Recognition: no theorem link
LBI: Parallel Scan Backpropagation via Latent Bounded Interfaces
Pith reviewed 2026-05-12 02:39 UTC · model grok-4.3
The pith
Latent Bounded Interfaces reduce backpropagation to low-cost scans over small matrices for parallel training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
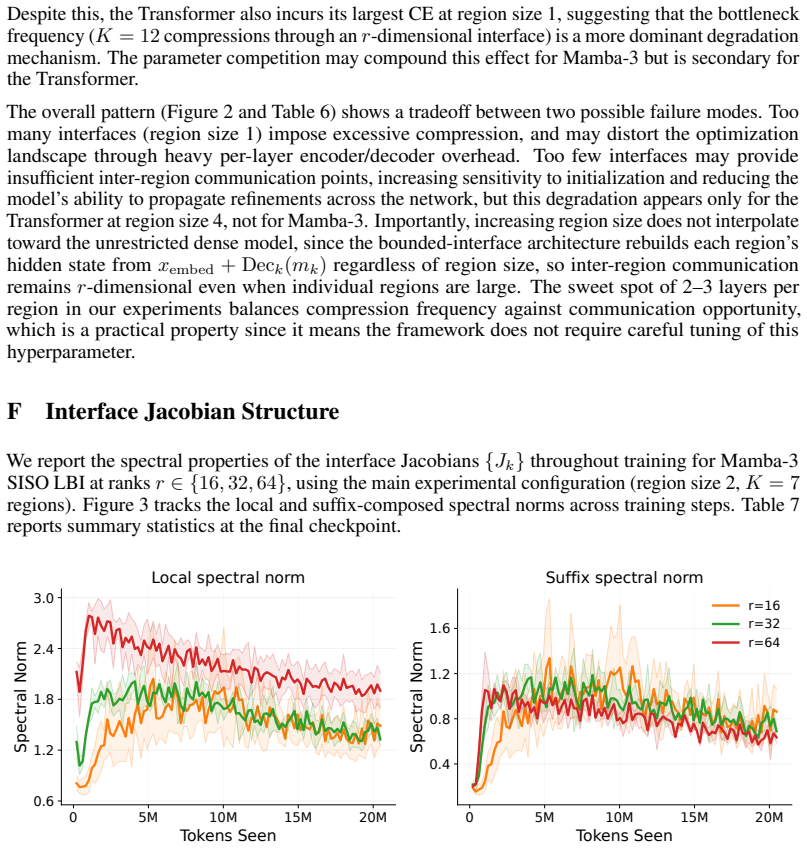
Latent Bounded Interfaces restrict inter-region communication to a low-dimensional latent state m_k in R^r. This reformulates the backward pass as a suffix scan over r-by-r Jacobians, lowering combine cost from O(d^3) to O(r^3) while preserving exact gradients inside the bounded-interface model. The paper reports that r=16 suffices to keep cross-entropy within 0.16-0.35 of dense baselines across Mamba-2, Mamba-3, Transformer, and hybrid blocks of 47-61 million parameters, and that the resulting backward communication collapses to a single scan over fixed-size matrices of about 56 KB.
What carries the argument
Latent Bounded Interface: a fixed-size vector m_k in R^r that carries every dependency needed for the adjoint recursion between adjacent regions.
If this is right
- Region-parallel training becomes possible because the backward pass needs only one scan over small fixed-size matrices.
- Cross-device gradient communication drops to roughly 56 KB per configuration.
- The forward pass remains unchanged, so existing Mamba and Transformer code can adopt the method directly.
- Exact gradients are recovered as long as the latent interface bounds all necessary dependencies.
Where Pith is reading between the lines
- The same bounded-interface idea could be applied to other sequential operations such as recurrent inference or long-context attention.
- If the required interface dimension stays constant as model size grows, LBI would become relatively cheaper at larger scales.
- Pairing LBI with existing data or tensor parallelism could compound the speedup beyond what the paper measures.
- Architectures that already contain natural low-dimensional bottlenecks would benefit most from this approach.
Load-bearing premise
That a low-dimensional latent interface of size r=16 can carry every critical gradient dependency between regions without any change to the forward pass or loss of accuracy.
What would settle it
A side-by-side training run in which an LBI model with r=16 ends more than 0.35 cross-entropy worse than an otherwise identical model trained with ordinary dense backpropagation.
Figures


read the original abstract
Backpropagation is inherently sequential across depth, creating an $O(K)$-deep dependency chain that bottlenecks parallel training. While parallel-scan formulations theoretically reduce this depth to $O(\log K)$, they are computationally prohibitive for modern architectures due to the $O(d^3)$ cost of composing full-rank $d\times d$ Jacobians over the entire hidden state. We introduce Latent Bounded Interfaces (LBI), an algorithmic formulation that makes scan-based backpropagation tractable by restricting inter-region communication to a low-dimensional latent interface, $ m_k \in \mathbb{R}^{r}$, where $r \ll d$. This reduces the adjoint recursion to a suffix scan over $r \times r$ Jacobians, cutting per-combine cost from $O(d^3)$ to $O(r^3)$ while preserving exact gradients under the bounded-interface model. We demonstrate that LBI maintains model quality across four architectures (Mamba-2, Mamba-3, Transformer, and a Mamba--Transformer hybrid) at 47--61M block parameters. Interfaces of dimension $r=16$ suffice to preserve training quality within 0.16--0.35 cross entropy of dense baselines. The resulting framework provides an algorithmic foundation for region-parallel training, reducing cross-device backward communication to a single scan over $K$ fixed-size matrices, of approximately 56 KB for our experimental configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Latent Bounded Interfaces (LBI), an algorithmic technique that restricts inter-region communication in scan-based models to a low-dimensional latent interface m_k ∈ R^r (r ≪ d) to enable tractable parallel-scan backpropagation. This reduces the adjoint recursion to a suffix scan over r×r Jacobians, lowering per-combine cost from O(d^3) to O(r^3) while claiming to preserve exact gradients under the bounded-interface model. Experiments on Mamba-2, Mamba-3, Transformer, and hybrid blocks (47-61M parameters) show that r=16 suffices to keep cross-entropy within 0.16-0.35 of dense baselines, providing a foundation for region-parallel training with reduced cross-device communication.
Significance. If the bounded-interface construction can be shown to enforce the restriction without altering forward-pass semantics or introducing unaccounted approximations, the work would provide a practical route to parallelizing backpropagation in state-space and attention models, directly addressing the O(K) sequential depth and O(d^3) Jacobian costs that currently limit large-scale distributed training. The reported empirical gaps are modest and the communication reduction (to ~56 KB per scan) is concrete; however, the absence of a detailed derivation or verification of exactness limits the immediate impact.
major comments (3)
- [Abstract and §3] Abstract and §3 (method): The central claim that LBI 'preserves exact gradients under the bounded-interface model' is load-bearing, yet no derivation is supplied showing how the original state-transition or attention Jacobians are rewritten to route all cross-region dependencies exclusively through m_k ∈ R^r; without this explicit factorization, the O(r^3) suffix scan cannot be guaranteed to compute the correct adjoints for the unmodified architecture.
- [§4 and Table 1] §4 (experiments) and Table 1: The reported 0.16–0.35 CE gaps to dense baselines are presented as evidence of quality preservation, but no ablation or error analysis confirms that these gaps arise solely from training dynamics rather than from an implicit approximation introduced by the interface restriction; this directly affects whether the 'exact' qualifier holds for the demonstrated models.
- [§3.2] §3.2 (architecture adaptations): The manuscript states that LBI is applied to Mamba-2/3, Transformer, and hybrid blocks, but provides no concrete construction (e.g., how the selective SSM or attention matrices are projected onto the latent interface while leaving forward semantics unchanged); this construction is required to validate that the Jacobian reduction does not discard critical gradient information.
minor comments (2)
- [Abstract] Notation: The symbol m_k is introduced in the abstract but its precise definition (e.g., whether it is a learned projection or a fixed bottleneck) should be stated at first use with an equation reference.
- [Figures] Figure clarity: The communication-volume diagram (presumably Fig. 2) would benefit from explicit annotation of the r×r matrix sizes and the single-scan reduction to 56 KB.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript can be strengthened. We address each major comment below with clarifications and commit to revisions that provide the requested derivations and constructions while preserving the core claims of the work.
read point-by-point responses
-
Referee: [Abstract and §3] The central claim that LBI 'preserves exact gradients under the bounded-interface model' is load-bearing, yet no derivation is supplied showing how the original state-transition or attention Jacobians are rewritten to route all cross-region dependencies exclusively through m_k ∈ R^r.
Authors: We agree that an explicit derivation is required. In the revised manuscript, we will add to §3 a step-by-step factorization showing that, under the bounded-interface model, all cross-region adjoint dependencies are routed exclusively through the low-dimensional m_k. This allows the suffix scan to operate on r×r Jacobians while computing exact adjoints for the LBI model (not the unmodified dense architecture). revision: yes
-
Referee: [§4 and Table 1] The reported 0.16–0.35 CE gaps to dense baselines are presented as evidence of quality preservation, but no ablation or error analysis confirms that these gaps arise solely from training dynamics rather than from an implicit approximation introduced by the interface restriction.
Authors: The gaps reflect the forward-pass approximation inherent to the bounded-interface model; the backpropagation remains exact for that model. We will revise §4 to clarify this distinction and add an ablation with r set to the full hidden dimension, which recovers the dense baseline exactly (within floating-point precision) and confirms the gradient computation is correct for the defined LBI architecture. revision: yes
-
Referee: [§3.2] The manuscript states that LBI is applied to Mamba-2/3, Transformer, and hybrid blocks, but provides no concrete construction (e.g., how the selective SSM or attention matrices are projected onto the latent interface while leaving forward semantics unchanged).
Authors: We will expand §3.2 with explicit constructions: for selective SSMs we detail the projection of state transitions onto m_k while keeping intra-region dynamics unchanged; for attention we specify the interface projection of key/value outputs. These ensure the Jacobian reduction applies without discarding intra-region gradient information. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claim introduces LBI explicitly as a restriction of inter-region communication to a low-dimensional latent interface m_k ∈ R^r (r ≪ d), which by definition reduces the adjoint recursion to a suffix scan over r×r Jacobians and yields O(r^3) per-combine cost. Exact gradient preservation is stated only under this bounded-interface model, not as a derivation from unmodified architectures. No steps reduce by construction to fitted parameters, self-referential definitions, or load-bearing self-citations; the algorithmic formulation is self-contained, with empirical results (0.16–0.35 CE gap) presented separately as validation rather than part of the derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- r (latent interface dimension) =
16
axioms (1)
- standard math Jacobian composition and matrix multiplication obey standard rules of linear algebra.
invented entities (1)
-
Latent Bounded Interface
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Pearlmutter, Alexey Andreyevich Radul, and Jeffrey Mark Siskind
Atılım Günes Baydin, Barak A. Pearlmutter, Alexey Andreyevich Radul, and Jeffrey Mark Siskind. Automatic differentiation in machine learning: a survey.J. Mach. Learn. Res., 18(1):5595–5637, January 2017
work page 2017
- [3]
-
[4]
Programming parallel algorithms.Communications of the ACM, 39(3):85–97, 1996
Guy E Blelloch. Programming parallel algorithms.Communications of the ACM, 39(3):85–97, 1996
work page 1996
-
[5]
Menger’s theorem.Journal of Graph Theory, 37(1):35–36, 2001
Thomas Böhme, Frank Göring, and Jochen Harant. Menger’s theorem.Journal of Graph Theory, 37(1):35–36, 2001
work page 2001
-
[6]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost.arXiv preprint arXiv:1604.06174, 2016
work page internal anchor Pith review arXiv 2016
-
[7]
DeepPCR: Parallelizing Sequential Operations in Neural Networks
Federico Danieli, Miguel Sarabia, Xavier Suau Cuadros, Pau Rodriguez, and Luca Zappella. DeepPCR: Parallelizing Sequential Operations in Neural Networks. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 47598–47625. Curran Associates, Inc., 2023
work page 2023
-
[8]
Monarch: Expressive structured matrices for efficient and accurate training
Tri Dao, Beidi Chen, Nimit S Sohoni, Arjun Desai, Michael Poli, Jessica Grogan, Alexander Liu, Aniruddh Rao, Atri Rudra, and Christopher Ré. Monarch: Expressive structured matrices for efficient and accurate training. InInternational Conference on Machine Learning, pages 4690–4721. PMLR, 2022
work page 2022
-
[9]
Tri Dao and Albert Gu. Transformers are SSMs: generalized models and efficient algorithms through structured state space duality. InProceedings of the 41st International Conference on Machine Learning, pages 10041–10071, 2024
work page 2024
-
[10]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Accelerated training through iterative gradient propagation along the residual path
Erwan Fagnou, Paul Caillon, Blaise Delattre, and Alexandre Allauzen. Accelerated training through iterative gradient propagation along the residual path. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[12]
JFB: Jacobian-Free Backpropagation for Implicit Networks
Samy Wu Fung, Howard Heaton, Qiuwei Li, Daniel McKenzie, Stanley Osher, and Wotao Yin. JFB: Jacobian-Free Backpropagation for Implicit Networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 6648–6656, 2022
work page 2022
-
[13]
Gomez, Oscar Key, Kuba Perlin, Stephen Gou, Nick Frosst, Jeff Dean, and Yarin Gal
Aidan N. Gomez, Oscar Key, Kuba Perlin, Stephen Gou, Nick Frosst, Jeff Dean, and Yarin Gal. Interlocking backpropagation: Improving depthwise model-parallelism.Journal of Machine Learning Research, 23(171):1–28, 2022
work page 2022
-
[14]
Xavier Gonzalez, Andrew Warrington, Jimmy T.H. Smith, and Scott W. Linderman. Towards Scalable and Stable Parallelization of Nonlinear RNNs. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 5817–5849. Curran Associates, Inc., 2024
work page 2024
-
[15]
Stefanie Günther, Lars Ruthotto, Jacob B. Schroder, Eric C. Cyr, and Nicolas R. Gauger. Layer-Parallel Training of Deep Residual Neural Networks.SIAM Journal on Mathematics of Data Science, 2(1):1–23, 2020
work page 2020
-
[16]
Gpipe: Efficient training of giant neural networks using pipeline parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, and Zhifeng Chen. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Proc...
work page 2019
-
[17]
Zih-Hao Huang, You-Teng Lin, and Hung-Hsuan Chen. Deinforeg: A decoupled learning framework with information regularization for better training throughput.Neurocomputing, 651:130813, 2025
work page 2025
-
[18]
Decoupled neural interfaces using synthetic gradients
Max Jaderberg, Wojciech Marian Czarnecki, Simon Osindero, Oriol Vinyals, Alex Graves, David Silver, and Koray Kavukcuoglu. Decoupled neural interfaces using synthetic gradients. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1627–16...
work page 2017
-
[19]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pages 4651–
-
[20]
Li, Berlin Chen, Caitlin Wang, Aviv Bick, J
Aakash Lahoti, Kevin Y Li, Berlin Chen, Caitlin Wang, Aviv Bick, J Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved Sequence Modeling using State Space Principles.arXiv preprint arXiv:2603.15569, 2026
-
[21]
Chimera: efficiently training large-scale neural networks with bidirectional pipelines
Shigang Li and Torsten Hoefler. Chimera: efficiently training large-scale neural networks with bidirectional pipelines. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’21, New York, NY , USA, 2021. Association for Computing Machinery
work page 2021
-
[22]
Yi Heng Lim, Qi Zhu, Joshua Selfridge, and Muhammad Firmansyah Kasim. Parallelizing non-linear sequential models over the sequence length.arXiv preprint arXiv:2309.12252, 2023
-
[23]
NVIDIA H100 Tensor Core GPU Architecture, 2022
NVIDIA. NVIDIA H100 Tensor Core GPU Architecture, 2022. White Paper
work page 2022
-
[24]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. PyTorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[25]
Unlocked Backpropagation using Wave Scattering.arXiv preprint arXiv:2602.10461, 2026
Christian Pehle and Jean-Jacques Slotine. Unlocked Backpropagation using Wave Scattering.arXiv preprint arXiv:2602.10461, 2026
-
[26]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Advances in Neural Information Processing Systems...
work page 2024
-
[27]
The information bottleneck method
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method.arXiv preprint physics/0004057, 2000
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[28]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and Efficient Foundation Language Models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[30]
Bppsa: Scaling back-propagation by parallel scan algorithm
Shang Wang, Yifan Bai, and Gennady Pekhimenko. Bppsa: Scaling back-propagation by parallel scan algorithm. In I. Dhillon, D. Papailiopoulos, and V . Sze, editors,Proceedings of Machine Learning and Systems, volume 2, pages 451–469, 2020
work page 2020
-
[31]
Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009. A Vertex Separators Definition A.1(Interface Separator).A set of nodes Sk ⊂ V is aninterface separatorat boundary k if every directed path fromR <k toR ≥k contains at least one no...
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.