Recognition: 2 theorem links
· Lean TheoremTrustworthy AI: Ensuring Reliability and Accountability from Models to Agents
Pith reviewed 2026-05-12 02:17 UTC · model grok-4.3
The pith
The thesis develops theoretically grounded algorithms to ensure reliability and accountability as machine learning systems advance from predictive models to generative models and autonomous agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
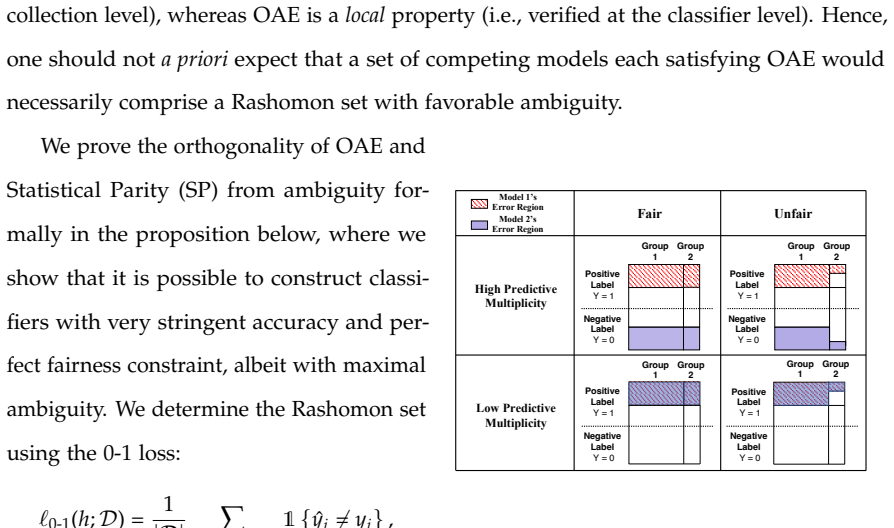
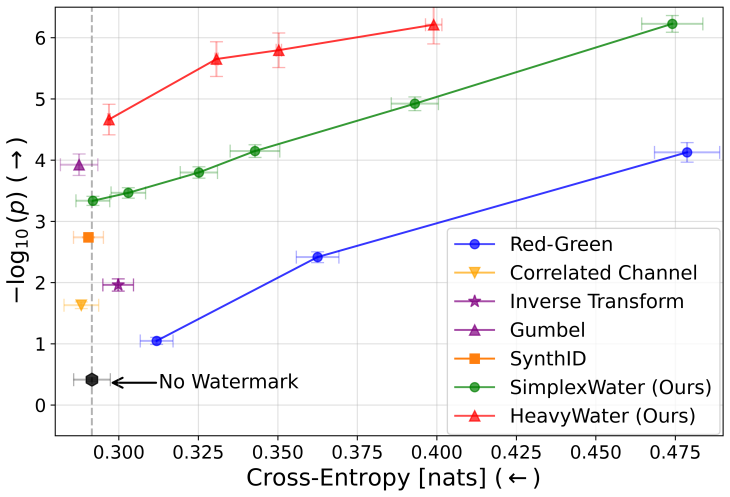
The central claim is that tools grounded in information theory, optimization, and statistical learning can mitigate bias and arbitrariness in traditional models, ensure content provenance in generative models, and evaluate the performance and risks of autonomous agents. A kernel method delivers multiaccuracy beyond conventional groups; predictive multiplicity is addressed by methods that reduce arbitrary individual decisions; watermarking strategies derived from optimal transport achieve an improved detection-distortion frontier across tasks; and the supply-chain simulator shows LLM agents outperforming humans at lower cost while surfacing tail-event vulnerabilities.
What carries the argument
Information-theoretic characterization of watermark detection versus distortion, optimized via optimal transport and coding theory, together with kernel-based multiaccuracy and a full LLM-agent supply-chain simulator.
If this is right
- Kernel-based multiaccuracy improves fairness across subpopulations that standard demographic partitions miss.
- Methods for predictive multiplicity reduce conflicting individual predictions among equally accurate models.
- Optimal-transport watermarking delivers a superior detection-quality trade-off on language and coding tasks.
- LLM agents in the supply-chain simulator outperform human teams and cut costs by up to 67 percent.
- The same agents introduce systemic risks including costly tail events.
Where Pith is reading between the lines
- The watermarking bounds could guide standards for provenance in other generative modalities such as images or structured data.
- The supply-chain simulator offers a template for testing agent behavior in additional high-stakes domains like logistics or finance.
- Integrating the multiaccuracy kernel with agent evaluation frameworks might produce fairness guarantees that extend to autonomous decision systems.
- The information-theoretic watermark trade-off might inform regulatory requirements for content traceability in deployed language models.
Load-bearing premise
Theoretical guarantees from information theory and optimization will carry over to real-world performance without major degradation when applied to complex, high-dimensional data or multi-agent interactions.
What would settle it
A deployment in which the proposed watermarks fail to maintain claimed detection rates at low text distortion levels, or in which LLM agents running in an actual supply chain neither achieve the reported cost reductions nor expose the predicted tail risks.
Figures



















read the original abstract
In this thesis, we develop algorithms with theoretical guarantees for ensuring reliability and accountability of Machine Learning (ML) systems. As ML systems evolve from predictive models to generative models and autonomous agents, the landscape of trustworthy AI has shifted. This thesis introduces tools grounded in information theory, optimization, and statistical learning to mitigate bias, reduce arbitrary decisions, ensure content provenance, and evaluate LLM-driven agents in autonomous settings. Towards mitigating bias and arbitrariness in traditional ML models, we introduce a kernel-based method to achieve multiaccuracy across complex subpopulations that traditional demographic categories may overlook. We also develop methods to address predictive multiplicity, where equally accurate models yield conflicting individual predictions. We ensure the accountability in generative AI through watermarking large language models (LLMs). We characterize the information-theoretic trade-off between watermark detection and text distortion and derive optimal watermarking strategies by leveraging optimal transport and coding theory. Empirical evaluations show our watermarks achieve a superior detection-quality tradeoff across language generation and coding tasks. Finally, we evaluate autonomous LLM agents in multi-agent environments through the first simulator of a fully LLM-driven supply chain. LLM agents offer significant performance gains, outperforming human teams and reducing costs by up to 67%, but also introduce systemic risks, including costly tail events.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This thesis develops algorithms with theoretical guarantees for trustworthy AI as ML systems progress from predictive models to generative models and autonomous agents. It introduces a kernel-based method for achieving multiaccuracy across complex subpopulations overlooked by standard demographics, methods to handle predictive multiplicity in equally accurate models, and information-theoretic watermarking for LLMs that characterizes the detection-distortion tradeoff and derives optimal strategies via optimal transport and coding theory. Empirical results are reported for superior detection-quality tradeoffs on language generation and coding tasks. The work concludes with a simulator for fully LLM-driven supply chains, claiming performance gains over human teams (including up to 67% cost reduction) alongside systemic risks such as costly tail events.
Significance. If the theoretical derivations and empirical results hold, the thesis offers a coherent pipeline of tools grounded in information theory, optimization, and statistical learning for bias mitigation, arbitrariness reduction, content provenance, and agent evaluation. The explicit pairing of guarantees with experiments on practical tasks (watermarking, multi-agent simulation) and the first reported LLM supply-chain simulator represent concrete advances that could inform deployment standards, provided the claimed performance margins and risk characterizations prove robust.
major comments (2)
- [Empirical evaluations (watermarking and supply-chain simulator)] Abstract and empirical sections: the claim of a 'superior detection-quality tradeoff' for the proposed watermarks and the 'up to 67% cost reduction' for LLM agents require explicit baselines, variance estimates, and statistical tests; without these, the superiority and risk claims cannot be evaluated as load-bearing contributions.
- [Watermarking characterization and optimal strategies] Theoretical sections on watermarking: the derivation of optimal strategies via optimal transport and coding theory is presented as yielding parameter-free or tight bounds, but the translation to high-dimensional LLM outputs and multi-agent interactions is asserted without a concrete robustness argument or counterexample analysis, which is central to the accountability claims.
minor comments (2)
- [Introduction / Abstract] The abstract and introduction would benefit from a short roadmap explicitly mapping each contribution to a chapter or section number.
- [Multiaccuracy and predictive multiplicity sections] Ensure consistent terminology for 'multiaccuracy' and 'predictive multiplicity' when first introduced, and provide a brief comparison table of the kernel method against standard fairness baselines.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our thesis. We have carefully considered the major comments and will make revisions to address the concerns regarding empirical evaluations and theoretical robustness. Below we respond point by point.
read point-by-point responses
-
Referee: Abstract and empirical sections: the claim of a 'superior detection-quality tradeoff' for the proposed watermarks and the 'up to 67% cost reduction' for LLM agents require explicit baselines, variance estimates, and statistical tests; without these, the superiority and risk claims cannot be evaluated as load-bearing contributions.
Authors: We agree that the empirical sections require explicit baselines, variance estimates, and statistical tests to substantiate the claims. In the revised version, we will include direct comparisons to established watermarking baselines (such as probability-shift and synonym-substitution methods), report means with standard deviations across multiple runs with different random seeds, and apply statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) for the detection-quality improvements on language and coding tasks. For the supply-chain simulator, we will add variance across repeated simulation episodes, explicit multi-trial human-team baselines, and statistical analysis supporting the cost-reduction figures and tail-event characterizations. revision: yes
-
Referee: Theoretical sections on watermarking: the derivation of optimal strategies via optimal transport and coding theory is presented as yielding parameter-free or tight bounds, but the translation to high-dimensional LLM outputs and multi-agent interactions is asserted without a concrete robustness argument or counterexample analysis, which is central to the accountability claims.
Authors: The optimal-transport and coding-theoretic derivations yield tight bounds in the idealized information-theoretic setting. We acknowledge that the manuscript asserts applicability to high-dimensional LLM outputs and multi-agent contexts without a dedicated robustness argument or counterexample analysis. In revision, we will expand the theoretical sections to explicitly state the assumptions (e.g., perfect token-level control and i.i.d. sampling), discuss potential looseness arising from discretization and approximation errors in high dimensions, and include a counterexample section illustrating degradation cases under realistic LLM constraints and agent interaction noise. This will strengthen the accountability claims. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The thesis structure grounds its contributions in external, established fields (information theory, optimal transport, coding theory, kernel methods, statistical learning) without evident self-referential loops. Watermarking derives optimal strategies from information-theoretic trade-offs and optimal transport, then validates via separate empirical evaluations on detection-quality tradeoffs. The LLM-agent simulator is presented as an empirical assessment of performance gains and risks, not a closed theoretical derivation. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or high-level argument that reduce the central claims to their own inputs by construction. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearkernel-based method to achieve multiaccuracy across complex subpopulations... information-theoretic trade-off between watermark detection and text distortion... first simulator of a fully LLM-driven supply chain
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearcharacterize the information-theoretic trade-off... leveraging optimal transport and coding theory
Reference graph
Works this paper leans on
-
[1]
(2024). Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act).Official Journal of the European Union, L 1689, 13 June 2024. Accessed: 2025-05-14
work page 2024
-
[2]
Aaronson, S. (2023). Watermarking of large language models. https://simons. berkeley.edu/talks/scott-aaronson-ut-austin-openai-2023-08-17 . Ac- cessed: 2025-01-1-
work page 2023
-
[3]
Agarwal, A., Beygelzimer, A., Dudík, M., Langford, J., and Wallach, H. (2018). A reductions approach to fair classification. InInternational conference on machine learning, pages 60–69. PMLR
work page 2018
-
[4]
Alghamdi, W., Hsu, H., Jeong, H., Wang, H., Michalak, P ., Asoodeh, S., and Calmon, F. (2022). Beyond adult and compas: Fair multi-class prediction via information projection. Advances in Neural Information Processing Systems, 35:38747–38760
work page 2022
- [5]
-
[6]
Bahri, D. and Jiang, H. (2021). Locally adaptive label smoothing for predictive churn. arXiv preprint arXiv:2102.05140
-
[7]
Bahri, D. and Wieting, J. (2024). A watermark for black-box language models.arXiv preprint arXiv:2410.02099
-
[8]
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., et al. (2022). Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
(2023).Fairness and machine learning: Limitations and opportunities
Barocas, S., Hardt, M., and Narayanan, A. (2023).Fairness and machine learning: Limitations and opportunities. MIT Press
work page 2023
-
[10]
K., Dey, K., Hind, M., Hoffman, S
Bellamy, R. K., Dey, K., Hind, M., Hoffman, S. C., Houde, S., Kannan, K., Lohia, P ., Martino, J., Mehta, S., Mojsilovi´ c, A., et al. (2019). Ai fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias.IBM Journal of Research and Development, 63(4/5):4–1
work page 2019
-
[11]
Berlinet, A. and Thomas-Agnan, C. (2004).Reproducing Kernel Hilbert Spaces in Probability and Statistics. Springer, 1 edition. 105
work page 2004
-
[12]
On the reproducibility of neural network predictions.arXiv preprint arXiv: 2102.03349,
Bhojanapalli, S., Wilber, K., Veit, A., Rawat, A. S., Kim, S., Menon, A., and Ku- mar, S. (2021). On the reproducibility of neural network predictions.arXiv preprint arXiv:2102.03349
- [13]
-
[14]
Black, E., Raghavan, M., and Barocas, S. (2022). Model multiplicity: Opportunities, con- cerns, and solutions. In2022 ACM Conference on Fairness, Accountability, and Transparency, pages 850–863
work page 2022
-
[15]
Blau, Y. and Michaeli, T. (2019). Rethinking lossy compression: The rate-distortion- perception tradeoff. InInternational Conference on Machine Learning, pages 675–685. PMLR
work page 2019
-
[16]
Boyd, S. P . and Vandenberghe, L. (2004).Convex optimization. Cambridge university press
work page 2004
-
[17]
Breiman, L. (1996). Bagging predictors.Machine learning, 24:123–140
work page 1996
-
[18]
Breiman, L. (2001). Statistical modeling: The two cultures (with comments and a rejoinder by the author).Statistical science, 16(3):199–231
work page 2001
-
[19]
Caton, S. and Haas, C. (2020). Fairness in machine learning: A survey.arXiv preprint arXiv:2010.04053
-
[20]
Chandra, B., Dunietz, J., and Roberts, K. (2024). Reducing risks posed by synthetic content: An overview of technical approaches to digital content transparency. Technical Report NIST.AI.100-4, National Institute of Standards and Technology, Gaithersburg, MD
work page 2024
- [21]
- [22]
-
[23]
(2000).Design and analysis of digital watermarking, information embedding, and data hiding systems
Chen, B. (2000).Design and analysis of digital watermarking, information embedding, and data hiding systems. PhD thesis, Massachusetts Institute of Technology
work page 2000
-
[24]
Chen, J., Yu, L., Wang, J., Shi, W., Ge, Y., and Tong, W. (2022). On the rate-distortion- perception function.IEEE Journal on Selected Areas in Information Theory, 3(4):664–673
work page 2022
-
[25]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P . D. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. (2021). Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Chouldechova, A. (2017). Fair prediction with disparate impact: A study of bias in recidivism prediction instruments.Big data, 5(2):153–163
work page 2017
-
[27]
Christ, M., Gunn, S., and Zamir, O. (2024). Undetectable watermarks for language models. InThe Thirty Seventh Annual Conference on Learning Theory, pages 1125–1139. PMLR. 106
work page 2024
-
[28]
Chzhen, E., Denis, C., Hebiri, M., Oneto, L., and Pontil, M. (2019). Leveraging labeled and unlabeled data for consistent fair binary classification.Advances in Neural Information Processing Systems, 32
work page 2019
-
[29]
F., Barocas, S., De Sa, C., and Sen, S
Cooper, A. F., Barocas, S., De Sa, C., and Sen, S. (2023). Variance, self-consistency, and arbitrariness in fair classification.arXiv preprint arXiv:2301.11562
-
[30]
Coston, A., Rambachan, A., and Chouldechova, A. (2021). Characterizing fairness over the set of good models under selective labels. InInternational Conference on Machine Learning, pages 2144–2155. PMLR
work page 2021
-
[31]
Cover, T. M. and Thomas, A. J. (2006).Elements of Information Theory. Wiley, New-York, 2nd edition
work page 2006
-
[32]
Creel, K. and Hellman, D. (2022). The algorithmic leviathan: arbitrariness, fairness, and opportunity in algorithmic decision-making systems.Canadian Journal of Philosophy, 52(1):26–43
work page 2022
-
[33]
Cui, P ., Hu, W., and Zhu, J. (2020). Calibrated reliable regression using maximum mean discrepancy. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H., editors, Advances in Neural Information Processing Systems, volume 33, pages 17164–17175. Curran Associates, Inc
work page 2020
-
[34]
Cury, C. R. J. (2022). Instituto nacional de estudos e pesquisas educacionais anísio teixeira: uma trajetória em busca de uma educação de qualidade
work page 2022
-
[35]
Cuturi, M. (2013). Sinkhorn distances: Lightspeed computation of optimal transport. Advances in neural information processing systems, 26
work page 2013
-
[36]
D’Amour, A., Heller, K., Moldovan, D., Adlam, B., Alipanahi, B., Beutel, A., Chen, C., Deaton, J., Eisenstein, J., Hoffman, M. D., et al. (2022). Underspecification presents challenges for credibility in modern machine learning.The Journal of Machine Learning Research, 23(1):10237–10297
work page 2022
-
[37]
Dathathri, S., See, A., Ghaisas, S., Huang, P .-S., McAdam, R., Welbl, J., Bachani, V ., Kaskasoli, A., Stanforth, R., Matejovicova, T., et al. (2024). Scalable watermarking for identifying large language model outputs.Nature, 634(8035):818–823
work page 2024
-
[38]
Dawid, A. P . (1982). The well-calibrated bayesian.Journal of the American Statistical Association, 77(379):605–610
work page 1982
- [39]
-
[40]
Diaconis, P . and Freedman, D. (1980). Finite exchangeable sequences.The Annals of Probability, pages 745–764
work page 1980
-
[41]
Dwork, C., Feldman, V ., Hardt, M., Pitassi, T., Reingold, O., and Roth, A. L. (2015). Preserving statistical validity in adaptive data analysis. InProceedings of the forty-seventh annual ACM symposium on Theory of computing, pages 117–126. 107
work page 2015
-
[42]
Dwork, C., Hardt, M., Pitassi, T., Reingold, O., and Zemel, R. (2012). Fairness through awareness. InProceedings of the 3rd Innovations in Theoretical Computer Science Conference, ITCS ’12, page 214–226, New York, NY, USA. Association for Computing Machinery
work page 2012
-
[43]
P ., Reingold, O., Rothblum, G
Dwork, C., Kim, M. P ., Reingold, O., Rothblum, G. N., and Yona, G. (2021). Outcome indistinguishability. InProceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pages 1095–1108
work page 2021
-
[44]
Dwork, C., Lee, D., Lin, H., and Tankala, P . (2023). From pseudorandomness to multi- group fairness and back. InThe Thirty Sixth Annual Conference on Learning Theory, pages 3566–3614. PMLR
work page 2023
-
[45]
Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir R
Fabbri, A. R., Li, I., She, T., Li, S., and Radev, D. R. (2019). Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model.arXiv preprint arXiv:1906.01749
-
[46]
Fairoze, J., Garg, S., Jha, S., Mahloujifar, S., Mahmoody, M., and Wang, M. (2025). Publicly-detectable watermarking for language models.IACR Communications in Cryptol- ogy, 1(4)
work page 2025
- [47]
-
[48]
Feldman, V . (2009). Distribution-specific agnostic boosting. InInternational Conference on Supercomputing
work page 2009
-
[49]
Fernandez, P ., Chaffin, A., Tit, K., Chappelier, V ., and Furon, T. (2023). Three bricks to consolidate watermarks for large language models. In2023 IEEE International Workshop on Information Forensics and Security (WIFS), pages 1–6. IEEE
work page 2023
-
[50]
Fisher, A., Rudin, C., and Dominici, F. (2019). All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously.J. Mach. Learn. Res., 20(177):1–81
work page 2019
-
[51]
Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., et al
Flamary, R., Courty, N., Gramfort, A., Alaya, M. Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., et al. (2021). Pot: Python optimal transport.Journal of Machine Learning Research, 22(78):1–8
work page 2021
-
[52]
A., Scheidegger, C., Venkatasubramanian, S., Choudhary, S., Hamilton, E
Friedler, S. A., Scheidegger, C., Venkatasubramanian, S., Choudhary, S., Hamilton, E. P ., and Roth, D. (2019). A comparative study of fairness-enhancing interventions in machine learning. InProceedings of the conference on fairness, accountability, and transparency, pages 329–338
work page 2019
- [53]
-
[54]
Ganesh, P ., Chang, H., Strobel, M., and Shokri, R. (2023). On the impact of machine learning randomness on group fairness. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’23, pages 1789–1800, New York, NY, USA. Association for Computing Machinery. 108
work page 2023
-
[55]
Garg, S., Jung, C., Reingold, O., and Roth, A. (2024). Oracle efficient online multicali- bration and omniprediction. InProceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2725–2792. SIAM
work page 2024
-
[56]
Gel’Fand, I. and Pinsker, M. (1980). Coding for channels with random parameters. Probl. Contr. Inform. Theory, 9(1):19–31
work page 1980
-
[57]
Geva, M., Schuster, R., Berant, J., and Levy, O. (2021). Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495
work page 2021
-
[58]
Giboulot, E. and Furon, T. (2024). Watermax: breaking the llm watermark detectability- robustness-quality trade-off.arXiv preprint arXiv:2403.04808
- [59]
- [60]
-
[61]
Goodrich, R. K. (1970). A riesz representation theorem. InProc. Amer. Math. Soc, volume 24, pages 629–636
work page 1970
-
[62]
P ., Reingold, O., and Wieder, U
Gopalan, P ., Hu, L., Kim, M. P ., Reingold, O., and Wieder, U. (2022). Loss minimization through the lens of outcome indistinguishability.arXiv preprint arXiv:2210.08649
-
[63]
T., Reingold, O., Sharan, V ., and Wieder, U
Gopalan, P ., Kalai, A. T., Reingold, O., Sharan, V ., and Wieder, U. (2021). Omnipredictors. arXiv preprint arXiv:2109.05389
-
[65]
Gretton, A., Borgwardt, K., Rasch, M., Schölkopf, B., and Smola, A. (2006). A kernel method for the two-sample-problem.Advances in neural information processing systems, 19
work page 2006
-
[66]
Gurobi Optimizer Reference Manual
Gurobi Optimization, LLC (2024). Gurobi Optimizer Reference Manual
work page 2024
-
[67]
Haghtalab, N., Jordan, M., and Zhao, E. (2024). A unifying perspective on multi- calibration: Game dynamics for multi-objective learning.Advances in Neural Information Processing Systems, 36
work page 2024
-
[68]
Hajek, B. and Raginsky, M. (2019). Statistical learning theory.Lecture Notes, 387
work page 2019
-
[69]
Hardt, M., Price, E., and Srebro, N. (2016). Equality of opportunity in supervised learning.Advances in neural information processing systems, 29
work page 2016
- [70]
-
[71]
He, H., Liu, Y., Wang, Z., Mao, Y., and Bu, Y. (2025). Theoretically grounded framework for llm watermarking: A distribution-adaptive approach. InThe 1st Workshop on GenAI Watermarking
work page 2025
-
[72]
Hébert-Johnson, U., Kim, M., Reingold, O., and Rothblum, G. (2018). Multicalibration: Calibration for the (computationally-identifiable) masses. InInternational Conference on Machine Learning, pages 1939–1948. PMLR
work page 2018
-
[73]
Hine, E. and Floridi, L. (2023). The blueprint for an ai bill of rights: in search of enaction, at risk of inaction.Minds and Machines, pages 1–8
work page 2023
-
[74]
Hort, M., Chen, Z., Zhang, J. M., Sarro, F., and Harman, M. (2022). Bia mitigation for machine learning classifiers: A comprehensive survey.arXiv preprint arXiv:2207.07068
-
[75]
Hou, A., Zhang, J., He, T., Wang, Y., Chuang, Y.-S., Wang, H., Shen, L., Van Durme, B., Khashabi, D., and Tsvetkov, Y. (2024). Semstamp: A semantic watermark with paraphrastic robustness for text generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
work page 2024
-
[76]
Hsu, H. and Calmon, F. d. P . (2022). Rashomon capacity: A metric for predictive multiplicity in probabilistic classification.arXiv preprint arXiv:2206.01295
-
[77]
Hu, Z., Chen, L., Wu, X., Wu, Y., Zhang, H., and Huang, H. (2024). Unbiased watermark for large language models. InThe Twelfth International Conference on Learning Representations
work page 2024
-
[78]
Huang, B. and Wan, X. (2024). Waterpool: A watermark mitigating trade-offs among imperceptibility, efficacy and robustness.arXiv preprint arXiv:2405.13517
-
[79]
Huang, B., Zhu, H., Zhu, B., Ramchandran, K., Jordan, M. I., Lee, J. D., and Jiao, J. (2023). Towards optimal statistical watermarking.arXiv preprint arXiv:2312.07930
- [80]
-
[81]
Huijben, I. A., Kool, W., Paulus, M. B., and Van Sloun, R. J. (2022). A review of the gumbel-max trick and its extensions for discrete stochasticity in machine learning.IEEE transactions on pattern analysis and machine intelligence, 45(2):1353–1371
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.