Recognition: 2 theorem links
· Lean TheoremMDL-GBG: A Non-parametric and Interpretable Granular-Ball Generation Method for Clustering
Pith reviewed 2026-05-14 21:42 UTC · model grok-4.3
The pith
MDL-GBG selects among single-ball, two-ball, or core-plus-residual models for each granular ball by choosing the shortest description length.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
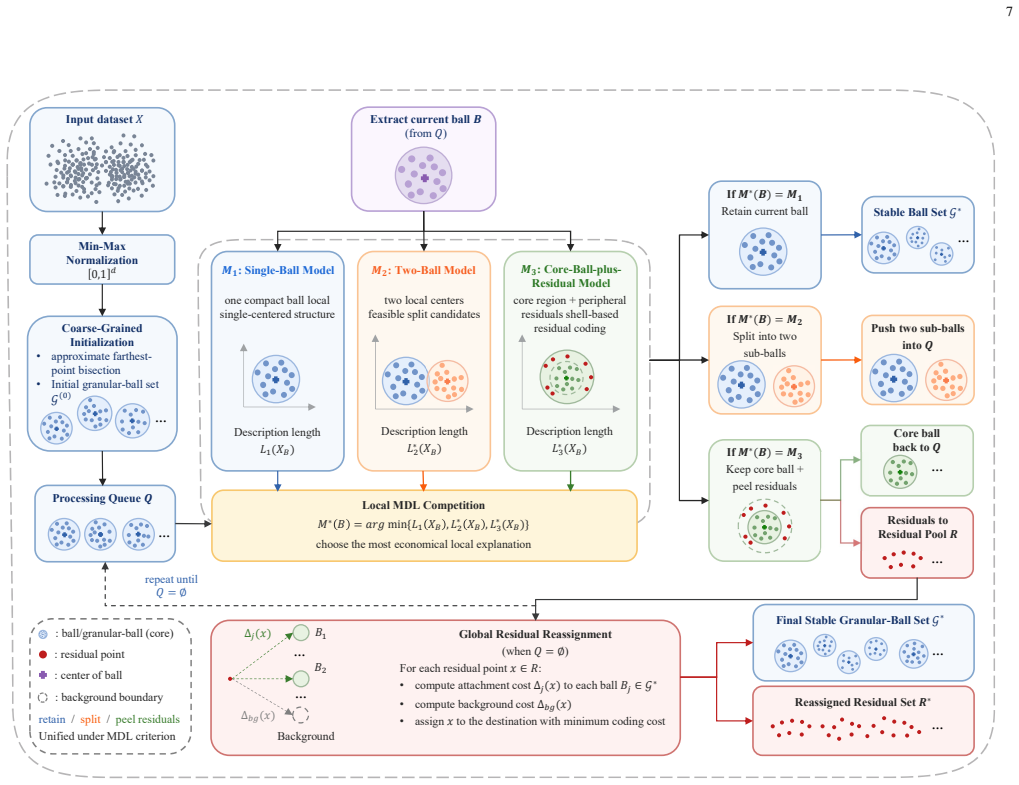
MDL-GBG treats each granular ball as an independent model-selection problem in which the minimum-description-length criterion chooses among three explicit explanations: a single ball, a partition into two balls, or a core ball plus peeled residuals. The choice simultaneously decides whether to retain the ball, split it, or peel boundary samples, all inside one coding-length calculation. A subsequent reassignment pass moves peeled points to the nearest stable ball, producing a final collection of non-overlapping granular balls that can be fed directly to downstream clustering algorithms.
What carries the argument
Minimum description length comparison of three candidate models (single-ball, two-ball, core-ball-plus-residual) that unifies retention, splitting, and residual peeling for each local ball.
If this is right
- Ball retention, splitting, and residual peeling become decisions inside a single, parameter-free coding framework.
- The generated granular balls form a stable, interpretable upstream representation for any subsequent clustering algorithm.
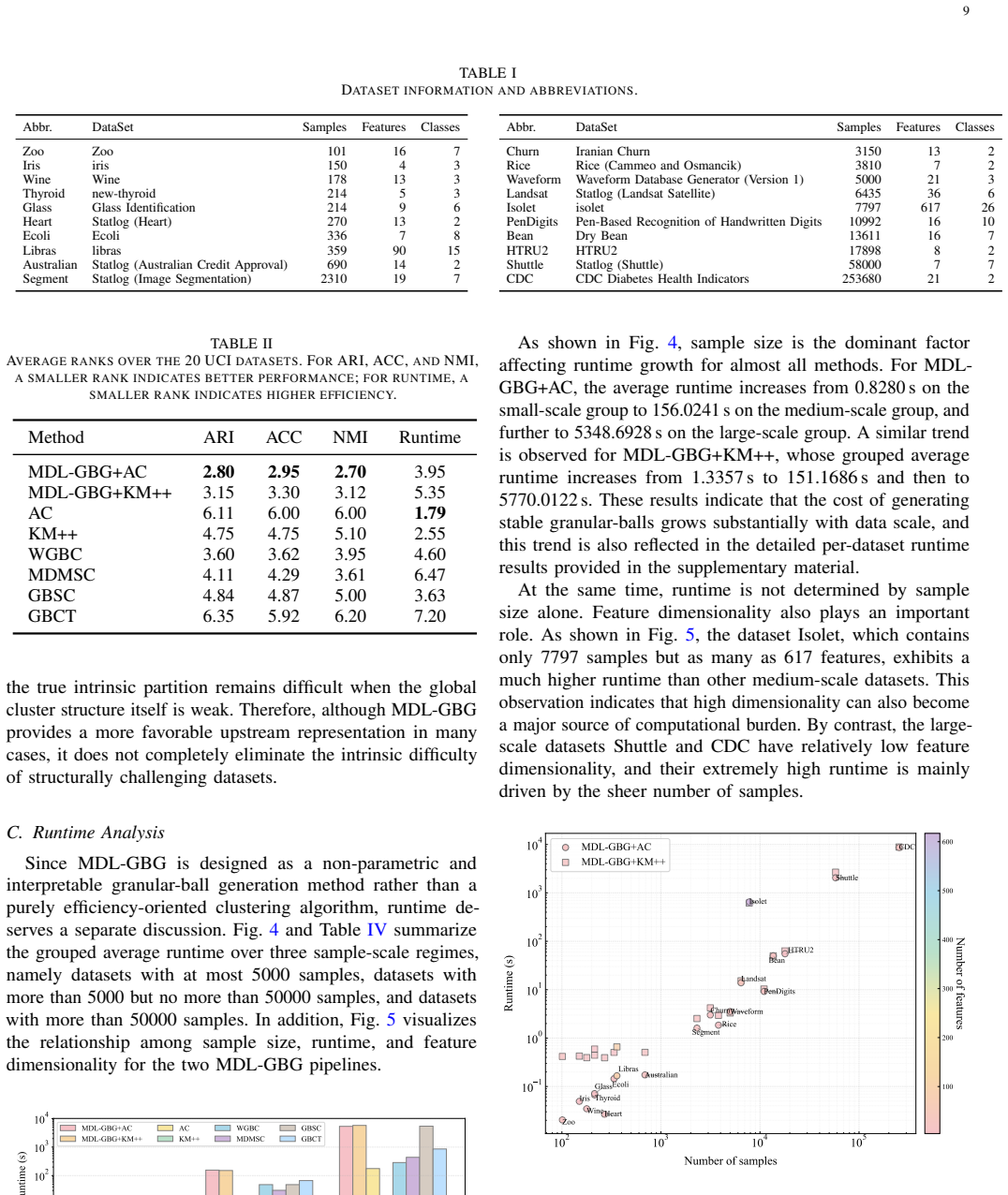
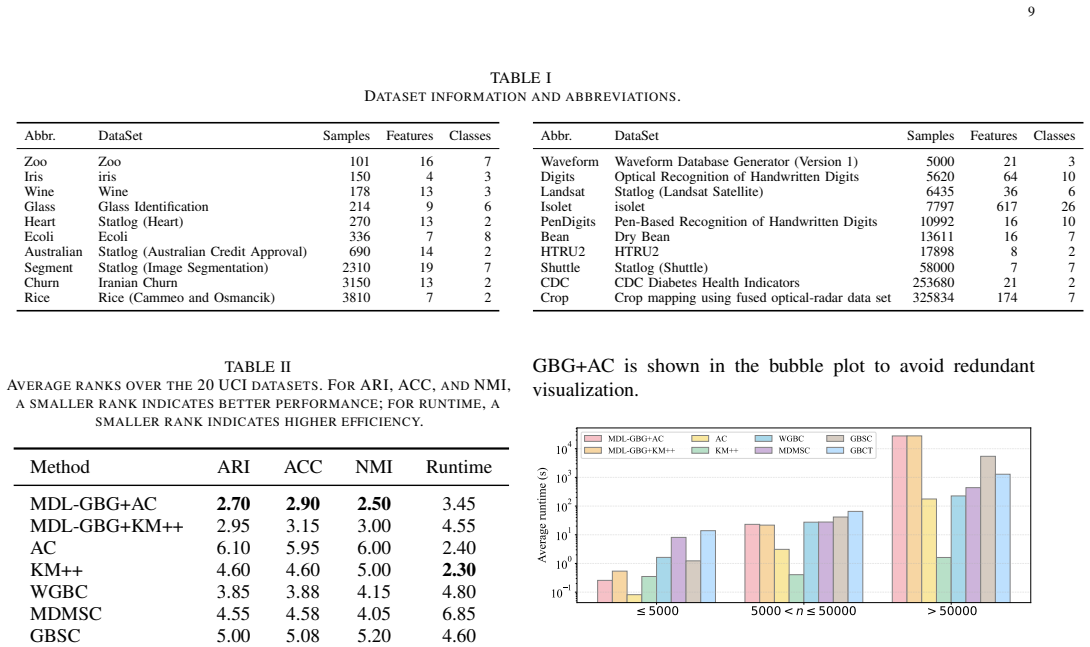
- MDL-GBG plus agglomerative clustering obtains the highest average ranks on ARI, ACC, and NMI across the twenty data sets.
- No handcrafted quality measure or heuristic stopping threshold is required.
Where Pith is reading between the lines
- The same local-model-selection logic could be applied to other granular or prototype-based representations beyond clustering.
- If the three-model set proves insufficient on certain data geometries, the method naturally invites extension by adding further candidate explanations.
- The residual-reassignment step suggests a general post-processing pattern that could improve boundary handling in other non-parametric clustering pipelines.
Load-bearing premise
That the three candidate models are sufficient to capture the optimal local structure around every point and that their description lengths can be computed without additional fitting parameters.
What would settle it
A controlled test on one or more UCI data sets in which an alternative set of candidate models or a different coding-length formula produces measurably higher ARI, ACC, or NMI than the three-model MDL-GBG procedure.
Figures



read the original abstract
Existing granular-ball generation methods are still mainly driven by handcrafted quality measures and heuristic splitting or stopping criteria, which may weaken the transparency of local generation decisions in clustering. To address this issue, this paper proposes Minimum Description Length based Granular-Ball Generation (MDL-GBG), a non-parametric and interpretable granular-ball generation method for clustering. MDL-GBG reformulates granular-ball generation as a local model selection problem under the Minimum Description Length principle. For each granular ball, three candidate explanations are compared, namely a single-ball model, a two-ball model, and a core-ball-plus-residual model, and the model with the shortest description length is selected. In this way, ball retention, splitting, and residual peeling are unified within a common coding-theoretic framework. A residual reassignment mechanism is further introduced to re-evaluate peeled-off boundary samples after stable granular-balls are formed. Experiments on 20 UCI datasets show that the stable granular-balls generated by MDL-GBG provide an effective upstream representation for clustering. In particular, MDL-GBG+AC achieves the best average ranks in ARI, ACC, and NMI among the compared methods. These results indicate that MDL-GBG offers a principled and interpretable alternative to heuristic granular-ball generation strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MDL-GBG, which reformulates granular-ball generation for clustering as a local model-selection task under the Minimum Description Length (MDL) principle. For each candidate ball, it compares three explicit local models (single-ball, two-ball, and core-ball-plus-residual), selects the shortest-description-length model, and thereby unifies retention, splitting, and residual peeling. A residual-reassignment step follows formation of stable balls. Experiments on 20 UCI datasets report that MDL-GBG+AC obtains the best average ranks in ARI, ACC, and NMI among compared methods.
Significance. If the MDL length calculations are shown to be free of data-dependent fitting constants and the three-model family is sufficient, the work supplies a principled, coding-theoretic alternative to heuristic quality measures and stopping rules in granular-ball clustering, increasing interpretability and transparency of local decisions.
major comments (2)
- [§3] §3 (Method description): the explicit formulas for the description lengths of the single-ball, two-ball, and core-ball-plus-residual models are not supplied. Without these formulas it is impossible to verify that the coding scheme for centers, radii, and point assignments introduces no data-derived quantities (e.g., empirical variance, range-based quantization, or adaptive bin widths), which would render the claimed non-parametric status circular.
- [§4] §4 (Experiments): the reported best average ranks on ARI/ACC/NMI are presented without error bars, without the results of statistical significance tests (e.g., Friedman + Nemenyi or Wilcoxon), and without an ablation that isolates the contribution of the residual-reassignment step. These omissions prevent assessment of whether the ranking advantage is robust or sensitive to baseline selection.
minor comments (2)
- [Introduction] The abstract and introduction cite the MDL principle but do not reference prior MDL-based clustering or granular-computing literature; adding 2–3 key citations would clarify novelty.
- [§3] Notation for the three candidate models (single-ball, two-ball, core-ball-plus-residual) is introduced only informally; a compact table or equation block defining their parameter sets and coding lengths would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below. Revisions have been made to the manuscript to incorporate the suggested improvements for greater transparency and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method description): the explicit formulas for the description lengths of the single-ball, two-ball, and core-ball-plus-residual models are not supplied. Without these formulas it is impossible to verify that the coding scheme for centers, radii, and point assignments introduces no data-derived quantities (e.g., empirical variance, range-based quantization, or adaptive bin widths), which would render the claimed non-parametric status circular.
Authors: We agree that the explicit formulas were omitted from the original submission, which hinders full verification of the coding scheme. In the revised manuscript we will insert the complete description-length formulas for all three models. The single-ball model encodes the center with fixed-precision floating-point representation, the radius with a uniform code, and point assignments via a simple indicator code with no data-dependent binning or variance terms. The two-ball model extends this by encoding an additional center-radius pair and a binary assignment vector. The core-ball-plus-residual model encodes the core ball identically to the single-ball case and then encodes each residual point individually with a fixed-length code. These formulas contain no empirical variance, range-based quantization, or adaptive bin widths, thereby confirming that the method remains strictly non-parametric and that the non-parametric claim is not circular. revision: yes
-
Referee: [§4] §4 (Experiments): the reported best average ranks on ARI/ACC/NMI are presented without error bars, without the results of statistical significance tests (e.g., Friedman + Nemenyi or Wilcoxon), and without an ablation that isolates the contribution of the residual-reassignment step. These omissions prevent assessment of whether the ranking advantage is robust or sensitive to baseline selection.
Authors: We acknowledge that the experimental section would be strengthened by the addition of error bars, formal statistical tests, and an ablation study. In the revision we will report standard deviations as error bars on all average-rank and performance figures across the 20 UCI datasets. We will also include the results of the Friedman test with Nemenyi post-hoc analysis to assess the statistical significance of the observed ranking differences. Finally, we will add an ablation table that directly compares MDL-GBG with and without the residual-reassignment step, thereby isolating its contribution to the final clustering metrics. These additions will allow readers to evaluate the robustness of the reported advantages. revision: yes
Circularity Check
No circularity: standard MDL applied to three fixed candidate models
full rationale
The paper reformulates granular-ball generation as local model selection by comparing description lengths of three explicitly enumerated models (single-ball, two-ball, core-ball-plus-residual) and selecting the shortest. No equation or step reduces this selection to a parameter fitted from the same data by construction, nor does any load-bearing premise rely on a self-citation chain or imported uniqueness theorem. The derivation is self-contained as a direct application of the MDL principle to the listed candidates.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Minimum Description Length principle can be directly applied to select among single-ball, two-ball, and core-ball-plus-residual explanations for local data subsets
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MDL-GBG reformulates granular-ball generation as a local model selection problem... three candidate explanations... single-ball model, two-ball model, and core-ball-plus-residual model... L1(Y)=−logp(Y|ĉ,σ̂²)+k1/2 log m with isotropic Gaussian
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
non-parametric and interpretable granular-ball generation method... no manual parameter tuning in the generation process
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
A Boundary-Aware Non-parametric Granular-Ball Classifier Based on Minimum Description Length
MDL-GBC constructs class-conditional granular balls by comparing single-ball, two-ball, and core-boundary models under a unified MDL criterion and aggregates them for prediction, achieving the best average accuracy an...
Reference graph
Works this paper leans on
-
[1]
Survey of spectral clustering based on graph theory,
L. Ding, C. Li, D. Jin, and S. Ding, “Survey of spectral clustering based on graph theory,”Pattern Recognition, vol. 151, p. 110366, 2024
work page 2024
-
[2]
Interpretable clustering: A survey,
L. Hu, M. Jiang, J. Dong, X. Liu, and Z. He, “Interpretable clustering: A survey,”ACM Computing Surveys, vol. 58, no. 8, pp. 1–21, 2026
work page 2026
-
[3]
Gbct: efficient and adaptive clustering via granular-ball computing for complex data,
S. Xia, B. Shi, Y . Wang, J. Xie, G. Wang, and X. Gao, “Gbct: efficient and adaptive clustering via granular-ball computing for complex data,” IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 7, pp. 12 159–12 172, 2025
work page 2025
-
[4]
Topological structure in visual perception,
L. Chen, “Topological structure in visual perception,”Science, vol. 218, no. 4573, pp. 699–700, 1982
work page 1982
-
[5]
Granular ball computing classifiers for efficient, scalable and robust learning,
S. Xia, Y . Liu, X. Ding, G. Wang, H. Yu, and Y . Luo, “Granular ball computing classifiers for efficient, scalable and robust learning,” Information Sciences, vol. 483, pp. 136–152, 2019
work page 2019
-
[6]
S. Xia, G. Wang, X. Gao, and X. Lian, “Granular-ball computing: an ef- ficient, robust, and interpretable adaptive multi-granularity representation and computation method,”arXiv preprint arXiv:2304.11171, 2023
-
[7]
Granular-ball fuzzy set and its implement in svm,
S. Xia, X. Lian, G. Wang, X. Gao, Q. Hu, and Y . Shao, “Granular-ball fuzzy set and its implement in svm,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6293–6304, 2024
work page 2024
-
[8]
An efficient spectral clustering algorithm based on granular-ball,
J. Xie, W. Kong, S. Xia, G. Wang, and X. Gao, “An efficient spectral clustering algorithm based on granular-ball,”IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 9, pp. 9743–9753, 2023
work page 2023
-
[9]
A fast granular-ball-based density peaks clustering algorithm for large-scale data,
D. Cheng, Y . Li, S. Xia, G. Wang, J. Huang, and S. Zhang, “A fast granular-ball-based density peaks clustering algorithm for large-scale data,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 12, pp. 17 202–17 215, 2023
work page 2023
-
[10]
Gb-dbscan: A fast granular-ball based dbscan clustering algorithm,
D. Cheng, C. Zhang, Y . Li, S. Xia, G. Wang, J. Huang, S. Zhang, and J. Xie, “Gb-dbscan: A fast granular-ball based dbscan clustering algorithm,”Information Sciences, vol. 674, p. 120731, 2024
work page 2024
-
[11]
Structure-aware granular ball clustering,
Q. Wang and M. Du, “Structure-aware granular ball clustering,”Infor- mation Sciences, vol. 740, p. 123224, 2026
work page 2026
-
[12]
Multi-view granular- ball contrastive clustering,
P. Su, S. Huang, W. Ma, D. Xiong, and J. Lv, “Multi-view granular- ball contrastive clustering,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 19, 2025, pp. 20 637–20 645
work page 2025
-
[13]
An efficient and adaptive granular-ball generation method in classification problem,
S. Xia, X. Dai, G. Wang, X. Gao, and E. Giem, “An efficient and adaptive granular-ball generation method in classification problem,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 4, pp. 5319–5331, 2022
work page 2022
-
[14]
Gbg++: A fast and stable granular ball generation method for clas- sification,
Q. Xie, Q. Zhang, S. Xia, F. Zhao, C. Wu, G. Wang, and W. Ding, “Gbg++: A fast and stable granular ball generation method for clas- sification,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 8, no. 2, pp. 2022–2036, 2024. 13
work page 2022
-
[15]
A new adaptive and effective granular ball generation method for classification,
W. Liao, Q. Zhang, Q. Xie, M. Gao, and P. Jin, “A new adaptive and effective granular ball generation method for classification,”International Journal of Machine Learning and Cybernetics, vol. 16, no. 5, pp. 3501– 3520, 2025
work page 2025
-
[16]
A granular-ball generation method based on local density for classification,
F. Liu, Q. Zhang, S. Xia, Q. Xie, W. Liao, and S. Zhang, “A granular-ball generation method based on local density for classification,”Information Sciences, vol. 717, p. 122295, 2025
work page 2025
-
[17]
A framework of granular-ball generation for classification via granularity tuning,
J. Pan, G. Lang, Q. Xiao, and T. Yang, “A framework of granular-ball generation for classification via granularity tuning,”Applied Intelligence, vol. 55, no. 1, p. 63, 2025
work page 2025
-
[18]
Generation of granular-balls for clustering based on the principle of justifiable granularity,
Z. Jia, Z. Zhang, and W. Pedrycz, “Generation of granular-balls for clustering based on the principle of justifiable granularity,”IEEE Transactions on Cybernetics, vol. 55, no. 4, pp. 1687–1700, 2025
work page 2025
-
[19]
Granular-ball regeneration clustering with principle of justifiable granu- larity,
W. Li, L. Wei, W. Pedrycz, W. Ding, C. Zhang, T. Zhan, and S. Xia, “Granular-ball regeneration clustering with principle of justifiable granu- larity,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 10, pp. 18 173–18 187, 2025
work page 2025
-
[20]
Nagb-dbscan: An improved dbscan clustering algorithm by natural neighbor and granular- ball,
R. Luo, T. Li, R. Pu, J. Yang, D. Tang, and L. Yang, “Nagb-dbscan: An improved dbscan clustering algorithm by natural neighbor and granular- ball,”Information Sciences, vol. 719, p. 122445, 2025
work page 2025
-
[21]
The minimum description length principle in coding and modeling,
A. Barron, J. Rissanen, and B. Yu, “The minimum description length principle in coding and modeling,”IEEE transactions on information theory, vol. 44, no. 6, pp. 2743–2760, 1998
work page 1998
-
[22]
P. D. Gr ¨unwald,The minimum description length principle. MIT press, 2007
work page 2007
-
[23]
k-means++: The advantages of careful seeding,
D. Arthur, S. Vassilvitskiiet al., “k-means++: The advantages of careful seeding,” inSoda, vol. 7, 2007, pp. 1027–1035
work page 2007
-
[24]
W-gbc: An adaptive weighted clustering method based on granular-ball structure,
J. Xie, C. Hua, S. Xia, Y . Cheng, G. Wang, and X. Gao, “W-gbc: An adaptive weighted clustering method based on granular-ball structure,” in 2024 IEEE 40th International conference on data engineering (ICDE). IEEE, 2024, pp. 914–925
work page 2024
-
[25]
Clustering by mining density distributions and splitting manifold structure,
Z. Xu, Z. Long, and H. Meng, “Clustering by mining density distributions and splitting manifold structure,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 20, 2025, pp. 21 842–21 849
work page 2025
-
[26]
Objective criteria for the evaluation of clustering methods,
W. M. Rand, “Objective criteria for the evaluation of clustering methods,” Journal of the American Statistical association, vol. 66, no. 336, pp. 846–850, 1971
work page 1971
-
[27]
Cluster ensembles—a knowledge reuse framework for combining multiple partitions,
A. Strehl and J. Ghosh, “Cluster ensembles—a knowledge reuse framework for combining multiple partitions,”Journal of machine learning research, vol. 3, no. Dec, pp. 583–617, 2002
work page 2002
-
[28]
Scikit-learn: Machine learning in python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourget al., “Scikit-learn: Machine learning in python,”the Journal of machine Learning research, vol. 12, pp. 2825–2830, 2011
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.