Recognition: no theorem link
When More Parameters Hurt: Foundation Model Priors Amplify Worst-Client Disparity Under Extreme Federated Heterogeneity
Pith reviewed 2026-05-12 02:36 UTC · model grok-4.3
The pith
Foundation model priors amplify worst-client accuracy gaps under extreme federated label skew.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
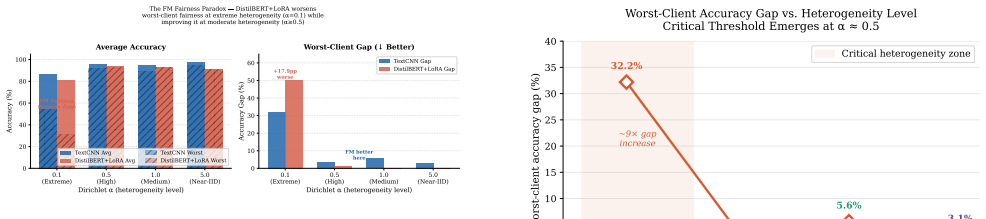
Under extreme label skew (Dirichlet alpha = 0.1), DistilBERT+LoRA yields a worst-client accuracy gap of 50.1 percent, 56 percent larger than the 32.2 percent gap produced by TextCNN, despite 25 times more parameters and extensive pretraining. At moderate heterogeneity (alpha >= 0.5) the pattern inverts and the foundation model reduces disparity. An inverse-weighted LoRA aggregation variant fails to close the gap, indicating that the priors embedded in the foundation model can systematically disadvantage clients with atypical label distributions.
What carries the argument
The FM Fairness Paradox, measured by comparing worst-client accuracy between a small CNN and a LoRA-adapted foundation model across four levels of Dirichlet-controlled label skew.
If this is right
- Under extreme heterogeneity, foundation models increase rather than reduce accuracy disparity for the most disadvantaged clients.
- Moderate heterogeneity allows the same foundation models to improve fairness across clients.
- Standard aggregation reweighting is insufficient to counteract the effect.
- High-stakes federated deployments such as healthcare or education require explicit mechanisms to protect minority clients.
Where Pith is reading between the lines
- Client-specific regularization or prompt-based adaptation may be needed to offset the influence of shared priors.
- The same pattern could appear when foundation models are fine-tuned on image or speech data under extreme non-IID partitions.
- Testing the effect across multiple foundation model families would clarify whether the disparity scales with model size or pretraining corpus.
Load-bearing premise
The larger worst-client disparity is caused by the foundation model's pretraining priors rather than by LoRA adaptation, differences in model architecture, or the specific way heterogeneity was generated.
What would settle it
Re-running the same controlled experiments on a different foundation model or with full fine-tuning instead of LoRA and observing no increase (or a decrease) in the worst-client gap at alpha = 0.1 would falsify the central claim.
Figures


read the original abstract
Federated learning (FL) is increasingly used to fine-tune foundation models (FMs) on distributed private data. The community largely assumes that large-scale pretraining serves as a 'rising tide that lifts all boats' in federated settings. However, our experiments reveal that these powerful priors can hinder rather than help the most disadvantaged clients under extreme heterogeneity. Through controlled experiments on federated text classification, we compare worst-client accuracy between TextCNN (2.7M parameters) and DistilBERT with Low-Rank Adaptation (LoRA, 66M parameters) across four Non-IID heterogeneity levels. Under extreme label skew (alpha = 0.1), DistilBERT+LoRA produces a worst-client accuracy gap of 50.1% -- 56% larger than TextCNN's 32.2% gap, despite having 25x more parameters and extensive pretraining. Under moderate heterogeneity (alpha >= 0.5), the pattern reverses: the FM nearly eliminates the gap. We call this the FM Fairness Paradox. We further show that an inverse-weighted LoRA aggregation method (FedAvgW) does not resolve the disparity, suggesting aggregation reweighting alone may be insufficient. Our results highlight the need for mechanisms that explicitly protect minority clients before deploying foundation models in high-stakes federated contexts such as healthcare and education.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that foundation model priors amplify worst-client disparity in federated learning under extreme heterogeneity. Through text classification experiments, it shows that under Dirichlet label skew with alpha=0.1, DistilBERT+LoRA (66M params) yields a 50.1% worst-client accuracy gap, 56% larger than TextCNN's 32.2% gap (2.7M params), despite pretraining and greater capacity. The pattern reverses for alpha >=0.5. An inverse-weighted aggregation (FedAvgW) fails to close the gap, leading to the 'FM Fairness Paradox' and a call for mechanisms protecting minority clients.
Significance. If the attribution to foundation model priors holds after isolating confounders, the result would be significant for federated fine-tuning of large models in heterogeneous, high-stakes domains. It provides empirical counter-evidence to the 'rising tide' assumption and motivates new fairness techniques beyond standard aggregation. The controlled comparison across heterogeneity levels is a strength, though the current design limits causal claims.
major comments (2)
- [Abstract and experimental design] The central claim attributes the 50.1% vs 32.2% worst-client gap under alpha=0.1 to foundation model priors. However, the design compares TextCNN (trained from scratch) against DistilBERT+LoRA (pretrained weights with low-rank adaptation). This confounds priors with architecture (CNN vs transformer), capacity (2.7M vs 66M), optimization, and adaptation method. No controls such as randomly initialized DistilBERT or matched-capacity non-pretrained models are described to isolate the priors' effect (Abstract; experimental sections).
- [Results] The reported accuracy gaps and the 56% larger disparity lack error bars, standard deviations across random seeds, or statistical tests. This makes it difficult to assess whether the FM Fairness Paradox observation is robust or reproducible (Results and tables).
minor comments (2)
- [Experimental setup] Expand the experimental protocol section with exact client count, local epochs, communication rounds, optimizer settings, and precise Dirichlet sampling procedure to enable full reproducibility.
- Consider adding a table or figure showing per-client accuracy distributions or additional heterogeneity metrics (e.g., label distribution entropy) to better illustrate the worst-client disparity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental controls and statistical rigor that we will address in the revision to strengthen the attribution of results to foundation model priors.
read point-by-point responses
-
Referee: [Abstract and experimental design] The central claim attributes the 50.1% vs 32.2% worst-client gap under alpha=0.1 to foundation model priors. However, the design compares TextCNN (trained from scratch) against DistilBERT+LoRA (pretrained weights with low-rank adaptation). This confounds priors with architecture (CNN vs transformer), capacity (2.7M vs 66M), optimization, and adaptation method. No controls such as randomly initialized DistilBERT or matched-capacity non-pretrained models are described to isolate the priors' effect (Abstract; experimental sections).
Authors: We agree that the experimental comparison confounds the effect of pretrained priors with differences in architecture, capacity, optimization, and adaptation method. The design was chosen to reflect realistic FL scenarios (small from-scratch models vs. practical FM fine-tuning with LoRA), and the larger gap despite greater capacity and pretraining already provides counter-evidence to the 'rising tide' assumption. To more cleanly isolate the priors, we will add control experiments with randomly initialized DistilBERT (no pretraining) and matched-capacity non-pretrained transformer baselines in the revised manuscript, allowing direct attribution while preserving the original comparisons. revision: yes
-
Referee: [Results] The reported accuracy gaps and the 56% larger disparity lack error bars, standard deviations across random seeds, or statistical tests. This makes it difficult to assess whether the FM Fairness Paradox observation is robust or reproducible (Results and tables).
Authors: We acknowledge that variability measures are essential for assessing robustness. In the revision, we will rerun all experiments across at least five random seeds, report standard deviations as error bars in tables and figures, and include statistical tests (e.g., paired t-tests) to evaluate the significance of the worst-client accuracy gaps and the 56% relative increase under alpha=0.1. revision: yes
Circularity Check
No circularity: purely empirical comparison of measured accuracy gaps
full rationale
The paper reports direct experimental measurements of worst-client accuracy under controlled federated heterogeneity settings (alpha=0.1 and higher). It compares two distinct models (TextCNN trained from scratch vs. DistilBERT+LoRA) on the same task and data partitions, presenting the 50.1% vs 32.2% gap as an observed outcome rather than a derived prediction. No equations, parameter fits, self-referential definitions, or load-bearing self-citations are used to generate the central claim; the result does not reduce to its inputs by construction. The FM Fairness Paradox is simply a label for the empirical pattern. This is the expected non-finding for an empirical study whose claims rest on falsifiable measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Non-IID client data distributions can be simulated using a Dirichlet distribution parameterized by alpha
Reference graph
Works this paper leans on
-
[1]
[Dettmers et al., 2024] Dettmers, T.; Pagnoni, A.; Holtzman, A.; and Zettlemoyer, L
work page 2024
-
[2]
[Dinh, Tran, and Nguyen, 2020] Dinh, C. T.; Tran, N. H.; and Nguyen, T. A
work page 2020
-
[3]
InAdvances in Neural Infor- mation Processing Systems (NeurIPS), volume 33, 21394– 21405
Personalized federated learn- ing with Moreau envelopes. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), volume 33, 21394– 21405. [Fallah, Mokhtari, and Ozdaglar, 2020] Fallah, A.; Mokhtari, A.; and Ozdaglar, A
work page 2020
-
[4]
InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, 9143–9154
Personalized federated learning with theoretical guarantees: A model- agnostic meta-learning approach. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, 9143–9154. [Go, Bhayani, and Huang, 2009] Go, A.; Bhayani, R.; and Huang, L
work page 2009
-
[5]
Technical report, Stanford University
Twitter sentiment classification using distant supervision. Technical report, Stanford University. CS224N Project Report. [Hard et al., 2018] Hard, A.; Rao, K.; Mathews, R.; Beau- fays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; and Ra- mage, D
work page 2018
-
[6]
Federated Learning for Mobile Keyboard Prediction
Federated learning for mobile keyboard prediction.arXiv preprint arXiv:1811.03604. [Hsu, Qi, and Brown, 2019] Hsu, T.-M. H.; Qi, H.; and Brown, M
work page Pith review arXiv 2019
-
[7]
Measuring the effects of non-IID data on federated learning.arXiv preprint arXiv:1909.06335. [Hu et al., 2022] Hu, E. J.; Shen, Y .; Wallis, P.; Allen-Zhu, Z.; Li, Y .; Wang, S.; Wang, L.; and Chen, W
-
[8]
InInter- national Conference on Learning Representations (ICLR)
LoRA: Low-rank adaptation of large language models. InInter- national Conference on Learning Representations (ICLR). [Jiang, Li, and Song, 2025a] Jiang, Y .; Li, Z.; and Song, B. 2025a. Fairness-aware prompt selection for federated LLMs.Neural Networks182:106883. [Jiang, Li, and Song, 2025b] Jiang, Y .; Li, Z.; and Song, B. 2025b. Fairness-aware prompt se...
work page 2024
-
[9]
[Karimireddy et al., 2020] Karimireddy, S
Non-IID data in federated learning: A survey with taxonomy, metrics, methods, frameworks and future directions.arXiv preprint arXiv:2411.12377. [Karimireddy et al., 2020] Karimireddy, S. P.; Kale, S.; Mohri, M.; Reddi, S. J.; Stich, S. U.; and Suresh, A. T
-
[10]
Convolutional neural networks for sentence classification. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1746–1751. [Li et al., 2020a] Li, T.; Sahu, A. K.; Sanjabi, M.; Zaheer, M.; Talwalkar, A.; and Smith, V . 2020a. Federated op- timization in heterogeneous networks. InProceedings of Machine Learning a...
work page 2014
-
[11]
[Li et al., 2020b] Li, T.; Sanjabi, M.; Beirami, A.; and Smith, V . 2020b. Fair resource allocation in federated learning. InInternational Conference on Learning Representations (ICLR). [Li et al., 2021a] Li, T.; Hu, S.; Beirami, A.; and Smith, V . 2021a. Ditto: Fair and robust federated learning through personalization. InProceedings of the 38th Internat...
work page 2022
-
[12]
[McMahan et al., 2017] McMahan, B.; Moore, E.; Ram- age, D.; Hampson, S.; and Agüera y Arcas, B
work page 2017
-
[13]
Communication-efficient learning of deep networks from decentralized data. InProceedings of the 20th Interna- tional Conference on Artificial Intelligence and Statistics (AISTATS), 1273–1282. [Sanh et al., 2019] Sanh, V .; Debut, L.; Chaumond, J.; and Wolf, T
work page 2019
-
[14]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108. [Shi, Yu, and Leung, 2023] Shi, Y .; Yu, K.; and Leung, V . C. M
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[15]
arXiv preprint arXiv:2311.02641
A survey of fairness-aware federated learning. arXiv preprint arXiv:2311.02641. [Woisetschläger et al., 2024] Woisetschläger, J. et al
-
[16]
[Zhang, Zhao, and LeCun, 2015] Zhang, X.; Zhao, J.; and LeCun, Y
A survey on efficient federated learning methods for foun- dation model training.arXiv preprint arXiv:2403.02154. [Zhang, Zhao, and LeCun, 2015] Zhang, X.; Zhao, J.; and LeCun, Y
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.