Recognition: 2 theorem links
· Lean TheoremBilinear autoencoders find interpretable manifolds
Pith reviewed 2026-05-12 01:21 UTC · model grok-4.3
The pith
Bilinear autoencoders with quadratic latents capture multi-dimensional manifolds that linear methods miss in neural activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
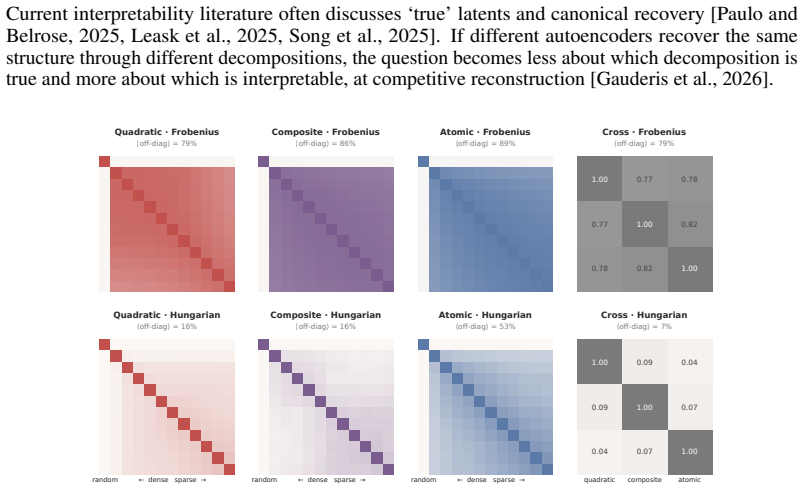
Bilinear autoencoders decompose activations into low-rank quadratic forms that compose linearly in weight space and support input-independent geometric analysis. This enables detection of multi-dimensional geometries, which experiments show are prevalent, and composite latents capture them to improve reconstruction error systematically in language models. Autoencoders with different geometric priors still recover the same input subspace even when their dictionary entries differ, providing an unsupervised tool for manifold discovery demonstrated via an interactive visualizer.
What carries the argument
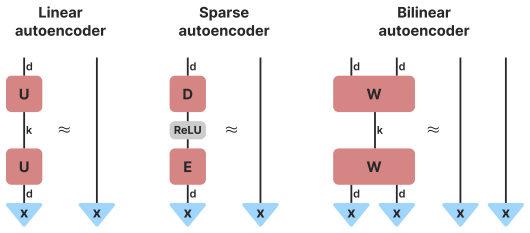
Bilinear decomposition of activations into low-rank quadratic forms, which produces composite latents for capturing manifolds.
If this is right
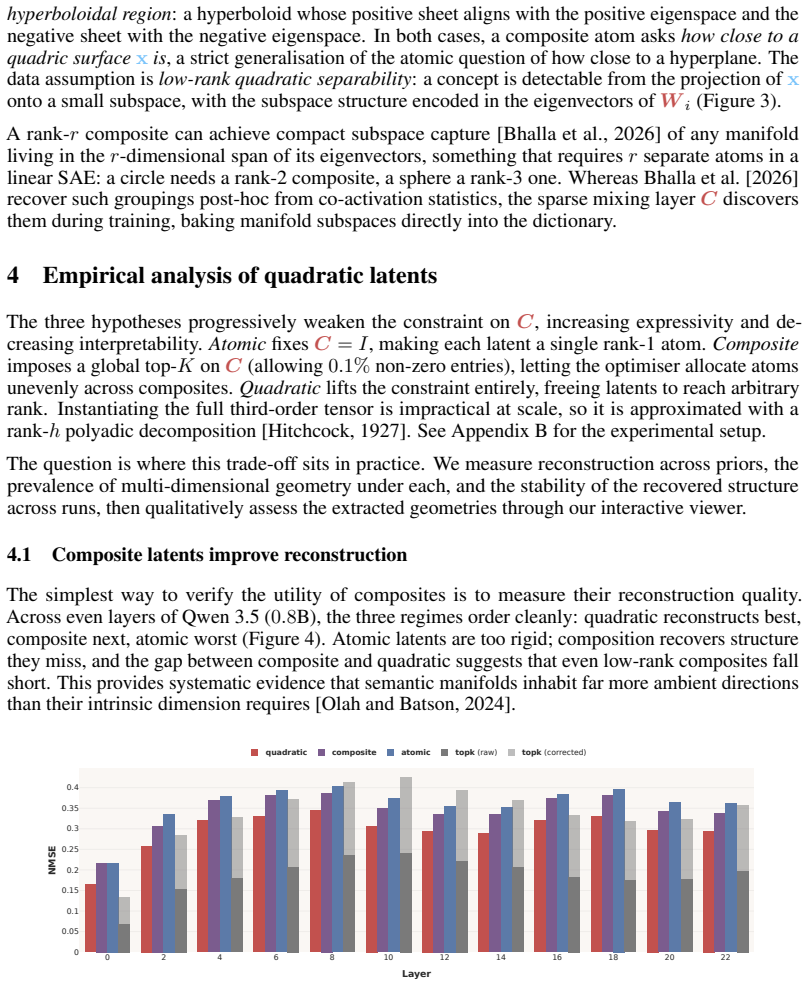
- Composite quadratic latents systematically lower reconstruction error compared to linear ones in language models.
- Models with different geometric priors converge on the same input subspace.
- Multi-dimensional geometries appear frequently in the learned representations.
- The method enables unsupervised manifold discovery with tools like interactive visualizers for specific models.
Where Pith is reading between the lines
- The technique could extend to other neural architectures to uncover similar manifold structures beyond language models.
- It implies that interpretability methods may need to move past linear assumptions to handle feature interactions more accurately.
- Similar decompositions might serve as a general tool for analyzing geometric properties in activation spaces across domains.
Load-bearing premise
The quadratic latents and bilinear decompositions identify genuinely meaningful concepts in the model's computation rather than artifacts of the fitting process.
What would settle it
A test showing that quadratic latents produce no consistent improvement in reconstruction error over linear autoencoders on held-out activations or that the identified manifolds do not align with observable changes in model behavior.
Figures










read the original abstract
Sparse autoencoders have become a standard tool for uncovering interpretable latent representations in neural networks. Yet salient concepts often span manifolds that current linear methods cannot capture without post hoc analysis. This paper uses quadratic latents to close this gap: we implement these with bilinear autoencoders, which decompose activations into low-rank quadratic forms, compose linearly in weight space, and admit input-independent geometric analysis. This qualitative difference in what concepts quadratic latents can detect challenges the standard linear representation hypothesis. Our experiments and visualisations show that multi-dimensional geometries are highly prevalent and that composite latents capture them well, systematically improving reconstruction error in language models. Furthermore, we show that autoencoders with varying geometric priors recover the same input subspace despite their dictionary entries being distinct. Practically, these models serve as an unsupervised tool for manifold discovery, which we demonstrate through an interactive online visualizer for Qwen 3.5. This is a step toward nonlinear but mathematically tractable latent representations whose composition is expressive and interpretable by design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces bilinear autoencoders to realize quadratic latents that decompose activations into low-rank quadratic forms, enabling capture of multi-dimensional geometric manifolds in neural network representations (especially language models) that linear sparse autoencoders cannot access without post-hoc analysis. It reports that these composite latents yield systematically lower reconstruction error, that multi-dimensional geometries are prevalent, that varying geometric priors recover the same input subspace, and that the approach supports an interactive unsupervised manifold-discovery visualizer for models like Qwen 3.5.
Significance. If the central claims hold after addressing capacity controls, the work supplies a mathematically tractable nonlinear extension of the sparse-autoencoder toolkit, directly challenging the linear representation hypothesis with evidence of prevalent composite structures and offering a practical visualization interface. This could shift interpretability research toward explicitly quadratic but still composable latents.
major comments (2)
- [Experiments] Experiments section (and abstract): the reported systematic improvement in reconstruction error and the claim that quadratic latents capture multi-dimensional manifolds inaccessible to linear methods lack controls that match the effective degrees of freedom or parameter count of the bilinear model against a linear SAE baseline (e.g., by enlarging the linear dictionary size). Without such matched-capacity ablations, the observed gains cannot be attributed specifically to the quadratic decomposition rather than increased expressivity.
- [Methods] Methods / bilinear formulation: the statement that the decomposition 'admits input-independent geometric analysis' and that 'composite latents capture them well' requires an explicit derivation or lemma showing how the low-rank quadratic terms produce interpretable, geometrically meaningful composites that are not artifacts of the fitting procedure; this is load-bearing for the challenge to the linear representation hypothesis.
minor comments (2)
- [Abstract] The abstract and introduction should cite the exact model, layer, and dataset used for the Qwen 3.5 visualizer to allow immediate reproducibility.
- [Figures] Figure captions would benefit from quantitative metrics (e.g., reconstruction MSE deltas or subspace overlap scores) alongside the qualitative visualizations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us improve the clarity and rigor of our work. We address each major comment below, providing additional experiments and theoretical derivations as requested.
read point-by-point responses
-
Referee: Experiments section (and abstract): the reported systematic improvement in reconstruction error and the claim that quadratic latents capture multi-dimensional manifolds inaccessible to linear methods lack controls that match the effective degrees of freedom or parameter count of the bilinear model against a linear SAE baseline (e.g., by enlarging the linear dictionary size). Without such matched-capacity ablations, the observed gains cannot be attributed specifically to the quadratic decomposition rather than increased expressivity.
Authors: We agree that controlling for model capacity is essential to attribute improvements to the bilinear structure rather than increased expressivity. In the revised version, we have included new ablations in the Experiments section where the linear SAE dictionary size is expanded to match the parameter count of the bilinear autoencoder. These matched-capacity comparisons confirm that the bilinear model still achieves lower reconstruction error and better captures multi-dimensional manifolds. We have also updated the abstract to reflect these findings. revision: yes
-
Referee: Methods / bilinear formulation: the statement that the decomposition 'admits input-independent geometric analysis' and that 'composite latents capture them well' requires an explicit derivation or lemma showing how the low-rank quadratic terms produce interpretable, geometrically meaningful composites that are not artifacts of the fitting procedure; this is load-bearing for the challenge to the linear representation hypothesis.
Authors: We appreciate this point, as it strengthens the theoretical foundation. We have added an explicit lemma (Lemma 2 in the revised Methods section) that derives the geometric properties of the low-rank quadratic terms. The lemma shows that each composite latent corresponds to a quadratic form whose level sets define interpretable manifolds in the input space, independent of specific activations. Furthermore, we prove that under the low-rank constraint and orthogonality conditions, these composites are unique and not fitting artifacts. This directly supports our challenge to the linear representation hypothesis by demonstrating that quadratic latents can represent multi-dimensional structures in a mathematically tractable way. revision: yes
Circularity Check
No significant circularity; claims rest on experimental results
full rationale
The paper introduces bilinear autoencoders as a method to decompose activations into low-rank quadratic forms and reports empirical findings from experiments on language models, including improved reconstruction error and visualizations of multi-dimensional geometries. No load-bearing steps reduce by construction to self-definition, fitted inputs renamed as predictions, or self-citation chains. The abstract and described content ground claims in observed outputs rather than definitional equivalences or ansatzes smuggled via prior work. Absence of parameter-matched controls is a methodological concern for claim strength but does not constitute circularity under the specified patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
bilinear autoencoder
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection, RCLCombiner_isCoupling_iff echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
bilinear autoencoders, which decompose activations into low-rank quadratic forms... composite latents... quadratic representation hypothesis... W_i = sum C_ij w_j w_j^T
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff, J_uniquely_calibrated_via_higher_derivative echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
z_i := x^T L^T diag(c_i) R x = <W_i, X>_F ... kernel trick... reconstruction of X=xx^T
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Not All Language Model Features Are One-Dimensionally Linear , author=. 2025 , eprint=
work page 2025
-
[2]
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. 2024 , eprint=
work page 2024
-
[3]
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
work page 2023
-
[4]
Sparse Autoencoders Trained on the Same Data Learn Different Features , author=. 2025 , eprint=
work page 2025
-
[5]
Position: Mechanistic Interpretability Should Prioritize Feature Consistency in SAEs , author=. 2025 , eprint=
work page 2025
-
[6]
Jai Bhagat and Sara Molas Medina and Giorgi Giglemiani and Stefan Heimersheim , title =. 2025 , month =
work page 2025
- [7]
- [8]
-
[9]
Language Models are Unsupervised Multitask Learners , author=
- [10]
- [11]
-
[12]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
work page 2023
-
[13]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
- [14]
-
[15]
Language Modeling with Gated Convolutional Networks , author=. 2017 , eprint=
work page 2017
-
[16]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , author=. 2022 , eprint=
work page 2022
-
[18]
Sparse Autoencoders Do Not Find Canonical Units of Analysis , author=. 2025 , eprint=
work page 2025
-
[19]
Interpretability as Compression: Reconsidering SAE Explanations of Neural Activations with MDL-SAEs , author=. 2024 , eprint=
work page 2024
-
[20]
Learning Multi-Level Features with Matryoshka Sparse Autoencoders , author=. 2025 , eprint=
work page 2025
-
[21]
G. E. Hinton and R. R. Salakhutdinov , title =. Science , volume =. 2006 , doi =
work page 2006
-
[22]
Do Sparse Autoencoders Capture Concept Manifolds? , author=. 2026 , eprint=
work page 2026
-
[23]
The Non-Linear Representation Dilemma: Is Causal Abstraction Enough for Mechanistic Interpretability? , author=. 2025 , eprint=
work page 2025
-
[24]
Projecting Assumptions: The Duality Between Sparse Autoencoders and Concept Geometry , author=. 2025 , eprint=
work page 2025
-
[25]
Bilinear MLPs enable weight-based mechanistic interpretability , author=. 2025 , eprint=
work page 2025
-
[26]
Compositionality as we see it, everywhere around us , author=. 2021 , eprint=
work page 2021
-
[27]
Everything, Everywhere, All at Once: Is Mechanistic Interpretability Identifiable? , author=. 2025 , eprint=
work page 2025
- [28]
- [29]
-
[30]
The Origins of Representation Manifolds in Large Language Models , author=. 2025 , eprint=
work page 2025
- [31]
-
[32]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders , author=. 2024 , eprint=
work page 2024
-
[33]
Tensor Diagram Notation , author =
-
[34]
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders , author=. 2025 , eprint=
work page 2025
-
[35]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[36]
Keller Jordan and Yuchen Jin and Vlado Boza and You Jiacheng and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
work page 2024
-
[37]
Tull, Sean and Lorenz, Robin and Clark, Stephen and Khan, Ilyas and Coecke, Bob , year =. Towards. doi:10.48550/arXiv.2406.17583 , urldate =. arXiv , keywords =:2406.17583 , primaryclass =
-
[38]
Dooms, Thomas and Gauderis, Ward and Wiggins, Geraint and Mogrovejo, Jose Antonio Oramas , year =. Compositionality. Connecting
- [39]
-
[40]
arXiv preprint arXiv:2511.13653 , year=
Weight-Sparse Transformers Have Interpretable Circuits , author =. doi:10.48550/arXiv.2511.13653 , urldate =. arXiv , keywords =:2511.13653 , primaryclass =
-
[41]
What is a Linear Representation? What is a Multidimensional Feature? , author =. 2024 , month =
work page 2024
-
[42]
Sparse and Redundant Representations: From Theory to Applications in Signal and Image Processing , author=. 2010 , publisher=
work page 2010
-
[43]
Emergence of simple-cell receptive field properties by learning a sparse code for natural images , author=. Nature , volume=. 1996 , publisher=
work page 1996
-
[44]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
Qwen Team , month =. Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[45]
Aharon, Michal and Elad, Michael and Bruckstein, Alfred , journal=. K-. 2006 , doi=
work page 2006
-
[46]
Learning Overcomplete Representations , author=. Neural Computation , volume=. 2000 , doi=
work page 2000
-
[47]
Proceedings of the 26th Annual International Conference on Machine Learning (ICML) , pages=
Online Dictionary Learning for Sparse Coding , author=. Proceedings of the 26th Annual International Conference on Machine Learning (ICML) , pages=. 2009 , doi=
work page 2009
-
[48]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Efficient Sparse Coding Algorithms , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[49]
An Information-Maximization Approach to Blind Separation and Blind Deconvolution , author=. Neural Computation , volume=. 1995 , doi=
work page 1995
-
[50]
Emergence of Phase- and Shift-Invariant Features by Decomposition of Natural Images into Independent Feature Subspaces , author=. Neural Computation , volume=. 2000 , doi=
work page 2000
-
[51]
Journal of Machine Learning Research , volume=
Proximal Methods for Hierarchical Sparse Coding , author=. Journal of Machine Learning Research , volume=
-
[52]
Structured Sparsity through Convex Optimization , author=. Statistical Science , volume=. 2012 , doi=
work page 2012
-
[53]
Modeling by Shortest Data Description , author=. Automatica , volume=. 1978 , doi=
work page 1978
-
[54]
Sharkey, Lee and Chughtai, Bilal and Batson, Joshua and Lindsey, Jack and Wu, Jeff and Bushnaq, Lucius and. Open. doi:10.48550/arXiv.2501.16496 , urldate =. arXiv , langid =:2501.16496 , primaryclass =
work page internal anchor Pith review doi:10.48550/arxiv.2501.16496
-
[55]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
- [56]
- [57]
-
[58]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author=. 2019 , eprint=
work page 2019
-
[59]
Hitchcock, Frank L. , title =. Journal of Mathematics and Physics , volume =. doi:https://doi.org/10.1002/sapm192761164 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/sapm192761164 , year =
-
[60]
and Ayonrinde, Kola and Wiggins, Geraint A
Gauderis, Ward and Dooms, Thomas and Homer, Steven T. and Ayonrinde, Kola and Wiggins, Geraint A. , month = jul, year =. From. Proceedings of the 2nd
-
[61]
Lewis, Martha , month = oct, year =. Compositional. Proceedings -. doi:10.26615/978-954-452-056-4_075 , abstract =
-
[62]
ICA with Reconstruction Cost for Efficient Overcomplete Feature Learning , url =
Le, Quoc and Karpenko, Alexandre and Ngiam, Jiquan and Ng, Andrew , booktitle =. ICA with Reconstruction Cost for Efficient Overcomplete Feature Learning , url =
-
[63]
Into the Rabbit Hull: From Task-Relevant Concepts in DINO to Minkowski Geometry
Fel, Thomas and Wang, Binxu and Lepori, Michael A. and Kowal, Matthew and Lee, Andrew and Balestriero, Randall and Joseph, Sonia and Lubana, Ekdeep S. and Konkle, Talia and Ba, Demba and Wattenberg, Martin , month = oct, year =. Into the. doi:10.48550/arXiv.2510.08638 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.08638
- [64]
-
[65]
Nguyen, Hien Van and Patel, Vishal M. and Nasrabadi, Nasser M. and Chellappa, Rama , month = mar, year =. Kernel dictionary learning , isbn =. 2012. doi:10.1109/ICASSP.2012.6288305 , urldate =
-
[66]
Nguyen, Hien Van and Patel, Vishal M and Nasrabadi, Nasser M and Chellappa, Rama , file =
-
[67]
Luo, Yifan and Zhan, Yang and Jiang, Jiedong and Liu, Tianyang and Wu, Mingrui and Zhou, Zhennan and Dong, Bin , month = feb, year =. From. doi:10.48550/arXiv.2602.11881 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.