Recognition: no theorem link
Instance-Adaptive Online Multicalibration
Pith reviewed 2026-05-12 04:39 UTC · model grok-4.3
The pith
A single efficient algorithm achieves online multicalibration with error rates that automatically adapt to the complexity of the data sequence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
There exists an efficient algorithm that maintains and adaptively refines a dyadic grid of prediction values so that the multicalibration error is controlled by the number of leaves in the refinement tree; this recovers the worst-case optimal rate of order T^{2/3} while achieving order sqrt(T) under marginal stochasticity and order sqrt(J T) under piecewise-stationary means with J segments, with the general rate governed by the threshold-complexity of the predictable mean process relative to the group family, and this dependence is tight up to logarithmic factors.
What carries the argument
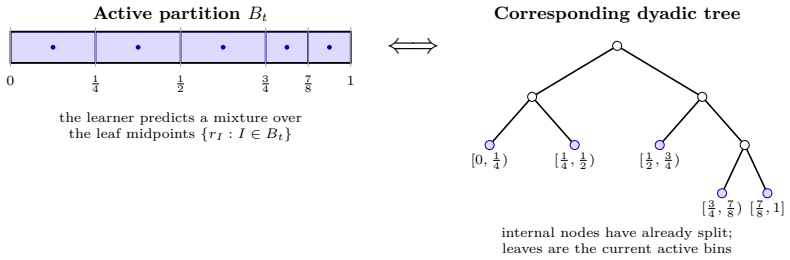
An adaptively refined dyadic grid of prediction values whose refinement tree's leaves determine the error bound by deciding when to split intervals based on observed data.
If this is right
- The algorithm automatically matches the optimal worst-case rate of order T^{2/3} without modification.
- It obtains the faster rate of order sqrt(T) whenever the sequence is drawn from a fixed marginal distribution.
- It obtains the rate of order sqrt(J T) whenever the mean process consists of at most J stationary segments.
- The error bound is controlled directly by the number of leaves in the adaptive refinement tree.
Where Pith is reading between the lines
- Similar adaptive refinement ideas could be applied to other online fairness or calibration notions where worst-case and stochastic regimes coexist.
- The threshold-complexity measure may serve as a useful complexity parameter for designing instance-adaptive algorithms in related online prediction problems.
- In practice this method lets a single deployed system handle both stable and drifting data streams without manual retuning.
Load-bearing premise
The threshold-complexity of the predictable mean process relative to the group family is well-defined and the algorithm receives enough observations to decide when to refine each grid interval.
What would settle it
A concrete data sequence whose mean process has threshold-complexity K but on which the algorithm's multicalibration error exceeds order K times a polylog factor would falsify the rate guarantee.
Figures
read the original abstract
We study online multicalibration beyond the worst-case. We give a single, efficient algorithm which dynamically interpolates between benign and worst-case sequences by adaptively refining a dyadic grid of prediction values. Its error is controlled by the number of leaves in the refinement tree. Our analysis recovers the known $\widetilde O(T^{2/3})$ worst-case-optimal rate for online multicalibration, while simultaneously automatically adapting to easier instances: in the marginal stochastic setting it obtains a rate of $\widetilde O(\sqrt T)$, and for piecewise-stationary means with $J$ segments its rate is $\widetilde O(\sqrt{JT})$. More generally, the rate depends on a threshold-complexity measure of the predictable mean process relative to the group family. We show that this dependence is tight up to logarithmic factors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a single efficient algorithm for online multicalibration that adaptively refines a dyadic grid of prediction values. Its multicalibration error is controlled by the number of leaves in the refinement tree. The algorithm recovers the known worst-case Õ(T^{2/3}) rate while automatically achieving Õ(√T) in the marginal stochastic setting and Õ(√(JT)) for piecewise-stationary means with J segments. More generally the rate depends on a threshold-complexity measure of the predictable mean process relative to the group family, and this dependence is shown to be tight up to logarithmic factors.
Significance. If the analysis holds, the work is significant: it supplies a unified, efficient online procedure that interpolates between adversarial and benign regimes without prior knowledge of instance difficulty. The dyadic-refinement mechanism together with the matching lower bounds (up to logs) provides both an algorithmic contribution and a tight characterization of instance complexity for multicalibration.
major comments (2)
- [Refinement rule and its analysis (likely §4–5)] The central adaptive claim rests on showing that the online splitting rule produces a number of leaves bounded by the threshold-complexity measure even under stochastic noise. The analysis must explicitly bound the probability (or expectation) of spurious splits triggered by variance in the observed outcomes; without such a bound the Õ(√T) rate does not follow.
- [Definition of threshold-complexity and main theorem] The performance guarantee is stated in terms of an externally supplied threshold-complexity measure of the mean process. The manuscript must clarify how this measure can be related to the algorithm’s observable behavior (predictions and realized outcomes) so that the instance-adaptive rate is not circular.
minor comments (2)
- [Abstract / §1] The abstract and introduction should state the precise definition of the group family and the dyadic grid at the first use of these terms.
- [Main theorem statement] Notation for the Õ notation and the precise dependence on the group family should be made explicit in the statement of the main theorem.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment of significance, and constructive major comments. The points raised concern the explicitness of the spurious-split analysis and the interpretation of the threshold-complexity measure. Both can be addressed by targeted clarifications and an additional lemma; we outline the revisions below.
read point-by-point responses
-
Referee: [Refinement rule and its analysis (likely §4–5)] The central adaptive claim rests on showing that the online splitting rule produces a number of leaves bounded by the threshold-complexity measure even under stochastic noise. The analysis must explicitly bound the probability (or expectation) of spurious splits triggered by variance in the observed outcomes; without such a bound the Õ(√T) rate does not follow.
Authors: We agree that an explicit bound on spurious splits strengthens the presentation. The current analysis in Section 5 already invokes Azuma-Hoeffding on the martingale of prediction errors to control deviations; when the conditional mean lies inside a threshold interval, the probability of an erroneous split at any node is at most 2 exp(−Ω(threshold² · samples)). A union bound over the O(log T) depth of the dyadic tree then yields an expected number of spurious leaves of O(log T). We will insert a dedicated Lemma 5.2 that states this expectation bound directly and derives the Õ(√T) stochastic rate as an immediate corollary. A high-probability version will also be added for completeness. revision: yes
-
Referee: [Definition of threshold-complexity and main theorem] The performance guarantee is stated in terms of an externally supplied threshold-complexity measure of the mean process. The manuscript must clarify how this measure can be related to the algorithm’s observable behavior (predictions and realized outcomes) so that the instance-adaptive rate is not circular.
Authors: The threshold-complexity is defined with respect to the (unknown) predictable mean process μ, yet the algorithm and its observable behavior—predictions, realized outcomes y_t, and the resulting leaf count—depend only on the data. Theorem 4.1 supplies an a-posteriori guarantee: for any fixed sequence, the multicalibration error is bounded by a function of the complexity of that sequence’s μ. The bound is therefore not circular; it simply characterizes the instance difficulty to which the algorithm automatically adapts. We will add a short clarifying paragraph after Definition 3.2 explaining this ex-post nature and noting that the leaf count itself serves as an observable proxy for the complexity of μ. No change to the formal definition is required. revision: partial
Circularity Check
No significant circularity detected
full rationale
The derivation bounds multicalibration error by the number of leaves in an adaptively refined dyadic tree and expresses instance-adaptive rates in terms of an externally defined threshold-complexity measure of the predictable mean process relative to the given group family. This measure is not constructed from the algorithm's own predictions or outputs, nor is any rate obtained by fitting parameters to the algorithm's results and relabeling them as predictions. No load-bearing self-citation, uniqueness theorem, or ansatz is invoked to force the central claims; the worst-case recovery and adaptation results follow from the analysis of the refinement rule without reducing to self-definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Predictions lie in [0,1] and group membership indicators are observed at each time step.
- domain assumption The threshold-complexity measure of the mean process is finite and controls the number of leaves needed.
invented entities (1)
-
dyadic refinement tree
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Electronic Communications in Probability , publisher =
Joel Tropp , title =. Electronic Communications in Probability , publisher =
-
[2]
Achieving all with no parameters: Adanormalhedge , author=. Proc. Conference on Learning Theory (COLT) , pages=. 2015 , organization=
work page 2015
-
[3]
Sample Complexity of Uniform Convergence for Multicalibration , author =. Proc. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[4]
Distribution-free calibration guarantees for histogram binning without sample splitting , author=. Proc. International conference on machine learning (ICML) , pages=. 2021 , organization=
work page 2021
-
[5]
Games and Economic Behavior , volume=
Calibrated learning and correlated equilibrium , author=. Games and Economic Behavior , volume=. 1997 , publisher=
work page 1997
-
[6]
Operations Research & Management Science in the Age of Analytics , pages=
Wasserstein distributionally robust optimization: Theory and applications in machine learning , author=. Operations Research & Management Science in the Age of Analytics , pages=. 2019 , publisher=
work page 2019
-
[7]
Calibrating predictions to decisions: A novel approach to multi-class calibration , author=. Proc. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[8]
Lunjia Hu and Yifan Wu , title =. 65th
-
[9]
arXiv preprint arXiv:2501.17205 , year=
Near-optimal algorithms for omniprediction , author=. arXiv preprint arXiv:2501.17205 , year=
-
[10]
American Economic Review , volume=
Robustness and linear contracts , author=. American Economic Review , volume=. 2015 , publisher=
work page 2015
-
[11]
Forecasting for Swap Regret for All Downstream Agents , booktitle =
Aaron Roth and Mirah Shi , editor =. Forecasting for Swap Regret for All Downstream Agents , booktitle =
-
[12]
Bobby Kleinberg and Renato Paes Leme and Jon Schneider and Yifeng Teng , title =. Proc. Annual Conference on Learning Theory (COLT) , series =
-
[13]
14th Innovations in Theoretical Computer Science Conference, ITCS 2023 , pages=
Decision-Making Under Miscalibration , author=. 14th Innovations in Theoretical Computer Science Conference, ITCS 2023 , pages=. 2023 , organization=
work page 2023
-
[14]
Inductive confidence machines for regression , author=. Machine learning: ECML 2002: 13th European conference on machine learning Helsinki, Finland, August 19--23, 2002 proceedings 13 , pages=. 2002 , organization=
work page 2002
-
[15]
The Annals of Mathematical Statistics , volume=
Determination of sample sizes for setting tolerance limits , author=. The Annals of Mathematical Statistics , volume=. 1941 , publisher=
work page 1941
-
[16]
Non-Parametric Estimation. I. Validation of Order Statistics , author =. Annals of Mathematical Statistics , volume =. 1945 , month =. doi:10.1214/aoms/1177731119 , url =
-
[17]
Algorithmic Learning in a Random World , journal =
Vovk, Vladimir and Gammerman, Alex and Shafer, Glenn , year =. Algorithmic Learning in a Random World , journal =
-
[18]
Saunders, C. and Gammerman, A. and Vovk, V. , title =. Proceedings of the 16th International Joint Conference on Artificial Intelligence - Volume 2 , pages =. 1999 , publisher =
work page 1999
-
[19]
Transduction with confidence and credibility , author=
-
[20]
Machine-learning applications of algorithmic randomness , author=
-
[21]
Algorithmic learning in a random world , author=. 2005 , publisher=
work page 2005
- [22]
- [23]
-
[24]
Gupta, Chirag and Kuchibhotla, Arun K. and Ramdas, Aaditya , year=. Nested conformal prediction and quantile out-of-bag ensemble methods , volume=. doi:10.1016/j.patcog.2021.108496 , journal=
-
[25]
Conformal Risk Minimization with Variance Reduction , author=. 2025 , eprint=
work page 2025
-
[26]
Distribution-Free Predictive Inference For Regression , author=. 2017 , eprint=
work page 2017
-
[27]
Journal of mathematical economics , volume=
Maxmin expected utility with non-unique prior , author=. Journal of mathematical economics , volume=. 1989 , publisher=
work page 1989
-
[28]
arXiv preprint arXiv:2502.17830 , year=
Certified Decisions , author=. arXiv preprint arXiv:2502.17830 , year=
-
[29]
Mathematical programming , volume=
Robust optimization--methodology and applications , author=. Mathematical programming , volume=. 2002 , publisher=
work page 2002
-
[30]
arXiv preprint arXiv:2402.13213 , year=
Probabilities of Chat LLMs Are Miscalibrated but Still Predict Correctness on Multiple-Choice Q&A , author=. arXiv preprint arXiv:2402.13213 , year=
-
[31]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Omnipredictors for regression and the approximate rank of convex functions , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
work page 2024
-
[32]
Sample Efficient Omniprediction and Downstream Swap Regret for Non-Linear Losses , booktitle =
Jiuyao Lu and Aaron Roth and Mirah Shi , editor =. Sample Efficient Omniprediction and Downstream Swap Regret for Non-Linear Losses , booktitle =. 2025 , url =
work page 2025
-
[33]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[34]
International Conference on Learning Representations , year=
Top-label calibration and multiclass-to-binary reductions , author=. International Conference on Learning Representations , year=
-
[35]
Advances in neural information processing systems , volume=
Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with dirichlet calibration , author=. Advances in neural information processing systems , volume=
-
[36]
The Thirty Seventh Annual Conference on Learning Theory , pages=
On computationally efficient multi-class calibration , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
work page 2024
-
[37]
Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , pages=
Outcome indistinguishability , author=. Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing , pages=
-
[38]
Multicalibration: Calibration for the (computationally-identifiable) masses , author=. Proc. International Conference on Machine Learning (ICML) , pages=. 2018 , organization=
work page 2018
-
[39]
The Annals of Statistics , volume=
Learning models with uniform performance via distributionally robust optimization , author=. The Annals of Statistics , volume=. 2021 , publisher=
work page 2021
-
[40]
American Economic Review , volume=
Robust control and model uncertainty , author=. American Economic Review , volume=. 2001 , publisher=
work page 2001
-
[41]
Breakthroughs in Statistics: Foundations and Basic Theory , pages=
Statistical decision functions , author=. Breakthroughs in Statistics: Foundations and Basic Theory , pages=. 1950 , publisher=
work page 1950
- [42]
-
[43]
Classification with Valid and Adaptive Coverage , author=. 2020 , eprint=
work page 2020
-
[44]
Uncertainty Sets for Image Classifiers using Conformal Prediction , author=. 2022 , eprint=
work page 2022
- [45]
-
[46]
Safe Planning in Dynamic Environments using Conformal Prediction , author=. 2023 , eprint=
work page 2023
-
[47]
Conformal Decision Theory: Safe Autonomous Decisions from Imperfect Predictions , author=. 2024 , eprint=
work page 2024
-
[48]
Uncertain: Modern topics in uncertainty estimation , author=. Lecture Notes , volume=
-
[49]
Decision Theoretic Foundations for Conformal Prediction: Optimal Uncertainty Quantification for Risk-Averse Agents , author=. 2025 , eprint=
work page 2025
- [50]
-
[51]
Predict Responsibly: Improving Fairness and Accuracy by Learning to Defer , author=. 2018 , eprint=
work page 2018
-
[52]
Consistent Estimators for Learning to Defer to an Expert , author=. 2021 , eprint=
work page 2021
-
[53]
Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , articleno =
Bansal, Gagan and Wu, Tongshuang and Zhou, Joyce and Fok, Raymond and Nushi, Besmira and Kamar, Ece and Ribeiro, Marco Tulio and Weld, Daniel , title =. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , articleno =. 2021 , isbn =. doi:10.1145/3411764.3445717 , abstract =
-
[54]
Towards Human-AI Complementarity with Prediction Sets , url =
De Toni, Giovanni and Okati, Nastaran and Thejaswi, Suhas and Straitouri, Eleni and Gomez-Rodriguez, Manuel , booktitle =. Towards Human-AI Complementarity with Prediction Sets , url =
-
[55]
Proceedings of the 40th International Conference on Machine Learning , pages =
Improving Expert Predictions with Conformal Prediction , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[56]
Controlling Counterfactual Harm in Decision Support Systems Based on Prediction Sets , url =
Straitouri, Eleni and Thejaswi, Suhas and Rodriguez, Manuel Gomez , booktitle =. Controlling Counterfactual Harm in Decision Support Systems Based on Prediction Sets , url =
-
[57]
Adaptive Conformal Inference Under Distribution Shift , author=. 2021 , eprint=
work page 2021
-
[58]
Conformal PID Control for Time Series Prediction , author=. 2023 , eprint=
work page 2023
-
[59]
Journal of Econometrics , volume=
Identification Problems and Decisions under Ambiguity , author=. Journal of Econometrics , volume=
-
[60]
Statistical Treatment Rules for Heterogeneous Populations , author=. Econometrica , volume=
-
[61]
Admissible Treatment Rules for a Risk-Averse Planner , author=. Econometrica , volume=
-
[62]
Annual Review of Economics , volume=
Choosing Treatment Policies under Ambiguity , author=. Annual Review of Economics , volume=
-
[63]
Progress in Artificial Intelligence , volume=
Event labeling combining ensemble detectors and background knowledge , author=. Progress in Artificial Intelligence , volume=. 2014 , publisher=
work page 2014
-
[64]
Statistics & Probability Letters , volume=
Sparse spatial autoregressions , author=. Statistics & Probability Letters , volume=. 1997 , publisher=
work page 1997
-
[65]
The Annals of Probability , volume=
Distribution function inequalities for martingales , author=. The Annals of Probability , volume=. 1973 , publisher=
work page 1973
-
[66]
High-Dimensional Prediction for Sequential Decision Making , author=. Proc. International Conference on Machine Learning (ICML) , year=
-
[67]
Supersimulators , author=. arXiv preprint arXiv:2509.17994 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Dagan, Yuval and Daskalakis, Constantinos and Fishelson, Maxwell and Golowich, Noah and Kleinberg, Robert and Okoroafor, Princewill , booktitle=. Breaking the
-
[69]
Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society , pages=
Multiaccuracy: Black-box post-processing for fairness in classification , author=. Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society , pages=
work page 2019
-
[70]
Advances in Neural Information Processing Systems , volume=
Truthfulness of calibration measures , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
The Thirty Eighth Annual Conference on Learning Theory , pages=
Truthfulness of Decision-Theoretic Calibration Measures , author=. The Thirty Eighth Annual Conference on Learning Theory , pages=. 2025 , organization=
work page 2025
-
[72]
A Perfectly Truthful Calibration Measure
A Perfectly Truthful Calibration Measure , author=. arXiv preprint arXiv:2508.13100 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [73]
-
[74]
Brownian Motion and Stochastic Calculus , author=. 2013 , howpublished=
work page 2013
-
[75]
Conference on Learning Theory , pages=
Low-degree multicalibration , author=. Conference on Learning Theory , pages=. 2022 , organization=
work page 2022
-
[76]
Denisov, Denis and Sakhanenko, Alexander and Wachtel, Vitali , title =. 2016 , eprint =
work page 2016
-
[77]
Electronic Journal of Probability , volume=
The First Hitting Time of a Single Point for Random Walks , author=. Electronic Journal of Probability , volume=. 2011 , publisher=
work page 2011
-
[78]
Stronger calibration lower bounds via sidestepping , author=. Proc. Annual ACM Symposium on Theory of Computing (STOC) , pages=
-
[79]
Innovations in Theoretical Computer Science Conference (ITCS) , volume=
Advancing Subgroup Fairness via Sleeping Experts , author=. Innovations in Theoretical Computer Science Conference (ITCS) , volume=
-
[80]
The Twelfth International Conference on Learning Representations , year=
Oracle Efficient Algorithms for Groupwise Regret , author=. The Twelfth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.