Recognition: 2 theorem links
· Lean TheoremCompact SO(3) Equivariant Atomistic Foundation Models via Structural Pruning
Pith reviewed 2026-05-12 01:38 UTC · model grok-4.3
The pith
Structural pruning of SO(3) equivariant atomistic models yields compact versions that outperform small models trained from scratch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that block-wise pruning along the channel and order dimensions of SO(3) equivariant layers, starting from a large checkpoint, produces a compressed model that retains full equivariance and exceeds the accuracy of a from-scratch small model of similar size. This is evidenced by the pruned MACE-MP model outperforming the official small model on seven of nine Matbench Discovery metrics, with 1.5 to 4 times fewer parameters and 2.5 to 4 times less pre-training compute.
What carries the argument
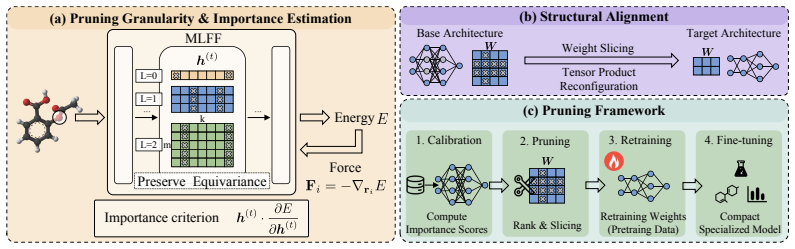
Block-wise structural pruning of irreducible representations along channel and order dimensions to preserve SO(3) equivariance while reducing model size.
If this is right
- Pruned models use 1.5× to 4× fewer parameters than training small models from scratch.
- Pre-training compute is reduced by 2.5× to 4× compared to training small models.
- Fine-tuning the pruned model lowers energy errors by 70.1% and force errors by 34.4% versus scratch-trained task-specific models.
- The pruning generalizes to other SO(3) equivariant architectures including SevenNet and eSCN.
- It combines effectively with quantization and knowledge distillation for further efficiency gains.
Where Pith is reading between the lines
- This approach suggests that training large equivariant models and then pruning may be more effective than directly training small ones for achieving high performance at low inference cost.
- Adopting this pruning could substantially lower the computational resources needed to develop and deploy atomistic AI models for materials science applications.
- Similar block-pruning strategies might transfer to other symmetry-aware neural networks, enabling compact versions without retraining from scratch.
Load-bearing premise
Removing blocks of irreducible representations from a large model preserves enough expressive power for the pruned version to outperform a small model trained from scratch.
What would settle it
If an independently trained small model achieves comparable or better performance than the pruned large-to-small model on the Matbench Discovery leaderboard metrics, the advantage of pruning would not hold.
Figures



read the original abstract
SO(3) equivariant graph neural networks have become the dominant paradigm for atomistic foundation models, achieving high accuracy and data efficiency by building rotational symmetry directly into the architecture. Yet the computational cost of their higher-order tensor operations creates a tough trade-off between model accuracy and inference efficiency. In this paper, we propose a structural pruning method for SO(3) equivariant atomistic foundation models to bridge this accuracy-efficiency gap. The pruning is applied along the channel and order dimensions, with each irreducible representation kept or removed as a complete block, thereby retaining SO(3) equivariance. Starting from a large checkpoint, the pruned model substantially reduces the inference cost while retaining higher accuracy than an independently trained small model. The pruned MACE-MP model outperforms the official from-scratch trained small model on 7 of 9 metrics on the Matbench Discovery leaderboard. In terms of efficiency, compressed MACE-MP and MACE-OFF models contain 1.5$\times$ to 4$\times$ fewer parameters and require 2.5$\times$ to 4$\times$ less pre-training compute than training a small model from scratch. For downstream applications, fine-tuning the pruned model reduces energy and force errors by 70.1% and 34.4% compared to training task-specific models from scratch across eight representative downstream datasets. We demonstrate that the method generalizes to other SO(3) equivariant architectures (SevenNet, eSCN) and can be combined with quantization and knowledge distillation for further gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a structural pruning method for SO(3) equivariant graph neural networks in atomistic foundation models (e.g., MACE-MP, MACE-OFF). Pruning is performed along channel and order dimensions by removing entire irreducible representation blocks to preserve equivariance. Starting from large pre-trained checkpoints, the resulting compact models reduce inference cost while achieving higher accuracy than independently trained small models of comparable size; the pruned MACE-MP outperforms the official from-scratch small model on 7 of 9 Matbench Discovery metrics. Additional claims include 1.5–4× parameter reduction and 2.5–4× lower pre-training compute versus training small models from scratch, plus gains from fine-tuning on eight downstream datasets and generalization to SevenNet and eSCN, with optional combination with quantization and distillation.
Significance. If the empirical claims hold under rigorous verification, the work would be significant for practical deployment of equivariant atomistic models, as it offers a way to obtain compact high-accuracy models without the full cost of training small architectures from scratch. The direct comparison against official from-scratch baselines on a public leaderboard (Matbench Discovery) and the reported fine-tuning improvements are strengths. The method's applicability across multiple SO(3)-equivariant architectures is also a positive aspect.
major comments (3)
- [Methods] Methods section: The pruning criterion for selecting which irreducible-representation blocks to remove (along channels or orders) is not specified with an equation or algorithm; it is unclear whether selection uses weight magnitude, activation statistics, or another importance measure. This is load-bearing for the central claim that the pruned model retains sufficient expressive power to outperform a from-scratch small model.
- [Results] Results on Matbench Discovery (Table reporting 7/9 metrics): No error bars, standard deviations across random seeds, or statistical significance tests are provided for the performance differences versus the official small model. Without these, it is impossible to determine whether the reported outperformance is reliable or could be explained by training variance.
- [Experiments] Ablation studies (if present) or Experiments section: There are no ablations varying the pruning ratio, comparing channel-only vs. order-only pruning, or contrasting the chosen criterion against random block removal. Such controls are required to substantiate that the specific structural pruning preserves task-critical tensor-product paths better than training a small model from scratch.
minor comments (2)
- [Abstract] Abstract: The efficiency statements (1.5×–4× fewer parameters, 2.5×–4× less pre-training compute) would be clearer if the exact pre- and post-pruning parameter counts and FLOPs for each model (MACE-MP, MACE-OFF) were stated explicitly.
- [Methods] Notation: The paper uses 'irreducible representations' and 'blocks' interchangeably in places; a short glossary or consistent definition in the methods would improve readability for readers less familiar with SO(3) equivariant tensor products.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen clarity and rigor.
read point-by-point responses
-
Referee: [Methods] Methods section: The pruning criterion for selecting which irreducible-representation blocks to remove (along channels or orders) is not specified with an equation or algorithm; it is unclear whether selection uses weight magnitude, activation statistics, or another importance measure. This is load-bearing for the central claim that the pruned model retains sufficient expressive power to outperform a from-scratch small model.
Authors: The referee is correct; the manuscript describes block removal to preserve equivariance but does not provide an explicit equation or algorithm for the selection criterion. We will add a precise mathematical formulation and pseudocode in the revised Methods section. revision: yes
-
Referee: [Results] Results on Matbench Discovery (Table reporting 7/9 metrics): No error bars, standard deviations across random seeds, or statistical significance tests are provided for the performance differences versus the official small model. Without these, it is impossible to determine whether the reported outperformance is reliable or could be explained by training variance.
Authors: We acknowledge the absence of error bars and statistical measures. In the revision we will rerun the relevant experiments across multiple seeds, report standard deviations, and include significance testing for the Matbench Discovery comparisons. revision: yes
-
Referee: [Experiments] Ablation studies (if present) or Experiments section: There are no ablations varying the pruning ratio, comparing channel-only vs. order-only pruning, or contrasting the chosen criterion against random block removal. Such controls are required to substantiate that the specific structural pruning preserves task-critical tensor-product paths better than training a small model from scratch.
Authors: We agree that systematic ablations would strengthen the evidence. The revised manuscript will include new experiments varying the pruning ratio, isolating channel-only versus order-only pruning, and comparing against random block removal. revision: yes
Circularity Check
No significant circularity in empirical pruning evaluation
full rationale
The paper presents a structural pruning method for SO(3) equivariant atomistic models, applied block-wise along channel and order dimensions to preserve equivariance, then evaluates the resulting compressed models against independently trained small models and from-scratch baselines on Matbench Discovery and downstream tasks. All reported gains (e.g., outperforming official small MACE-MP on 7/9 metrics, 1.5-4x parameter reduction) are obtained via direct experimental comparison rather than any derivation that reduces outputs to pruning hyperparameters, fitted inputs, or self-citations. No equations or uniqueness claims collapse the central result to its own inputs by construction; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- pruning ratios or selection thresholds for channels and orders
axioms (2)
- domain assumption Removing entire irreducible representations as blocks preserves the SO(3) equivariance of the network
- domain assumption A large pre-trained equivariant checkpoint contains redundant information that can be pruned without destroying the model's ability to outperform a small model trained from scratch
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
pruning is applied along the channel and order dimensions, with each irreducible representation kept or removed as a complete block, thereby retaining SO(3) equivariance
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
importance score I(t)_{k,l} based on first-order Taylor expansion of energy w.r.t. features h(t)_{j,klm}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bhupalee Kalita, Hatice Gokcan, and Olexandr Isayev. Machine learning interatomic potentials at the centennial crossroads of quantum mechanics.Nature Computational Science, pages 1–13, 2025
work page 2025
-
[2]
arXiv preprint arXiv:2401.00096 , year=
Ilyes Batatia, Philipp Benner, Yuan Chiang, Alin M Elena, Dávid P Kovács, Janosh Riebesell, Xavier R Advincula, Mark Asta, Matthew Avaylon, William J Baldwin, et al. A foundation model for atomistic materials chemistry.arXiv preprint arXiv:2401.00096, 2023
-
[3]
Yutack Park, Jaesun Kim, Seungwoo Hwang, and Seungwu Han. Scalable parallel algorithm for graph neural network interatomic potentials in molecular dynamics simulations.J. Chem. Theory Comput., 20 (11):4857–4868, 2024. doi: 10.1021/acs.jctc.4c00190
-
[4]
Brandon M Wood, Misko Dzamba, Xiang Fu, Meng Gao, Muhammed Shuaibi, Luis Barroso-Luque, Kareem Abdelmaqsoud, Vahe Gharakhanyan, John R Kitchin, Daniel S Levine, et al. Uma: A family of universal models for atoms.arXiv preprint arXiv:2506.23971, 2025
-
[5]
arXiv preprint arXiv:2504.06231 , year=
Benjamin Rhodes, Sander Vandenhaute, Vaidotas Šimkus, James Gin, Jonathan Godwin, Tim Duignan, and Mark Neumann. Orb-v3: atomistic simulation at scale.arXiv preprint arXiv:2504.06231, 2025
-
[6]
Arslan Mazitov, Filippo Bigi, Matthias Kellner, Paolo Pegolo, Davide Tisi, Guillaume Fraux, Sergey Pozdnyakov, Philip Loche, and Michele Ceriotti. Pet-mad as a lightweight universal interatomic potential for advanced materials modeling.Nature Communications, 16(1):10653, 2025
work page 2025
-
[7]
Flashtp: Fused, sparsity-aware tensor product for machine learning interatomic potentials
Seung Yul Lee, Hojoon Kim, Yutack Park, Dawoon Jeong, Seungwu Han, Yeonhong Park, and Jae W Lee. Flashtp: Fused, sparsity-aware tensor product for machine learning interatomic potentials. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[8]
Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds
Nathaniel Thomas, Tess Smidt, Steven Kearnes, Lusann Yang, Li Li, Kai Kohlhoff, and Patrick Riley. Tensor field networks: Rotation-and translation-equivariant neural networks for 3d point clouds.arXiv preprint arXiv:1802.08219, 2018
work page Pith review arXiv 2018
-
[9]
Mario Geiger and Tess Smidt. e3nn: Euclidean neural networks.arXiv preprint arXiv:2207.09453, 2022
-
[10]
Reducing so (3) convolutions to so (2) for efficient equivariant gnns
Saro Passaro and C Lawrence Zitnick. Reducing so (3) convolutions to so (2) for efficient equivariant gnns. InInternational conference on machine learning, pages 27420–27438. PMLR, 2023
work page 2023
-
[11]
Knowledge distillation: A survey
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International journal of computer vision, 129(6):1789–1819, 2021
work page 2021
-
[12]
A survey of quantization methods for efficient neural network inference
Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. A survey of quantization methods for efficient neural network inference. InLow-power computer vision, pages 291–326. Chapman and Hall/CRC, 2022
work page 2022
-
[13]
Manish Gupta and Puneet Agrawal. Compression of deep learning models for text: A survey.ACM Transactions on Knowledge Discovery from Data (TKDD), 16(4):1–55, 2022
work page 2022
-
[14]
arXiv preprint arXiv:2310.06694 , year=
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. Sheared llama: Accelerating language model pre-training via structured pruning.arXiv preprint arXiv:2310.06694, 2023
-
[15]
Slicegpt: Compress large language models by deleting rows and columns,
Saleh Ashkboos, Maximilian L Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. Slicegpt: Compress large language models by deleting rows and columns.arXiv preprint arXiv:2401.15024, 2024
-
[16]
Shortgpt: Layers in large language models are more redundant than you expect
Xin Men, Mingyu Xu, Qingyu Zhang, Qianhao Yuan, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. Shortgpt: Layers in large language models are more redundant than you expect. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20192–20204, 2025
work page 2025
-
[17]
Towards faster and more compact foundation models for molecular property prediction
Yasir Ghunaim, Andrés Villa, Gergo Ignacz, Gyorgy Szekely, Motasem Alfarra, and Bernard Ghanem. Towards faster and more compact foundation models for molecular property prediction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 48–57, 2025
work page 2025
-
[18]
Lingyu Kong, Jaeheon Shim, Guoxiang Hu, and Victor Fung. Scalable foundation interatomic potentials via message-passing pruning and graph partitioning.arXiv preprint arXiv:2509.21694, 2025
-
[19]
Ilyes Batatia, David P Kovacs, Gregor Simm, Christoph Ortner, and Gábor Csányi. Mace: Higher order equivariant message passing neural networks for fast and accurate force fields.Advances in neural information processing systems, 35:11423–11436, 2022. 10
work page 2022
-
[20]
Han Wang, Linfeng Zhang, Jiequn Han, et al. Deepmd-kit: A deep learning package for many-body potential energy representation and molecular dynamics.Computer Physics Communications, 228:178–184, 2018
work page 2018
-
[21]
Equivariant message passing for the prediction of tensorial properties and molecular spectra
Kristof Schütt, Oliver Unke, and Michael Gastegger. Equivariant message passing for the prediction of tensorial properties and molecular spectra. InInternational conference on machine learning, pages 9377–9388. PMLR, 2021
work page 2021
-
[22]
Johannes Gasteiger, Florian Becker, and Stephan Günnemann. Gemnet: Universal directional graph neural networks for molecules.Advances in Neural Information Processing Systems, 34:6790–6802, 2021
work page 2021
-
[23]
Simon Batzner, Albert Musaelian, Lixin Sun, Mario Geiger, Jonathan P Mailoa, Mordechai Kornbluth, Nicola Molinari, Tess E Smidt, and Boris Kozinsky. E (3)-equivariant graph neural networks for data- efficient and accurate interatomic potentials.Nature communications, 13(1):2453, 2022
work page 2022
-
[24]
Chuin Wei Tan, Marc L Descoteaux, Mit Kotak, Gabriel de Miranda Nascimento, Seán R Kavanagh, Laura Zichi, Menghang Wang, Aadit Saluja, Yizhong R Hu, Tess Smidt, et al. High-performance training and inference for deep equivariant interatomic potentials.arXiv preprint arXiv:2504.16068, 2025
-
[25]
Yury Lysogorskiy, Anton Bochkarev, and Ralf Drautz. Graph atomic cluster expansion for foundational machine learning interatomic potentials.arXiv preprint arXiv:2508.17936, 2025
-
[26]
Zhang et al., A Graph Neural Network for the Era of Large Atomistic Models
Duo Zhang, Anyang Peng, Chun Cai, Wentao Li, Yuanchang Zhou, Jinzhe Zeng, Mingyu Guo, Chengqian Zhang, Bowen Li, Hong Jiang, et al. A graph neural network for the era of large atomistic models (2025). arXiv preprint arXiv:2506.01686, 2025
-
[27]
arXiv preprint arXiv:2405.04967 , year=
Han Yang, Chenxi Hu, Yichi Zhou, Xixian Liu, Yu Shi, Jielan Li, Guanzhi Li, Zekun Chen, Shuizhou Chen, Claudio Zeni, et al. Mattersim: A deep learning atomistic model across elements, temperatures and pressures.arXiv preprint arXiv:2405.04967, 2024
-
[28]
Eric Qu, Brandon M Wood, Aditi S Krishnapriyan, and Zachary W Ulissi. A recipe for scalable attention- based mlips: unlocking long-range accuracy with all-to-all node attention.arXiv preprint arXiv:2603.06567, 2026
-
[29]
Yuanchang Zhou, Siyu Hu, Xiangyu Zhang, Hongyu Wang, Guangming Tan, and Weile Jia. Matris: Toward reliable and efficient pretrained machine learning interatomic potentials.arXiv preprint arXiv:2603.02002, 2026
-
[30]
Bowen Deng, Peichen Zhong, KyuJung Jun, Janosh Riebesell, Kevin Han, Christopher J Bartel, and Gerbrand Ceder. Chgnet as a pretrained universal neural network potential for charge-informed atomistic modelling.Nature Machine Intelligence, 5(9):1031–1041, 2023
work page 2023
-
[31]
Peter Eastman, Pavan Kumar Behara, David L Dotson, Raimondas Galvelis, John E Herr, Josh T Horton, Yuezhi Mao, John D Chodera, Benjamin P Pritchard, Yuanqing Wang, et al. Spice, a dataset of drug-like molecules and peptides for training machine learning potentials.Scientific Data, 10(1):11, 2023
work page 2023
-
[32]
arXiv preprint arXiv:2410.12771 , year=
Luis Barroso-Luque, Muhammed Shuaibi, Xiang Fu, Brandon M Wood, Misko Dzamba, Meng Gao, Ammar Rizvi, C Lawrence Zitnick, and Zachary W Ulissi. Open materials 2024 (omat24) inorganic materials dataset and models.arXiv preprint arXiv:2410.12771, 2024
-
[33]
Levine, Muhammed Shuaibi, Evan Walter Clark Spotte-Smith, Michael G
Daniel S Levine, Muhammed Shuaibi, Evan Walter Clark Spotte-Smith, Michael G Taylor, Muhammad R Hasyim, Kyle Michel, Ilyes Batatia, Gábor Csányi, Misko Dzamba, Peter Eastman, et al. The open molecules 2025 (omol25) dataset, evaluations, and models.arXiv preprint arXiv:2505.08762, 2025
-
[34]
Open molecular crystals 2025 (omc25) dataset and models.Scientific Data, 2026
Vahe Gharakhanyan, Luis Barroso-Luque, Yi Yang, Muhammed Shuaibi, Kyle Michel, Daniel S Levine, Misko Dzamba, Xiang Fu, Meng Gao, Xingyu Liu, et al. Open molecular crystals 2025 (omc25) dataset and models.Scientific Data, 2026
work page 2025
-
[35]
Anuroop Sriram, Logan M Brabson, Xiaohan Yu, Sihoon Choi, Kareem Abdelmaqsoud, Elias Moubarak, Pim de Haan, Sindy Löwe, Johann Brehmer, John R Kitchin, et al. The open dac 2025 dataset for sorbent discovery in direct air capture.arXiv preprint arXiv:2508.03162, 2025
-
[36]
Machine learning meets quantum physics.Lecture Notes in Physics, 2020
Kristof T Schütt, Stefan Chmiela, O Anatole V on Lilienfeld, Alexandre Tkatchenko, Koji Tsuda, and Klaus-Robert Müller. Machine learning meets quantum physics.Lecture Notes in Physics, 2020
work page 2020
-
[37]
Scaling deep learning for materials discovery.Nature, 624(7990):80–85, 2023
Amil Merchant, Simon Batzner, Samuel S Schoenholz, Muratahan Aykol, Gowoon Cheon, and Ekin Dogus Cubuk. Scaling deep learning for materials discovery.Nature, 624(7990):80–85, 2023. 11
work page 2023
-
[38]
Mariia Radova, Wojciech G Stark, Connor S Allen, Reinhard J Maurer, and Albert P Bartók. Fine-tuning foundation models of materials interatomic potentials with frozen transfer learning.npj Computational Materials, 11(1):237, 2025
work page 2025
-
[39]
Harveen Kaur, Flaviano Della Pia, Ilyes Batatia, Xavier R Advincula, Benjamin X Shi, Jinggang Lan, Gábor Csányi, Angelos Michaelides, and Venkat Kapil. Data-efficient fine-tuning of foundational models for first-principles quality sublimation enthalpies.Faraday Discussions, 256:120–138, 2025
work page 2025
-
[40]
Lei Deng, Guoqi Li, Song Han, Luping Shi, and Yuan Xie. Model compression and hardware acceleration for neural networks: A comprehensive survey.Proceedings of the IEEE, 108(4):485–532, 2020
work page 2020
-
[41]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635, 2018
work page Pith review arXiv 2018
-
[42]
Filip Ekström Kelvinius, Dimitar Georgiev, Artur Toshev, and Johannes Gasteiger. Accelerating molecular graph neural networks via knowledge distillation.Advances in Neural Information Processing Systems, 36: 25761–25792, 2023
work page 2023
-
[43]
arXiv preprint arXiv:2501.09009 , year=
Ishan Amin, Sanjeev Raja, and Aditi Krishnapriyan. Towards fast, specialized machine learning force fields: Distilling foundation models via energy hessians.arXiv preprint arXiv:2501.09009, 2025
-
[44]
Alexandre Benoit. Speeding up mace: Low-precision tricks for equivarient force fields.arXiv preprint arXiv:2510.23621, 2025
-
[45]
Are sixteen heads really better than one?Advances in neural information processing systems, 32, 2019
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one?Advances in neural information processing systems, 32, 2019
work page 2019
-
[46]
Structured pruning of large language models
Ziheng Wang, Jeremy Wohlwend, and Tao Lei. Structured pruning of large language models. InProceedings of the 2020 conference on empirical methods in natural language processing (emnlp), pages 6151–6162, 2020
work page 2020
-
[47]
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models.Advances in neural information processing systems, 36:21702–21720, 2023
work page 2023
-
[48]
Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding.arXiv preprint arXiv:1510.00149, 2015
work page internal anchor Pith review arXiv 2015
-
[49]
Dávid Péter Kovács, J Harry Moore, Nicholas J Browning, Ilyes Batatia, Joshua T Horton, Yixuan Pu, Venkat Kapil, William C Witt, Ioan-Bogdan Magdau, Daniel J Cole, et al. Mace-off: Short-range transferable machine learning force fields for organic molecules.Journal of the American Chemical Society, 147(21):17598–17611, 2025
work page 2025
-
[50]
Dávid Péter Kovács, Cas van der Oord, Jiri Kucera, Alice EA Allen, Daniel J Cole, Christoph Ortner, and Gábor Csányi. Linear atomic cluster expansion force fields for organic molecules: beyond rmse.Journal of chemical theory and computation, 17(12):7696–7711, 2021
work page 2021
-
[51]
Batatia,et al., The Design Space of E(3)-Equivariant Atom-Centered Interatomic Potentials
Ilyes Batatia, Simon Batzner, Dávid Péter Kovács, Albert Musaelian, Gregor NC Simm, Ralf Drautz, Christoph Ortner, Boris Kozinsky, and Gábor Csányi. The design space of e (3)-equivariant atom-centered interatomic potentials.arXiv preprint arXiv:2205.06643, 2022
-
[52]
Anders S Christensen and O Anatole V on Lilienfeld. On the role of gradients for machine learning of molecular energies and forces.Machine Learning: Science and Technology, 1(4):045018, 2020
work page 2020
-
[53]
Jonathan Schmidt, Tiago FT Cerqueira, Aldo H Romero, Antoine Loew, Fabian Jäger, Hai-Chen Wang, Silvana Botti, and Miguel AL Marques. Improving machine-learning models in materials science through large datasets.Materials Today Physics, 48:101560, 2024
work page 2024
-
[54]
Learning smooth and expressive interatomic potentials for physical property prediction
Xiang Fu, Brandon M Wood, Luis Barroso-Luque, Daniel S Levine, Meng Gao, Misko Dzamba, and C Lawrence Zitnick. Learning smooth and expressive interatomic potentials for physical property prediction. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[55]
Janosh Riebesell, Rhys EA Goodall, Philipp Benner, Yuan Chiang, Bowen Deng, Alpha A Lee, Anubhav Jain, and Kristin A Persson. Matbench discovery–a framework to evaluate machine learning crystal stability predictions.arXiv preprint arXiv:2308.14920, 2023
-
[56]
Open catalyst 2020 (oc20) dataset and community challenges.Acs Catalysis, 11(10):6059–6072, 2021
Lowik Chanussot, Abhishek Das, Siddharth Goyal, Thibaut Lavril, Muhammed Shuaibi, Morgane Riviere, Kevin Tran, Javier Heras-Domingo, Caleb Ho, Weihua Hu, et al. Open catalyst 2020 (oc20) dataset and community challenges.Acs Catalysis, 11(10):6059–6072, 2021. 12
work page 2020
-
[57]
Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, and Pavlo Molchanov. Compact language models via pruning and knowledge distillation.Advances in Neural Information Processing Systems, 37:41076–41102, 2024
work page 2024
-
[58]
Jianxing Huang, Linfeng Zhang, Han Wang, Jinbao Zhao, Jun Cheng, et al. Deep potential generation scheme and simulation protocol for the li10gep2s12-type superionic conductors.The Journal of Chemical Physics, 154(9), 2021
work page 2021
-
[59]
Phase diagram of a deep potential water model
Linfeng Zhang, Han Wang, Roberto Car, and Weinan E. Phase diagram of a deep potential water model. Physical review letters, 126(23):236001, 2021
work page 2021
-
[60]
YiNan Wang, LinFeng Zhang, Ben Xu, XiaoYang Wang, and Han Wang. A generalizable machine learning potential of ag–au nanoalloys and its application to surface reconstruction, segregation and diffusion. Modelling and Simulation in Materials Science and Engineering, 30(2):025003, 2021
work page 2021
-
[61]
Wanrun Jiang, Yuzhi Zhang, Linfeng Zhang, and Han Wang. Accurate deep potential model for the al–cu–mg alloy in the full concentration space.Chinese Physics B, 30(5):050706, 2021
work page 2021
-
[62]
Yuzhi Zhang, Haidi Wang, Weijie Chen, Jinzhe Zeng, Linfeng Zhang, Han Wang, and E Weinan. Dp-gen: A concurrent learning platform for the generation of reliable deep learning based potential energy models. Computer Physics Communications, 253:107206, 2020
work page 2020
-
[63]
Tongqi Wen, Rui Wang, Lingyu Zhu, Linfeng Zhang, Han Wang, David J Srolovitz, and Zhaoxuan Wu. Specialising neural network potentials for accurate properties and application to the mechanical response of titanium.npj Computational Materials, 7(1):206, 2021
work page 2021
-
[64]
Rui Wang, Xiaoxiao Ma, Linfeng Zhang, Han Wang, David J Srolovitz, Tongqi Wen, and Zhaoxuan Wu. Classical and machine learning interatomic potentials for bcc vanadium.Physical Review Materials, 6(11): 113603, 2022
work page 2022
-
[65]
Xiaoyang Wang, Yinan Wang, Linfeng Zhang, Fuzhi Dai, and Han Wang. A tungsten deep neural-network potential for simulating mechanical property degradation under fusion service environment.Nuclear Fusion, 62(12):126013, 2022
work page 2022
-
[66]
Mario Geiger, Emine Kucukbenli, Becca Zandstein, and Kyle Tretina. Accelerate drug and material discovery with new math library nvidia cuequivariance.URL https://github.com/NVIDIA/cuEquivariance, 2024
work page 2024
-
[67]
Zhao Xu, Haiyang Yu, Montgomery Bohde, and Shuiwang Ji. Equivariant graph network approximations of high-degree polynomials for force field prediction.arXiv preprint arXiv:2411.04219, 2024. 13 A Background Machine-Learning Interatomic Potentials (MLIPs).The primary objective of MLIPs is to approximate the Potential Energy Surface (PES) of an atomic system...
-
[68]
, ml) be an arbitrary diagonal binary mask where not allm i are equal
Element-wise Pruning:Let M=diag(m −l, . . . , ml) be an arbitrary diagonal binary mask where not allm i are equal. ApplyingMelement-wise violates equivariance: M(Dl(g)hl)̸=D l(g)(Mhl)(10) 15
-
[69]
Block-wise Pruning:Applying a scalar mask z∈ {0,1} (our proposed method) preserves equivariance: z(Dl(g)hl) =D l(g)(zh l)(11) Proof. Part 1 (Violation):The Wigner-D matrix Dl(g) is a dense (2l+ 1)×(2l+ 1) unitary matrix that mixes all components indexed by m∈[−l, l] . Let h′ =D l(g)h. The i-th compo- nent of the rotated feature is h′ i = P j Dl(g)ijhj. If...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.