Recognition: no theorem link
Cosine-Gated Adam-Decay: Drop-In Staleness-Aware Outer Optimization for Decoupled DiLoCo
Pith reviewed 2026-05-12 02:26 UTC · model grok-4.3
The pith
Cosine-gated scaling of stale pseudo-gradients yields a DiLoCo outer optimizer whose convergence bound depends only on decay rate α
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that modulating incoming pseudo-gradients with the age-dependent factor σ(τ) = γ(τ) e^{-α τ} before they update Adam moments produces a staleness-aware outer optimizer for DiLoCo that converges with a bound independent of τ_max.
What carries the argument
The scaling factor σ(τ) = γ(τ) e^{-α τ} applied to each pseudo-gradient, where γ(τ) is the cosine gate that smoothly zeros contributions beyond a cutoff age.
Load-bearing premise
The idealized gated-adaptive update studied in the convergence proof accurately models the dynamics of the complete CGAD algorithm when embedded in the actual DiLoCo outer loop.
What would settle it
Observe whether a 7B model trained under CGAD at delay τ=16 maintains loss below chance level; failure to do so would indicate the bound does not translate to the full practical setting.
Figures



read the original abstract
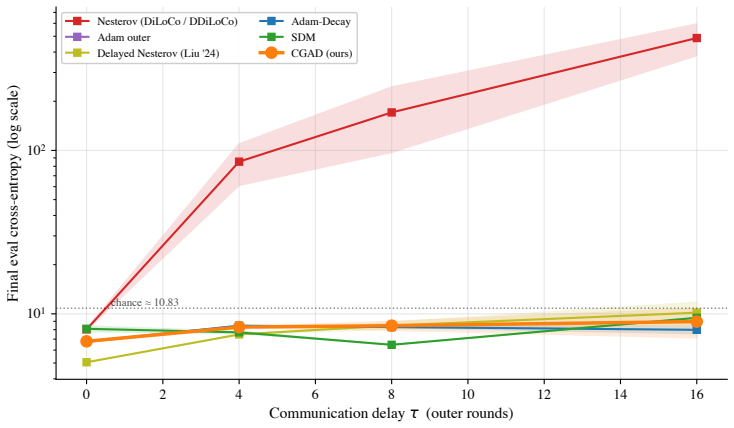
Asynchronous DiLoCo systems may receive pseudo-gradients computed several outer rounds earlier, yet the standard Nesterov outer optimizer does not explicitly condition its update on per-update age. This can make the outer momentum buffer brittle under large controlled delays. We propose Cosine Gated Adam Decay (CGAD), a simple, drop-in, age-aware outer optimizer that scales each incoming pseudo-gradient by $\sigma(\tau) = \gamma(\tau) e^{-\alpha\tau}$ before it enters Adam's first- and second-moment buffers; the exponential models information decay and the cosine gate $\gamma(\tau)$ smoothly zeroes contributions past a chosen cutoff. CGAD reduces to plain Adam at $\tau=0$, adds two hyperparameters whose defaults transfer across scales, and extends to partial-sync schedulers via a per-fragment age-aware variant (PA-CGAD). For an idealized gated-adaptive update on smooth non convex objectives, we prove a non-asymptotic convergence bound whose staleness-bias term depends on $\alpha$ alone, rather than on the realized maximum delay $\tau_{\max}$; standard analyses of asynchronous momentum-SGD instead carry a $\tau_{\max}^2$ factor. Empirically, on Llama style language model pretraining at 25M, 1B, and 7B parameters, CGAD trains stably across the controlled delays we sweep. The cosine cutoff acts as scale insurance: the closest baseline, Adam Decay (CGAD without the cutoff), is competitive at 25M but its seed-to-seed $\sigma$ at $\tau=8$ grows 27x from 25M to 7B, pushing its single-shot risk (mean + $\sigma$) above the chance-level loss while CGAD's stays well below. The published Nesterov recipe is the least stable method on the full sweep.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Cosine-Gated Adam-Decay (CGAD), a drop-in outer optimizer for asynchronous DiLoCo that scales each incoming pseudo-gradient by σ(τ) = γ(τ) e^{-ατ} before it enters Adam's moment buffers, with the cosine gate γ(τ) providing a smooth cutoff. It proves a non-asymptotic convergence bound for an idealized gated-adaptive update on smooth non-convex objectives in which the staleness-bias term depends on α alone rather than on realized maximum delay τ_max. Empirically, CGAD is shown to train stably on Llama-style language model pretraining at 25M, 1B, and 7B scales across controlled delays, with the cosine cutoff acting as scale insurance relative to Adam Decay and the published Nesterov baseline.
Significance. If the idealized bound transfers to the implemented CGAD and the empirical stability claims are statistically supported, the method offers a practical, low-overhead way to stabilize outer optimization in decoupled DiLoCo without explicit dependence on τ_max. The non-asymptotic analysis for the idealized gated update and the reported hyperparameter transfer across three orders of magnitude in model size are concrete strengths that could inform asynchronous training practice.
major comments (2)
- [Abstract and theoretical analysis] Abstract and theoretical section: the non-asymptotic convergence bound is derived explicitly for an idealized gated-adaptive update that applies σ(τ) directly to the gradient before any moment accumulation. The actual CGAD inserts the scaling before Adam's m and v buffers and runs inside DiLoCo's decoupled outer loop with persistent state across outer steps; no analysis is given for the interaction of the exponential decay and cosine gate with the bias-corrected second-moment estimate or the parameter-server decoupling. This gap is load-bearing for the claim that the staleness-bias term depends on α alone in the deployed algorithm.
- [Empirical evaluation] Empirical evaluation: the abstract asserts stable training and transferability of the two hyperparameters across 25M–7B scales, yet provides no quantitative metrics, error bars, or statistical details for the experiments. The specific claim that Adam Decay's seed-to-seed σ at τ=8 grows 27× from 25M to 7B (pushing single-shot risk above chance-level loss) is presented without supporting tables or variance calculations, undermining assessment of the cosine cutoff's scale-insurance benefit.
minor comments (2)
- Explicitly define the cosine cutoff function γ(τ) and the composite σ(τ) with all parameters in the main text rather than relying on the abstract.
- Clarify whether the partial-sync scheduler variant (PA-CGAD) inherits the same idealized convergence guarantee or requires a separate argument.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis] Abstract and theoretical section: the non-asymptotic convergence bound is derived explicitly for an idealized gated-adaptive update that applies σ(τ) directly to the gradient before any moment accumulation. The actual CGAD inserts the scaling before Adam's m and v buffers and runs inside DiLoCo's decoupled outer loop with persistent state across outer steps; no analysis is given for the interaction of the exponential decay and cosine gate with the bias-corrected second-moment estimate or the parameter-server decoupling. This gap is load-bearing for the claim that the staleness-bias term depends on α alone in the deployed algorithm.
Authors: We agree that the convergence bound is stated for an idealized gated-adaptive update and does not analyze the full interactions present in the implemented CGAD (pre-Adam scaling, bias correction, and DiLoCo decoupling). The manuscript already qualifies the result as applying to the idealized case, but we will revise the theoretical section to more explicitly discuss this limitation and explain why the α-only dependence is expected to carry over approximately, as supported by the empirical results across scales. A full non-asymptotic analysis of the complete deployed algorithm lies beyond the scope of the current work. revision: partial
-
Referee: [Empirical evaluation] Empirical evaluation: the abstract asserts stable training and transferability of the two hyperparameters across 25M–7B scales, yet provides no quantitative metrics, error bars, or statistical details for the experiments. The specific claim that Adam Decay's seed-to-seed σ at τ=8 grows 27× from 25M to 7B (pushing single-shot risk above chance-level loss) is presented without supporting tables or variance calculations, undermining assessment of the cosine cutoff's scale-insurance benefit.
Authors: We accept that the abstract and main text would benefit from more explicit quantitative support. While the full manuscript contains experimental figures, we will add a dedicated table in the revised version that reports mean and standard deviation of final loss across seeds for each model scale and delay value. This table will directly document the reported 27× growth in seed-to-seed standard deviation for Adam Decay and the corresponding stability under CGAD, allowing readers to assess the scale-insurance claim with concrete statistics. revision: yes
- A complete non-asymptotic convergence analysis for the full CGAD implementation, including interactions with Adam bias correction and DiLoCo decoupling.
Circularity Check
No significant circularity; convergence bound is a standard first-principles derivation under explicit idealization
full rationale
The paper's central theoretical claim is a non-asymptotic convergence bound derived for an idealized gated-adaptive update on smooth non-convex objectives, with the staleness-bias term depending only on the hyperparameter α. This follows directly from standard analysis assumptions on the idealized update rule σ(τ) applied before moment buffers, without reducing to any fitted parameters, self-definitional equations, or load-bearing self-citations. The empirical results on Llama-style pretraining at multiple scales are presented separately and do not rely on the proof for their validity. No steps in the derivation chain match the enumerated circularity patterns; the idealized model is explicitly distinguished from the full CGAD + DiLoCo implementation.
Axiom & Free-Parameter Ledger
free parameters (2)
- α (exponential decay rate)
- cosine cutoff age
axioms (1)
- domain assumption The loss is smooth and non-convex
invented entities (1)
-
σ(τ) = γ(τ) e^{-ατ}
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Decoupled DiLoCo for Resilient Distributed Pre-training
The Decoupled DiLoCo Team. Decoupled DiLoCo for Resilient Distributed Pre-training. arXiv:2604.21428, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Diloco: Distributed low- communication training of language models.arXiv preprint arXiv:2311.08105,
A. Douillard, Q. Feng, A. A. Rusu, R. Chhaparia, Y . Donchev, A. Kuncoro, M. Ranzato, A. Szlam, J. Shen. DiLoCo: Distributed Low-Communication Training of Language Models.ICML Workshop, 2024. arXiv:2311.08105
-
[3]
A. Douillard et al. Streaming DiLoCo with Overlapping Communication.arXiv:2501.18512, 2025
- [4]
-
[5]
S. Jaghouar, J. M. Ong, J. Hagemann. OpenDiLoCo.arXiv:2407.07852, 2024
-
[6]
A. Bhardwaj et al. Smoothing DiLoCo with Primal Averaging.arXiv:2512.17131, 2025
- [7]
- [8]
-
[9]
T. Ajanthan, S. Ramasinghe, G. Avraham, Y . Zuo, A. Long. Momentum Look-Ahead for Asynchronous Distributed Low-Communication Training.ICLR-W MCDC, 2025
work page 2025
- [10]
- [11]
-
[12]
K. Mishchenko, F. Bach, M. Even, B. Woodworth. Asynchronous SGD beats minibatch SGD under arbitrary delays.arXiv:2206.07638, 2022
-
[13]
S. U. Stich. Local SGD converges fast and communicates little.ICLR, 2019
work page 2019
- [14]
-
[15]
A. Koloskova, S. U. Stich, M. Jaggi. Sharper convergence guarantees for asynchronous SGD. arXiv:2206.08307, 2022
- [16]
- [17]
-
[18]
C. Raffel et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. JMLR, 2020
work page 2020
-
[19]
Y . Wang et al. FADAS: Federated Adaptive Asynchronous Optimization.arXiv:2407.18365, 2024
-
[20]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, Y . Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding.Neurocomputing, 568:127063, 2024. arXiv:2104.09864. 11 A Full proof of Theorem 1 ByL-smoothness, F(θt+1)≤F(θ t) +⟨∇F(θ t),θ t+1 −θ t⟩+ L 2 ∥θt+1 −θ t∥2. The CGAD step is θt+1 −θ t =−ησ t ˆmt/(√ ˆvt +ε) . By the Adam-ratio assumption, ∥ˆmt/(√ ˆvt ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.