Recognition: no theorem link
VORT: Adaptive Power-Law Memory for NLP Transformers
Pith reviewed 2026-05-12 01:55 UTC · model grok-4.3
The pith
VORT lets each token learn its own power-law memory decay rate inside a transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Variable-Order Retention Transformer assigns each token a learnable fractional order alpha in [delta,1] that defines a Grünwald-Letnikov power-law retention kernel. This non-Markovian sum is replaced by a sum-of-exponentials approximation obtained from Gauss-Laguerre quadrature on the Laplace integral of the kernel, yielding an O(S d_v) Markovian recurrence per step with S logarithmic in horizon length. An SOE convergence theorem, a quantization bound on [delta,1], an L2 lower bound showing unbounded error for any fixed-minimum-decay mixture when alpha exceeds 1/2, and linear convergence of a gradient plasticity rule under the Polyak-Lojasiewicz condition are all proved.
What carries the argument
The sum-of-exponentials approximation of the Grünwald-Letnikov power-law kernel, obtained by Gauss-Laguerre quadrature on its Laplace integral representation, which converts the fractional retention into parallel linear recurrences.
If this is right
- Memory over any horizon T can be kept to uniform epsilon error with only O(log(T/epsilon)) exponential terms.
- Any mixture of fixed exponential decays incurs L2 error on [1,T] that grows without bound relative to a true power-law kernel when the order exceeds 1/2.
- Keyed associative retrieval remains possible with an exact linear-attention accumulator at O(K S d_phi d_v) cost per step.
- A simple gradient plasticity rule converges linearly whenever the training loss satisfies the Polyak-Lojasiewicz condition.
Where Pith is reading between the lines
- The per-token alpha values could let the model automatically allocate longer memory to some tokens and shorter memory to others, something fixed-kernel models cannot do.
- The same SOE technique might be applied to other sequence models that currently rely on exponential decay, such as state-space or recurrent architectures.
- If the learned alphas on real text cluster around particular values, that distribution itself could become a diagnostic for the typical range of long-range dependencies in language.
- Replacing the synthetic Zipf and lag-copy tasks with real long-document modeling would test whether the power-law advantage survives the noise of actual data.
Load-bearing premise
Power-law long-range dependencies are the dominant structure that ordinary transformers miss, and the fixed-term sum-of-exponentials approximation remains accurate enough throughout end-to-end training on real data.
What would settle it
Run VORT on a long-document question-answering benchmark; if accuracy does not exceed a standard transformer baseline or if the learned alpha values all cluster near 1 instead of spreading through the interval, the claimed advantage is refuted.
Figures

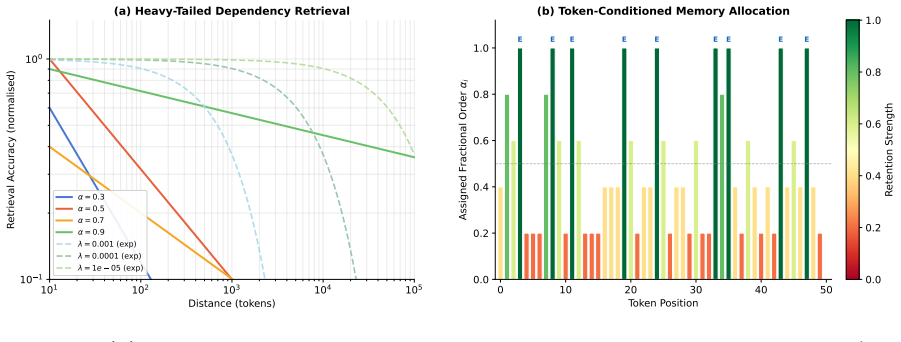


read the original abstract
Standard Transformers impose near-exponential decay on the influence of distant tokens, conflicting with the power-law structure of long-range dependencies in natural language. We introduce the \emph{Variable-Order Retention Transformer} (\VORT{}), a memory architecture in which each ingested token is assigned a learnable fractional order \alpha_i\in[\delta,1] that governs a Gr\"unwald--Letnikov power-law retention kernel. Because the fractional weighted sum is non-Markovian, we approximate it through a sum-of-exponentials (SOE) decomposition computed by Gauss--Laguerre quadrature on a Laplace-type integral representation of the kernel weights. Each exponential component admits a one-step Markovian recurrence at O(Sd_v) per step, where S=O(\log(T/\varepsilon)) terms suffice for \varepsilon-uniform accuracy on horizon [1,T]. Retrieval is keyed and associative via a linear-attention accumulator with an exact O(KSd_\phi d_v) -per-step recurrence. Four results are established: (i) an SOE approximation theorem with geometric convergence rate from the analyticity of the integrand after a log-change of variables; (ii) a quantisation bound valid on [\delta,1] with correct analysis near \alpha=0; (iii) a direct L^2 energy argument (Proposition) showing that for \alpha>1/2 any mixture with fixed minimum decay rate \Lambda>0 incurs L^2([1,T]) error at least N_\alpha(T)-C(\Lambda)\to\infty, with the \Lambda-dependence made explicit; and (iv) linear convergence of a gradient plasticity rule under the Polyak--\L{}ojasiewicz condition. Two synthetic experiments confirm the architectural advantage: a Zipf-distributed retrieval benchmark and an entity label-copy task with uniform lag distribution, the latter ruling out prior-matching as an explanation for the power-law kernel's advantage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Variable-Order Retention Transformer (VORT), which assigns each ingested token a learnable fractional order α_i ∈ [δ,1] to define a Grünwald–Letnikov power-law retention kernel. The non-Markovian weighted sum is approximated by a sum-of-exponentials (SOE) decomposition via Gauss–Laguerre quadrature on a Laplace integral representation, yielding an O(S d_v) per-step Markovian recurrence with S = O(log(T/ε)) for ε-uniform accuracy on [1,T]. Retrieval uses a keyed linear-attention accumulator. Four results are proved: (i) an SOE approximation theorem with geometric convergence from analyticity after log-change of variables; (ii) a quantization bound on [δ,1] with analysis near α=0; (iii) an L² energy lower bound showing that any fixed-minimum-decay mixture incurs unbounded L²([1,T]) error for α>1/2; and (iv) linear convergence of a gradient plasticity rule under the Polyak–Łojasiewicz condition. Two synthetic experiments (Zipf retrieval benchmark and uniform-lag entity label-copy) confirm the architectural advantage.
Significance. If the central claims hold, the work supplies a mathematically grounded mechanism for adaptive power-law memory in transformers, directly addressing the exponential-decay limitation of standard attention. Strengths include the SOE approximation theorem with explicit geometric rate, the explicit L² lower-bound argument with Λ-dependence, the Polyak–Łojasiewicz convergence result, and synthetic experiments that test the hypothesized advantage rather than fitting to a pre-specified target. These elements could influence long-context NLP architectures if the recurrence efficiency is clarified.
major comments (1)
- Abstract (recurrence claim): The stated O(S d_v) per-step recurrence with fixed S = O(log(T/ε)) appears incompatible with per-token learnable α_i. Each token’s distinct Grünwald–Letnikov kernel produces its own set of S exponential components; maintaining and decaying these independently causes the state dimension to grow linearly with sequence length, contradicting the fixed-size Markovian claim. If α is instead shared (e.g., per head), the phrasing “each ingested token” is inaccurate and the per-token adaptivity central to the power-law motivation disappears. This issue is load-bearing for the architectural efficiency and the variable-order retention motivation.
minor comments (2)
- The abstract mentions four theorems and two synthetic experiments but provides no error-bar details, data-exclusion rules, or explicit statements of the Polyak–Łojasiewicz parameters; these should be added for reproducibility.
- Notation for the SOE state update and the exact form of the keyed linear-attention accumulator recurrence should be clarified with a small diagram or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the potential inconsistency between the per-token α_i and the claimed fixed-size Markovian recurrence. The comment is well-taken and points to an ambiguity in the abstract's phrasing. We clarify the architecture below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract (recurrence claim): The stated O(S d_v) per-step recurrence with fixed S = O(log(T/ε)) appears incompatible with per-token learnable α_i. Each token’s distinct Grünwald–Letnikov kernel produces its own set of S exponential components; maintaining and decaying these independently causes the state dimension to grow linearly with sequence length, contradicting the fixed-size Markovian claim. If α is instead shared (e.g., per head), the phrasing “each ingested token” is inaccurate and the per-token adaptivity central to the power-law motivation disappears. This issue is load-bearing for the architectural efficiency and the variable-order retention motivation.
Authors: We thank the referee for identifying this important point. The apparent incompatibility stems from the assumption that each α_i requires its own distinct set of exponential bases. In the VORT construction, the SOE approximation is obtained by Gauss–Laguerre quadrature on the Laplace integral representation of the kernel after a log-change of variables (see Section 3 and Theorem 1). This yields a fixed collection of quadrature nodes s_j (hence fixed decay rates) that do not depend on α. The α-dependence is confined to the quadrature weights w_j(α), which are evaluated per token at ingestion time. The memory state is therefore realized by S parallel recurrences state_j^{(t)} = exp(−s_j) · state_j^{(t−1)} + w_j(α_t) · v_t. The state dimension remains O(S d_v) independently of sequence length and of how many distinct α_i appear. Per-token adaptivity is fully preserved because each token’s α_i directly modulates the injection coefficients into the shared bases. We will revise the abstract to read “each ingested token is assigned a learnable fractional order α_i that modulates the coefficients of a shared sum-of-exponentials approximation” and will add an analogous clarifying sentence in the method section. This preserves both the efficiency claim and the per-token motivation. revision: yes
Circularity Check
No significant circularity; theorems rely on independent analytic and energy arguments
full rationale
The four established results—an SOE approximation theorem via analyticity after log-change of variables, a quantization bound on [δ,1], an L² energy lower bound for mixtures with fixed decay, and linear convergence under Polyak-Łojasiewicz—are derived from standard quadrature, direct energy estimates, and classical optimization theory. These steps do not reduce by construction to the architectural claims or to self-citations; the synthetic experiments test the hypothesized advantage on Zipf and lag-copy tasks without pre-fitting targets. The per-token α_i recurrence description, while potentially inconsistent with fixed-state O(S d_v) complexity, is an implementation claim rather than a load-bearing derivation that collapses into its own inputs.
Axiom & Free-Parameter Ledger
free parameters (3)
- α_i
- S =
O(log(T/ε))
- δ
axioms (3)
- standard math Grünwald-Letnikov definition of the fractional integral for the retention kernel.
- standard math Existence of a Laplace-type integral representation that permits Gauss-Laguerre quadrature after log substitution.
- domain assumption Polyak-Łojasiewicz condition for the loss landscape.
invented entities (1)
-
Variable-Order Retention mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
G. Altmann, E. G. Altmann, and M. Gerlach. Beyond word frequency: Bursts, lulls, and scaling in the temporal distributions of words.PLoS ONE, 4(11):e7678, 2009
work page 2009
-
[2]
Gemini: A Family of Highly Capable Multimodal Models
R. Anil et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, and A. Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
Beran.Statistics for Long-Memory Processes
J. Beran.Statistics for Long-Memory Processes. Chapman & Hall, New York, 1994
work page 1994
-
[5]
P. J. Brockwell and R. A. Davis.Time Series: Theory and Methods, 2nd edition. Springer-Verlag, New York, 1991
work page 1991
-
[6]
T. B. Brown et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
work page 1901
-
[7]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, and I. Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[8]
K. Choromanski et al. Rethinking attention with performers. InInternational Conference on Learning Representations, 2021
work page 2021
-
[9]
PaLM: Scaling Language Modeling with Pathways
A. Chowdhery et al. PaLM: Scaling language modeling with pathways.arXiv preprint arXiv:2204.02311, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
J. P. Crutchfield and D. P. Feldman. Regularities unseen, randomness observed: Levels of entropy convergence.Chaos, 13(1):25–54, 2003
work page 2003
-
[11]
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. Ré. FlashAttention: Fast and memory- efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems, volume 35, pages 16344–16359, 2022
work page 2022
-
[12]
W. Ebeling and G. Nicolis. Word frequency and entropy of symbolic sequences.Chaos, Solitons & Fractals, 2(6):635–650, 1992. 15
work page 1992
-
[13]
A. A. Gonchar and E. A. Rakhmanov. Equilibrium distributions and the rate of rational approximation of analytic functions.Mathematics of the USSR-Sbornik, 62 (2):305–348, 1987
work page 1987
-
[14]
C. W. J. Granger and R. Joyeux. An introduction to long-memory time series models and fractional differencing.Journal of Time Series Analysis, 1(1):15–29, 1980
work page 1980
-
[15]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
A. Gu, K. Goel, and C. Ré. Efficiently modeling long sequences with structured state spaces. InInternational Conference on Learning Representations, 2022
work page 2022
- [17]
-
[18]
C. Hooper et al. KVQuant: Towards 10 million context length LLM inference with KV cache quantization.arXiv preprint arXiv:2401.18079, 2024
-
[19]
J. R. M. Hosking. Fractional differencing.Biometrika, 68(1):165–176, 1981
work page 1981
-
[20]
RULER: What's the Real Context Size of Your Long-Context Language Models?
C.-Y. Hsieh et al. RULER: What’s the real context window size of your LLM?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
J. Jumper et al. Highly accurate protein structure prediction with AlphaFold.Nature, 596:583–589, 2021
work page 2021
-
[22]
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. InProceedings of the 37th ICML, pages 5156–5165. PMLR, 2020
work page 2020
- [23]
-
[24]
B. M. Lake and M. Baroni. Generalization without systematicity. InProceedings of the 35th ICML, pages 2879–2888. PMLR, 2018
work page 2018
-
[25]
SnapKV: LLM Knows What You are Looking for Before Generation
Y. Li et al. SnapKV: LLM knows what you are looking for before generation.arXiv preprint arXiv:2404.14469, 2024
work page internal anchor Pith review arXiv 2024
-
[26]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InICLR, 2019
work page 2019
-
[27]
C. Lubich. Discretized fractional calculus.SIAM Journal on Mathematical Analysis, 17(3):704–719, 1986
work page 1986
-
[28]
K. S. Miller and B. Ross.An Introduction to the Fractional Calculus and Fractional Differential Equations. John Wiley & Sons, New York, 1993
work page 1993
-
[29]
C. A. Monje, Y. Chen, B. M. Vinagre, D. Xue, and V. Feliu.Fractional-Order Systems and Controls. Springer, London, 2010
work page 2010
-
[30]
K. B. Oldham and J. Spanier.The Fractional Calculus. Academic Press, New York, 1974
work page 1974
-
[31]
A. Orvieto et al. Resurrecting recurrent neural networks for long sequences. In Proceedings of the 40th ICML, pages 26670–26698. PMLR, 2023. 16
work page 2023
-
[32]
B. Peng et al. RWKV: Reinventing RNNs for the transformer era. InFindings of EMNLP 2023, pages 14048–14077. ACL, 2023
work page 2023
-
[33]
Podlubny.Fractional Differential Equations
I. Podlubny.Fractional Differential Equations. Academic Press, San Diego, 1999
work page 1999
- [34]
-
[35]
A. Radford et al. Learning transferable visual models from natural language supervi- sion. InProceedings of the 38th ICML, pages 8748–8763. PMLR, 2021
work page 2021
-
[36]
J. W. Rae et al. Compressive transformers for long-range sequence modelling. In ICLR, 2020
work page 2020
-
[37]
C. Raffel et al. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
work page 2020
-
[38]
S. G. Samko, A. A. Kilbas, and O. I. Marichev.Fractional Integrals and Derivatives: Theory and Applications. Gordon and Breach, Yverdon, 1993
work page 1993
-
[39]
P. Shaw, J. Uszkoreit, and A. Vaswani. Self-attention with relative position represen- tations. InProceedings of NAACL-HLT 2018, pages 464–468. ACL, 2018
work page 2018
-
[40]
I. M. Sokolov and J. Klafter. From diffusion to anomalous diffusion: A century after Einstein’s Brownian motion.Chaos, 15(2):026103, 2005
work page 2005
-
[41]
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[42]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, pages 5998–6008, 2017
work page 2017
-
[44]
S. Wang, B. Z. Li, M. Khabsa, H. Fang, and H. Ma. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
- [45]
-
[46]
Towards ai-complete question answering: A set of prerequisite toy tasks
J. Weston et al. Towards AI-complete question answering: A set of prerequisite toy tasks.arXiv preprint arXiv:1502.05698, 2015
-
[47]
Wiener.Extrapolation, Interpolation and Smoothing of Stationary Time Series
N. Wiener.Extrapolation, Interpolation and Smoothing of Stationary Time Series. MIT Press, Cambridge, MA, 1949
work page 1949
- [48]
-
[49]
M. Zaheer et al. Big bird: Transformers for longer sequences. InAdvances in Neural Information Processing Systems, volume 33, pages 17283–17297, 2020. 17
work page 2020
-
[50]
Z. Zhang et al. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[51]
G. K. Zipf.The Psycho-Biology of Language. Houghton Mifflin, Boston, MA, 1935. 18
work page 1935
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.