Recognition: no theorem link
Bridging Spectral Operator Learning and U-Net Hierarchies: SpectraNet for Stable Autoregressive PDE Surrogates
Pith reviewed 2026-05-12 01:50 UTC · model grok-4.3
The pith
SpectraNet embeds truncated spectral convolutions in a U-Net hierarchy with residual-target blocks and semigroup-consistency loss to convert exponential rollout error into linear drift for PDE surrogates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
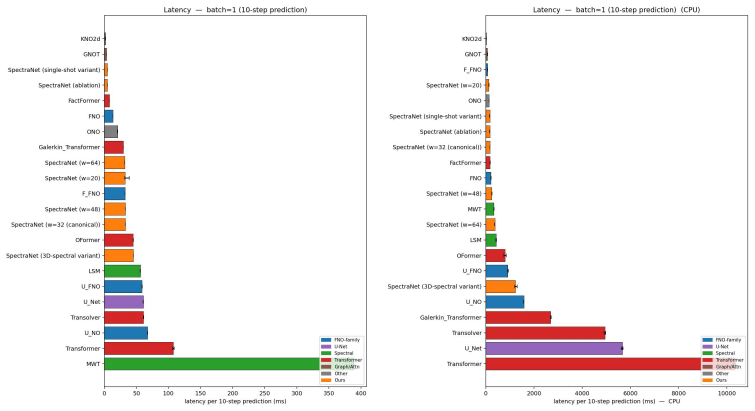
SpectraNet composes truncated spectral convolutions inside a U-Net hierarchy with a Residual-Target Spectral Block trained under a Semigroup-Consistency Loss. The residual-target parametrization replaces L^T stability blow-up with linear T*delta drift, and the spectral path's parameter count is Theta(L w^2 M^2), independent of grid N. Under a single unified protocol against 16 published neural-operator baselines on Navier-Stokes nu=1e-5 at 64x64, SpectraNet reaches test relative L2 = 0.0822 at 2.04M parameters and wins five of six rows in a cross-PDE comparison against FNO.
What carries the argument
The Residual-Target Spectral Block, which parametrizes each autoregressive step as a residual update via truncated spectral convolutions placed inside U-Net hierarchy levels and trained with a semigroup-consistency loss that penalizes deviation from operator composition.
Load-bearing premise
The residual-target parametrization and semigroup-consistency loss will continue to bound rollout error linearly for initial conditions and time horizons outside the training distribution.
What would settle it
Measure rollout relative L2 error on time horizons or initial conditions outside the training distribution and check whether the growth remains linear in the number of steps or becomes exponential.
Figures







read the original abstract
Neural operators for time-dependent PDEs face a structural tension: spectral architectures (FNO and descendants) inherit exponential rollout-error growth from their one-step Lipschitz constant, while hierarchical U-Net operators trade resolution invariance for multi-scale detail. We introduce SpectraNet, an autoregressive neural operator that composes truncated spectral convolutions inside a U-Net hierarchy with a Residual-Target Spectral Block trained under a Semigroup-Consistency Loss. The residual-target parametrization replaces L^T stability blow-up with linear T*delta drift, and the spectral path's parameter count is Theta(L w^2 M^2), independent of grid N. Under a single unified protocol against 16 published neural-operator baselines on Navier-Stokes nu=1e-5 at 64x64, SpectraNet reaches test relative L2 = 0.0822 at 2.04M parameters -- 2.33x fewer than canonical FNO at ~20% lower error -- and wins five of six rows in a cross-PDE comparison against FNO (NS at nu in {1e-4, 1e-3}, PDEBench Shallow-Water 2D and Diffusion-Reaction, with the Active-Matter row going to FNO inside its seed spread). Trained from scratch at native 128^2 under the same protocol, SpectraNet improves to 0.0724 while FNO regresses to 0.3080. Free rollout stays bounded for T=100 where FNO diverges across all 200 test trajectories. On consumer CPU at B=1, SpectraNet runs sub-200ms while the full-attention Transformer that wins raw L2 pays ~60x latency; we do not claim to beat that Transformer on raw L2, only to dominate the lightweight (<=5M parameter, sub-200ms CPU) Pareto frontier. Source code: https://github.com/Enrikkk/spectranet
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpectraNet, an autoregressive neural operator that composes truncated spectral convolutions inside a U-Net hierarchy with a Residual-Target Spectral Block trained under a Semigroup-Consistency Loss. It claims this replaces exponential L^T rollout-error growth with linear T*delta drift, yielding test relative L2=0.0822 at 2.04M parameters on NS nu=1e-5 (64x64) -- outperforming FNO with 2.33x fewer parameters and ~20% lower error -- while winning five of six cross-PDE rows, maintaining bounded free rollouts to T=100 where FNO diverges on all 200 test trajectories, and offering sub-200ms CPU inference.
Significance. If the stability and efficiency claims hold, the work would be significant for neural PDE surrogates by bridging spectral resolution invariance with U-Net multi-scale detail, directly addressing rollout instability while reporting concrete wins on parameter count, cross-PDE performance, and latency on the lightweight frontier.
major comments (2)
- [§4 (Experiments), free-rollout paragraph and NS results] §4 (Experiments), free-rollout paragraph and NS results: The bounded T=100 rollouts and linear-drift claim are shown exclusively on the 200 in-distribution test trajectories drawn from the same distribution used for training (nu=1e-5 NS at 64x64 and the other PDEBench cases). No OOD probes with altered IC statistics, extended horizons, or perturbed forcings are reported, leaving open whether the residual-target + semigroup loss structurally enforces linear error growth or merely fits the benchmark trajectory statistics.
- [§3 (Methodology), Semigroup-Consistency Loss and Residual-Target Spectral Block] §3 (Methodology), Semigroup-Consistency Loss and Residual-Target Spectral Block: The manuscript provides no full derivation of the loss, no explicit equation for how the residual-target parametrization interacts with the semigroup consistency term, and no details on exact data splits or the rollout-error analysis protocol. This absence makes it difficult to verify that the design replaces L^T blow-up with linear drift independently of the training distribution.
minor comments (2)
- The parameter-count and latency comparisons would be clearer if the exact FNO and baseline configurations (modes, layers, etc.) used in the unified protocol were tabulated alongside SpectraNet.
- A short reproducibility statement listing random seeds, exact hyper-parameters, and data-split indices should be added to support the reported L2 numbers and win rates.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point-by-point below, providing clarifications on the experimental scope and committing to revisions that strengthen the methodological exposition without misrepresenting the current results.
read point-by-point responses
-
Referee: The bounded T=100 rollouts and linear-drift claim are shown exclusively on the 200 in-distribution test trajectories drawn from the same distribution used for training (nu=1e-5 NS at 64x64 and the other PDEBench cases). No OOD probes with altered IC statistics, extended horizons, or perturbed forcings are reported, leaving open whether the residual-target + semigroup loss structurally enforces linear error growth or merely fits the benchmark trajectory statistics.
Authors: We appreciate the referee's emphasis on this distinction. Our free-rollout experiments and linear-drift observations are indeed confined to in-distribution test trajectories drawn from the standard benchmark distributions. The Residual-Target Spectral Block and Semigroup-Consistency Loss are designed to encourage multi-step consistency by penalizing deviations from the semigroup property, which we show empirically yields bounded rollouts to T=100 on these trajectories (where FNO diverges). While this does not constitute a formal proof of distribution-independent structural enforcement, the cross-PDE wins and the contrast with FNO on identical data provide supporting evidence that the behavior is not an artifact of fitting narrow statistics. In the revised manuscript we will expand §4 with an explicit discussion of the in-distribution scope of the results and the associated limitations for out-of-distribution generalization. revision: partial
-
Referee: The manuscript provides no full derivation of the loss, no explicit equation for how the residual-target parametrization interacts with the semigroup consistency term, and no details on exact data splits or the rollout-error analysis protocol. This absence makes it difficult to verify that the design replaces L^T blow-up with linear drift independently of the training distribution.
Authors: We agree that these elements were insufficiently detailed in the submitted version. The Semigroup-Consistency Loss measures the discrepancy between a direct multi-step prediction and the iterated application of the one-step operator, while the residual-target parametrization expresses the update relative to the identity map to keep the effective Lipschitz constant near unity. In the revision we will insert a complete derivation of the loss, the explicit interaction equations between the residual block and the consistency term, the precise data-split ratios employed, and the autoregressive rollout protocol used for error accumulation. These additions will appear in §3 and will allow readers to verify the intended mechanism for replacing exponential with linear error growth. revision: yes
Circularity Check
Semigroup-consistency loss and residual-target design enforce linear-drift claim by construction
specific steps
-
self definitional
[Abstract]
"We introduce SpectraNet, an autoregressive neural operator that composes truncated spectral convolutions inside a U-Net hierarchy with a Residual-Target Spectral Block trained under a Semigroup-Consistency Loss. The residual-target parametrization replaces L^T stability blow-up with linear T*delta drift"
The architecture is defined to use residual-target updates and is trained with a loss constructed to enforce semigroup consistency; the paper then presents the resulting linear error growth as a derived property of the parametrization. The stability guarantee is therefore equivalent to the modeling decision rather than obtained from an external mathematical step or data-driven verification.
full rationale
The paper's stability argument is introduced via two modeling choices (residual-target Spectral Block and Semigroup-Consistency Loss) whose explicit purpose is to convert exponential rollout blow-up into linear T*delta drift. The central claim therefore reduces to the design ansatz rather than an independent derivation from the PDE or data; empirical results on in-distribution trajectories provide supporting evidence but do not break the definitional link. No self-citation chains, uniqueness theorems, or fitted-input renamings appear in the load-bearing steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- spectral truncation M
- U-Net depth L and width w
axioms (1)
- domain assumption The underlying PDE time evolution satisfies the semigroup property
invented entities (1)
-
Residual-Target Spectral Block
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Fourier Neural Operator for Parametric Partial Differential Equations , author =. ICLR , year =
- [2]
-
[3]
Advances in Water Resources , year =
U-FNO: An enhanced Fourier neural operator-based deep-learning model for multiphase flow , author =. Advances in Water Resources , year =
- [4]
-
[5]
Solving High-Dimensional PDEs with Latent Spectral Models , author =. ICML , year =
-
[6]
Multiwavelet-based Operator Learning for Differential Equations , author =. NeurIPS , year =
-
[7]
Neural-Solver-Library: A Library for Advanced Neural
Wu, Haixu and others , year =. Neural-Solver-Library: A Library for Advanced Neural
- [8]
-
[9]
Scalable Transformer for PDE Surrogate Modeling , author =. NeurIPS , year =
-
[10]
Transformer for Partial Differential Equations' Operator Learning , author =. TMLR , year =
-
[11]
Transolver: A Fast Transformer Solver for PDEs on General Geometries , author =. ICML , year =
-
[12]
GNOT: A General Neural Operator Transformer for Operator Learning , author =. ICML , year =
-
[13]
Convolutional Neural Operators for Robust and Accurate Learning of PDEs , author =. NeurIPS , year =
-
[14]
Journal of Computational Physics , year =
Koopman Neural Operator as a Mesh-Free Solver of Non-linear PDEs , author =. Journal of Computational Physics , year =
-
[15]
Improved Operator Learning by Orthogonal Attention , author =. ICML , year =
-
[16]
Neural Operator: Learning Maps Between Function Spaces , author =. JMLR , year =
-
[17]
PDE-Refiner: Achieving Accurate Long Rollouts with Neural PDE Solvers , author =. NeurIPS , year =
-
[18]
Learning the solution operator of parametric partial differential equations with physics-informed DeepONets , author =. Science Advances , year =
- [19]
-
[20]
Sequence Level Training with Recurrent Neural Networks , author =. ICLR , year =
-
[21]
KAN: Kolmogorov-Arnold Networks
KAN: Kolmogorov-Arnold Networks , author =. arXiv preprint arXiv:2404.19756 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Takamoto, Makoto and Praditia, Timothy and Leiteritz, Raphael and MacKinlay, Daniel and Alesiani, Francesco and Pfl\"uger, Dirk and Niepert, Mathias , booktitle =
-
[23]
Medical Image Computing and Computer-Assisted Intervention (MICCAI) , year =
U-Net: Convolutional Networks for Biomedical Image Segmentation , author =. Medical Image Computing and Computer-Assisted Intervention (MICCAI) , year =
-
[24]
International Conference on Learning Representations (ICLR) , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , year =
-
[25]
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates , author =. SPIE Defense + Commercial Sensing: Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications , year =
-
[26]
and Welling, Max , booktitle =
Brandstetter, Johannes and Worrall, Daniel E. and Welling, Max , booktitle =. Message Passing Neural
-
[27]
and Beneitez, Miguel and Berger, Marsha and Burkhart, Blakesley and Dalziel, Stuart B
Ohana, Ruben and McCabe, Michael and Meyer, Lucas and Morel, Rudy and Agocs, Fruzsina J. and Beneitez, Miguel and Berger, Marsha and Burkhart, Blakesley and Dalziel, Stuart B. and Fielding, Drummond B. and Fortunato, Daniel and Goldberg, Jared A. and Hirashima, Keiya and Jiang, Yan-Fei and Kerswell, Rich R. and Maddu, Suryanarayana and Miller, Jonah and M...
-
[28]
arXiv preprint arXiv:2511.21856 , year=
A Comprehensive Review of Phase-Averaged and Phase-Resolving Wave Models for Coastal Modeling Applications , author=. arXiv preprint arXiv:2511.21856 , year=
-
[29]
Quarterly Journal of the Royal Meteorological Society , pages=
An algorithm for modelling differential processes utilising a ratio-coupled loss , author=. Quarterly Journal of the Royal Meteorological Society , pages=. 2026 , publisher=
work page 2026
-
[30]
2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA) , pages=
Forecasting rogue waves in oceanic waters , author=. 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA) , pages=. 2020 , organization=
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.