Recognition: 2 theorem links
· Lean TheoremInpainting physics: self-supervised learning for context-driven fluid simulation
Pith reviewed 2026-05-12 01:35 UTC · model grok-4.3
The pith
Reformulating steady fluid simulation as inpainting lets a self-supervised prior over velocity fields adapt to new boundary conditions at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Steady CFD inference can be recast as an inpainting problem: a self-supervised prior is learned over velocity fields without explicit boundary conditions in training, after which new constraints are imposed at inference by fixing known inlet, outlet, or unchanged geometry regions, allowing full-field reconstruction from sparse context and local edits without retraining.
What carries the argument
A local neighbourhood tokeniser that converts high-resolution 3D velocity fields into compact spatial latent tokens, on which latent flow-matching and masked-autoencoder models are trained self-supervised.
If this is right
- Full velocity fields can be reconstructed from sparse boundary context on 3D meshes.
- The approach outperforms supervised neural surrogates when boundary conditions or training datasets shift.
- Local geometry edits become possible by reusing unchanged simulation context without full recomputation.
- Neural surrogates function as reusable flow priors rather than task-specific predictors tied to fixed conditions.
Where Pith is reading between the lines
- The same inpainting formulation could be tested on time-dependent flows by including temporal context tokens.
- Similar self-supervised priors might apply to reconstruction of other physical fields such as pressure or temperature.
- Lower data requirements for surrogate modeling could follow if explicit problem specifications are needed only at inference.
- Application to CFD problems outside hemodynamics would test whether the prior generalizes across different flow regimes.
Load-bearing premise
A prior learned self-supervised over velocity fields without boundary conditions will accurately and stably incorporate arbitrary new boundary constraints and local geometry changes when applied at inference to unseen data.
What would settle it
Direct numerical comparison of the inpainted velocity field against a high-fidelity CFD solver on a held-out 3D mesh that uses inlet and outlet profiles never present in the training distribution.
Figures







read the original abstract
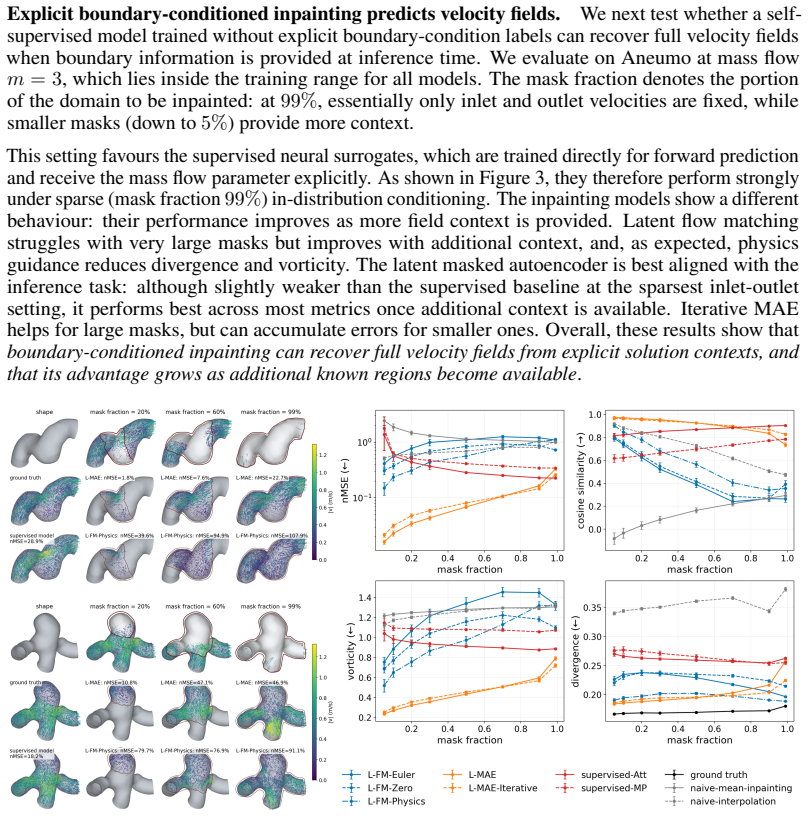
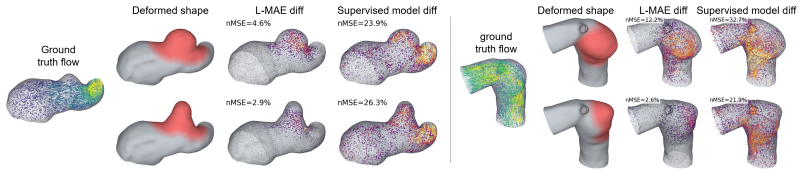
Neural surrogate models for computational fluid dynamics (CFD) are typically trained as forward operators that map explicit problem specifications, such as geometry and boundary conditions, to solution fields. This ties the model to the conditioning variables seen during training and limits reuse under boundary-condition shifts or local geometry changes. We propose to reformulate steady CFD inference as an inpainting problem: instead of training on explicit boundary conditions, we learn a self-supervised prior over velocity fields and impose boundary constraints only during inference by fixing known regions such as inlet, outlet or unchanged regions from previous simulations. To scale this idea to large 3D meshes, we introduce a local neighbourhood tokeniser that represents high-resolution velocity fields as compact spatial latent tokens and train latent flow-matching and masked-autoencoder models on these tokens. On intracranial aneurysm hemodynamics, our method reconstructs full velocity fields from sparse boundary context, outperforms supervised neural surrogates under boundary-condition and dataset shift and enables local geometry editing by reusing unchanged simulation context. These results suggest that viewing CFD inference as context-conditioned inpainting can turn neural surrogates from task-specific predictors into reusable flow priors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes reformulating steady CFD inference as an inpainting task: a self-supervised prior over velocity fields is learned via masked autoencoders and latent flow-matching on velocity fields tokenized by a local neighbourhood tokeniser, without explicit boundary conditions or physics residuals during training. At inference, new boundary constraints and local geometry changes are imposed solely by fixing sparse known velocity patches (e.g., inlet/outlet or unchanged context), enabling full-field reconstruction, improved generalization under BC and dataset shifts, and reusable context on intracranial aneurysm hemodynamics data.
Significance. If the central claims hold, the work could meaningfully advance neural surrogates for CFD by converting them from task-specific forward maps into reusable, context-conditioned flow priors. The local neighbourhood tokeniser is a practical contribution for scaling self-supervised models to high-resolution 3D meshes. The self-supervised training strategy that avoids conditioning on BCs during learning directly targets a known limitation of supervised surrogates.
major comments (2)
- [§3.2] §3.2 (Inference procedure): The method imposes new boundary conditions and geometry edits exclusively by fixing known velocity patches at inference time, yet no mechanism (constrained sampling, projection, or auxiliary loss) is described to guarantee exact matching to the fixed regions or to enforce physical properties such as divergence-free flow. This assumption is load-bearing for the claims of accurate reconstruction from sparse context and stable performance under arbitrary shifts.
- [§4] §4 (Experiments): The reported outperformance over supervised neural surrogates under boundary-condition and dataset shift is stated without accompanying quantitative metrics, baseline specifications, error bars, or ablations on the neighbourhood token size or model components. This weakens the ability to evaluate the strength of the central generalization claim.
minor comments (2)
- [§3.1] The definition and hyperparameter sensitivity of the neighbourhood token size should be expanded with an explicit equation or pseudocode in §3.1 to improve reproducibility.
- A brief discussion of related inpainting or masked-modeling work in physics-informed ML would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of reformulating CFD inference as context-conditioned inpainting. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Inference procedure): The method imposes new boundary conditions and geometry edits exclusively by fixing known velocity patches at inference time, yet no mechanism (constrained sampling, projection, or auxiliary loss) is described to guarantee exact matching to the fixed regions or to enforce physical properties such as divergence-free flow. This assumption is load-bearing for the claims of accurate reconstruction from sparse context and stable performance under arbitrary shifts.
Authors: We agree that the inference procedure section would benefit from greater precision. The manuscript explains that known velocity patches are supplied as unmasked tokens to the latent flow-matching or masked autoencoder model at inference, allowing the generative process to condition on them. However, we acknowledge that an explicit mechanism guaranteeing exact reproduction of the fixed patches is not described. In the revised manuscript we will augment §3.2 with a lightweight post-sampling projection step that overwrites the generated values in the fixed regions with the supplied known velocities, thereby ensuring exact matching without altering the learned prior. With respect to physical properties such as divergence-free flow, the model acquires these properties implicitly through training on physics-consistent data; no auxiliary loss or constrained sampling is applied at inference. We will add a concise discussion of this design choice and its implications, noting that explicit enforcement could be explored as future work (e.g., via a latent-space divergence regularizer). These clarifications strengthen the description while preserving the reported experimental outcomes. revision: partial
-
Referee: [§4] §4 (Experiments): The reported outperformance over supervised neural surrogates under boundary-condition and dataset shift is stated without accompanying quantitative metrics, baseline specifications, error bars, or ablations on the neighbourhood token size or model components. This weakens the ability to evaluate the strength of the central generalization claim.
Authors: We accept the referee’s observation that the experimental presentation requires additional quantitative detail to support the generalization claims. Although comparative results are shown, the manuscript does not provide the full set of metrics, error statistics, baseline descriptions, or component ablations requested. In the revised version we will expand §4 to include: tables reporting relative L2 and velocity-magnitude errors with standard deviations computed over multiple random seeds; explicit specifications of the supervised neural surrogate baselines (architectures, training regimes, and hyper-parameters); and ablation studies varying neighbourhood token size as well as the relative contributions of the masked-autoencoder and latent flow-matching components. These additions will allow readers to assess the strength of the reported improvements under boundary-condition and dataset shifts. revision: yes
Circularity Check
No significant circularity in the self-supervised inpainting formulation
full rationale
The paper trains a self-supervised prior over velocity fields via masked autoencoders and latent flow-matching on tokenized meshes, without BCs or physics residuals in training. Inference imposes new boundary constraints solely by fixing sparse known velocity patches and inpainting the remainder. This does not reduce any claimed result to its inputs by construction: the generative model is not fitted to test-time BC values or meshes, and no derivation step equates a prediction to a training fit or self-citation. Evaluation on held-out aneurysm data with imposed contexts remains an independent empirical test. No self-definitional, fitted-input-renamed-as-prediction, or load-bearing self-citation patterns appear in the central claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- neighbourhood token size
axioms (1)
- domain assumption Steady fluid velocity fields possess statistical structure that can be captured by a self-supervised prior without explicit boundary conditioning during training
invented entities (1)
-
local neighbourhood tokeniser
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we learn a self-supervised prior over velocity fields and impose boundary constraints only during inference by fixing known regions
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
latent flow-matching and masked-autoencoder models on these tokens
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Benedikt Alkin and Maurits Bleeker and Richard Kurle and Tobias Kronlachner and Reinhard Sonnleitner and Matthias Dorfer and Johannes Brandstetter , title =. Trans. Mach. Learn. Res. , volume =. 2025 , url =
work page 2025
-
[2]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
LaB-GATr: geometric algebra transformers for large biomedical surface and volume meshes , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2024 , organization=
work page 2024
-
[3]
arXiv preprint arXiv:2505.14717 , year=
Aneumo: A Large-Scale Multimodal Aneurysm Dataset with Computational Fluid Dynamics Simulations and Deep Learning Benchmarks , author=. arXiv preprint arXiv:2505.14717 , year=
-
[4]
AneuG-Flow: A Large-Scale Synthetic Dataset of Diverse Intracranial Aneurysm Geometries and Hemodynamics , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[5]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
Advances in neural information processing systems , volume=
Pointnet++: Deep hierarchical feature learning on point sets in a metric space , author=. Advances in neural information processing systems , volume=
-
[8]
A foundation model for the Earth system , volume =
Bodnar, Cristian and Bruinsma, Wessel and Lucic, Ana and Stanley, Megan and Allen, Anna and Brandstetter, Johannes and Garvan, Patrick and Riechert, Maik and Weyn, Jonathan and Dong, Haiyu and Gupta, Jayesh and Thambiratnam, Kit and Archibald, Alexander and Wu, Chun-Chieh and Heider, Elizabeth and Welling, Max and Turner, Richard and Perdikaris, Paris , y...
-
[9]
Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics , booktitle =
Jonas Spinner and Victor Bres. Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics , booktitle =. 2024 , url =
work page 2024
-
[10]
Learning nonlinear operators via
Lu, Lu and Jin, Pengzhan and Pang, Guofei and Zhang, Zhongqiang and Karniadakis, George , year =. Learning nonlinear operators via. Nature Machine Intelligence , doi =
-
[11]
Stuart and Anima Anandkumar , title =
Zongyi Li and Nikola Borislavov Kovachki and Kamyar Azizzadenesheli and Burigede Liu and Kaushik Bhattacharya and Andrew M. Stuart and Anima Anandkumar , title =. 9th International Conference on Learning Representations,. 2021 , url =
work page 2021
-
[12]
Transolver++: An Accurate Neural Solver for
Huakun Luo and Haixu Wu and Hang Zhou and Lanxiang Xing and Yichen Di and Jianmin Wang and Mingsheng Long , booktitle=. Transolver++: An Accurate Neural Solver for. 2025 , url=
work page 2025
-
[13]
Benjamin Holzschuh and Georg Kohl and Florian Redinger and Nils Thuerey , booktitle=. 2026 , url=
work page 2026
-
[14]
Fengbo: a Clifford Neural Operator pipeline for 3D
Alberto Pepe and Mattia Montanari and Joan Lasenby , booktitle=. Fengbo: a Clifford Neural Operator pipeline for 3D. 2025 , url=
work page 2025
-
[15]
Turner and Johannes Brandstetter , editor =
Phillip Lippe and Bas Veeling and Paris Perdikaris and Richard E. Turner and Johannes Brandstetter , editor =. PDE-Refiner: Achieving Accurate Long Rollouts with Neural. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
work page 2023
-
[16]
On conditional diffusion models for
Aliaksandra Shysheya and Cristiana Diaconu and Federico Bergamin and Paris Perdikaris and Jos. On conditional diffusion models for. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
work page 2024
-
[17]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[18]
From Zero to Turbulence: Generative Modeling for
Marten Lienen and David L. From Zero to Turbulence: Generative Modeling for. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[19]
Physics-constrained flow matching: Sampling generative models with hard constraints , author=. arXiv preprint arXiv:2506.04171 , year=
-
[20]
The Thirteenth International Conference on Learning Representations,
Mario Lino and Tobias Pfaff and Nils Thuerey , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[21]
Conditional neural field latent diffusion model for generating spatiotemporal turbulence , volume =
Du, Pan and Parikh, Meet and Fan, Xiantao and Liu, Xin-Yang and Wang, Jian-Xun , year =. Conditional neural field latent diffusion model for generating spatiotemporal turbulence , volume =. Nature Communications , doi =
-
[22]
Luning Sun and Xu Han and Han Gao and Jian. Unifying Predictions of Deterministic and Stochastic Physics in Mesh-reduced Space with Sequential Flow Generative Model , booktitle =. 2023 , url =
work page 2023
-
[23]
Drygala, C. and Winhart, B. and di Mare, F. and Gottschalk, H. , title =. Physics of Fluids , volume =. 2022 , month =. doi:10.1063/5.0082562 , url =
-
[24]
Buzzicotti, M. and Bonaccorso, F. and Di Leoni, P. Clark and Biferale, L. , journal =. Reconstruction of turbulent data with deep generative models for semantic inpainting from. 2021 , month =. doi:10.1103/PhysRevFluids.6.050503 , url =
-
[25]
Holzschuh and Qiang Liu and Georg Kohl and Nils Thuerey , editor =
Benjamin J. Holzschuh and Qiang Liu and Georg Kohl and Nils Thuerey , editor =. Forty-second International Conference on Machine Learning,. 2025 , url =
work page 2025
-
[26]
IEEE transactions on image processing , volume=
The farthest point strategy for progressive image sampling , author=. IEEE transactions on image processing , volume=. 1997 , publisher=
work page 1997
-
[27]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Pointnet: Deep learning on point sets for 3d classification and segmentation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[28]
Proceedings of the IEEE international conference on computer vision , pages=
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[29]
Optuna: A next-generation hyperparameter optimization framework , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[30]
Guido Nannini and Simone Saitta and Luca Mariani and Riccardo Maragna and Andrea Baggiano and Saima Mushtaq and Gianluca Pontone and Alberto Redaelli , keywords =. An automated and time-efficient framework for simulation of coronary blood flow under steady and pulsatile conditions , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.cmpb.2024.108415 , url =
-
[31]
Ashton, Neil and Mockett, Charles and Fuchs, Marian and Fliessbach, Louis and Hetmann, Hendrik and Knacke, Thilo and Schonwald, Norbert and Skaperdas, Vangelis and Fotiadis, Grigoris and Walle, Astrid and Hupertz, Burkhard and Maddix, Danielle , year =. DrivAerML: High-Fidelity Computational Fluid Dynamics Dataset for Road-Car External Aerodynamics , doi =
-
[32]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Bj. High-Resolution Image Synthesis with Latent Diffusion Models , booktitle =. 2022 , url =. doi:10.1109/CVPR52688.2022.01042 , timestamp =
-
[33]
Geometry Aware Operator Transformer as an efficient and accurate neural surrogate for
Shizheng Wen and Arsh Kumbhat and Levi Lingsch and Sepehr Mousavi and Yizhou Zhao and Praveen Chandrashekar and Siddhartha Mishra , booktitle=. Geometry Aware Operator Transformer as an efficient and accurate neural surrogate for. 2026 , url=
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.