Recognition: no theorem link
LAQuant: A Simple Overhead-free Large Reasoning Model Quantization by Layer-wise Lookahead Loss
Pith reviewed 2026-05-12 03:26 UTC · model grok-4.3
The pith
Layer-wise lookahead loss in quantization preserves KV-cache fidelity for long reasoning chains without adding inference overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through a systematic gradient-direction analysis, we identify two factors driving this gap: (i) KV-cache fidelity preservation under the QAT loss, which E2E supervision attenuates via the softmax Fisher metric; and (ii) Hessian-subspace alignment between calibration data and the deployment distribution. We propose LookAhead Quantization (LAQuant), a layer-wise weight-only QAT method that addresses both factors without online-transform overhead by combining reasoning-domain calibration with a one-layer lookahead loss whose implicit cross-layer co-adaptation preserves the next-layer residual stream.
What carries the argument
one-layer lookahead loss inside a layer-wise weight-only QAT procedure that produces implicit cross-layer co-adaptation to protect residual streams and KV-cache fidelity
Load-bearing premise
A single lookahead step from the current layer is enough to keep the next layer's residual stream and KV-cache accurate after quantization.
What would settle it
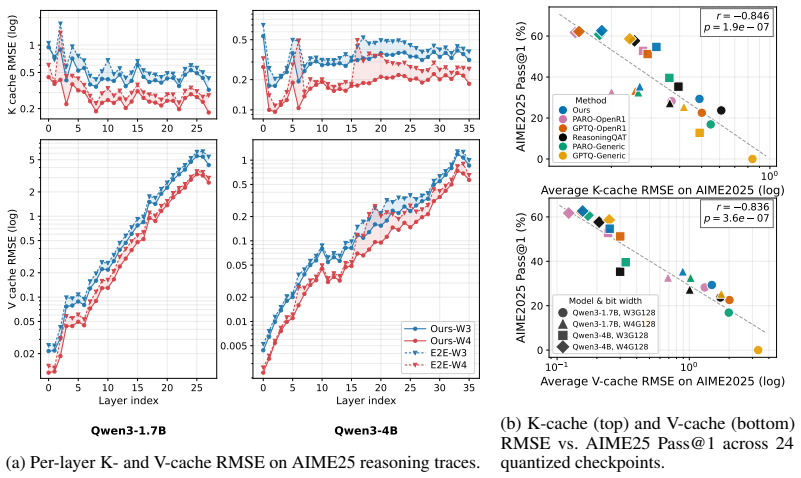
Direct measurement of KV-cache or residual-stream error on long AIME25 sequences after applying the quantized weights with versus without the lookahead term; large divergence would show the term failed to preserve fidelity.
Figures



read the original abstract
Large reasoning models (LRMs) reach competition-level math and coding accuracy via long autoregressive decoding, making per-token decoding cost a primary deployment concern. Weight quantization is the standard tool for acceleration, but representative recipes -- including state-of-the-art end-to-end (E2E) QAT -- lose accuracy on long-decoding reasoning benchmarks despite preserving perplexity and short-decode accuracy. Through a systematic gradient-direction analysis, we identify two factors driving this gap: (i) KV-cache fidelity preservation under the QAT loss, which E2E supervision attenuates via the softmax Fisher metric; and (ii) Hessian-subspace alignment between calibration data and the deployment distribution. We propose LookAhead Quantization (LAQuant), a layer-wise weight-only QAT method that addresses both factors without online-transform overhead by combining reasoning-domain calibration with a one-layer lookahead loss whose implicit cross-layer co-adaptation preserves the next-layer residual stream. For Qwen3-4B under W3G128 quantization, LAQuant improves AIME25 Pass@1 over ParoQuant by 15.11pp (1.93pp over ParoQuant++ at matched calibration) while achieving a 3.42x decoding speedup over FP16 on RTX A6000, compared with ParoQuant's 3.01x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LAQuant, a layer-wise weight-only QAT method for large reasoning models that combines reasoning-domain calibration data with a one-layer lookahead loss. Through gradient-direction analysis, the authors identify KV-cache fidelity attenuation (via softmax Fisher metric) and Hessian-subspace misalignment as causes of accuracy loss on long-decoding reasoning tasks despite preserved perplexity. They claim the lookahead loss enables implicit cross-layer co-adaptation that preserves next-layer residual streams and KV-cache states without online overhead. On Qwen3-4B with W3G128 quantization, LAQuant is reported to improve AIME25 Pass@1 by 15.11pp over ParoQuant (1.93pp over ParoQuant++ at matched calibration) while delivering 3.42x decoding speedup over FP16.
Significance. If the reported gains and mechanistic claims hold under rigorous verification, LAQuant would represent a meaningful advance in practical quantization for LRMs, enabling higher accuracy on competition-level math benchmarks at substantial inference speedups with no added runtime cost. The gradient-based diagnosis of the two failure modes (KV fidelity and calibration alignment) could inform future QAT designs for autoregressive models.
major comments (2)
- [gradient-direction analysis (Section 3)] The gradient-direction analysis demonstrates only local directional alignment between the lookahead loss and FP16 gradients; it does not include any multi-layer error-propagation analysis or measurements of residual-stream cosine similarity / KV-cache L2 deviation on sequences exceeding 1k tokens. Without such evidence, the 15.11pp AIME25 gain cannot be confidently attributed to the proposed cross-layer co-adaptation mechanism rather than calibration data differences.
- [experimental results (Section 4)] Table reporting AIME25 Pass@1 results (and associated speedup figures) provides no error bars, no ablation isolating the lookahead loss from the reasoning-domain calibration, and no details on sequence lengths or number of long traces used during evaluation. This leaves the central claim that LAQuant specifically solves the long-decoding gap unverifiable from the presented data.
minor comments (1)
- [method (Section 3)] Notation for the lookahead loss (Eq. (X)) should explicitly define how the one-layer surrogate is computed during back-propagation to avoid ambiguity about whether it requires additional forward passes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below with clarifications on the existing analysis and results, and we commit to targeted revisions that strengthen verifiability without altering the core claims.
read point-by-point responses
-
Referee: [gradient-direction analysis (Section 3)] The gradient-direction analysis demonstrates only local directional alignment between the lookahead loss and FP16 gradients; it does not include any multi-layer error-propagation analysis or measurements of residual-stream cosine similarity / KV-cache L2 deviation on sequences exceeding 1k tokens. Without such evidence, the 15.11pp AIME25 gain cannot be confidently attributed to the proposed cross-layer co-adaptation mechanism rather than calibration data differences.
Authors: We agree that Section 3 focuses on local per-layer gradient directional alignment to diagnose the two failure modes (KV-cache fidelity via softmax Fisher metric and Hessian-subspace misalignment). The cross-layer co-adaptation arises implicitly because each layer is optimized with a one-layer lookahead loss that directly supervises the residual stream passed to the next layer. The 1.93pp gain over ParoQuant++ (which uses identical reasoning-domain calibration data) already isolates the lookahead contribution from calibration differences. To further substantiate the long-sequence mechanism, the revised manuscript will add: (i) chained multi-layer gradient propagation analysis and (ii) residual-stream cosine similarity plus KV-cache L2 deviation measurements on sequences up to 4k tokens drawn from AIME25-style traces. These additions will be placed in an expanded Section 3. revision: yes
-
Referee: [experimental results (Section 4)] Table reporting AIME25 Pass@1 results (and associated speedup figures) provides no error bars, no ablation isolating the lookahead loss from the reasoning-domain calibration, and no details on sequence lengths or number of long traces used during evaluation. This leaves the central claim that LAQuant specifically solves the long-decoding gap unverifiable from the presented data.
Authors: We acknowledge that the current experimental section omits error bars, a dedicated isolation ablation, and explicit evaluation metadata. The ParoQuant++ comparison already provides a matched-calibration control that isolates the lookahead loss, but we will expand this into a full ablation table. In the revision we will: (1) report error bars from three independent runs with different seeds for all AIME25 Pass@1 numbers; (2) add a clear ablation subsection contrasting LAQuant against a reasoning-calibration baseline without the lookahead term; and (3) state that evaluation uses the complete set of 30 AIME25 problems with full autoregressive traces (average length exceeding 2k tokens) and report the exact number of traces evaluated. Speedup measurements remain as reported on RTX A6000. These changes will make the long-decoding claims directly verifiable. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives its LAQuant method from a gradient-direction analysis identifying KV-cache fidelity and Hessian alignment issues, then introduces a one-layer lookahead loss plus reasoning-domain calibration as an independent mechanism. No equations reduce the claimed accuracy gains or speedup to fitted parameters by construction, and no load-bearing steps rely on self-citations or imported uniqueness theorems. The central claims rest on the proposed loss formulation and empirical benchmarks rather than tautological redefinitions or renamings of prior results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hadacore: Tensor core accelerated hadamard transform kernel.arXiv preprint arXiv:2412.08832, 2024
Krish Agarwal, Rishi Astra, Adnan Hoque, Mudhakar Srivatsa, Raghu Ganti, Less Wright, and Sijia Chen. Hadacore: Tensor core accelerated hadamard transform kernel.arXiv preprint arXiv:2412.08832, 2024
-
[2]
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213– 100240, 2024
work page 2024
-
[3]
Db-llm: Accurate dual-binarization for efficient llms
Hong Chen, Chengtao Lv, Liang Ding, Haotong Qin, Xiabin Zhou, Yifu Ding, Xuebo Liu, Min Zhang, Jinyang Guo, Xianglong Liu, et al. Db-llm: Accurate dual-binarization for efficient llms. InFindings of the Association for Computational Linguistics: ACL 2024, pages 8719–8730, 2024
work page 2024
-
[4]
Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, Yu Qiao, and Ping Luo. Efficientqat: Efficient quantization-aware training for large language models.arXiv preprint arXiv:2407.11062, 2024
-
[5]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), ...
work page 2019
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Fast Hadamard Transform in CUDA, with a PyTorch Interface
Tri Dao. Fast Hadamard Transform in CUDA, with a PyTorch Interface. https://github. com/Dao-AILab/fast-hadamard-transform, 2024
work page 2024
-
[8]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
work page 2025
-
[9]
Bitdistiller: Unleashing the potential of sub-4-bit llms via self-distillation, 2024
Dayou Du, Yijia Zhang, Shijie Cao, Jiaqi Guo, Ting Cao, Xiaowen Chu, and Ningyi Xu. Bitdistiller: Unleashing the potential of sub-4-bit llms via self-distillation, 2024
work page 2024
-
[10]
Razvan-Gabriel Dumitru, Vikas Yadav, Rishabh Maheshwary, Paul-Ioan Clotan, Sathwik Te- jaswi Madhusudhan, and Mihai Surdeanu. Layer-wise quantization: A pragmatic and effective method for quantizing llms beyond integer bit-levels.arXiv preprint arXiv:2406.17415, 2024
-
[11]
Elias Frantar and Dan Alistarh. Optimal brain compression: A framework for accurate post- training quantization and pruning.Advances in Neural Information Processing Systems, 35:4475– 4488, 2022
work page 2022
-
[12]
OPTQ: Accurate quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. OPTQ: Accurate quantization for generative pre-trained transformers. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[13]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
work page 2024
-
[14]
Ross Girshick. Fast r-cnn. InProceedings of the IEEE international conference on computer vision, pages 1440–1448, 2015
work page 2015
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Lighteval: A lightweight framework for llm evaluation, 2023
Nathan Habib, Clémentine Fourrier, Hynek Kydlí ˇcek, Thomas Wolf, and Lewis Tunstall. Lighteval: A lightweight framework for llm evaluation, 2023
work page 2023
-
[18]
Babak Hassibi and David Stork. Second order derivatives for network pruning: Optimal brain surgeon.Advances in neural information processing systems, 5, 1992
work page 1992
-
[19]
Billm: pushing the limit of post-training quantization for llms
Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, and Xiaojuan Qi. Billm: pushing the limit of post-training quantization for llms. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[20]
Robust estimation of a location parameter
Peter J Huber. Robust estimation of a location parameter. InBreakthroughs in statistics: Methodology and distribution, pages 492–518. Springer, 1992
work page 1992
-
[21]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025
work page 2025
-
[22]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
- [23]
-
[24]
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, and Kurt Keutzer. Squeezellm: Dense-and-sparse quantization. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[25]
The impact of quantization on large reasoning model reinforcement learning
Medha Kumar, Zifei Xu, Xin Wang, and Tristan Webb. The impact of quantization on large reasoning model reinforcement learning. InNeurIPS 2025 Workshop on Efficient Reasoning, 2025
work page 2025
-
[26]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[27]
Optimal brain damage.Advances in neural information processing systems, 2, 1989
Yann LeCun, John Denker, and Sara Solla. Optimal brain damage.Advances in neural information processing systems, 2, 1989
work page 1989
-
[28]
Geonho Lee, Janghwan Lee, Sukjin Hong, Minsoo Kim, Euijai Ahn, Du-Seong Chang, and Jungwook Choi. Rilq: Rank-insensitive lora-based quantization error compensation for boosting 2-bit large language model accuracy. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 18091–18100, 2025
work page 2025
-
[29]
Zhen Li, Yupeng Su, Runming Yang, Congkai Xie, Zheng Wang, Zhongwei Xie, Ngai Wong, and Hongxia Yang. Quantization meets reasoning: Exploring llm low-bit quantization degradation for mathematical reasoning.arXiv preprint arXiv:2501.03035, 2025
-
[30]
ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference
Yesheng Liang, Haisheng Chen, Zihan Zhang, Song Han, and Zhijian Liu. ParoQuant: Pairwise Rotation Quantization for Efficient Reasoning LLM Inference. InInternational Conference on Learning Representations (ICLR), 2026
work page 2026
-
[31]
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. Duquant: Distributing outliers via dual transformation makes stronger quantized llms.Advances in Neural Information Processing Systems, 37:87766–87800, 2024
work page 2024
-
[32]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024. 12
work page 2024
-
[33]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. Qserve: W4a8kv4 quantization and system co-design for efficient llm serving. Proceedings of Machine Learning and Systems, 7, 2025
work page 2025
-
[34]
Ruikang Liu, Yuxuan Sun, Manyi Zhang, Haoli Bai, Xianzhi Yu, Tiezheng Yu, Chun Yuan, and Lu Hou. Quantization hurts reasoning? an empirical study on quantized reasoning models. arXiv preprint arXiv:2504.04823, 2025
-
[35]
Vptq: Extreme low-bit vector post-training quantization for large language models
Yifei Liu, Jicheng Wen, Yang Wang, Shengyu Ye, Li Lyna Zhang, Ting Cao, Cheng Li, and Mao Yang. Vptq: Extreme low-bit vector post-training quantization for large language models. InThe 2024 Conference on Empirical Methods in Natural Language Processing, 2024
work page 2024
-
[36]
Spinquant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant: LLM quantization with learned rotations. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[37]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[38]
What makes low-bit quantization-aware training work for reasoning llms? a systematic study, 2026
Keyu Lv, Manyi Zhang, Xiaobo Xia, Jingchen Ni, Shannan Yan, Xianzhi Yu, Lu Hou, Chun Yuan, and Haoli Bai. What makes low-bit quantization-aware training work for reasoning llms? a systematic study, 2026
work page 2026
- [39]
-
[40]
Anmol Mekala, Anirudh Atmakuru, Yixiao Song, Marzena Karpinska, and Mohit Iyyer. Does quantization affect models’ performance on long-context tasks? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9433–9481, 2025
work page 2025
-
[41]
Pointer sentinel mixture models, 2016
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016
work page 2016
-
[42]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
work page 2025
-
[43]
Towards quantization- aware training for ultra-low-bit reasoning LLMs
Yasuyuki Okoshi, Hikari Otsuka, Daichi Fujiki, and Masato Motomura. Towards quantization- aware training for ultra-low-bit reasoning LLMs. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[44]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
work page 2020
-
[45]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[46]
Omniquant: Omnidirectionally calibrated quan- tization for large language models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quan- tization for large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[47]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025. 13
work page 2025
-
[49]
Albert Tseng, Qingyao Sun, David Hou, and Christopher De. Qtip: Quantization with trellises and incoherence processing.Advances in Neural Information Processing Systems, 37:59597– 59620, 2024
work page 2024
-
[50]
Bitnet: Scaling 1-bit transformers for large language models,
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. Bitnet: Scaling 1-bit transformers for large language models.arXiv preprint arXiv:2310.11453, 2023
-
[51]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[52]
Maurice Weber, Daniel Y . Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexan- drov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher Ré, Irina Rish, and Ce Zhang. Redpajama: an open dataset for training large language models.NeurIPS Datasets an...
work page 2024
-
[53]
On the impact of calibration data in post-training quantization and pruning
Miles Williams and Nikolaos Aletras. On the impact of calibration data in post-training quantization and pruning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10100–10118, 2024
work page 2024
-
[54]
Yang Xiang, Yixin Ji, Juntao Li, and Min Zhang. Think before you prune: Selective self- generated calibration for pruning large reasoning models, 2025
work page 2025
-
[55]
SmoothQuant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. In Proceedings of the 40th International Conference on Machine Learning, 2023
work page 2023
-
[56]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
work page 2019
-
[59]
Nan Zhang, Eugene Kwek, Yusen Zhang, Muyu Pan, Suhang Wang, Prasenjit Mitra, and Rui Zhang. Quantlrm: Quantization of large reasoning models via fine-tuning signals.arXiv preprint arXiv:2602.02581, 2026
-
[60]
Atom: Low-bit quantization for efficient and accurate llm serving
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. Atom: Low-bit quantization for efficient and accurate llm serving. In P. Gibbons, G. Pekhimenko, and C. De Sa, editors,Proceedings of Machine Learning and Systems, volume 6, pages 196–209, 2024
work page 2024
-
[61]
An empirical study of qwen3 quantiza- tion.Visual Intelligence, 4(1):11, 2026
Xingyu Zheng, Yuye Li, Haoran Chu, Yue Feng, Xudong Ma, Zining Wang, Jie Luo, Jinyang Guo, Haotong Qin, Michele Magno, and Xianglong Liu. An empirical study of qwen3 quantiza- tion.Visual Intelligence, 4(1):11, 2026
work page 2026
-
[62]
Ar-lsat: Investigating analytical reasoning of text.arXiv preprint arXiv:2104.06598, 2021
Wanjun Zhong, Siyuan Wang, Duyu Tang, Zenan Xu, Daya Guo, Jiahai Wang, Jian Yin, Ming Zhou, and Nan Duan. Ar-lsat: Investigating analytical reasoning of text.arXiv preprint arXiv:2104.06598, 2021. 14 A Related Work Post-training quantization (PTQ) for LLMs.GPTQ [ 12] introduced layer-wise OBS-style weight reconstruction with per-group quantization, becomi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.