Recognition: 2 theorem links
· Lean TheoremObjective-Specific Privileged Bases via Full-Prefix Matryoshka Learning
Pith reviewed 2026-05-12 04:20 UTC · model grok-4.3
The pith
Matryoshka Representation Learning imposes a task-aligned ordering on embedding dimensions that recovers principal directions in linear settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
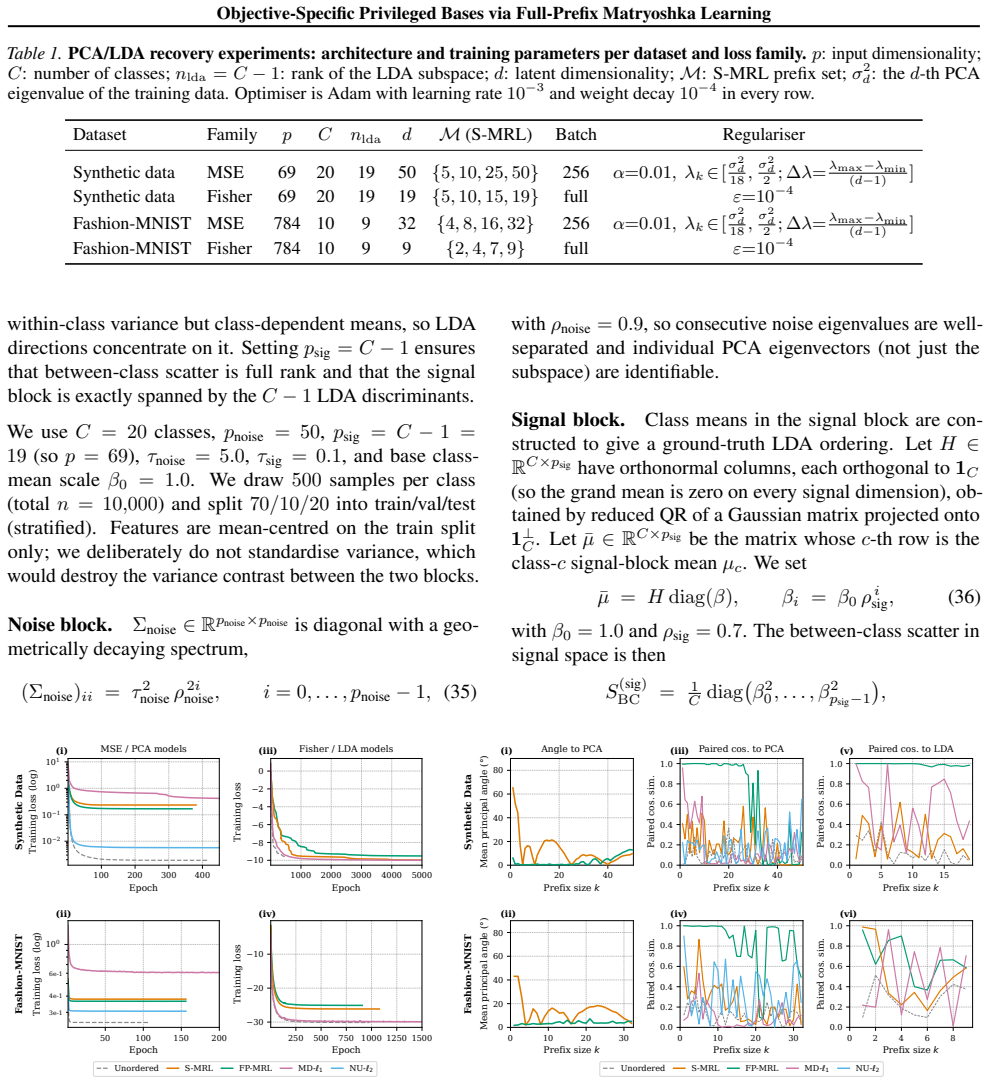
Full-prefix MRL recovers the ordered principal directions in the linear setting and can be computed efficiently using shared statistics. Empirically, MRL yields consistent per-dimension structure aligned with task signal, where coordinate magnitude reflects informativeness.
What carries the argument
Full-prefix Matryoshka Representation Learning, which trains all nested prefixes of a representation to independently satisfy the task objective and thereby enforces an ordering by cumulative contribution.
Load-bearing premise
The analysis assumes a linear setting in which the objective is invariant under rotations of the representation space.
What would settle it
In a linear regression or PCA setting, if the dimensions produced by full-prefix MRL do not match the principal directions ordered by their contribution to the objective, the recovery claim is false.
Figures



read the original abstract
Learned representations are often invariant to rotational transformations, leaving individual dimensions non-identifiable and interchangeable. We study how Matryoshka Representation Learning (MRL) induces a task-aligned privileged basis distinct from variance-based or regularizer-induced orderings. In the linear setting, we prove that full-prefix MRL recovers the ordered principal directions, and can be computed efficiently using shared statistics. Empirically, we demonstrate that MRL yields consistent per-dimension structure aligned with task signal, where coordinate magnitude reflects informativeness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes full-prefix Matryoshka Representation Learning (MRL) to induce objective-specific privileged bases in rotationally invariant learned representations. In the linear setting, it proves that full-prefix MRL recovers the ordered principal directions and can be computed efficiently using shared statistics. Empirically, it demonstrates that MRL produces consistent per-dimension structures aligned with task signals, where coordinate magnitudes reflect informativeness.
Significance. If the results hold, the work offers a mechanism for obtaining task-aligned identifiable dimensions beyond standard variance-based orderings, with potential benefits for interpretability and efficiency in downstream applications. The explicit linear proof and shared-statistics computation are clear strengths supporting efficiency and reproducibility. The empirical alignment with task signal is a useful observation, though its scope requires further substantiation.
major comments (2)
- [Linear Setting] Linear setting analysis: the proof establishes recovery of ordered principal directions (variance-based by construction). This appears to limit the claim of inducing orderings distinct from variance-based ones unless the objective coincides with reconstruction; the manuscript should clarify in the relevant theorem or derivation how arbitrary task objectives are handled without reducing to PCA.
- [Empirical Evaluation] Empirical section: the demonstration of task-signal alignment and magnitude reflecting informativeness is stated without specifying whether non-linear models or objectives that break rotational invariance differently were evaluated. This is load-bearing for the objective-specific privileged basis claim, as the linear case reduces to principal directions.
minor comments (2)
- [Abstract] Abstract: 'full-prefix MRL' is used without a one-sentence reminder of its relation to standard MRL; a brief parenthetical would aid readers.
- [Introduction] Notation: ensure 'privileged basis' is defined once early and used consistently, avoiding interchangeable terms like 'ordered directions' without cross-reference.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment below and have revised the manuscript to clarify the scope of our linear analysis and to provide additional details on the empirical evaluations.
read point-by-point responses
-
Referee: [Linear Setting] Linear setting analysis: the proof establishes recovery of ordered principal directions (variance-based by construction). This appears to limit the claim of inducing orderings distinct from variance-based ones unless the objective coincides with reconstruction; the manuscript should clarify in the relevant theorem or derivation how arbitrary task objectives are handled without reducing to PCA.
Authors: We appreciate this observation. Our linear analysis indeed proves that full-prefix MRL recovers the ordered principal directions, which are variance-based by construction when the model is linear. We have revised the theorem statement, its proof sketch, and the surrounding discussion to explicitly note this equivalence in the linear case and to clarify that the objective-specific privileged basis claim applies more broadly: the MRL nesting mechanism induces task-aligned orderings that coincide with PCA under linear reconstruction but extend to arbitrary objectives in non-linear regimes without reducing to standard PCA. This addresses the scope without overstating the linear result. revision: yes
-
Referee: [Empirical Evaluation] Empirical section: the demonstration of task-signal alignment and magnitude reflecting informativeness is stated without specifying whether non-linear models or objectives that break rotational invariance differently were evaluated. This is load-bearing for the objective-specific privileged basis claim, as the linear case reduces to principal directions.
Authors: We thank the referee for this important point. Our experiments evaluate both linear and non-linear models (including deep networks) across tasks with objectives that are not purely reconstructive and that break rotational invariance in task-specific ways. We have expanded the empirical section to explicitly describe the model architectures, training objectives, and additional controls/ablation studies demonstrating that the observed per-dimension task alignment and magnitude-informativeness relationship hold in non-linear settings beyond variance-based orderings. These revisions strengthen the substantiation of the general claim. revision: yes
Circularity Check
No significant circularity in linear proof or empirical claims
full rationale
The abstract presents a proof that full-prefix MRL recovers ordered principal directions in the linear setting, derived from the MRL objective via linear algebra and shared statistics. This is framed as an independent derivation rather than a redefinition or fit. No equations, self-citations, or ansatzes are quoted that reduce the result to its inputs by construction. The distinction from variance-based orderings is asserted but the recovery of principal directions is stated as a theorem outcome, not a renaming or tautology. Empirical claims of task-signal alignment are presented separately without reducing to the linear proof. The derivation chain appears self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Representations are invariant to rotational transformations, leaving individual dimensions non-identifiable.
- domain assumption The MRL objective induces an ordering distinct from variance-based orderings.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
In the linear setting, we prove that full-prefix MRL recovers the ordered principal directions... LFP-MRL(θ) = Σ_m ω_m ||x - Σ_{k=1}^m y_k||² with wk = d-k+1
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The ordered weighting... forces a nested chain of principal subspaces... Eckart–Young–Mirsky theorem
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Neural networks and principal component analysis: Learning from examples without local minima , author=. Neural networks , volume=. 1989 , publisher=
work page 1989
-
[2]
Advances in Neural Information Processing Systems , volume=
Regularized linear autoencoders recover the principal components, eventually , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
International Conference on Machine Learning , pages=
Eliminating the invariance on the loss landscape of linear autoencoders , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[4]
International Conference on Machine Learning , pages=
Learning ordered representations with nested dropout , author=. International Conference on Machine Learning , pages=. 2014 , organization=
work page 2014
-
[5]
Slimmable neural networks.arXiv preprint arXiv:1812.08928, 2018
Slimmable neural networks , author=. arXiv preprint arXiv:1812.08928 , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Fjord: Fair and accurate federated learning under heterogeneous targets with ordered dropout , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Advances in Neural Information Processing Systems , volume=
Matryoshka representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
The approximation of one matrix by another of lower rank , author=. Psychometrika , volume=. 1936 , publisher=
work page 1936
-
[9]
The quarterly journal of mathematics , volume=
Symmetric gauge functions and unitarily invariant norms , author=. The quarterly journal of mathematics , volume=. 1960 , publisher=
work page 1960
-
[10]
International conference on machine learning , pages=
Loss landscapes of regularized linear autoencoders , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[11]
arXiv preprint arXiv:2601.19179 , year=
Learning Ordered Representations in Latent Space for Intrinsic Dimension Estimation via Principal Component Autoencoder , author=. arXiv preprint arXiv:2601.19179 , year=
-
[12]
Proceedings of the International Conference on Learning Representation , year=
Matryoshka Multimodal Models , author=. Proceedings of the International Conference on Learning Representation , year=
-
[13]
The Fourteenth International Conference on Learning Representations , year=
MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction , author=. The Fourteenth International Conference on Learning Representations , year=
-
[14]
Advances in Neural Information Processing Systems , volume=
Matryoshka query transformer for large vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Matryoshka Model Learning for Improved Elastic Student Models , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[16]
Transformer Circuits Thread , volume=
Privileged bases in the transformer residual stream , author=. Transformer Circuits Thread , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.