Recognition: no theorem link
RareCP: Regime-Aware Retrieval for Efficient Conformal Prediction
Pith reviewed 2026-05-12 01:24 UTC · model grok-4.3
The pith
RareCP retrieves top-k past residuals weighted by regime-specific attention experts to form tighter conformal prediction intervals for drifting time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
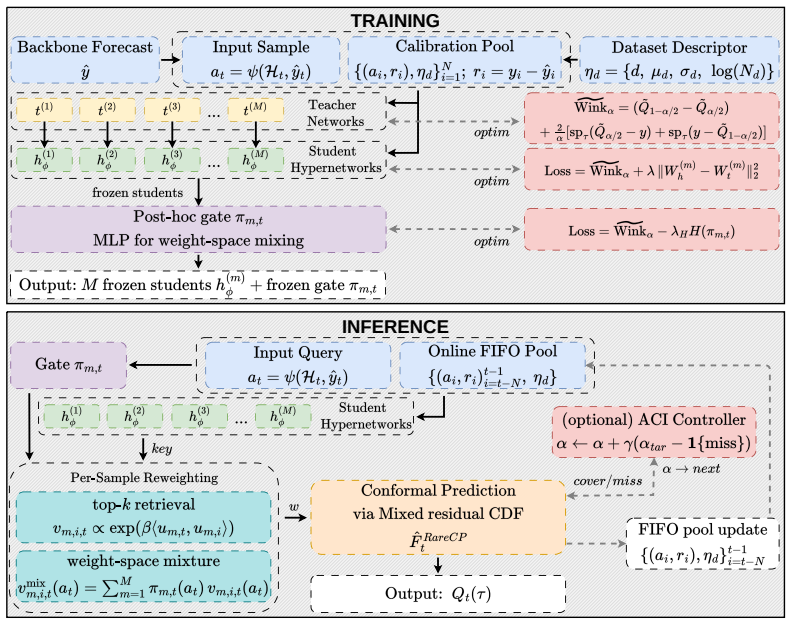
RareCP learns local calibration representations through a mixture of cosine-attention experts that each capture distinct error regimes, while a compact hypernetwork adapts the kernel parameters to track temporal drift. Given a new forecasting context, it retrieves the top-k most relevant calibration examples, assigns similarity weights, and forms a weighted conformal quantile over their signed residuals, yielding asymmetric prediction intervals. The adaptive kernel is trained using a smooth interval score objective with a parameter-space anchor to a lightweight teacher kernel.
What carries the argument
Mixture of cosine-attention experts that separate error regimes, paired with a hypernetwork for drift adaptation and top-k retrieval to weight residuals for the conformal quantile.
If this is right
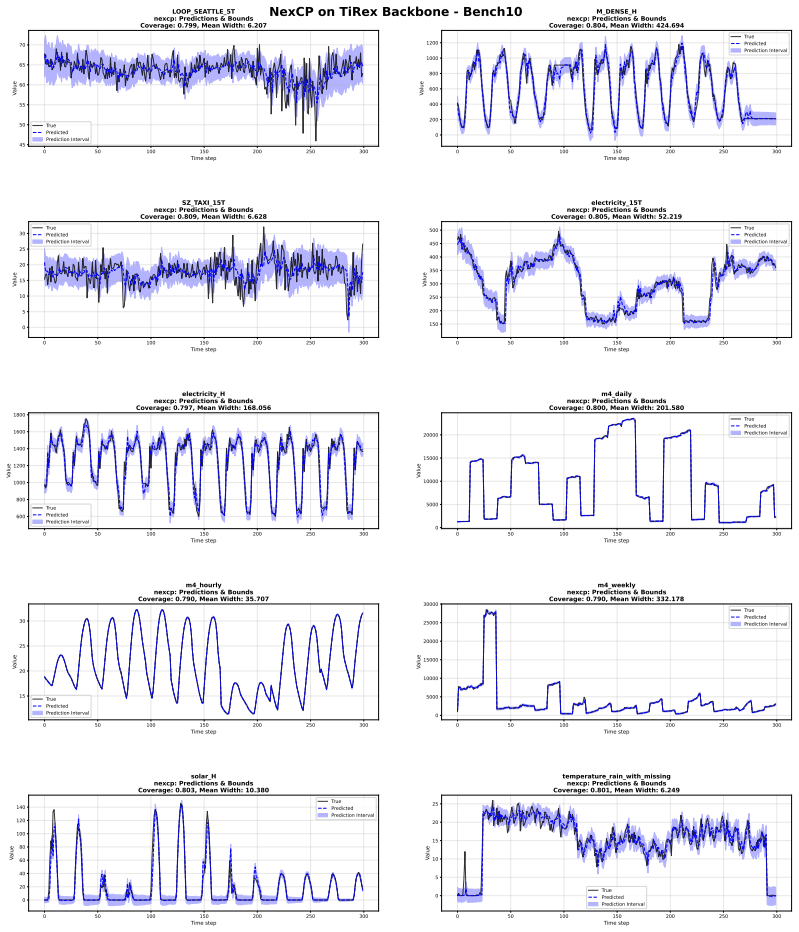
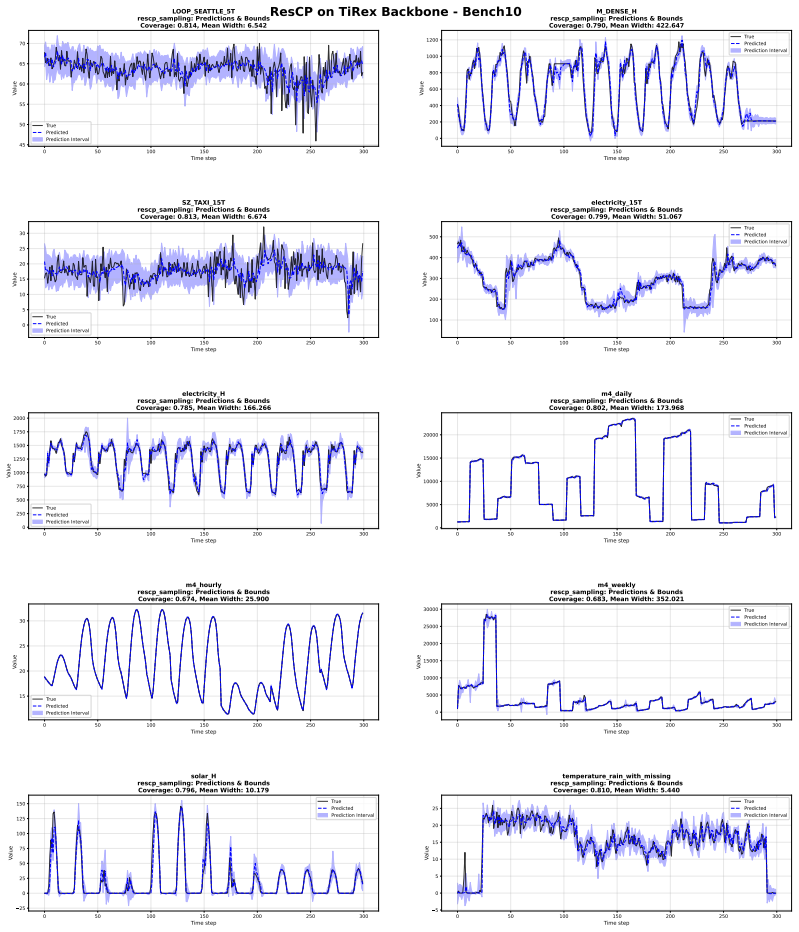
- Interval efficiency improves over recent conformal baselines and foundation-model uncertainty estimates on the GIFT-Eval benchmark.
- Empirical coverage is maintained at the nominal level.
- Ablations show separate gains from regime-specific experts, drift-adaptive kernels, sparse retrieval, and teacher anchoring.
- The method produces asymmetric intervals that adapt to local context rather than global or sliding-window statistics.
Where Pith is reading between the lines
- The same retrieval-plus-experts pattern could be tested on other online learning settings where error regimes shift abruptly, such as anomaly detection streams.
- If regime separation proves stable, the approach might reduce the frequency of full recalibration needed in production forecasting pipelines.
- One could check whether the learned expert weights themselves serve as interpretable indicators of which error regime is active at any moment.
- Applying the method to multivariate series or to settings with known external regime triggers would test how far the cosine-attention separation generalizes.
Load-bearing premise
Distinct error regimes exist in the data and the mixture of cosine-attention experts can reliably separate them so that retrieved residuals remain relevant for the weighted quantile even when drift occurs.
What would settle it
On a time series dataset with documented regime shifts, remove the expert mixture and measure whether interval width improves by less than the reported margin over baselines while empirical coverage stays at the target level.
Figures

















read the original abstract
Recent advances in uncertainty quantification for time series forecasting show that conformal prediction can provide reliable prediction intervals, yet standard conformal methods are often inefficient under temporal dependence, drift, and heterogeneous error behavior. Existing methods typically either update miscoverage rates over time or learn unconstrained calibration weights, without explicitly separating two central sources of nonstationarity: smoothly drifting error distributions and co-existing distinct error regimes. We introduce RareCP, a regime-aware retrieval method for adaptive conformal time series prediction. RareCP learns local calibration representations through a mixture of cosine-attention experts that each capture distinct error regimes, while a compact hypernetwork adapts the kernel parameters to track temporal drift. Given a new forecasting context, RareCP retrieves the top-k most relevant calibration examples, assigns similarity weights, and forms a weighted conformal quantile over their signed residuals, yielding asymmetric prediction intervals. The adaptive kernel is trained using a smooth interval score objective, with a parameter-space anchor to a lightweight teacher kernel to preserve stable local representations. On the GIFT-Eval benchmark, RareCP improves interval efficiency over recent conformal baselines and foundation model uncertainty estimates while maintaining empirical coverage. Ablations confirm that regime-specific experts, drift-adaptive kernels, sparse retrieval, and teacher anchoring each contribute to the final performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RareCP, a regime-aware retrieval method for adaptive conformal prediction in time series forecasting. It learns local calibration representations via a mixture of cosine-attention experts to capture distinct error regimes, employs a compact hypernetwork to adapt kernel parameters for temporal drift, and retrieves the top-k most similar past calibration examples to compute similarity-weighted conformal quantiles over signed residuals, producing asymmetric prediction intervals. The adaptive kernel is trained with a smooth interval score objective and a parameter-space anchor to a teacher kernel. On the GIFT-Eval benchmark, RareCP is claimed to improve interval efficiency over recent conformal baselines and foundation model uncertainty estimates while maintaining empirical coverage, with ablations indicating that each component (regime experts, drift adaptation, sparse retrieval, teacher anchoring) contributes to performance.
Significance. If the empirical gains are robust and the regime separation proves meaningful rather than incidental, RareCP would offer a concrete advance in handling both smooth drift and heterogeneous error regimes within conformal prediction for dependent data, potentially yielding more efficient intervals than purely adaptive miscoverage or unconstrained weighting approaches without sacrificing validity guarantees.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and associated ablations: the central efficiency claim on GIFT-Eval rests on benchmark improvements, yet the manuscript provides no error bars, exact train/calibration/test splits, or statistical significance tests comparing RareCP to baselines. This gap prevents verification that the reported interval-length reductions are reliable rather than artifacts of benchmark variability.
- [Ablation studies (Experiments section)] Ablation studies (Experiments section): the paper states that ablations confirm the contribution of regime-specific experts, but supplies no quantitative diagnostics of regime separation quality such as expert assignment entropy, inter-regime residual divergence, or cluster stability metrics. Without such measures, it remains unclear whether the cosine-attention mixture isolates stable error regimes or merely fits spurious correlations, which directly bears on whether the weighted-quantile efficiency gains follow from the regime-aware design.
minor comments (2)
- [Method section] The description of the hypernetwork and teacher-kernel anchor in the method section would benefit from an explicit equation or pseudocode showing how the parameter-space regularization is applied during training.
- [Method section] Notation for the similarity weights and weighted quantile could be clarified with a single consolidated equation rather than scattered references across paragraphs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important aspects of empirical rigor and interpretability that we will address to strengthen the manuscript. We respond to each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated ablations: the central efficiency claim on GIFT-Eval rests on benchmark improvements, yet the manuscript provides no error bars, exact train/calibration/test splits, or statistical significance tests comparing RareCP to baselines. This gap prevents verification that the reported interval-length reductions are reliable rather than artifacts of benchmark variability.
Authors: We agree that the lack of error bars, explicit splits, and significance testing reduces the ability to verify the reliability of the reported efficiency gains. In the revised version, we will explicitly document the train/calibration/test splits for every dataset in the GIFT-Eval benchmark. We will also recompute and report interval efficiency as mean ± standard deviation over multiple random seeds for calibration-set construction. Finally, we will add paired statistical tests (Wilcoxon signed-rank) with p-values to compare RareCP against each baseline. These updates will appear in Section 4 and the associated tables. revision: yes
-
Referee: [Ablation studies (Experiments section)] Ablation studies (Experiments section): the paper states that ablations confirm the contribution of regime-specific experts, but supplies no quantitative diagnostics of regime separation quality such as expert assignment entropy, inter-regime residual divergence, or cluster stability metrics. Without such measures, it remains unclear whether the cosine-attention mixture isolates stable error regimes or merely fits spurious correlations, which directly bears on whether the weighted-quantile efficiency gains follow from the regime-aware design.
Authors: We acknowledge that the current ablation results, while showing performance degradation when experts are removed, do not include direct diagnostics of regime quality. In the revision we will augment the ablation subsection with the requested metrics: average entropy of expert assignment weights across calibration examples (to quantify specialization), Wasserstein distance between signed-residual distributions of different experts (to measure inter-regime divergence), and a simple stability check by re-running assignments on held-out calibration windows. These additions will provide quantitative support that the observed efficiency gains arise from meaningful regime separation rather than spurious fitting. revision: yes
Circularity Check
Low circularity: empirical benchmark gains rest on external evaluation rather than self-referential derivations
full rationale
The paper's central claim is an empirical improvement in interval efficiency on the external GIFT-Eval benchmark while preserving coverage. The method combines a mixture of cosine-attention experts, a hypernetwork for drift adaptation, top-k retrieval, and a smooth interval score objective with teacher anchoring. These are design and training choices whose outputs are evaluated against independent baselines and foundation model estimates; no equation or component reduces the reported performance metric to a fitted input by construction. Ablations are mentioned but serve as supporting evidence rather than a closed loop. Minor self-citation risk exists in related conformal literature but is not load-bearing for the benchmark result, yielding only a low score of 2.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of experts
- retrieval k
axioms (1)
- domain assumption Weighted conformal prediction yields valid coverage when weights are derived from similarity to the test context
Reference graph
Works this paper leans on
-
[1]
Electricity price forecasting: A review of the state of the art and outlook
Rafal Weron. Electricity price forecasting: A review of the state of the art and outlook. International Journal of Forecasting, 2014
work page 2014
-
[2]
Vladimir V ovk, Alex Gammerman, and Glenn Shafer.Algorithmic Learning in a Random World. 01 2005. doi: 10.1007/b106715
-
[3]
Adaptive conformal predictions for time series, 2022
Margaux Zaffran, Aymeric Dieuleveut, Olivier Féron, Yannig Goude, and Julie Josse. Adaptive conformal predictions for time series, 2022. URLhttps://arxiv.org/abs/2202.07282
-
[4]
Conformal prediction interval for dynamic time-series
Chen Xu and Yao Xie. Conformal prediction interval for dynamic time-series. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 11559–11569. PMLR, 18–24 Jul 2021. URLhttps://proceedings.mlr.press/v139/xu21h.html
work page 2021
-
[5]
A tutorial on conformal prediction, 2007
Glenn Shafer and Vladimir V ovk. A tutorial on conformal prediction, 2007. URL https: //arxiv.org/abs/0706.3188
-
[6]
Tibshirani, and Larry Wasserman
Jing Lei, Max G’Sell, Alessandro Rinaldo, Ryan J. Tibshirani, and Larry Wasserman. Distribution-free predictive inference for regression, 2017. URL https://arxiv.org/abs/ 1604.04173
-
[7]
Cross-conformal predictors, 2012
Vladimir V ovk. Cross-conformal predictors, 2012. URL https://arxiv.org/abs/1208. 0806
work page 2012
-
[8]
Candes, Aaditya Ramdas, and Ryan J
Rina Foygel Barber, Emmanuel J. Candes, Aaditya Ramdas, and Ryan J. Tibshirani. Predictive inference with the jackknife+, 2020. URLhttps://arxiv.org/abs/1905.02928
-
[9]
Stable conformal prediction sets
Eugene Ndiaye. Stable conformal prediction sets. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th Inter- national Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 16462–16479. PMLR, 17–23 Jul 2022. URL https://proceedings.mlr. press/v...
work page 2022
-
[10]
Efficient conformal prediction via cascaded inference with expanded admission, 2021
Adam Fisch, Tal Schuster, Tommi Jaakkola, and Regina Barzilay. Efficient conformal prediction via cascaded inference with expanded admission, 2021. URL https://arxiv.org/abs/ 2007.03114
-
[11]
Selection and aggregation of conformal prediction sets, 2024
Yachong Yang and Arun Kumar Kuchibhotla. Selection and aggregation of conformal prediction sets, 2024. URLhttps://arxiv.org/abs/2104.13871
-
[12]
Classification with valid and adaptive coverage
Yaniv Romano, Matteo Sesia, and Emmanuel Candes. Classification with valid and adaptive coverage. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 3581–3591. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 244edd7e85...
work page 2020
-
[13]
Improved online conformal prediction via strongly adaptive online learning, 2023
Aadyot Bhatnagar, Huan Wang, Caiming Xiong, and Yu Bai. Improved online conformal prediction via strongly adaptive online learning, 2023. URL https://arxiv.org/abs/2302. 07869
work page 2023
-
[14]
Conformalized quantile regression
Yaniv Romano, Evan Patterson, and Emmanuel Candes. Conformalized quantile regression. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, ed- itors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/ 5103c3584b063c431b...
work page 2019
-
[15]
Conformal prediction using decision trees
Ulf Johansson, Henrik Boström, and Tuve Löfström. Conformal prediction using decision trees. 12 2013. doi: 10.1109/ICDM.2013.85
-
[16]
Johansson, Henrik Boström, Tuwe Löfström, and Henrik Linusson
U. Johansson, Henrik Boström, Tuwe Löfström, and Henrik Linusson. Regression conformal prediction with random forests.Machine Learning, 97:155 – 176, 2014. URL https://api. semanticscholar.org/CorpusID:14015369. 11
work page 2014
-
[17]
Learning optimal conformal classifiers, 2022
David Stutz, Krishnamurthy, Dvijotham, Ali Taylan Cemgil, and Arnaud Doucet. Learning optimal conformal classifiers, 2022. URLhttps://arxiv.org/abs/2110.09192
-
[18]
Efficient and differentiable conformal prediction with general function classes, 2022
Yu Bai, Song Mei, Huan Wang, Yingbo Zhou, and Caiming Xiong. Efficient and differentiable conformal prediction with general function classes, 2022. URL https://arxiv.org/abs/ 2202.11091
-
[19]
Ran Xie, Rina Foygel Barber, and Emmanuel J. Candès. Boosted conformal prediction intervals,
- [20]
-
[21]
Candes, Aaditya Ramdas, and Ryan J
Rina Foygel Barber, Emmanuel J. Candes, Aaditya Ramdas, and Ryan J. Tibshirani. Conformal prediction beyond exchangeability, 2023. URLhttps://arxiv.org/abs/2202.13415
-
[22]
Adaptive conformal inference under distribution shift
Isaac Gibbs and Emmanuel Candes. Adaptive conformal inference under distribution shift. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 1660–1672. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/ 2021/file/0d441d...
work page 2021
-
[23]
Conformal inference for online prediction with arbitrary distribution shifts, 2023
Isaac Gibbs and Emmanuel Candès. Conformal inference for online prediction with arbitrary distribution shifts, 2023. URLhttps://arxiv.org/abs/2208.08401
-
[24]
Conformal pid control for time series prediction
Anastasios Angelopoulos, Emmanuel Candes, and Ryan J Tibshirani. Conformal pid control for time series prediction. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 23047–23074. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/ pa...
work page 2023
-
[25]
Tibshirani, Rina Foygel Barber, Emmanuel J
Ryan J. Tibshirani, Rina Foygel Barber, Emmanuel J. Candes, and Aaditya Ramdas. Conformal prediction under covariate shift, 2020. URLhttps://arxiv.org/abs/1904.06019
-
[26]
Distribution-free uncertainty quantification for classification under label shift, 2021
Aleksandr Podkopaev and Aaditya Ramdas. Distribution-free uncertainty quantification for classification under label shift, 2021. URLhttps://arxiv.org/abs/2103.03323
-
[27]
Kernel-based optimally weighted conformal time-series prediction, 2026
Jonghyeok Lee, Chen Xu, and Yao Xie. Kernel-based optimally weighted conformal time-series prediction, 2026. URLhttps://arxiv.org/abs/2405.16828
-
[28]
Conformal prediction for time series with modern hopfield networks, 2023
Andreas Auer, Martin Gauch, Daniel Klotz, and Sepp Hochreiter. Conformal prediction for time series with modern hopfield networks, 2023. URLhttps://arxiv.org/abs/2303.12783
-
[29]
Predictive inference with feature conformal prediction, 2023
Jiaye Teng, Chuan Wen, Dinghuai Zhang, Yoshua Bengio, Yang Gao, and Yang Yuan. Predictive inference with feature conformal prediction, 2023. URL https://arxiv.org/abs/2210. 00173
work page 2023
-
[30]
Conformalized time series with semantic features
Baiting Chen, Zhimei Ren, and Lu Cheng. Conformalized time series with semantic features. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems, volume 37, pages 121449–121474. Curran Associates, Inc., 2024. doi: 10.52202/079017-3859
-
[31]
Adaptive conformal prediction via mixture-of-experts gating similarity
Jingsen Kong, Wenlu Tang, Dezheng Kong, Linglong Kong, Guangren Yang, and Bei Jiang. Adaptive conformal prediction via mixture-of-experts gating similarity. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=vCmnu4q8C3
work page 2026
-
[32]
Sequential predictive conformal inference for time series, 2023
Chen Xu and Yao Xie. Sequential predictive conformal inference for time series, 2023. URL https://arxiv.org/abs/2212.03463
-
[33]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021. URL https://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Retrieval augmented time series forecasting, 2025
Sungwon Han, Seungeon Lee, Meeyoung Cha, Sercan O Arik, and Jinsung Yoon. Retrieval augmented time series forecasting, 2025. URLhttps://arxiv.org/abs/2505.04163. 12
-
[35]
Kanghui Ning, Zijie Pan, Yu Liu, Yushan Jiang, James Yiming Zhang, Kashif Rasul, Anderson Schneider, Lintao Ma, Yuriy Nevmyvaka, and Dongjin Song. Ts-rag: Retrieval-augmented generation based time series foundation models are stronger zero-shot forecaster, 2025. URL https://arxiv.org/abs/2503.07649
-
[36]
Retrieval based time series forecasting, 2022
Baoyu Jing, Si Zhang, Yada Zhu, Bin Peng, Kaiyu Guan, Andrew Margenot, and Hanghang Tong. Retrieval based time series forecasting, 2022. URL https://arxiv.org/abs/2209.13525
-
[37]
Retrieval-augmented diffusion models for time series forecasting, 2024
Jingwei Liu, Ling Yang, Hongyan Li, and Shenda Hong. Retrieval-augmented diffusion models for time series forecasting, 2024. URLhttps://arxiv.org/abs/2410.18712
-
[38]
Timerag: Boosting llm time series forecasting via retrieval-augmented generation, 2024
Silin Yang, Dong Wang, Haoqi Zheng, and Ruochun Jin. Timerag: Boosting llm time series forecasting via retrieval-augmented generation, 2024. URL https://arxiv.org/abs/2412. 16643
work page 2024
-
[39]
David Ha, Andrew M. Dai, and Quoc V . Le. Hypernetworks.CoRR, abs/1609.09106, 2016. URLhttp://arxiv.org/abs/1609.09106
work page internal anchor Pith review arXiv 2016
-
[40]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catas- trophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):352...
-
[41]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc' Aurelio Ranzato. Gradient episodic memory for continual learning. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/ f87...
work page 2017
-
[42]
Johannes von Oswald, Christian Henning, Benjamin F. Grewe, and João Sacramento. Continual learning with hypernetworks, 2020. URLhttps://arxiv.org/abs/1906.00695
-
[43]
Personalized federated learning using hypernetworks, 2021
Aviv Shamsian, Aviv Navon, Ethan Fetaya, and Gal Chechik. Personalized federated learning using hypernetworks, 2021. URLhttps://arxiv.org/abs/2103.04628
-
[44]
Distilling the knowledge in a neural network,
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network,
-
[45]
URLhttps://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
FitNets: Hints for Thin Deep Nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets, 2015. URL https://arxiv.org/abs/ 1412.6550
work page internal anchor Pith review arXiv 2015
-
[47]
Gift-eval: A benchmark for general time series forecasting model evaluation,
Taha Aksu, Gerald Woo, Juncheng Liu, Xu Liu, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. Gift-eval: A benchmark for general time series forecasting model evaluation,
- [48]
- [49]
-
[50]
Bronstein, and Filippo Maria Bianchi
Roberto Neglia, Andrea Cini, Michael M. Bronstein, and Filippo Maria Bianchi. ResCP: Reser- voir Conformal Prediction for Time Series Forecasting.arXiv e-prints, art. arXiv:2510.05060, October 2025. doi: 10.48550/arXiv.2510.05060
-
[51]
Tirex: Zero-shot forecasting across long and short horizons with enhanced in-context learning, 2025
Andreas Auer, Patrick Podest, Daniel Klotz, Sebastian Böck, Günter Klambauer, and Sepp Hochreiter. Tirex: Zero-shot forecasting across long and short horizons with enhanced in-context learning, 2025. URLhttps://arxiv.org/abs/2505.23719
-
[52]
Chronos: Learning the Language of Time Series
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Yuyang Wang. Chronos: Learning the language ...
work page internal anchor Pith review arXiv 2024
-
[53]
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers, 2024. URL https: //arxiv.org/abs/2402.02592
-
[54]
A decoder-only foundation model for time-series forecasting.arXiv preprint arXiv:2310.10688, 2023
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting, 2024. URLhttps://arxiv.org/abs/2310.10688
-
[55]
B., M \"u ller, S., Salinas, D., and Hutter, F
Shi Bin Hoo, Samuel Müller, David Salinas, and Frank Hutter. From Tables to Time: Extending TabPFN-v2 to Time Series Forecasting.arXiv e-prints, art. arXiv:2501.02945, January 2025. doi: 10.48550/arXiv.2501.02945
-
[56]
Toto: Time series optimized transformer for observability, 2024
Ben Cohen, Emaad Khwaja, Kan Wang, Charles Masson, Elise Ramé, Youssef Doubli, and Othmane Abou-Amal. Toto: Time series optimized transformer for observability, 2024. URL https://arxiv.org/abs/2407.07874
-
[57]
Lag-llama: Towards foundation models for probabilistic time series forecasting, 2024
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Hena Ghonia, Rishika Bhagwatkar, Arian Khorasani, Mohammad Javad Darvishi Bayazi, George Adamopoulos, Roland Riachi, Nadhir Hassen, Marin Biloš, Sahil Garg, Anderson Schneider, Nicolas Chapados, Alexandre Drouin, Valentina Zantedeschi, Yuriy Nevmyvaka, and Irina Rish. Lag-llama: Towards foundation models ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.