is a limitation in assessing the robustness of the results. Although the current simulations are based on a widely used urban blockage model and heterogeneous mobility patterns, we will revise the manuscript to include sensitivity analyses with respect to different blockage statistics and alternative mobility traces. This will help demonstrate the policy's ability to maintain constraint satisfaction under varied conditions. revision: yes
-
Referee: RL formulation (abstract and method description): the state/action spaces, reward design, and mechanism for enforcing instantaneous QoS/fronthaul constraints within the online RL agent are not detailed enough to evaluate how the nonconvex time-varying problem is mapped to a learnable policy, undermining assessment of why the approach succeeds where conventional optimization would fail.
Authors: We agree that additional details on the RL formulation would enhance the manuscript. In the revised version, we will provide a more comprehensive description of the state and action spaces, the reward design, and the specific mechanisms used to enforce the QoS and fronthaul constraints within the RL agent. This will include clarifying how the online policy addresses the nonconvex and time-varying nature of the problem, thereby better illustrating its advantages over traditional optimization techniques. revision: yes
Circularity Check
No significant circularity in RL formulation or simulation validation
full rationale
The paper formulates a nonconvex, time-varying optimization problem for UAV trajectory planning and joint bandwidth/power allocation under QoS rate thresholds, fronthaul capacity, and total resource constraints. It then casts the problem as an MDP and applies an online RL agent for real-time decisions. Validation consists of independent simulations under a specified urban blockage and heterogeneous mobility model, showing constraint satisfaction and throughput-fairness trade-offs. No derivation step reduces by construction to its own inputs, no fitted parameters are relabeled as predictions, and no load-bearing uniqueness claims rely on self-citations. The RL policy is learned from the environment dynamics rather than being tautological with the objective.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The optimization problem is highly nonconvex and time-varying due to user mobility and urban blockages.
Reference graph
Works this paper leans on
-
[1]
Q. Hou, Y. Cai, Q. Hu, M. Lee, and G. Yu, “Joint resource allocation and trajectory design for multi-uav systems with moving users: Pointer network and unfolding,” IEEE Trans. Wireless Commun., vol. 22, no. 5, pp. 3310–3323, 2022
work page 2022
-
[2]
Z. Yang, S. Bi, and Y.-J. A. Zhang, “Dynamic offloading and trajectory control for uav-enabled mobile edge computing system with energy harvesting devices,” IEEE Trans. Wireless Commun., vol. 21, no. 12, pp. 10 515–10 528, 2022
work page 2022
-
[3]
Path planning for the dynamic uav-aided wireless systems using monte carlo tree search,
Y. Qian, K. Sheng, C. Ma, J. Li, M. Ding, and M. Hassan, “Path planning for the dynamic uav-aided wireless systems using monte carlo tree search,” IEEE Trans. Veh. Technol., vol. 71, no. 6, pp. 6716–6721, 2022
work page 2022
-
[4]
On energy consumption of airship-based flying base stations serving mobile users,
Z. Becvar, M. Nikooroo, and P. Mach, “On energy consumption of airship-based flying base stations serving mobile users,” IEEE Trans. Commun., vol. 70, no. 10, pp. 7006–7022, 2022
work page 2022
-
[5]
X. Yuan, Y. Hu, J. Zhang, and A. Schmeink, “Joint user schedul- ing and uav trajectory design on completion time minimization for uav-aided data collection,” IEEE Trans. Wireless Commun., vol. 22, no. 6, pp. 3884–3898, 2022
work page 2022
-
[6]
Completion time optimiza- tion in uav-relaying-assisted mec networks with moving users,
Q. Qi, T. Shi, K. Qin, and G. Luo, “Completion time optimiza- tion in uav-relaying-assisted mec networks with moving users,” IEEE Trans. Consum. Electron., vol. 70, no. 1, pp. 1246–1258, 2023
work page 2023
-
[7]
F. Song, H. Xing, X. Wang, S. Luo, P. Dai, Z. Xiao, and B. Zhao, “Evolutionary multi-objective reinforcement learning based trajectory control and task offloading in uav-assisted mobile edge computing,” IEEE Trans. Mob. Comput., vol. 22, no. 12, pp. 7387–7405, 2022
work page 2022
-
[8]
Y. Wei, Z. Wan, Y. Xiao, S. Leng, K. Wang, and K. Yang, “Joint split offloading and trajectory scheduling for uav-enabled mobile edge computing in iot network,” IEEE Trans. Network Sci. Eng., 2024
work page 2024
-
[9]
Optimal uav trajectory design for moving users in integrated sensing and communications networks,
Y. Li, X. Yuan, Y. Hu, J. Yang, and A. Schmeink, “Optimal uav trajectory design for moving users in integrated sensing and communications networks,” IEEE Trans. Intell. Transp. Syst., vol. 24, no. 12, pp. 15 113–15 130, 2023
work page 2023
-
[10]
User scheduling and trajectory optimization for energy-efficient irs- uav networks with swipt,
S. Zargari, A. Hakimi, C. Tellambura, and S. Herath, “User scheduling and trajectory optimization for energy-efficient irs- uav networks with swipt,” IEEE Trans. Veh. Technol., vol. 72, no. 2, pp. 1815–1830, 2022
work page 2022
-
[11]
X. Yan, X. Fang, C. Deng, and X. Wang, “Joint optimization of resource allocation and trajectory control for mobile group users in fixed-wing uav-enabled wireless network,” IEEE Trans. Wireless Commun., vol. 23, no. 2, pp. 1608–1621, 2023
work page 2023
-
[12]
Collaborative positioning optimization for multiple moving users in uav-enabled isac,
Y. Hu, X. Zhuo, Z. Meng, W. Wu, W. Lu, L. Tang, F. Qu, and Z. Bu, “Collaborative positioning optimization for multiple moving users in uav-enabled isac,” IEEE Trans. Cognit. Com- mun. Networking, 2025
work page 2025
-
[13]
A comparative study of mobility models in the performance evaluation of mcl,
F. Geng and S. Xue, “A comparative study of mobility models in the performance evaluation of mcl,” in 2013 22nd Wireless and Optical Communication Conference, 2013, pp. 288–292
work page 2013
-
[14]
Learning in constrained markov decision processes,
R. Singh, A. Gupta, and N. B. Shroff, “Learning in constrained markov decision processes,” IEEE Trans. Control Network Syst., vol. 10, no. 1, pp. 441–453, 2023
work page 2023
-
[15]
X. Yan, X. Fang, C. Deng, and X. Wang, “Joint optimization of resource allocation and trajectory control for mobile group users in fixed-wing uav-enabled wireless network,” IEEE Trans. Wireless Commun., vol. 23, no. 2, pp. 1608–1621, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.