Recognition: no theorem link
When and Why Grouping Attention Heads Accelerates Muon Optimization
Pith reviewed 2026-05-12 02:45 UTC · model grok-4.3
The pith
Grouping attention heads in Muon improves validation loss by balancing whitening gains against added norm costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
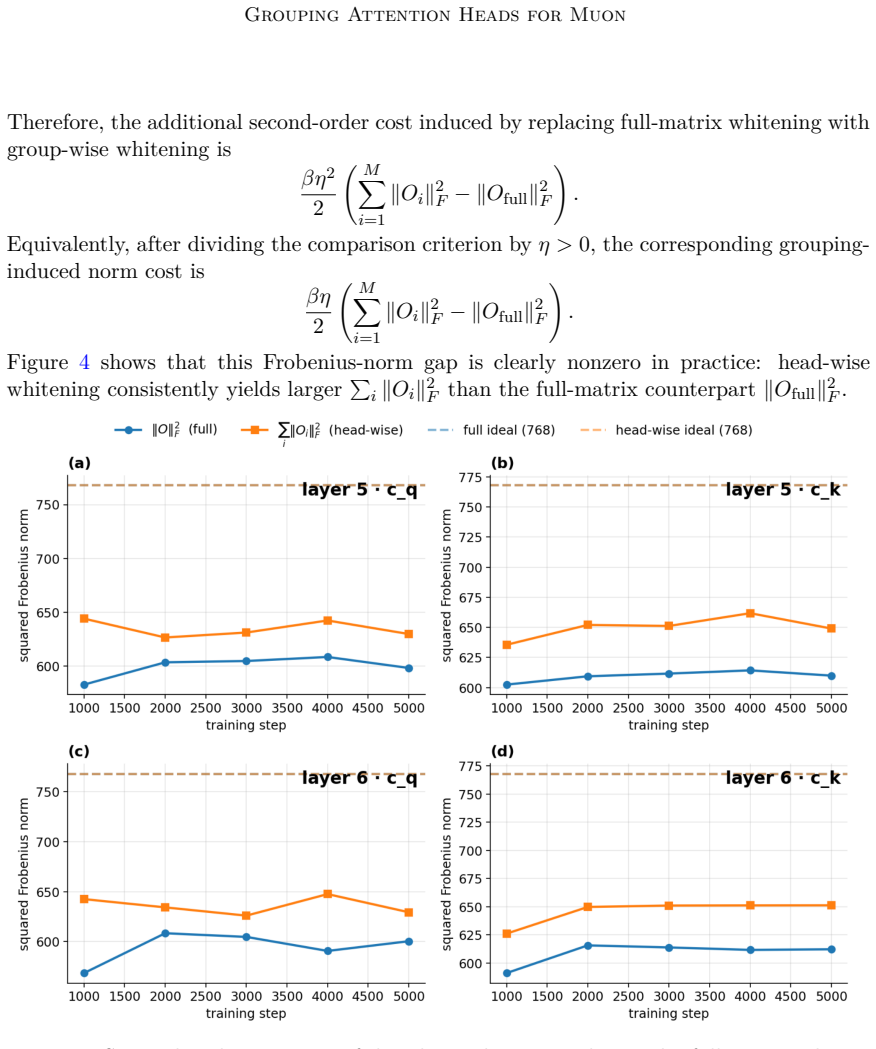
Muon orthogonalizes matrix updates, but multi-head attention naturally operates at the level of heads. This granularity mismatch raises the question of whether Muon should be applied to the full attention projection, to individual heads, or to intermediate head groups. We study this question through a one-step descent comparison between full-matrix Muon and group-wise Muon. Our analysis reveals a trade-off between the group-wise whitening gain from group-wise updates and the grouping-induced norm cost, an additional update-norm cost caused by replacing full-matrix whitening with group-wise whitening. Motivated by this trade-off, we propose Group Muon, which treats head group size and groupin
What carries the argument
Group-wise whitening applied to attention head groups inside Muon, trading off intra-group whitening benefit against the extra norm cost of replacing a single full-matrix orthogonalization with several smaller ones.
If this is right
- Appropriate head grouping yields lower validation loss than either full-QKV Muon or head-wise MuonSplit on GPT-2 Small with FineWeb data.
- Head group size and grouping rule function as effective hyperparameters that can be tuned for Muon on attention layers.
- The one-step trade-off between whitening gain and grouping-induced norm cost predicts when grouping will accelerate training.
- Group Muon can be used by treating grouping choices as additional optimizer settings without changing the underlying Muon update rule.
Where Pith is reading between the lines
- If the same trade-off appears in larger transformers, Group Muon could become a standard way to adapt matrix orthogonalization optimizers to attention architectures.
- Similar grouping decisions may improve other matrix-based optimizers when they are applied to modular network components such as attention heads or feed-forward blocks.
- Testing grouping rules that respect token or position structure rather than uniform size could uncover further gains on specific tasks or datasets.
Load-bearing premise
The one-step descent comparison between full-matrix Muon and group-wise Muon generalizes to the multi-step, full-training regime observed in the GPT-2 experiments.
What would settle it
Training GPT-2 Small on FineWeb with the group size and rule predicted optimal by the one-step analysis, yet obtaining validation loss equal to or worse than full-QKV Muon, would show the claimed acceleration does not hold.
Figures



read the original abstract
Muon orthogonalizes matrix updates, but multi-head attention naturally operates at the level of heads. This granularity mismatch raises the question of whether Muon should be applied to the full attention projection, to individual heads, or to intermediate head groups. We study this question through a one-step descent comparison between full-matrix Muon and group-wise Muon. Our analysis reveals a trade-off between the \textbf{group-wise whitening gain} from group-wise updates and the \textbf{grouping-induced norm cost}, an additional update-norm cost caused by replacing full-matrix whitening with group-wise whitening. Motivated by this trade-off, we propose \textbf{Group Muon}, which treats head group size and grouping rule as optimizer hyperparameters. On GPT-2 Small trained on FineWeb, appropriate grouping improves validation loss over both full-QKV Muon and fully head-wise MuonSplit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Muon applied to full attention projections can be improved by grouping heads into intermediate sizes, motivated by a one-step descent analysis that identifies a trade-off between group-wise whitening gain and an additional grouping-induced norm cost; on GPT-2 Small trained on FineWeb, suitable grouping yields lower validation loss than both full-QKV Muon and fully head-wise MuonSplit.
Significance. If the one-step trade-off generalizes and the empirical gains prove robust, the work would supply a practical hyperparameter (head group size and rule) for Muon on attention layers, potentially improving optimization of transformers. The explicit derivation of the norm cost and the controlled comparison against both extremes constitute a clear contribution, though the manuscript does not yet demonstrate that the one-step optimum predicts the multi-step winners.
major comments (2)
- [§3] §3 (one-step descent comparison): the analysis derives the whitening-gain versus norm-cost trade-off but reports no verification that the group size minimizing the one-step quantity coincides with the group size that wins in the full GPT-2 training runs; without this alignment or per-step norm diagnostics, the claimed explanatory link between the analysis and the observed validation-loss improvement is unverified.
- [§4] §4 (GPT-2 Small / FineWeb experiments): validation-loss curves are presented without error bars, run counts, or statistical tests, so it is impossible to assess whether the reported improvement over full-QKV Muon and MuonSplit is reliable or could be explained by incidental learning-rate rescaling induced by the norm cost.
minor comments (2)
- The precise grouping rule (e.g., contiguous heads, learned, or fixed) that produced the best result should be stated explicitly in the experimental section for reproducibility.
- [§3] Notation for the grouping-induced norm cost could be introduced with an equation number in §3 to make later references unambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying the intent of our analysis and committing to revisions that improve the manuscript's rigor without overstating our current results.
read point-by-point responses
-
Referee: [§3] §3 (one-step descent comparison): the analysis derives the whitening-gain versus norm-cost trade-off but reports no verification that the group size minimizing the one-step quantity coincides with the group size that wins in the full GPT-2 training runs; without this alignment or per-step norm diagnostics, the claimed explanatory link between the analysis and the observed validation-loss improvement is unverified.
Authors: We agree that a direct verification of alignment between the one-step minimizer and the multi-step empirical optimum would strengthen the claimed explanatory link. Our one-step descent analysis is primarily intended to derive the existence of a trade-off (whitening gain versus grouping-induced norm cost) and thereby motivate treating group size as a tunable hyperparameter, rather than to serve as a precise predictor of the optimal group size under full multi-step training. The GPT-2 experiments confirm that intermediate grouping outperforms both extremes, which is consistent with the direction predicted by the trade-off. In the revised manuscript we will add a dedicated discussion paragraph clarifying the scope and limitations of the one-step approximation, together with per-step norm diagnostics computed from the existing training runs to illustrate the norm-cost component in practice. Full quantitative alignment across many random seeds would require substantial additional compute and is noted as future work. revision: partial
-
Referee: [§4] §4 (GPT-2 Small / FineWeb experiments): validation-loss curves are presented without error bars, run counts, or statistical tests, so it is impossible to assess whether the reported improvement over full-QKV Muon and MuonSplit is reliable or could be explained by incidental learning-rate rescaling induced by the norm cost.
Authors: We acknowledge that the absence of error bars, run counts, and statistical tests makes it difficult to judge the reliability of the reported gains and to rule out confounding effects from the norm cost. The presented curves reflect single training runs performed under fixed hyperparameter budgets; we did tune the base learning rate separately for each grouping configuration to compensate for the norm-cost difference. In the revised version we will rerun the key configurations (full QKV, MuonSplit, and the best-performing group sizes) with at least three independent random seeds, add shaded error bars to the validation-loss plots, state the number of runs explicitly, and include a simple statistical comparison (e.g., paired t-test on final validation loss) to quantify significance. We will also expand the experimental-details section to describe how the norm cost was accounted for during learning-rate selection. revision: yes
Circularity Check
One-step descent analysis supplies independent motivation; empirical gains are not forced by construction
full rationale
The paper performs a one-step descent comparison to identify a trade-off between group-wise whitening gain and grouping-induced norm cost, then treats group size as a hyperparameter and validates Group Muon on full GPT-2 training runs. No equation in the provided text equates the multi-step validation loss improvement to a quantity defined by the same one-step fit or grouping rule; the one-step math is presented as motivation rather than a predictive model whose optimum is retrofitted to the observed winners. The derivation chain therefore remains self-contained: the theoretical trade-off is derived from matrix-update norms independent of the later empirical hyperparameter search, and the reported validation-loss gains are not shown to reduce tautologically to the inputs of that search.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language Models are Unsupervised Multitask Learners , url =
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , biburl =. Language Models are Unsupervised Multitask Learners , url =. OpenAI , keywords =
-
[2]
Modded-nanogpt Speedrun PR 253: Pair-Head Muon , author=. 2026 , month=
work page 2026
-
[3]
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
work page 2024
- [4]
-
[5]
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
work page 2026
- [6]
-
[7]
Practical Efficiency of Muon for Pretraining , author=. 2025 , eprint=
work page 2025
- [8]
-
[9]
ES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models , year=
Towards Understanding Orthogonalization in Muon , author=. ES-FoMo III: 3rd Workshop on Efficient Systems for Foundation Models , year=
-
[10]
Beyond the Ideal: Analyzing the Inexact Muon Update , author=. 2025 , eprint=
work page 2025
- [11]
-
[12]
Dion2: A Simple Method to Shrink Matrix in Muon , author=. 2025 , eprint=
work page 2025
-
[13]
MuonBP: Faster Muon via Block-Periodic Orthogonalization , author=. 2025 , eprint=
work page 2025
-
[14]
Advances in Neural Information Processing Systems , volume=
The fineweb datasets: Decanting the web for the finest text data at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Advances in neural information processing systems , volume=
Root mean square layer normalization , author=. Advances in neural information processing systems , volume=
-
[16]
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
work page 2024
-
[17]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.