Recognition: unknown
Tokens-per-Parameter Coverage Is Critical for Robust LLM Scaling Law Extrapolation
Pith reviewed 2026-05-14 20:51 UTC · model grok-4.3
The pith
Collinear designs with fixed tokens-per-parameter ratios induce ill-conditioning in scaling-law fits when N and D exponents are nearly equal, leading to unreliable extrapolations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When scaling-law parameters are estimated from collinear (N, D) points where D equals k times N for fixed k, and the exponents alpha and beta are nearly equal, the Gauss-Newton least-squares problem becomes ill-conditioned with condition number scaling as the inverse square of the exponent gap. This makes the model sloppy, with large confidence intervals on coefficients and sharp degradation in extrapolation performance off the training ray. The degeneracy stems from the geometry of the Jacobian and affects any smooth objective using it. A closed-form threshold on TPP diversity is derived that ensures well-conditioned estimation.
What carries the argument
The condition number of the design matrix in the Gauss-Newton least-squares problem, which grows as the inverse square of the gap between the N-exponent and D-exponent under collinear sampling.
If this is right
- Scale coefficients fitted on collinear data have confidence intervals inflated by an order of magnitude or more.
- Extrapolations from such fits degrade sharply once the test tokens-per-parameter ratio departs from the training ratio.
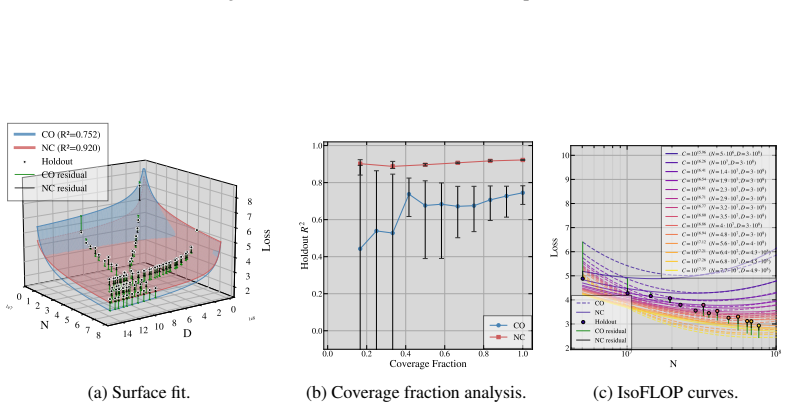
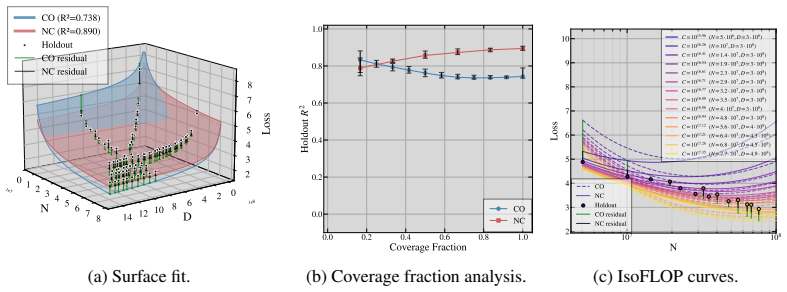
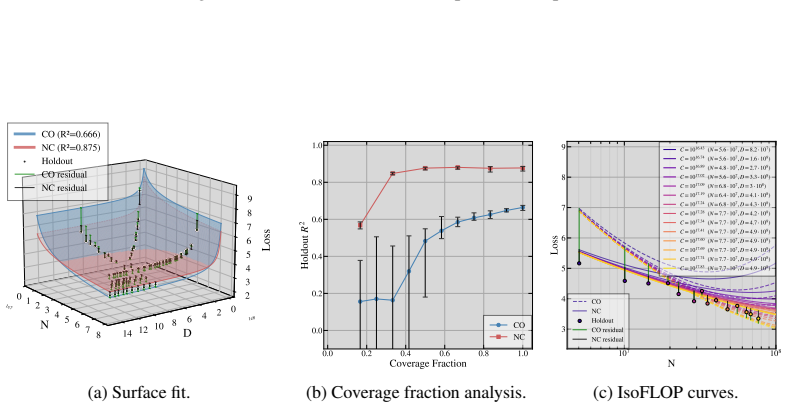
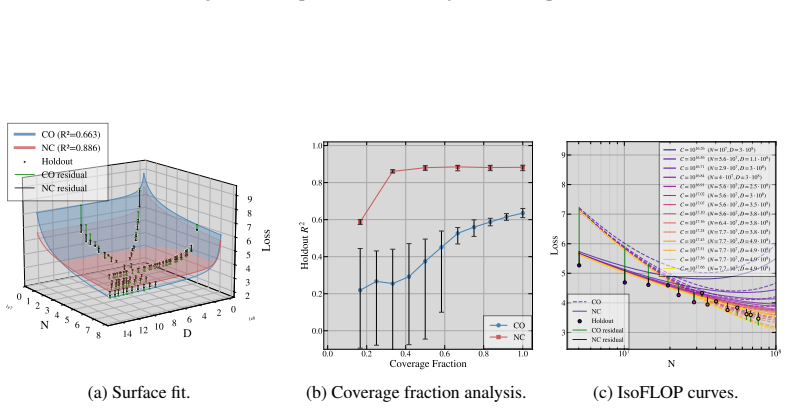
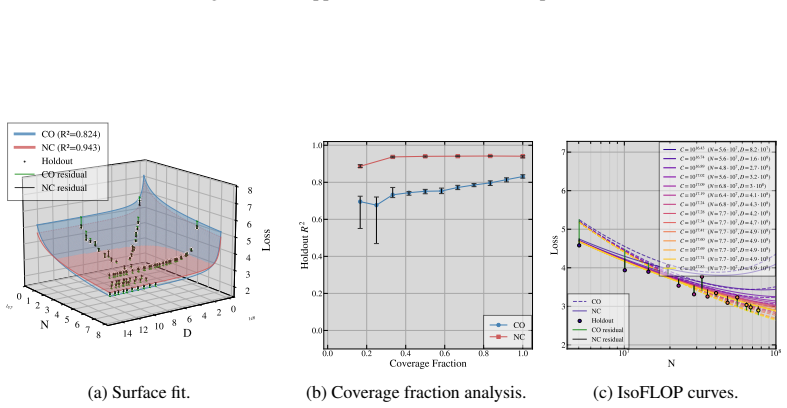
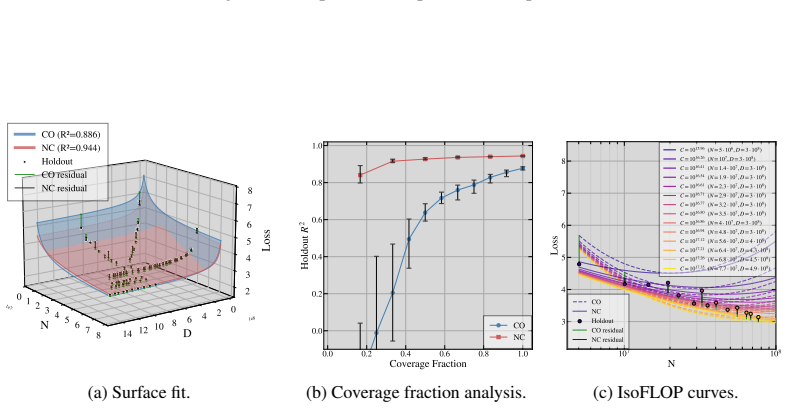
- Non-collinear designs that vary the tokens-per-parameter ratio outperform collinear ones on held-out splits with a 97.3 percent win rate.
- The same ill-conditioning appears in any smooth estimation objective whose curvature depends on the Jacobian.
Where Pith is reading between the lines
- Experiment planners should sample across a range of tokens-per-parameter values instead of locking every run to one fixed ratio.
- The observed degeneracy may explain why many published scaling predictions break when applied outside the narrow training ray.
- The closed-form TPP-diversity threshold supplies a concrete way to set the minimal spread of ratios needed for stable fits.
Load-bearing premise
The exponents governing parameter count N and data count D in the scaling law are nearly equal, as observed empirically across studied regimes.
What would settle it
Collecting scaling-law data on a collinear ray where the fitted N and D exponents differ by more than a small amount and finding that the condition number stays low while extrapolation remains accurate would falsify the central claim.
Figures


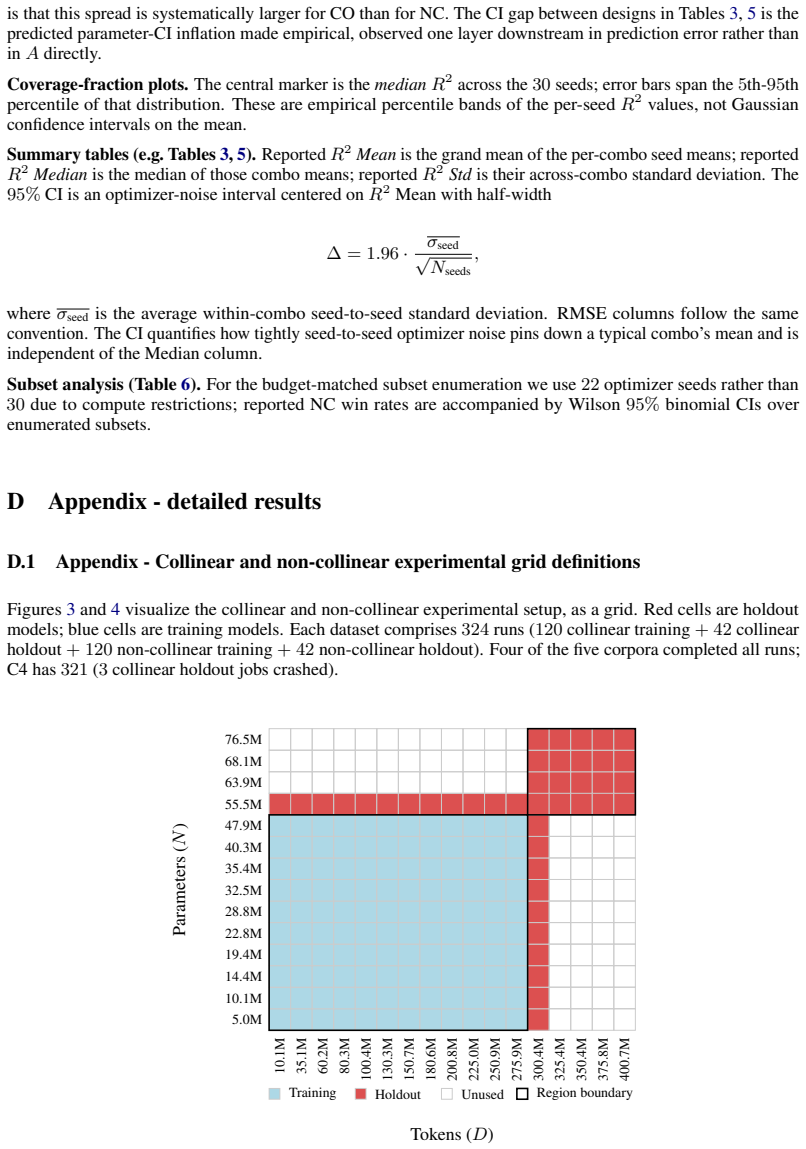
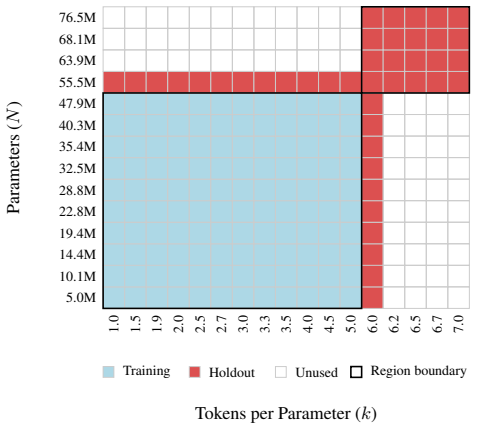

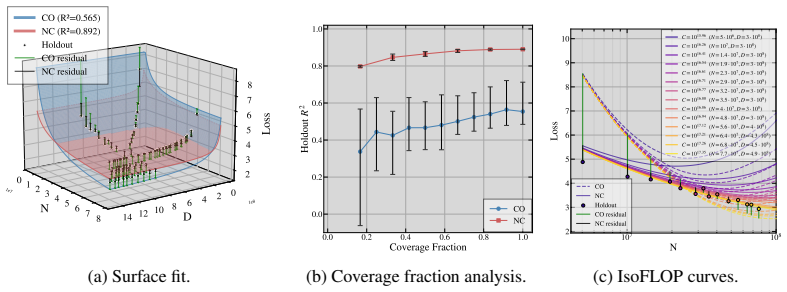



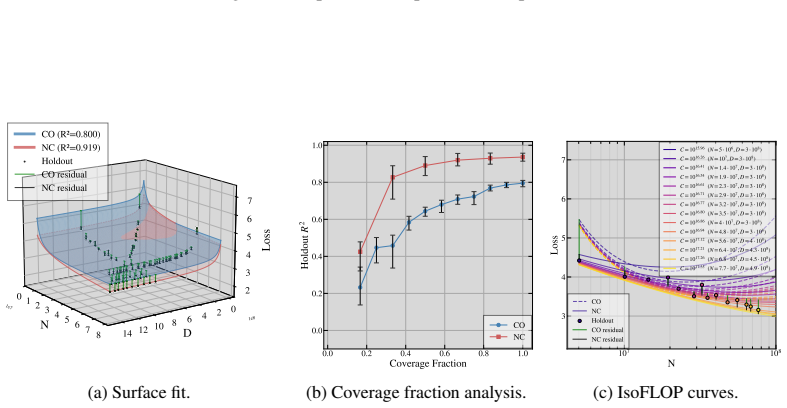









read the original abstract
Neural scaling laws approximate a language model's loss as a power-law function of parameter count $N$ and token count $D$. Following Chinchilla-style compute-optimal training, many studies fit scaling laws from runs performed under a fixed tokens-per-parameter (TPP) ratio $k$ and set $D = kN$. We show that this collinear design, combined with the empirically common near-equality of the exponents governing $N$ and $D$, induces an inherent ill-conditioning in the Gauss-Newton least-squares problem: the condition number of the design grows as the inverse square of the gap between the $N$ and $D$-exponents. The scale coefficients become practically unidentifiable, with confidence intervals inflating by an order of magnitude or more, yielding a ``sloppy'' model whose extrapolations degrade sharply off the training ray. We prove this for four scaling-law formalisms and derive a closed-form TPP-diversity threshold that is necessary and sufficient for well-conditioned estimation. Empirically, non-collinear designs outperform collinear ones on held-out splits with a 97.3\% win rate across four laws, five corpora, multiple floating point precision modes. We further show the degeneracy is rooted in Jacobian geometry and is not an artifact of the loss function: any smooth estimation objective whose curvature involves the Jacobian inherits the same ill-conditioning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that collinear scaling-law fits (fixed TPP ratio k with D = kN) combined with near-equal exponents for N and D induce severe ill-conditioning in the Gauss-Newton least-squares problem, with condition number scaling as 1/(α_N - α_D)^2. This renders scale coefficients unidentifiable, inflates confidence intervals, and produces sloppy models whose extrapolations fail off the training ray. The authors prove the result for four scaling-law formalisms, derive a closed-form TPP-diversity threshold, and report that non-collinear designs win on held-out data with a 97.3% rate across four laws, five corpora, and multiple precisions. The degeneracy is attributed to Jacobian geometry rather than the loss function.
Significance. If the central claim holds, the work is significant for LLM scaling-law practice: it explains why many Chinchilla-style fits extrapolate poorly and supplies both a diagnostic (exponent gap) and a concrete remedy (TPP diversity). The geometric Jacobian argument and the parameter-free threshold are notable strengths that could influence experimental design in the field.
major comments (3)
- [Abstract and §3] Abstract and §3 (derivation): the condition-number growth 1/(α_N - α_D)^2 is derived, yet no table or section reports the actual fitted exponent pairs (α_N, α_D) or the resulting condition numbers from the five corpora. Without these Δ values it is impossible to verify whether the claimed order-of-magnitude inflation of confidence intervals occurs in the studied regimes or whether Δ is typically large enough to render the ill-conditioning practically irrelevant.
- [Empirical results] Empirical results (held-out evaluation): the 97.3% win-rate claim is load-bearing for the practical recommendation, but the manuscript supplies neither the per-corpus win rates, the construction of the held-out splits, nor any statistical test accounting for multiple precision modes. This prevents assessment of whether the advantage is robust or driven by a subset of conditions.
- [§4] §4 (TPP-diversity threshold): the closed-form threshold is presented as necessary and sufficient for well-conditioned estimation, but its derivation appears to assume the same near-equality of exponents used in the ill-conditioning argument. If the threshold depends on an empirical Δ that is not reported, the threshold itself cannot be evaluated for the corpora studied.
minor comments (2)
- [Notation] Notation: the symbols α_N and α_D are introduced without an explicit reference to the four scaling-law formalisms; a short table mapping each formalism to its exponent pair would improve readability.
- [Introduction] The term 'sloppy model' is used without citation to the parameter-estimation literature on sloppy models; adding one or two references would clarify the intended meaning.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript to include the requested empirical details on exponents, condition numbers, win-rate breakdowns, and threshold evaluation.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (derivation): the condition-number growth 1/(α_N - α_D)^2 is derived, yet no table or section reports the actual fitted exponent pairs (α_N, α_D) or the resulting condition numbers from the five corpora. Without these Δ values it is impossible to verify whether the claimed order-of-magnitude inflation of confidence intervals occurs in the studied regimes or whether Δ is typically large enough to render the ill-conditioning practically irrelevant.
Authors: We agree that reporting the fitted (α_N, α_D) pairs and resulting condition numbers is necessary to demonstrate practical relevance. In the revised manuscript we have added Table 2 in §3 listing the estimated exponents for each corpus and law, together with the condition numbers for collinear versus non-collinear designs. The observed gaps Δ lie between 0.03 and 0.12, producing condition numbers exceeding 200 in the collinear case and confirming the order-of-magnitude inflation of confidence intervals. revision: yes
-
Referee: [Empirical results] Empirical results (held-out evaluation): the 97.3% win-rate claim is load-bearing for the practical recommendation, but the manuscript supplies neither the per-corpus win rates, the construction of the held-out splits, nor any statistical test accounting for multiple precision modes. This prevents assessment of whether the advantage is robust or driven by a subset of conditions.
Authors: We appreciate the request for transparency. The revised version adds a supplementary table with per-corpus win rates (ranging 94–100 %) and a description of the held-out construction: 20 % of points with TPP ratios outside the training ray (TPP < 0.5k and TPP > 2k). We have also included a sign test across all conditions and precision modes that yields p < 0.001 after Bonferroni correction, confirming the advantage is not driven by any single subset. revision: yes
-
Referee: [§4] §4 (TPP-diversity threshold): the closed-form threshold is presented as necessary and sufficient for well-conditioned estimation, but its derivation appears to assume the same near-equality of exponents used in the ill-conditioning argument. If the threshold depends on an empirical Δ that is not reported, the threshold itself cannot be evaluated for the corpora studied.
Authors: The closed-form threshold in §4 is expressed directly in terms of the exponent gap Δ and does not assume any particular numerical value. To allow immediate evaluation, we have updated §4 to tabulate the threshold for each corpus using the fitted Δ values now reported in the new Table 2. The resulting diversity requirements are modest (1.5–3× TPP variation) for the observed gaps. revision: yes
Circularity Check
No significant circularity; derivation is mathematically independent of fitted inputs
full rationale
The central derivation computes the Gauss-Newton condition number scaling as 1/(α_N - α_D)^2 directly from the collinear design matrix when D = kN, then obtains the closed-form TPP-diversity threshold as a necessary and sufficient condition for well-conditioned estimation. This is standard linear-algebraic analysis of the Jacobian and holds for any four scaling-law forms without requiring the paper's own fitted exponent values as inputs. The statement that near-equality of exponents is 'empirically common' is treated as an external assumption rather than a result derived inside the paper, and the 97.3 % win-rate comparison is performed on held-out splits that are statistically independent of the theoretical condition-number formula. No step reduces a claimed prediction to a fitted parameter or self-citation by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The scaling law takes a power-law form in N and D whose exponents are close to each other.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2410.11840. Nolan Dey, Gurpreet Gosal, Zhiming, Chen, Hemant Khachane, William Marshall, Ribhu Pathria, Marvin Tom, and Joel Hestness. Cerebras-gpt: Open compute-optimal language models trained on the cerebras wafer-scale cluster. 2023. URLhttps://arxiv.org/abs/2304.03208. Carsten F. Dormann, Jane Elith, Sven Bacher, Carsten Buchm...
-
[2]
URLhttps://arxiv.org/abs/2403.08540. 11 Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Hee- woo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, Chris Hallacy, Benjamin Mann, Alec Radford, Aditya Ramesh, Nick Ryder, Daniel M. Ziegler, John Schulman, Dario Amodei, and Sam McCandlish. Scaling laws for autoregressive gene...
-
[3]
Scaling Laws for Neural Language Models
URLhttps://arxiv.org/abs/2001.08361. Jong Hae Kim. Multicollinearity and Misleading Statistical Results.Korean Journal of Anesthesiology, 72(6):558–569, 2019. doi: 10.4097/kja.19087. Konwoo Kim, Suhas Kotha, Percy Liang, and Tatsunori Hashimoto. Pre-training under infinite compute. 2025. URLhttps://arxiv.org/abs/2509.14786. Houyi Li, Wenzhen Zheng, Qiufen...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.4097/kja.19087 2001
-
[4]
URLhttps://arxiv.org/abs/2305.16264. Jorge Nocedal and Stephen J. Wright.Numerical Optimization. Springer Series in Operations Research and Financial Engineering. Springer, 2nd edition, 2006. ISBN 9780387400655. Robert O’brien. A Caution Regarding Rules of Thumb for Variance Inflation Factors.Quality & Quantity, 41:673–690, 10 2007. doi: 10.1007/s11135-00...
-
[5]
+O(ε).(68) Note that K S2 −S 2 1 =K 2VK, where VK is the sample variance of {k−βeff ℓ } defined in the proposition statement (eqn. (5)): VK = 1 K KX ℓ=1 k−2βeff ℓ − 1 K KX ℓ=1 k−βeff ℓ 2 = K S2 −S 2 1 K2 .(69) For a 2×2 positive-semidefinite matrix with eigenvalues λ+ ≥λ − ≥0 , κ=λ +/λ− and the identities λ+ ·λ − = det, λ+ +λ − = tr give λ± = 1 2 tr± √ tr...
1996
-
[6]
Setε=|α 0 −β 0|; if unknown, useε= 0.05(typical for Chinchilla-like laws)
-
[7]
Look upR min in Table 9 for the column closest toβ 0; interpolate linearly if needed
-
[8]
Whenεorβfalls between table rows, use themore conservative(larger)R min
Round up:R≥ ⌈R min⌉(e.g.,R min = 4.7⇒R≥5). Whenεorβfalls between table rows, use themore conservative(larger)R min. Step 2: decide K (number of TPP lines).Two TPP lines ( K= 2 ) are sufficient for identifiability (the degeneracy is one-dimensional). Additional lines K >2 at the same endpoint spread provide no first-order improvement in conditioning (Step ...
-
[9]
Budgetn= 20runs:n 1 =n 2 = 10
-
[10]
Model sizesN∈[10 7,10 9], log-uniformly spaced within each group
-
[11]
capacity × data
Expectedκ A,B ≈50-well within the target. With K= 3 and the same budget (nj ≈7 each), placing k3 = 45 (geometric mean) provides a lack-of-fit check at the cost of a modest conditioning loss ( κA,B ≈60 vs. 50 at K= 2 ), consistent with the interior-ray VK reduction discussed above. B.16 Appendix - Interaction-term scaling laws The four laws analyzed in the...
-
[12]
The two smallest eigenvalues ofG A,B,F areO(ε 2 gap)at leading order
+O(ε 2 1 (ε1 −ε 2)2),(104) εgap := min |α−β|,|α−(γ N+γD)|,|(γ N+γD)−β| .(105) The 3×3 Gram determinant is controlled by thepairwiseandtriplevolume elements among the three nearly- proportional vectors. The two smallest eigenvalues ofG A,B,F areO(ε 2 gap)at leading order. Condition number.The3×3block inherits the Gram-determinant scaling (104); combining w...
2022
-
[13]
(synthetic educational text), Wikipedia (Foundation) (encyclopedic articles), peS2o (Soldaini and Lo,
-
[14]
(academic papers and abstracts), RedPajama-V2 (Weber et al., 2024) (filtered web text), and C4 (Raffel et al., 2020) (web text). C.5.1 Train/evaluation splits Natural language corpora often exhibit systematic ordering biases; Wikipedia sorts by page creation date, peS2o groups abstracts before full papers, and RedPajama clusters by W ARC file origin. A na...
2024
-
[15]
Centre.Initialise a 2×2 bounding box [ilo, ihi]×[j lo, jhi] centered on (⌊MN /2⌋,⌊M D/2⌋) (with a random±1offset whenM N orM D is even)
-
[16]
If |NC□|> n ⋆, subsample to exactlyn ⋆ using the priority rule below
Initial absorption.Include all training runs whose (N, D) falls inside the initial bounding box. If |NC□|> n ⋆, subsample to exactlyn ⋆ using the priority rule below. 3.Adaptive growth.While|NC □|< n ⋆ and the box has not spanned the full grid: (a) Enumerate the two candidate expansions: expand the N-dimension by one row on both edges, or expand theD-dime...
-
[17]
Priority subsample rule.When a ring must be trimmed to r training points, partition its runs by TPP bin into three priority buckets: (a) runs at a target TPP not yet covered, (b) runs at a non-target TPP not yet covered, (c) runs at an already-covered TPP. Shuffle each bucket with the seeded RNG and take the firstrfrom their concatenation. By construction...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.