Recognition: no theorem link
Multi-scale Predictive Representations for Goal-conditioned Reinforcement Learning
Pith reviewed 2026-05-12 03:31 UTC · model grok-4.3
The pith
Multi-scale predictive supervision aligns state and goal latents to stop divergence into goal-agnostic subspaces during offline goal-conditioned reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
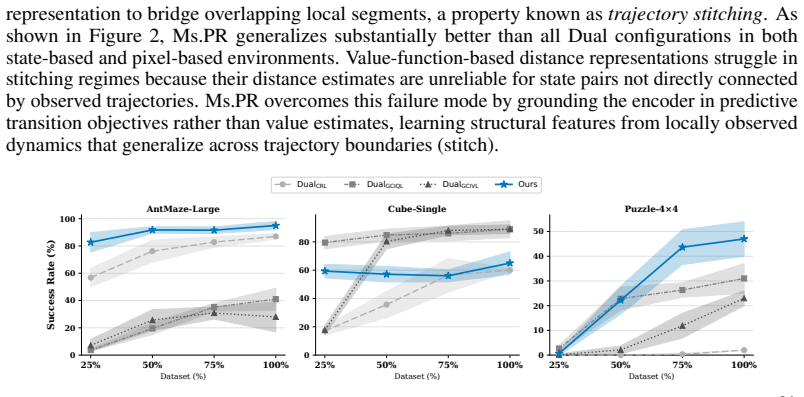
The authors establish that multi-scale predictive supervision enforces goal-directed alignment in the latent space and thereby prevents the encoder from drifting into a low-dimensional goal-agnostic subspace. By supervising predictions that span local dynamics up to long-horizon goal-directed behavior, the framework maintains representations that remain useful for downstream policy optimization even under sparse rewards and challenging offline data conditions.
What carries the argument
Ms.PR, the framework that applies auxiliary predictive losses at multiple temporal and spatial scales to enforce alignment between state and goal latents.
If this is right
- Representation quality improves enough to support stronger policy performance on both vision and state-based tasks.
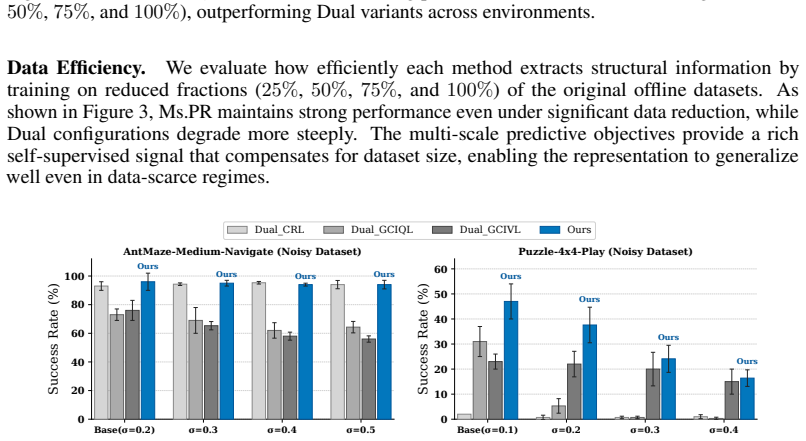
- The method remains effective under trajectory stitching and high-noise offline regimes.
- State-of-the-art results hold across a wide variety of goal-conditioned tasks without additional online interaction.
Where Pith is reading between the lines
- The same multi-scale losses might stabilize learning when goals change over time or when the agent must discover new goals.
- Combining the approach with hierarchical policies could let each level inherit aligned representations at its natural scale.
- Testing on physical robots with sensor noise and partial views would check whether the alignment survives real-world distribution shifts.
Load-bearing premise
That adding predictive supervision across scales will reliably keep the latent space goal-directed rather than letting it collapse under realistic offline data limits and noise.
What would settle it
A controlled run on the same offline datasets where multi-scale supervision is added yet goal-reaching accuracy from the encoded states remains low or policy learning still destabilizes would show the alignment mechanism does not hold.
Figures




read the original abstract
This paper investigates robust representation learning in offline goal-conditioned reinforcement learning (GCRL). Particularly in sparse reward scenarios, learning representations that align state and goal latents is a challenge that frequently culminates in representation divergence where the encoder drifts toward a low-dimensional, goal-agnostic subspace that destabilizes policy learning. We address this issue by showing that an agent must acquire a fundamental understanding of its environment across multiple scales, from local physical dynamics to long-horizon goal-directed structure. Building on this insight, we propose Ms.PR, a framework that leverages multi-scale predictive supervision to enforce goal-directed alignment within the latent space. We demonstrate that Ms.PR leads to improved representation quality and strong performance on both vision and state-based tasks. Furthermore, we show that our approach is exceptionally resilient under realistic, challenging data regimes, maintaining state-of-the-art performance across a wide variety of tasks, trajectory stitching scenarios, and extreme noise conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Ms.PR, a framework for multi-scale predictive representations in offline goal-conditioned reinforcement learning. It identifies representation divergence—where encoders drift into low-dimensional goal-agnostic subspaces—as a core failure mode under sparse rewards, and claims that acquiring predictive understanding across scales (local dynamics to long-horizon goal structure) prevents this drift and enforces latent alignment. The paper reports improved representation quality, strong performance on vision and state-based tasks, and robustness under trajectory stitching and high-noise offline regimes.
Significance. If the empirical gains are supported by controlled ablations and the multi-scale mechanism is shown to be the load-bearing factor, the work could provide a practical, scalable approach to representation learning in offline GCRL. The insight that single-scale supervision is insufficient for goal-directed alignment is potentially useful for the community, though it is demonstrated empirically rather than derived from an identifiability result.
major comments (2)
- [§4.2] §4.2, Eq. (3)–(5): The multi-scale predictive loss is defined as a sum of terms at different horizons, but the paper does not specify how the prediction targets or encoders are shared across scales, nor does it include a proof or argument that this construction prevents subspace collapse rather than simply adding more supervision. This is load-bearing for the central claim of enforced alignment.
- [§5.4] §5.4, Table 4: The noise-robustness experiments report higher success rates for Ms.PR, yet omit both the number of random seeds and a single-scale predictive baseline trained with matched total loss weight; without these controls it is impossible to attribute gains to the multi-scale structure rather than increased regularization or hyperparameter effects.
minor comments (3)
- [Abstract] Abstract: The phrase 'exceptionally resilient' is not supported by quantitative comparison; replace with concrete metrics (e.g., success-rate delta under 50% noise) drawn from the results section.
- [§2] §2: The related-work discussion omits several recent offline GCRL representation papers that also address latent alignment; adding them would clarify the precise novelty of the multi-scale supervision.
- [Figure 2] Figure 2: Axis labels and legend entries are too small for readability; enlarge fonts and add a caption explaining the color coding of different scales.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§4.2] §4.2, Eq. (3)–(5): The multi-scale predictive loss is defined as a sum of terms at different horizons, but the paper does not specify how the prediction targets or encoders are shared across scales, nor does it include a proof or argument that this construction prevents subspace collapse rather than simply adding more supervision. This is load-bearing for the central claim of enforced alignment.
Authors: We agree that the current description in §4.2 lacks sufficient implementation detail. In the revised manuscript we will explicitly state that a single shared encoder processes observations for all scales and that prediction targets at different horizons are generated by the same learned dynamics model applied recursively. Regarding the central claim, we acknowledge that no formal proof is provided; the work is empirical. We will add a concise argument in §4.2 based on the fact that single-scale losses can be satisfied by goal-agnostic features while multi-scale losses require the latent space to preserve both local transition structure and long-horizon goal reachability, thereby reducing the measure of goal-agnostic subspaces. We will also report an additional ablation comparing multi-scale training against a single-scale baseline whose total loss weight is matched to Ms.PR. revision: partial
-
Referee: [§5.4] §5.4, Table 4: The noise-robustness experiments report higher success rates for Ms.PR, yet omit both the number of random seeds and a single-scale predictive baseline trained with matched total loss weight; without these controls it is impossible to attribute gains to the multi-scale structure rather than increased regularization or hyperparameter effects.
Authors: We thank the referee for identifying these omissions. In the revised version we will state that all experiments, including those in Table 4, were run with 5 independent random seeds and report mean and standard deviation. We will also add a single-scale predictive baseline whose total loss coefficient is set equal to the sum of the multi-scale coefficients used by Ms.PR, allowing direct comparison under matched regularization strength. These additions will be included in an updated Table 4 and accompanying text in §5.4. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical framework (Ms.PR) for multi-scale predictive representations in offline goal-conditioned RL, motivated by an insight about needing understanding across scales to prevent representation divergence. The abstract and description frame the contribution as a proposed method whose benefits are shown through experiments on vision/state tasks, trajectory stitching, and noise conditions rather than any formal derivation, identifiability proof, or equation that reduces to its own inputs. No load-bearing steps involving self-definitional quantities, fitted parameters called predictions, or self-citation chains appear in the provided text; the central claim rests on empirical outcomes under realistic data regimes and is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay,
- [2]
-
[3]
Td-jepa: Latent-predictive representations for zero-shot reinforcement learning, 2025
Marco Bagatella, Matteo Pirotta, Ahmed Touati, Alessandro Lazaric, and Andrea Tirinzoni. Td-jepa: Latent-predictive representations for zero-shot reinforcement learning, 2025. URL https://arxiv.org/abs/2510.00739
-
[4]
Pablo Samuel Castro, Tyler Kastner, Prakash Panangaden, and Mark Rowland. Mico: Improved representations via sampling-based state similarity for markov decision processes, 2022. URL https://arxiv.org/abs/2106.08229
-
[5]
Ayoub Echchahed and Pablo Samuel Castro. A survey of state representation learning for deep reinforcement learning, 2025. URLhttps://arxiv.org/abs/2506.17518
-
[6]
C-learning: Learning to achieve goals via recursive classification, 2021
Benjamin Eysenbach, Ruslan Salakhutdinov, and Sergey Levine. C-learning: Learning to achieve goals via recursive classification, 2021. URL https://arxiv.org/abs/2011. 08909
work page 2021
-
[7]
Contrastive learning as goal-conditioned reinforcement learning, 2023
Benjamin Eysenbach, Tianjun Zhang, Ruslan Salakhutdinov, and Sergey Levine. Contrastive learning as goal-conditioned reinforcement learning, 2023. URLhttps://arxiv.org/abs/ 2206.07568
-
[8]
A minimalist approach to offline reinforcement learning
Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning. InThirty-Fifth Conference on Neural Information Processing Systems, 2021
work page 2021
-
[9]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018
work page 2018
-
[10]
Smith, Shixiang Shane Gu, Doina Precup, and David Meger
Scott Fujimoto, Wei-Di Chang, Edward J. Smith, Shixiang Shane Gu, Doina Precup, and David Meger. For sale: State-action representation learning for deep reinforcement learning, 2023. URLhttps://arxiv.org/abs/2306.02451
-
[11]
Towards general-purpose model-free reinforcement learning.arXiv preprint arXiv:2501.16142, 2025
Scott Fujimoto, Pierluca D’Oro, Amy Zhang, Yuandong Tian, and Michael Rabbat. Towards general-purpose model-free reinforcement learning, 2025. URL https://arxiv.org/abs/ 2501.16142
- [12]
-
[13]
Learning to reach goals via iterated supervised learning, 2020
Dibya Ghosh, Abhishek Gupta, Ashwin Reddy, Justin Fu, Coline Devin, Benjamin Eysenbach, and Sergey Levine. Learning to reach goals via iterated supervised learning, 2020. URL https://arxiv.org/abs/1912.06088
-
[14]
David Ha and Jürgen Schmidhuber. World models. 2018. doi: 10.5281/ZENODO.1207631. URLhttps://zenodo.org/record/1207631
-
[15]
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels, 2019. URL https: //arxiv.org/abs/1811.04551. 10
-
[16]
Dream to con- trol: Learning behaviors by latent imagination, 2020
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to con- trol: Learning behaviors by latent imagination, 2020. URL https://arxiv.org/abs/1912. 01603
work page 2020
-
[17]
Danijar Hafner, Kuang-Huei Lee, Ian Fischer, and Pieter Abbeel. Deep hierarchical planning from pixels.Advances in Neural Information Processing Systems, 35:26091–26104, 2022
work page 2022
-
[18]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
TD-MPC2: Scalable, Robust World Models for Continuous Control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control.arXiv preprint arXiv:2310.16828, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
Leslie Pack Kaelbling. Learning to achieve goals. InInternational Joint Conference on Artificial Intelligence, 1993. URLhttps://api.semanticscholar.org/CorpusID:5538688
work page 1993
-
[21]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning, 2021. URLhttps://arxiv.org/abs/2110.06169
work page internal anchor Pith review arXiv 2021
-
[22]
Self-Predictive Representations for Combinatorial Generalization in Behavioral Cloning
Daniel Lawson, Adriana Hugessen, Charlotte Cloutier, Glen Berseth, and Khimya Khetarpal. Self-predictive representations for combinatorial generalization in behavioral cloning, 2025. URLhttps://arxiv.org/abs/2506.10137
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Michael L. Littman, Richard S. Sutton, and Satinder Singh. Predictive representations of state. InProceedings of the 15th International Conference on Neural Information Processing Systems: Natural and Synthetic, NIPS’01, page 1555–1561, Cambridge, MA, USA, 2001. MIT Press
work page 2001
-
[24]
Learning latent plans from play, 2019
Corey Lynch, Mohi Khansari, Ted Xiao, Vikash Kumar, Jonathan Tompson, Sergey Levine, and Pierre Sermanet. Learning latent plans from play, 2019. URL https://arxiv.org/abs/ 1903.01973
-
[25]
How far i’ll go: Offline goal-conditioned reinforcement learning viaf-advantage regression, 2022
Yecheng Jason Ma, Jason Yan, Dinesh Jayaraman, and Osbert Bastani. How far i’ll go: Offline goal-conditioned reinforcement learning viaf-advantage regression, 2022. URL https: //arxiv.org/abs/2206.03023
-
[26]
arXiv preprint arXiv:2210.00030 , year=
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training, 2023. URLhttps://arxiv.org/abs/2210.00030
-
[27]
Learning state representation for deep actor-critic control
Jelle Munk, Jens Kober, and Robert Babuška. Learning state representation for deep actor-critic control. In2016 IEEE 55th Conference on Decision and Control (CDC), pages 4667–4673,
-
[28]
doi: 10.1109/CDC.2016.7798980
-
[29]
Vivek Myers, Bill Chunyuan Zheng, Anca Dragan, Kuan Fang, and Sergey Levine. Tempo- ral representation alignment: Successor features enable emergent compositionality in robot instruction following, 2025. URLhttps://arxiv.org/abs/2502.05454
-
[30]
Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092, 2024
-
[31]
Is value learning really the main bottleneck in offline rl?, 2024
Seohong Park, Kevin Frans, Sergey Levine, and Aviral Kumar. Is value learning really the main bottleneck in offline rl?, 2024. URLhttps://arxiv.org/abs/2406.09329
-
[32]
Hiql: Offline goal- conditioned rl with latent states as actions, 2024
Seohong Park, Dibya Ghosh, Benjamin Eysenbach, and Sergey Levine. Hiql: Offline goal- conditioned rl with latent states as actions, 2024. URL https://arxiv.org/abs/2307. 11949
work page 2024
-
[33]
Dual goal representations, 2025
Seohong Park, Deepinder Mann, and Sergey Levine. Dual goal representations, 2025. URL https://arxiv.org/abs/2510.06714
-
[34]
Ronald Parr, Lihong Li, Gavin Taylor, Christopher Painter-Wakefield, and Michael L. Littman. An analysis of linear models, linear value-function approximation, and feature selection for reinforcement learning. InProceedings of the 25th International Conference on Machine Learning, ICML ’08, page 752–759, New York, NY , USA, 2008. Association for Computing...
-
[35]
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lil- licrap, and David Silver. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, December 2020. ISSN 1476-4687. doi: 10.1038/ s41586-020-0...
-
[36]
Data-efficient reinforcement learning with self-predictive representations
Max Schwarzer, Ankesh Anand, Rishab Goel, R Devon Hjelm, Aaron Courville, and Philip Bachman. Data-efficient reinforcement learning with self-predictive representations, 2021. URL https://arxiv.org/abs/2007.05929
-
[37]
Curl: Contrastive unsupervised representations for reinforcement learning
Aravind Srinivas, Michael Laskin, and Pieter Abbeel. Curl: Contrastive unsupervised represen- tations for reinforcement learning, 2020. URLhttps://arxiv.org/abs/2004.04136
-
[38]
Optimal goal-reaching reinforcement learning via quasimetric learning, 2023
Tongzhou Wang, Antonio Torralba, Phillip Isola, and Amy Zhang. Optimal goal-reaching reinforcement learning via quasimetric learning, 2023. URL https://arxiv.org/abs/2304. 01203
work page 2023
-
[39]
Rerogcrl: Representation-based robustness in goal-conditioned reinforcement learning,
Xiangyu Yin, Sihao Wu, Jiaxu Liu, Meng Fang, Xingyu Zhao, Xiaowei Huang, and Wenjie Ruan. Rerogcrl: Representation-based robustness in goal-conditioned reinforcement learning,
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.