Recognition: no theorem link
Controlling Transient Amplification Improves Long-horizon Rollouts
Pith reviewed 2026-05-12 01:30 UTC · model grok-4.3
The pith
Non-normal and non-commuting Jacobians along rollout trajectories transiently amplify perturbations and drive long-horizon drift in autoregressive neural simulators, even when the underlying system is stable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the Jacobians along an autoregressive trajectory are non-normal and non-commuting, the model amplifies errors transiently, resulting in model rollout drift even when the overall system is asymptotically stable. A propagator bound quantifies the rollout error under approximate commutativity and normality. Commutativity regularization, implemented via two penalties on the normality defect of individual Jacobians and the commutator norm across steps, reduces this transient amplification and produces accurate long-horizon rollouts over thousands of steps on synthetic and real data without sacrificing short-horizon performance or incurring inference-time overhead.
What carries the argument
Commutativity regularization: a pair of penalties, estimated via Jacobian-vector products, that reduce the normality defect of each Jacobian and the commutator norm between Jacobians at successive time steps.
If this is right
- Regularized models remain in-distribution for thousands of rollout steps on initial conditions where baselines diverge.
- The same penalties improve FourCastNet climate forecasts on ERA5 without requiring additional training data.
- The method applies to both UNet and FNO architectures on 1D and 2D spatio-temporal tasks.
- No extra computation is required at inference time because the penalties are used only during training.
- A propagator bound derived under approximate commutativity and normality directly limits the accumulated rollout error.
Where Pith is reading between the lines
- The same Jacobian-level diagnosis and penalties could be tested on other autoregressive sequence models outside physical simulation, such as video prediction or language-model rollouts.
- If non-normality and non-commutativity prove widespread in trained recurrent or autoregressive networks, Jacobian-normality statistics could become a routine diagnostic alongside loss curves.
- The approach suggests that training objectives focused on operator properties rather than pointwise prediction error may be broadly useful for stabilizing long iterative computations.
- An explicit check for the propagator bound on held-out trajectories would provide a direct, computable certificate of rollout reliability.
Load-bearing premise
Linearization of the nonlinear network around rollout trajectories captures the dominant source of long-horizon error, and the added penalties do not trade off short-horizon accuracy or introduce new instabilities.
What would settle it
Train a model with the proposed penalties until both the normality defect and commutator norm are driven near zero; if long-horizon rollouts still diverge at the same rate as the unregularized baseline, the transient-amplification mechanism does not explain the observed drift.
Figures















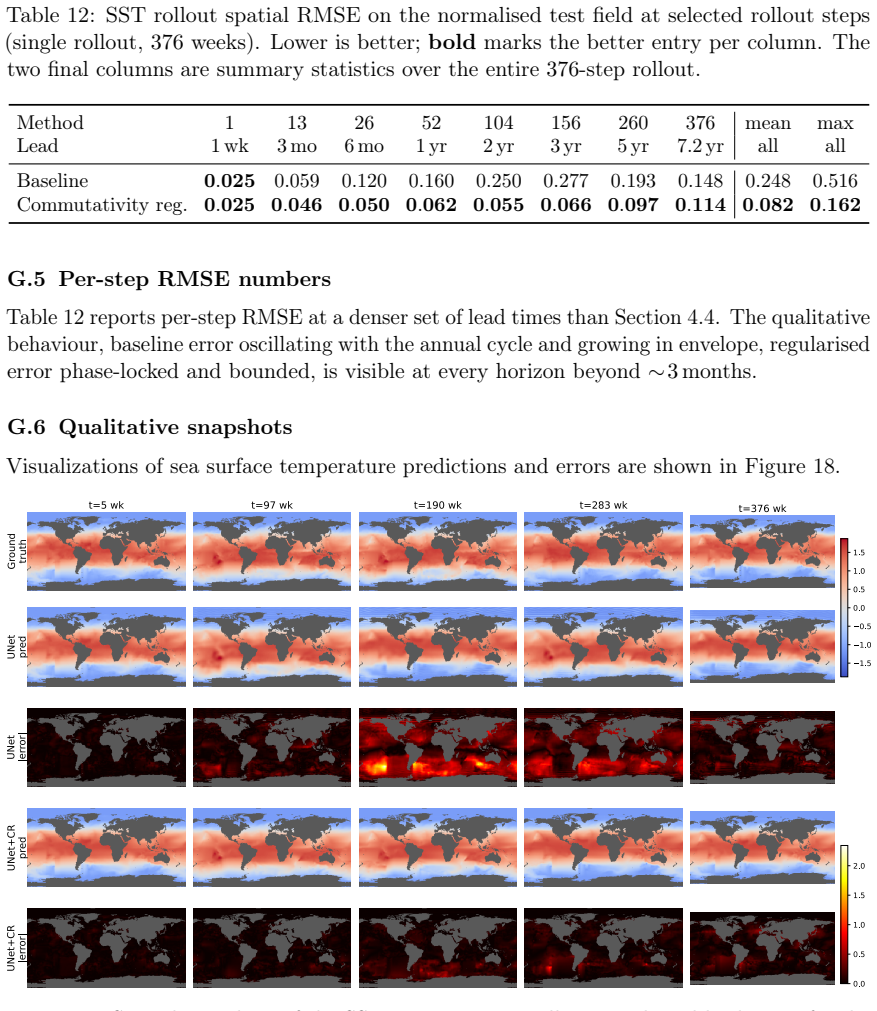
read the original abstract
Autoregressive neural simulators now match classical solvers on short-horizon prediction of physical systems, yet their accuracy degrades rapidly when rolled out over long horizons. In this work, we identify transient amplification of perturbations around rollout trajectories as a structural mechanism driving rollout error. Using a linearization analysis we show that when the Jacobians along an autoregressive trajectory are non-normal and non-commuting, the model amplifies errors transiently, resulting in model rollout drift even when the overall system is asymptotically stable. Building on the analysis, we propose commutativity regularization: a combination of two penalties designed to reduce the normality defect of individual Jacobians and the commutator norm of Jacobians across steps. The penalties are estimated with Jacobian-vector products and have no inference-time cost. We show a propagator bound that quantifies rollout error under approximate commutativity and normality. We evaluate UNet and FNO variants with commutativity regularization on 1D and 2D spatio-temporal data in synthetic and real settings, showing successful long-horizon rollouts over thousands of steps. Further, we show that the method improves FourCastNet climate forecasts on ERA5 without using any new data. The gain is most pronounced out-of-distribution: trained on trajectories of a few hundred steps, regularized models remain in-distribution for thousands of rollout steps on initial conditions where baselines diverge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that transient amplification of perturbations due to non-normal and non-commuting Jacobians along autoregressive trajectories is a key structural driver of long-horizon rollout drift in neural simulators, even when the system is asymptotically stable. It supports this via linearization analysis around trajectories, derives a propagator bound under approximate commutativity and normality, introduces two commutativity regularization penalties (on Jacobian normality defect and cross-step commutator norm) estimated via Jacobian-vector products with no inference-time cost, and reports empirical gains in long-horizon stability for UNet/FNO variants on 1D/2D spatio-temporal tasks plus improved FourCastNet forecasts on ERA5, especially out-of-distribution.
Significance. If the linearization analysis and regularization hold, the work provides a principled, low-overhead mechanism to diagnose and mitigate rollout instability in autoregressive neural models for physical systems. The propagator bound offers theoretical grounding, the JVP-based penalties are practical, and the ERA5 results demonstrate real-world utility without new data. This could meaningfully advance reliable long-term simulation in climate, fluid dynamics, and related domains.
major comments (3)
- [§3] §3 (linearization analysis): the central claim that first-order linearization around rollout trajectories captures the dominant error mechanism requires stronger support in nonlinear networks (UNet/FNO with activations). As perturbations grow beyond the infinitesimal neighborhood, higher-order terms can engage whose stability is uncontrolled by the proposed penalties; a direct comparison of linear vs. nonlinear error growth rates on the same trajectories would test this assumption.
- [§4] §4 (propagator bound): the bound is derived under approximate commutativity and normality, yet the regularization only reduces (does not eliminate) the commutator norm and normality defect. It is unclear whether the residual non-commutativity still permits significant transient amplification or how tight the bound remains in the reported experiments; explicit numerical evaluation of the bound vs. observed error growth is needed.
- [Experiments] Experiments (FourCastNet/ERA5 and UNet/FNO sections): while long-horizon gains are shown, short-horizon accuracy metrics (e.g., 1-step or 10-step RMSE) must be reported with and without regularization to confirm the penalties do not trade off local fidelity or introduce new instabilities, as this is a load-bearing assumption for the method's practicality.
minor comments (3)
- Notation for the two penalties (normality defect and commutator norm) should be defined explicitly with equations rather than described in prose.
- Rollout visualization figures would benefit from error bands over multiple random seeds or initial conditions to demonstrate robustness.
- The related-work discussion should cite prior analyses of non-normal operators and transient growth in dynamical systems (e.g., from numerical linear algebra and fluid dynamics).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the suggested analyses and metrics.
read point-by-point responses
-
Referee: [§3] §3 (linearization analysis): the central claim that first-order linearization around rollout trajectories captures the dominant error mechanism requires stronger support in nonlinear networks (UNet/FNO with activations). As perturbations grow beyond the infinitesimal neighborhood, higher-order terms can engage whose stability is uncontrolled by the proposed penalties; a direct comparison of linear vs. nonlinear error growth rates on the same trajectories would test this assumption.
Authors: We agree that stronger empirical support for the linearization assumption in nonlinear networks is warranted. In the revised manuscript we will add a direct comparison of linear versus nonlinear error growth rates computed on identical rollout trajectories for the UNet and FNO models. This analysis will quantify the relative contribution of higher-order terms during the early phase of perturbation growth and confirm that the first-order terms dominate the transient amplification mechanism addressed by our regularization. revision: yes
-
Referee: [§4] §4 (propagator bound): the bound is derived under approximate commutativity and normality, yet the regularization only reduces (does not eliminate) the commutator norm and normality defect. It is unclear whether the residual non-commutativity still permits significant transient amplification or how tight the bound remains in the reported experiments; explicit numerical evaluation of the bound vs. observed error growth is needed.
Authors: We acknowledge that the tightness of the bound under residual non-commutativity should be verified numerically. In the revised version we will include explicit numerical evaluations of the propagator bound against observed error growth rates across the reported experiments. These comparisons will demonstrate that the achieved levels of approximate commutativity and normality keep transient amplification within the bound’s predictions and that further residual non-commutativity does not produce significant additional drift. revision: yes
-
Referee: [Experiments] Experiments (FourCastNet/ERA5 and UNet/FNO sections): while long-horizon gains are shown, short-horizon accuracy metrics (e.g., 1-step or 10-step RMSE) must be reported with and without regularization to confirm the penalties do not trade off local fidelity or introduce new instabilities, as this is a load-bearing assumption for the method's practicality.
Authors: We will add the requested short-horizon metrics to the revised experiments section. Specifically, we will report 1-step and 10-step RMSE (together with any other relevant local accuracy measures) for all UNet, FNO, and FourCastNet variants, with and without commutativity regularization. These results will confirm that the penalties preserve short-horizon fidelity and do not introduce new instabilities, thereby validating the practicality of the approach. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper derives the propagator bound directly from the linearization of the autoregressive rollout under explicit commutativity and normality assumptions on the Jacobians, without fitting any parameter to the long-horizon error itself. The two commutativity penalties are introduced as novel regularizers estimated via Jacobian-vector products and are not defined in terms of the rollout drift they aim to mitigate. No step in the chain reduces by construction to a fitted input, a self-citation load-bearing premise, or an ansatz smuggled from prior work by the same authors. The empirical results on UNet/FNO and FourCastNet provide external validation outside the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linearization around rollout trajectories accurately reflects the dominant error amplification mechanism in the full nonlinear model.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1038/ s41586-023-06185-3. C. Bodnar, W. P. Bruinsma, A. Lucic, M. Stanley, J. Brandstetter, P. Garvan, M. Riechert, J. Weyn, H. Dong, A. Vaughan, J. K. Gupta, K. Tambiratnam, A. Archibald, E. Heider, M. Welling, R. E. Turner, and P. Perdikaris. Aurora: A foundation model of the atmosphere. arXiv preprint arXiv:2405.13063,
-
[2]
URLhttps://openreview.net/forum?id=MKP1g8wU0P. H. Hersbach, B. Bell, P. Berrisford, S. Hirahara, A. Horányi, J. Muñoz-Sabater, J. Nicolas, C. Peubey, R. Radu, D. Schepers, A. Simmons, C. Soci, S. Abdalla, X. Abellan, G. Balsamo, P. Bechtold, G. Biavati, J. Bidlot, M. Bonavita, G. De Chiara, P. Dahlgren, D. Dee, M. Diamantakis, R. Dragani, J. Flemming, R. ...
work page 1999
-
[3]
doi: https://doi.org/10.1002/qj.3803. URLhttps://rmets.onlinelibrary. wiley.com/doi/abs/10.1002/qj.3803. R. A. Horn and C. R. Johnson.Matrix Analysis. Cambridge University Press, Cambridge,
-
[4]
ISSN 0893-6080. 15 Controlling Transient Amplification Improves Long-horizon Rollouts doi: https://doi.org/10.1016/j.neunet.2026.108641. URL https://www.sciencedirect. com/science/article/pii/S0893608026001036. H.-O. Kreiss. Über die Stäbilitätsdefinition für Differenzengleichungen die partielle Differ- entialgleichungen approximieren.BIT Numerical Mathem...
-
[5]
doi: 10.1007/BF01957346. R. Lam, A. Sanchez-Gonzalez, M. Willson, P. Wirnsberger, M. Fortunato, F. Alet, S. Ravuri, T. Ewalds, Z. Eaton-Rosen, W. Hu, et al. Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421,
-
[6]
doi: 10.1126/science.adi2336. Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anand- kumar. Fourier neural operator for parametric partial differential equations. InInter- national Conference on Learning Representations,
-
[7]
URLhttps://arxiv.org/abs/ 2010.08895. P. Lippe, B. S. Veeling, P. Perdikaris, R. E. Turner, and J. Brandstetter. PDE-refiner: Achieving accurate long rollouts with neural PDE solvers. InThirty-seventh Conference on Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[8]
doi: 10.1016/j.cma.2024.117441
ISSN 0045-7825. doi: 10.1016/j.cma.2024.117441. URLhttps://www.sciencedirect.com/science/article/pii/S0045782524006960. M. McCabe, P. Harrington, S. Subramanian, and J. Brown. Towards stability of autoregressive neural operators.Transactions on Machine Learning Research,
-
[9]
doi: 10.1007/s11071-005-2824-x. A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32,
-
[11]
URLhttps://arxiv.org/abs/ 2202.11214. T. Pfaff, M. Fortunato, A. Sanchez-Gonzalez, and P. W. Battaglia. Learning mesh-based simulation with graph networks. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review arXiv
-
[12]
doi: 10.1175/1520-0442(2002)015<1609:AIISAS>2.0.CO;2. O. Ronneberger, P. Fischer, and T. Brox. U-Net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention (MICCAI), pages 234–241,
-
[13]
doi: 10.1007/978-3-319-24574-4_28. W. J. Rugh.Nonlinear system theory. Johns Hopkins University Press Baltimore,
-
[14]
doi: 10.1146/annurev.fluid.38.050304.092139. D. Scieur, G. Gidel, Q. Bertrand, and F. Pedregosa. The curse of unrolling: Rate of differentiating through optimization. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, editors,Advances in Neural Information Processing Systems,
-
[15]
doi: 10.1126/science.261.5121.578. M. O. Williams, I. G. Kevrekidis, and C. W. Rowley. A data-driven approximation of the Koopman operator: Extending dynamic mode decomposition.Journal of Nonlinear Science, 25(6):1307–1346,
-
[16]
Alexander D Wilson, Joshua A Schultz, and Todd D Murphey
doi: 10.1007/s00332-015-9258-5. 17 Controlling Transient Amplification Improves Long-horizon Rollouts Appendix A. Proof of theorem 2.1 We first record the exact result when the Jacobians commute and are individually normal. Proposition A.1(Exact commuting case).Let J0, . . . , JT−1 ∈R n×n be simultaneously diagonalisable as Jt = UΛtU ⊤ for a common orthog...
-
[17]
When ε = η = 0, each Jt is normal and all pairs commute
Proof. When ε = η = 0, each Jt is normal and all pairs commute. Commuting normal matrices are simultaneously diagonalizable by a common orthogonal matrix (Horn and Johnson, 1985), giving∥ΦT ∥2 ≤ρ T by Proposition A.1. For ε, η > 0, the joint conditions (iii)–(iv) imply that{Jt} lies within distanceδ(ε, η) of the closed set of simultaneously orthogonally d...
work page 1985
-
[18]
with a single denoising network conditioned on the previous state, the current (noisy) prediction, and a step index k∈ { 0, . . . , M}. The backbone is identical to the UNet above; we useM = 4 refinement iterations per rollout step and the geometric noise schedule of Lippe et al. (2023) with σmin = 10−7. PDE-Refiner therefore costsM+1 = 5× backbone evalua...
work page 2023
-
[19]
but is overtaken by both alternatives by step∼100and is more than an order of magnitude worse than UNet+CR already inside the training window (step200). PDE-Refiner is the strongest unregularisedmodel up to step ∼1000, paying5 × inference-time cost; from step ∼2000 onwards UNet+CR overtakes it on both the in-distribution and the out-of-distribution split....
work page 2000
-
[20]
F.1 Data and preprocessing Source.ERA5 reanalysis on FCN’s native20-channel state at721×1440(0 .25◦,∆ t = 6h): 10m winds( u10, v10),2m temperature t2m, surface and mean-sea-level pressures(sp,msl ), T at850hPa, winds at1000/850/500hPa, geopotential at1000/850/500/50hPa, relative humidity at500/850hPa, T at500hPa, and total column water vapourtcwv. We use ...
work page 2015
-
[21]
Optimiser AdamW Peak learning rate5×10 −6 Weight decay0 Schedule cosine annealing Epochs50 Batch size2(single-GPU, A10080GB) Loss (one-step) latitude-weighted MSE between ˆXt+1 and ERA5 Regulariser latent comm. + normality λc 10−5 λn 10−5 JVP frequency every minibatch (comm_freq=1) Skip blocks first10AFNO blocks detached (comm_skip_blocks=10) Comm. pair a...
-
[22]
The version we use contains1727weeks beginning in
G.1 Data and preprocessing Source.NOAA Optimum Interpolation Sea-Surface Temperature, weekly-mean product (sst.wkmean.1990-present) (Reynolds et al., 2002), covering the global ocean on a1◦ (180×360) grid at weekly cadence. The version we use contains1727weeks beginning in
work page 1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.