Recognition: 2 theorem links
· Lean TheoremBeyond Static Bias: Adaptive Multi-Fidelity Bandits with Improving Proxies
Pith reviewed 2026-05-12 01:06 UTC · model grok-4.3
The pith
In multi-fidelity bandits with improving low-fidelity proxies, adaptive continuation replaces logarithmic high-fidelity sampling with bounded low-fidelity use for intermediate arms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove an instance-dependent regret bound showing that, for detected intermediate arms, adaptive continuation replaces logarithmic high-fidelity confirmation with bounded low-fidelity continuation.
What carries the argument
The selected-average mismatch bound, which turns dynamic low-fidelity observations into improvement-aware confidence bounds for the high-fidelity target and supports the bounded continuation rule.
If this is right
- For intermediate arms the total number of low-fidelity samples remains bounded rather than growing logarithmically with time.
- Cost-weighted regret improves when the proxy's improvement rate satisfies the mismatch condition.
- The same decision rule applies directly to LLM-as-a-judge evaluation tasks without requiring static bias assumptions.
Where Pith is reading between the lines
- If the mismatch bound can be empirically verified for a new proxy, practitioners can safely restrict high-fidelity queries to only the current top contenders.
- The approach extends to other improving surrogates such as neural-network simulators whose error decreases predictably with calibration data.
- Proxy designers could target calibration schedules that enlarge the region of arms eligible for bounded continuation.
Load-bearing premise
The low-fidelity source improves with repeated use in a way that can be captured by a selected-average mismatch bound allowing safe bounded continuation decisions instead of high-fidelity escalation.
What would settle it
An experiment or dataset in which low-fidelity mismatch fails to decrease with additional samples as required by the bound, forcing the algorithm to either incur unbounded regret or revert to full high-fidelity confirmation.
Figures









read the original abstract
As an extension of the classical multi-armed bandit problem, multi-fidelity multi-armed bandits (MF-MAB) enable individual arms to be evaluated using diverse feedback sources that vary in both cost and accuracy. Prior stochastic models typically assume fixed low-to-high fidelity discrepancies, whereas modern proxy sources, such as learning-based simulators and Large Language Models (LLMs), can be improved using additional calibration. We investigate adaptive MF-MAB with improving proxy sources, and focus on the canonical two-fidelity case in which the low-fidelity source becomes more informative with repeated use. To capture this dynamic, we introduce a selected-average mismatch bound that converts dynamic low-fidelity observations into improvement-aware confidence bounds for the high-fidelity target. We propose the Threshold-Based Adaptive Continuation Companion (TACC), an optimistic algorithm that uses a bounded continuation rule to decide when low-fidelity sampling remains cost-effective and when to escalate. We prove an instance-dependent regret bound showing that, for detected intermediate arms, adaptive continuation replaces logarithmic high-fidelity confirmation with bounded low-fidelity continuation. Experiments on synthetic bandits and an LLM-as-a-judge policy-evaluation task examine when continuation improves cost-weighted regret.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends multi-fidelity multi-armed bandits to the setting of improving low-fidelity proxies (e.g., calibrated simulators or LLMs). It introduces a selected-average mismatch bound that converts repeated low-fidelity observations into improvement-aware confidence intervals for the high-fidelity target. The Threshold-Based Adaptive Continuation Companion (TACC) algorithm uses an optimistic bounded-continuation rule to decide when low-fidelity sampling remains cost-effective. The central theoretical result is an instance-dependent regret bound showing that, for arms whose empirical gap falls in an intermediate regime, adaptive continuation replaces the usual logarithmic number of high-fidelity pulls with a finite number of low-fidelity samples. Experiments on synthetic instances and an LLM-as-a-judge policy-evaluation task illustrate the resulting cost-weighted regret improvement.
Significance. If the regret analysis holds, the work provides a principled relaxation of the static-bias assumption that has dominated prior MF-MAB literature. The instance-dependent bound and the explicit conversion of proxy improvement into a continuation threshold are technically substantive and directly address practical settings in which low-fidelity sources can be refined. The inclusion of both synthetic verification and a real LLM task strengthens the claim that the mechanism yields measurable savings when high-fidelity evaluations are expensive.
minor comments (3)
- §3 (definition of the selected-average mismatch bound): a short paragraph clarifying how the bound is estimated from data and whether it requires any tuning parameter would improve readability for readers unfamiliar with the construction.
- Algorithm 1 (TACC pseudocode): the continuation threshold is referenced but not given an explicit line-numbered definition; adding a boxed equation for the threshold would eliminate ambiguity when readers compare the algorithm to the regret proof.
- Experiments section: the LLM-as-a-judge task description would benefit from one additional sentence stating how many low-fidelity samples are needed before the mismatch bound stabilizes in the reported runs.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on adaptive multi-fidelity bandits with improving proxies, the recognition of the selected-average mismatch bound and TACC algorithm, and the recommendation for minor revision. We appreciate the assessment that the instance-dependent regret result and LLM experiment strengthen the contribution.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces a selected-average mismatch bound as a modeling assumption that captures dynamic improvement in low-fidelity observations. The TACC algorithm's continuation rule and the instance-dependent regret bound are then derived from this assumption using standard optimistic bandit analysis. No load-bearing step reduces a prediction to a fitted parameter by construction, invokes a self-citation chain, or renames a known result; the derivation remains self-contained against the stated model.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low-fidelity observations improve with repeated sampling in a quantifiable manner captured by a mismatch bound.
invented entities (1)
-
Selected-average mismatch bound
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe introduce a selected-average mismatch bound that converts dynamic low-fidelity observations into improvement-aware confidence bounds
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearinstance-dependent regret bound showing that, for detected intermediate arms, adaptive continuation replaces logarithmic high-fidelity confirmation with bounded low-fidelity continuation
Reference graph
Works this paper leans on
-
[1]
Jean-Yves Audibert, Rémi Munos, and Csaba Szepesvári. Exploration–exploitation tradeoff using variance estimates in multi-armed bandits.Theoretical Computer Science, 410(19):1876–1902,
work page 1902
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Amir Rezaei Balef, Claire Vernade, and Katharina Eggensperger. Put cash on bandits: A max k-armed problem for automated machine learning.arXiv preprint arXiv:2505.05226,
-
[4]
Djallel Bouneffouf and Irina Rish. A survey on practical applications of multi-armed and contextual bandits.arXiv preprint arXiv:1904.10040,
-
[5]
Yuriy Dorn, Aleksandr Katrutsa, Ilgam Latypov, and Anastasiia Soboleva. Functional multi-armed bandit and the best function identification problems.arXiv preprint arXiv:2503.00509,
-
[6]
Ucb-type algorithm for budget-constrained expert learning.arXiv preprint arXiv:2510.22654,
Ilgam Latypov, Alexandra Suvorikova, Alexey Kroshnin, Alexander Gasnikov, and Yuriy Dorn. Ucb-type algorithm for budget-constrained expert learning.arXiv preprint arXiv:2510.22654,
-
[7]
Best arm identification for stochastic rising bandits.arXiv preprint arXiv:2302.07510,
Marco Mussi, Alessandro Montenegro, Francesco Trovo, Marcello Restelli, and Alberto Maria Metelli. Best arm identification for stochastic rising bandits.arXiv preprint arXiv:2302.07510,
-
[8]
Functional bandits.arXiv preprint arXiv:1405.2432,
11 Long Tran-Thanh and Jia Yuan Yu. Functional bandits.arXiv preprint arXiv:1405.2432,
-
[9]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020,
work page internal anchor Pith review arXiv
-
[10]
A prompt-policy maps an NLI input to a candidate label
D.2 LLM-as-a-Judge Experimental Protocol The LLM-as-a-judge experiment treats a bandit arm as a prompt-policy rather than as an individual NLI example. A prompt-policy maps an NLI input to a candidate label. The high-fidelity target is the expected verifier correctness of that policy, while the low-fidelity source is a cheaper weak-judge feedback process ...
work page 2018
-
[11]
Confidence intervals are paired95%intervals over200common seeds
The reported value is TACC minus baseline; negative values favor TACC. Confidence intervals are paired95%intervals over200common seeds. Baseline Mean diff.95%CI Favors TACC? DNC−561.1 [−1103.6,−18.6]Yes MF-UCB−631.4 [−1208.5,−54.4]Yes UCB−619.4 [−1227.2,−11.6]Yes Weak-Fixed−2865.0 [−3318.3,−2411.6]Yes 0 3 6 9 12 13 Budget (×104) 0 1000 2000 3000 4000 5000...
work page 2000
-
[12]
Values are mean cost-weighted pseudo-regret ± standard error
Table 5: Vanishing-mismatch experiment at final budgetΛ = 128000. Values are mean cost-weighted pseudo-regret ± standard error. Lower is better; the best reported method for each high-fidelity cost is bolded. λ(H) TACC DNC MF-UCB UCB Weak-Fixed 20075.7±0.5677.5±28.6 1503.1±37.1 1506.1±39.4 6503.0±0.0 500143.0±0.3657.7±113.4 2687.8±74.0 2711.1±52.0 6503.0±...
work page 2048
-
[13]
Figure 8 and Table 7 report the resulting policy-level low–high gap
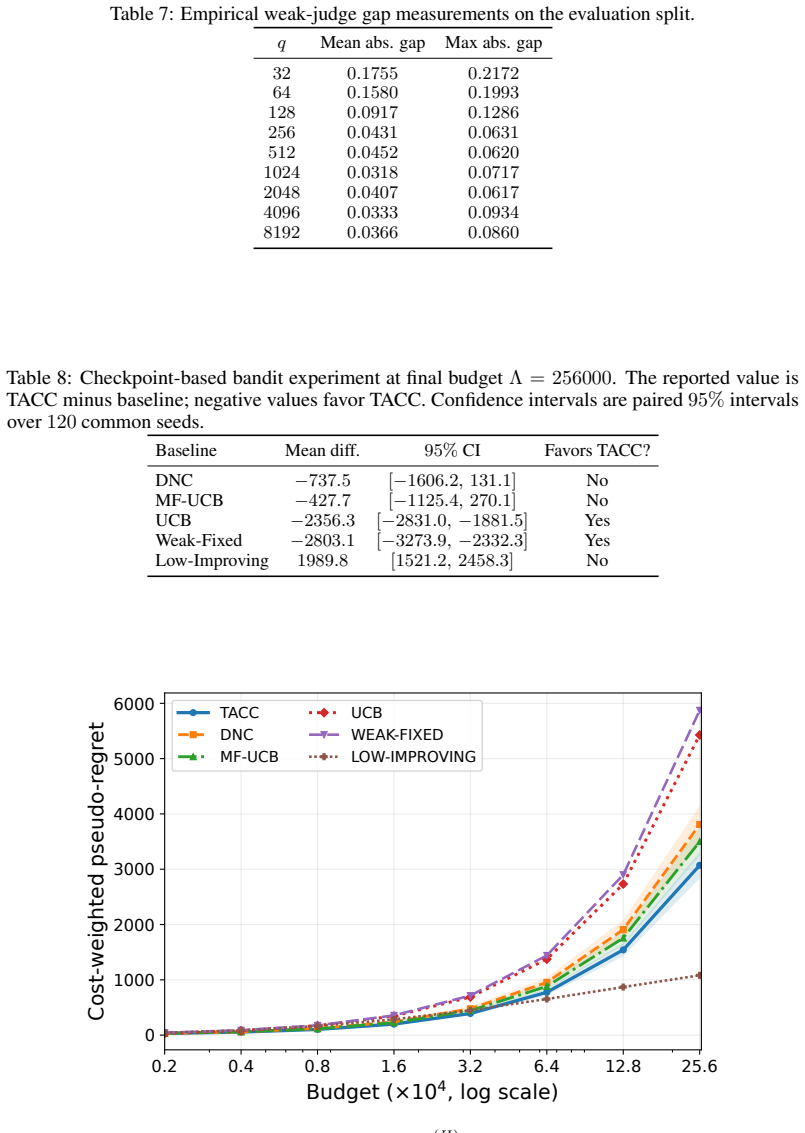
For each prompt-policy arm and weak-judge scale q, we compute an empirical low-fidelity policy mean and compare it with the verifier mean. Figure 8 and Table 7 report the resulting policy-level low–high gap. The mean absolute gap decreases from 0.1755 at q= 32 to 0.0452 at q= 512 and 0.0318 at q= 1024 , with later checkpoints fluctuating at a lower level....
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.