Recognition: no theorem link
SMIXAE: Towards Unsupervised Manifold Discovery in Language Models
Pith reviewed 2026-05-12 02:45 UTC · model grok-4.3
The pith
SMIXAE uses a mixture of sparse autoencoders to learn multidimensional manifold structures directly in language model activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
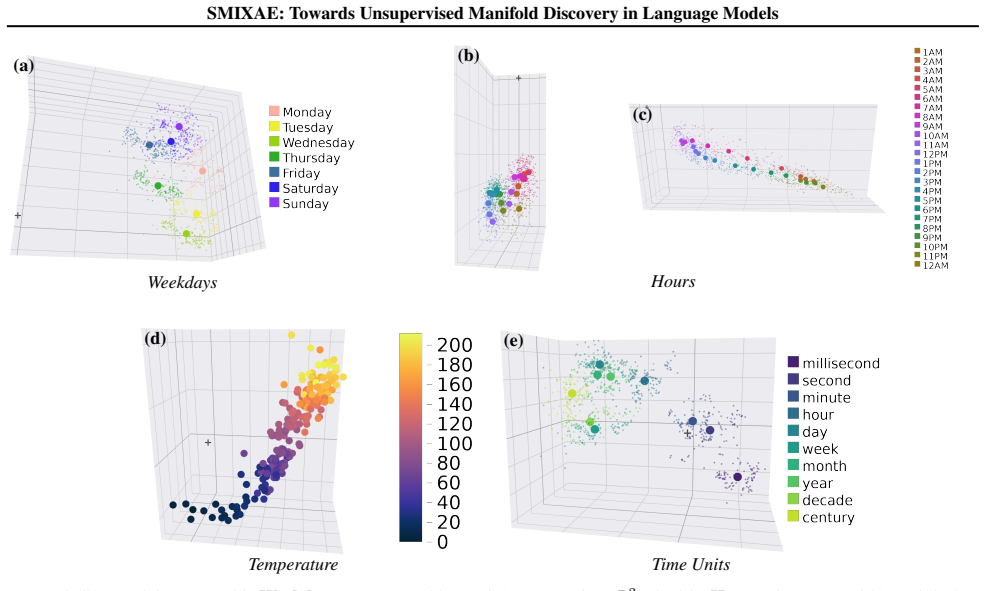
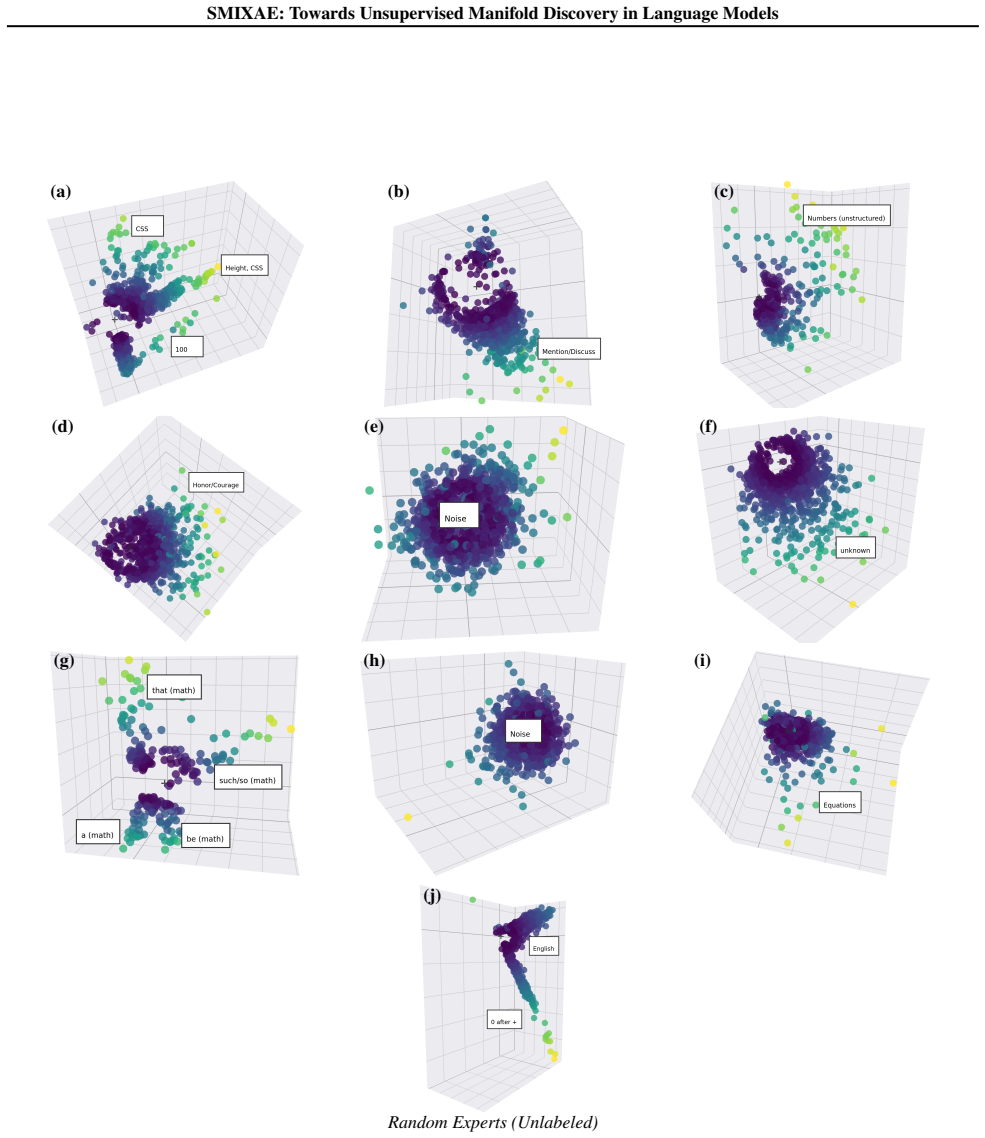
The Sparse MIXture of Autoencoders (SMIXAE) architecture succeeds at directly learning previously identified manifold structures as well as discovering novel structures within the activations of the open-source Gemma 2 2B and 9B models.
What carries the argument
The SMIXAE mixture architecture, which trains multiple sparse autoencoders together so that each component can represent an entire multidimensional manifold rather than isolated directions.
If this is right
- Multidimensional features can be discovered and interpreted as single units during training rather than after.
- Unsupervised discovery becomes possible for manifold structures that were previously hard to isolate.
- The approach demonstrates success on both 2B and 9B scale open models from the Gemma 2 family.
- Limitations discussed in the paper point to the need for further scaling and validation work.
Where Pith is reading between the lines
- The same mixture approach could be tested on other transformer families to check whether manifold recovery holds beyond Gemma.
- If SMIXAE reduces the need for post-training feature grouping, it could speed up automated interpretability pipelines that currently rely on clustering steps.
- Novel structures found by SMIXAE might correspond to functional behaviors that standard SAEs miss, offering a route to test specific hypotheses about model computation.
Load-bearing premise
The mixture architecture can reliably capture multidimensional manifold structures in language model activations without needing post-hoc grouping, based on results from two specific Gemma models.
What would settle it
Running the same SMIXAE training on a different language model family or on a set of known multidimensional features and finding that the learned representations still split across multiple components requiring manual grouping afterward.
Figures








read the original abstract
Sparse autoencoders (SAEs) have been used widely to decompose and interpret neural network activations, especially those of transformer language models. One key issue with SAEs is their inability to directly model multidimensional features. Instead, SAEs may tile such features by a set of independent directions that must be grouped together after the SAE training phase, impeding discoverability and interpretation of learned feature representations. We begin to address this issue by introducing the Sparse MIXture of Autoencoders (SMIXAE) architecture. Empirically, we provide evidence that SMIXAE models have success both in directly learning previously identified manifold structures, as well as finding novel structures, within the open source Gemma 2 2B and 9B models. Finally, we discuss several limitations and point towards areas for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sparse MIXture of Autoencoders (SMIXAE), a mixture-of-autoencoders architecture intended to overcome the tendency of standard sparse autoencoders (SAEs) to tile multidimensional manifold features in language-model activations into independent directions that must be grouped post hoc. The central claim is that SMIXAE directly learns both previously identified and novel manifold structures in the activations of open-source Gemma 2 2B and 9B models, with supporting empirical evidence presented and limitations discussed.
Significance. If the empirical results can be shown to rest on well-defined quantitative metrics, ablations, and validation procedures rather than subjective interpretation, the work would address a recognized limitation in mechanistic interpretability and could reduce dependence on post-training feature grouping. The use of publicly available Gemma 2 models is a positive step toward reproducibility.
major comments (3)
- [Experiments] Experiments section: the abstract and main text assert empirical success in directly learning multidimensional manifolds without post-hoc grouping, yet no quantitative metrics (e.g., per-component effective dimensionality, reconstruction error on held-out known manifolds, or clustering purity scores versus SAE baselines) or ablation studies isolating the mixture component are reported. This absence prevents assessment of whether the claimed advantage is architectural or due to hyperparameter choices.
- [Method] Method section: the description of how mixture components are assigned to manifold dimensions (as opposed to independent directions) is not accompanied by a formal argument or diagnostic showing that the assignment is enforced by the architecture rather than emerging from training dynamics or initialization; without this, the central distinction from tiled SAE features remains unproven.
- [Experiments] Validation of 'previously identified' and 'novel' structures: the paper does not specify the procedure used to confirm that recovered structures correspond to true manifolds (e.g., comparison against known feature dictionaries, geometric tests for dimensionality, or human-interpretability controls), leaving open the possibility that success is driven by subjective selection.
minor comments (2)
- [Method] Notation for the mixture weights and sparsity penalties should be unified across equations and text to avoid ambiguity in the definition of the SMIXAE objective.
- [Limitations] The limitations section could usefully include a brief discussion of computational overhead relative to standard SAEs, as mixture models typically increase training cost.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments identify important opportunities to strengthen the quantitative rigor, theoretical grounding, and validation procedures in the manuscript. We address each major comment below and will incorporate revisions to address them.
read point-by-point responses
-
Referee: Experiments section: the abstract and main text assert empirical success in directly learning multidimensional manifolds without post-hoc grouping, yet no quantitative metrics (e.g., per-component effective dimensionality, reconstruction error on held-out known manifolds, or clustering purity scores versus SAE baselines) or ablation studies isolating the mixture component are reported. This absence prevents assessment of whether the claimed advantage is architectural or due to hyperparameter choices.
Authors: We agree that additional quantitative metrics and ablations would strengthen the claims. The current version relies primarily on visualizations and qualitative recovery of known structures. In the revised manuscript we will add per-component effective dimensionality, reconstruction error on held-out data, clustering purity comparisons against SAE baselines, and ablation studies that isolate the mixture component. These additions will clarify whether the observed advantages arise from the architecture. revision: yes
-
Referee: Method section: the description of how mixture components are assigned to manifold dimensions (as opposed to independent directions) is not accompanied by a formal argument or diagnostic showing that the assignment is enforced by the architecture rather than emerging from training dynamics or initialization; without this, the central distinction from tiled SAE features remains unproven.
Authors: We acknowledge that the manuscript would benefit from an explicit formal argument. The mixture-of-autoencoders design is intended to encourage each component to capture a coherent subspace rather than isolated directions, but this was not accompanied by a proof or diagnostic. In the revision we will add a formal argument in the Method section together with empirical diagnostics (component-wise activation statistics and per-component dimensionality measurements) to demonstrate that the manifold assignment is promoted by the architecture. revision: yes
-
Referee: Validation of 'previously identified' and 'novel' structures: the paper does not specify the procedure used to confirm that recovered structures correspond to true manifolds (e.g., comparison against known feature dictionaries, geometric tests for dimensionality, or human-interpretability controls), leaving open the possibility that success is driven by subjective selection.
Authors: We agree that the validation procedure should be stated explicitly. The current text describes recovery of known and novel structures but does not detail the exact checks performed. In the revised Experiments section we will specify the full procedure, including direct comparison to published feature dictionaries, geometric dimensionality tests, and human-interpretability controls, to make the identification of manifolds more objective and reproducible. revision: yes
Circularity Check
No circularity: empirical architecture proposal on external models
full rationale
The paper introduces the SMIXAE architecture as a direct response to a known SAE limitation (tiling of multidimensional features) and reports empirical results on activations from independent open-source models (Gemma 2 2B/9B). No derivation chain, equations, or fitted parameters are presented that reduce to self-defined terms or prior self-citations. The central claim rests on application to external data rather than any self-referential construction or renaming of inputs. This is a standard empirical contribution with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Elhage, Nelson and Hume, Tristan and Olsson, Catherine and Schiefer, Nicholas and Henighan, Tom and Kravec, Shauna and Hatfield-Dodds, Zac and Lasenby, Robert and Drain, Dawn and Chen, Carol and Grosse, Roger and McCandlish, Sam and Kaplan, Jared and Amodei, Dario and Wattenberg, Martin and Olah, Christopher. Toy models of superposition. arXiv:2209.10652
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
The origins of representation manifolds in large language models.arXiv preprint arXiv:2505.18235,
Modell, Alexander and Rubin-Delanchy, Patrick and Whiteley, Nick. The origins of representation manifolds in large language models. arXiv:2505.18235
-
[3]
When models manipulate manifolds: The geometry of a counting task, 2026
Gurnee, Wes and Ameisen, Emmanuel and Kauvar, Isaac and Tarng, Julius and Pearce, Adam and Olah, Chris and Batson, Joshua. When models manipulate manifolds: The geometry of a counting task. arXiv:2601.04480
-
[4]
Chasing the Counting Manifold in Open LLMs , author=
-
[5]
The Thirteenth International Conference on Learning Representations , year=
Not All Language Model Features Are One-Dimensionally Linear , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
Progress measures for grokking via mechanistic interpretability , author=. ArXiv , year=
-
[7]
Shai, Adam S. and Marzen, Sarah E. and Teixeira, Lucas and Oldenziel, Alexander Gietelink and Riechers, Paul M. , booktitle =. Transformers Represent Belief State Geometry in their Residual Stream , url =. doi:10.52202/079017-2387 , editor =
-
[8]
Extensions of Lipschitz maps into a Hilbert space , volume =
Johnson, William and Lindenstrauss, Joram , year =. Extensions of Lipschitz maps into a Hilbert space , volume =. Contemporary Mathematics , doi =
-
[9]
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. 2023 , eprint=
work page 2023
-
[10]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
work page 2023
-
[11]
Shape Happens: Automatic Feature Manifold Discovery in LLMs via Supervised Multi-Dimensional Scaling , author=. 2025 , eprint=
work page 2025
-
[12]
Learning Multi-Level Features with Matryoshka Sparse Autoencoders , author=. 2025 , eprint=
work page 2025
-
[13]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders , author=. 2024 , eprint=
work page 2024
-
[14]
Tom Conerly and Hoagy Cunningham and Adly Templeton and Jack Lindsey and Basil Hosmer and Adam Jermyn , title =. 2025 , note =
work page 2025
-
[15]
Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
Finding Manifolds With Bilinear Autoencoders , author=. Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
work page 2025
-
[16]
PolySAE: Modeling Feature Interactions in Sparse Autoencoders via Polynomial Decoding , author=. 2026 , eprint=
work page 2026
-
[17]
A theory of steady-state activity in nerve-fiber networks: I
Householder, Alston S. A theory of steady-state activity in nerve-fiber networks: I. Definitions and preliminary lemmas. Bulletin of Mathematical Biophysics
- [18]
- [19]
-
[20]
Christopher Tralie and Nathaniel Saul and Rann Bar-On , title =. 2018 , month =. doi:10.21105/joss.00925 , url =
-
[21]
Bauer, Ulrich , TITLE =. J. Appl. Comput. Topol. , FJOURNAL =. 2021 , NUMBER =. doi:10.1007/s41468-021-00071-5 , URL =
-
[22]
Schonsheck and Jie Chen and Rongjie Lai , title =
Stefan C. Schonsheck and Jie Chen and Rongjie Lai , title =. CoRR , volume =. 2019 , url =. 1912.10094 , timestamp =
-
[23]
Minimalistic Unsupervised Learning with the Sparse Manifold Transform , author=. 2023 , eprint=
work page 2023
-
[24]
Not All Language Model Features Are One-Dimensionally Linear , author=. 2025 , eprint=
work page 2025
-
[25]
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders , author=. 2025 , eprint=
work page 2025
-
[26]
Data Whitening Improves Sparse Autoencoder Learning , author=. 2025 , eprint=
work page 2025
-
[27]
Deep Unsupervised Clustering Using Mixture of Autoencoders , author=. 2017 , eprint=
work page 2017
-
[28]
Valence-Arousal Subspace in LLMs: Circular Emotion Geometry and Multi-Behavioral Control , author=. 2026 , eprint=
work page 2026
-
[29]
Latent Structure of Affective Representations in Large Language Models , author=. 2026 , eprint=
work page 2026
-
[30]
Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
Understanding sparse autoencoder scaling in the presence of feature manifolds , author=. Mechanistic Interpretability Workshop at NeurIPS 2025 , year=
work page 2025
-
[31]
Do Sparse Autoencoders Capture Concept Manifolds? , author=. 2026 , eprint=
work page 2026
-
[32]
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. 2024 , eprint=
work page 2024
-
[33]
Understanding Deep Neural Networks with Rectified Linear Units , author=. 2018 , eprint=
work page 2018
-
[34]
Approximation capabilities of multilayer feedforward networks , journal =
Kurt Hornik , keywords =. Approximation capabilities of multilayer feedforward networks , journal =. 1991 , issn =. doi:https://doi.org/10.1016/0893-6080(91)90009-T , url =
-
[35]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling , author=. 2020 , eprint=
work page 2020
- [36]
-
[37]
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
work page 2024
- [38]
- [39]
-
[40]
ICML 2024 Workshop on Mechanistic Interpretability , year=
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author=. ICML 2024 Workshop on Mechanistic Interpretability , year=
work page 2024
-
[41]
The neural basis of the Weber-Fechner law: a logarithmic mental number line
Dehaene, Stanislas. The neural basis of the Weber-Fechner law: a logarithmic mental number line. Trends Cogn. Sci
-
[42]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
work page 2020
-
[43]
SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability , author=. 2025 , eprint=
work page 2025
-
[44]
Are Sparse Autoencoders Useful? A Case Study in Sparse Probing , author=. 2025 , eprint=
work page 2025
-
[45]
Priors in Time: Missing Inductive Biases for Language Model Interpretability , author=. 2025 , eprint=
work page 2025
-
[46]
Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior , author=. 2026 , eprint=
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.