Recognition: 2 theorem links
· Lean TheoremTabular Foundation Model for Generative Modelling
Pith reviewed 2026-05-12 02:13 UTC · model grok-4.3
The pith
TabFORGE generates high-quality synthetic tabular data by using causal information captured in a unified latent space from a pretrained encoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
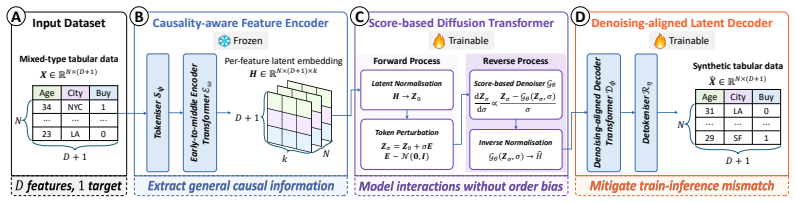
TabFORGE utilises the implicitly learned causal information underlying diverse tabular datasets in a unified latent space induced by a pretrained causality-aware feature encoder. It decouples latent modelling from decoding through a two-stage design: a score-based diffusion transformer is pretrained first, then a denoising-aligned decoder is pretrained using the denoised latent embeddings. This design mitigates distribution shifts between training and inference and enables efficient generation of high-quality synthetic tabular data with strong structural fidelity, as demonstrated in evaluations against 22 benchmark methods on 45 real-world datasets.
What carries the argument
A pretrained causality-aware feature encoder that induces a unified latent space containing causal structural priors of heterogeneous tabular data, paired with a two-stage score-based diffusion transformer and denoising-aligned decoder.
If this is right
- Synthetic tabular data can be generated from a single pretrained model without retraining per dataset from scratch.
- The produced tables exhibit stronger fidelity to the original causal and structural relationships than prior foundation generators.
- Generalisable representations learned across datasets enable transfer of generative capability to new tabular sources.
- The approach matches or exceeds dataset-specific generators in quality while remaining more efficient at inference time.
Where Pith is reading between the lines
- Causal structure appears to be a transferable prior that benefits generation across many tabular sources when encoded in a shared space.
- The two-stage separation of diffusion and decoding may generalise to other data types that require both global structure preservation and local decoding accuracy.
- High-fidelity synthetic tables produced this way could serve as drop-in replacements for real data in privacy-constrained downstream prediction tasks.
Load-bearing premise
A pretrained causality-aware feature encoder already captures the distinctive causal structural prior of heterogeneous tabular data in a unified latent space, and the two-stage diffusion-plus-decoder design sufficiently mitigates distribution shifts between training and inference.
What would settle it
Evaluation on new tabular datasets whose causal structures differ markedly from the pretraining collection, measuring whether synthetic data quality drops below that of strong dataset-specific generators.
Figures




read the original abstract
Generative modelling is a demanding test of foundation models, because it requires robust, holistic representation learning for a given data modality, rather than optimisation for a supervised prediction target alone. While recent work on tabular foundation models has achieved remarkable progress in predictive modelling, generative tabular foundation models remain underexplored. Existing tabular foundation generators, in particular, have not yet consistently matched strong dataset-specific generators in synthetic data quality. A key reason is their misalignment with the distinctive causal structural prior of heterogeneous tabular data. In this paper, we address this gap by introducing a novel tabular foundation model, \textbf{TabFORGE}, built on pretrained \textbf{Tab}ular \textbf{FO}undational \textbf{R}epresentations for \textbf{GE}neration. TabFORGE is designed to utilise the implicitly learned causal information underlying diverse tabular datasets in a unified latent space induced by a pretrained causality-aware feature encoder. It further decouples latent modelling from decoding through a two-stage design: we first pretrain a score-based diffusion transformer, and then pretrain a denoising-aligned decoder using the denoised latent embeddings. This design elegantly mitigates the distribution shifts in latent embeddings that typically arise between training and inference. We evaluate TabFORGE comprehensively against 22 benchmark methods on 45 real-world datasets. Our results show that TabFORGE effectively learns and leverages generalisable tabular representations, enabling efficient generation of high-quality synthetic tabular data, particularly with strong structural fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TabFORGE, a tabular foundation model for generative modeling of heterogeneous data. It builds on a pretrained causality-aware feature encoder to induce a unified latent space that implicitly captures causal structure across datasets, then decouples modeling via a two-stage procedure: pretraining a score-based diffusion transformer on the latents followed by pretraining a denoising-aligned decoder on the denoised embeddings. This is claimed to mitigate train-inference distribution shifts. The model is evaluated against 22 baselines on 45 real-world datasets, with results asserting superior synthetic data quality, particularly structural fidelity, due to generalizable representations.
Significance. If the central claims on causal prior capture and shift mitigation hold with supporting evidence, TabFORGE would represent a meaningful advance in tabular generative foundation models, addressing the gap where prior tabular generators underperform dataset-specific methods. Strengths include the two-stage decoupling design and comprehensive multi-dataset evaluation; reproducible code or parameter-free derivations are not mentioned.
major comments (3)
- [§3.1] §3.1 (pretrained encoder description): The assertion that the causality-aware encoder embeds the 'distinctive causal structural prior' of heterogeneous tabular data into a unified latent space lacks any diagnostic evidence, such as invariance to interventions, recovery of known DAGs on benchmark datasets, or cross-dataset causal consistency metrics. Without this, performance gains cannot be attributed to the claimed mechanism rather than the diffusion transformer alone.
- [§3.3, §4.2] §3.3 and §4.2 (two-stage design and experiments): The claim that pretraining the denoising-aligned decoder on denoised latents 'elegantly mitigates the distribution shifts' is not supported by quantitative diagnostics (e.g., MMD, Wasserstein distance, or latent marginal comparisons between training and inference). No ablation against a joint diffusion baseline is reported to isolate the contribution of the two-stage procedure.
- [§4.1, Table 2] §4.1 and Table 2 (evaluation): The abstract and results claim superior performance on 45 datasets, but no error bars, statistical significance tests (e.g., paired t-tests or Wilcoxon), or details on how 'structural fidelity' was measured (e.g., via causal discovery metrics or correlation structure preservation) are provided to substantiate the central claim over the 22 baselines.
minor comments (2)
- [§3.2] Notation for the latent space and diffusion process in §3.2 is introduced without explicit equations for the score function or decoder alignment loss, making the two-stage procedure harder to follow.
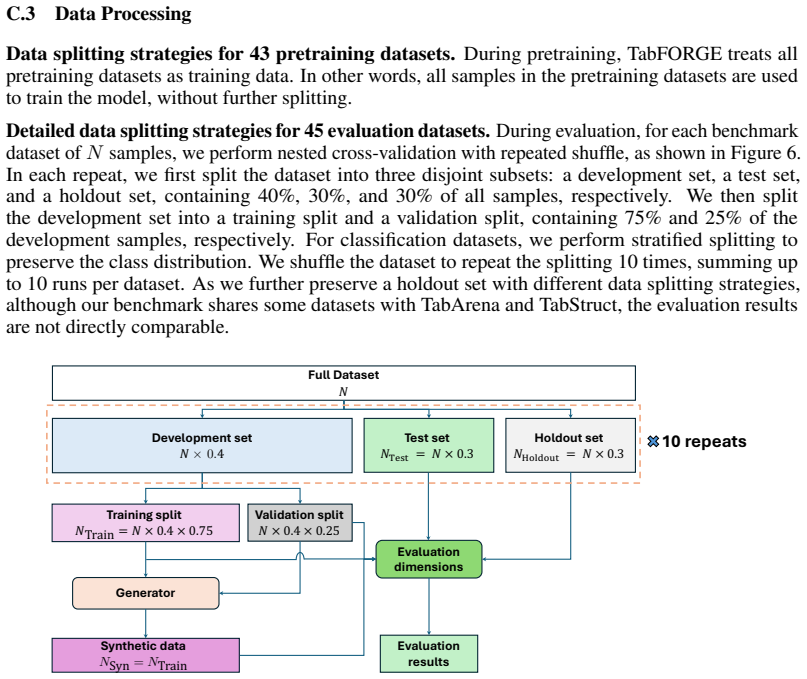
- [§4] The abstract states evaluation on '45 real-world datasets' but the experimental section should clarify the exact train/test splits, preprocessing, and whether any datasets overlap with the encoder pretraining corpus to avoid data leakage concerns.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where we agree and the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (pretrained encoder description): The assertion that the causality-aware encoder embeds the 'distinctive causal structural prior' of heterogeneous tabular data into a unified latent space lacks any diagnostic evidence, such as invariance to interventions, recovery of known DAGs on benchmark datasets, or cross-dataset causal consistency metrics. Without this, performance gains cannot be attributed to the claimed mechanism rather than the diffusion transformer alone.
Authors: We agree that the manuscript would be strengthened by direct diagnostic evidence linking the latent space to causal structure. The encoder is adopted from prior work specifically designed to capture causal priors across tabular datasets; our contribution focuses on its use for generative modeling. In the revised version, we will expand §3.1 with references to the encoder's original validation and add supplementary analyses (latent space visualizations and cross-dataset consistency metrics) to better support the claim. Full intervention-based tests will be noted as future work if resource constraints prevent complete inclusion. revision: partial
-
Referee: [§3.3, §4.2] §3.3 and §4.2 (two-stage design and experiments): The claim that pretraining the denoising-aligned decoder on denoised latents 'elegantly mitigates the distribution shifts' is not supported by quantitative diagnostics (e.g., MMD, Wasserstein distance, or latent marginal comparisons between training and inference). No ablation against a joint diffusion baseline is reported to isolate the contribution of the two-stage procedure.
Authors: We acknowledge that quantitative diagnostics for shift mitigation and an ablation against a joint diffusion model are missing. In the revision, we will add MMD and Wasserstein distance comparisons between training and inference latents, plus an ablation study on a representative subset of datasets comparing the two-stage design to a single-stage joint diffusion baseline. These additions will isolate the two-stage contribution and directly support the shift-mitigation claim. revision: yes
-
Referee: [§4.1, Table 2] §4.1 and Table 2 (evaluation): The abstract and results claim superior performance on 45 datasets, but no error bars, statistical significance tests (e.g., paired t-tests or Wilcoxon), or details on how 'structural fidelity' was measured (e.g., via causal discovery metrics or correlation structure preservation) are provided to substantiate the central claim over the 22 baselines.
Authors: We agree that statistical rigor and measurement details are necessary to substantiate the claims. In the revised manuscript, we will report error bars (standard deviations across multiple runs) in Table 2 and all figures, include paired t-tests and Wilcoxon signed-rank tests for comparisons against baselines, and expand the description of structural fidelity metrics to explicitly cover correlation structure preservation and any causal discovery-based evaluations used. revision: yes
Circularity Check
No circularity: architecture described without equations or self-referential reductions
full rationale
The provided abstract and description present TabFORGE as a two-stage model that uses a pretrained causality-aware encoder to induce a unified latent space and then applies a score-based diffusion transformer followed by a denoising-aligned decoder. No equations, derivations, fitted parameters renamed as predictions, or self-citations appear in the text. Claims about mitigating distribution shifts and capturing causal structure are asserted descriptively and supported by empirical evaluation on 45 datasets rather than reducing to inputs by construction. The derivation chain is therefore self-contained at the level of architectural description and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Heterogeneous tabular data has a distinctive causal structural prior that previous generators failed to align with
- domain assumption A pretrained causality-aware feature encoder produces a unified latent space suitable for downstream diffusion modeling
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the early-to-middle layers of a trained PFN model... implicitly capture general causal information
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2623–2631, 2019
work page 2019
-
[3]
Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela van der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International Conference on Machine Learning, pages 290–306. PMLR, 2022
work page 2022
-
[4]
DM Anisuzzaman, Jeffrey G Malins, Paul A Friedman, and Zachi I Attia. Fine-tuning large lan- guage models for specialized use cases.Mayo Clinic Proceedings: Digital Health, 3(1):100184, 2025
work page 2025
-
[5]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Sam Bond-Taylor, Adam Leach, Yang Long, and Chris G Willcocks. Deep generative modelling: A comparative review of vaes, gans, normalizing flows, energy-based and autoregressive models. IEEE transactions on pattern analysis and machine intelligence, 44(11):7327–7347, 2021
work page 2021
-
[7]
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. Deep neural networks and tabular data: A survey.IEEE transactions on neural networks and learning systems, 35(6):7499–7519, 2022
work page 2022
-
[8]
Language models are realistic tabular data generators
Vadim Borisov, Kathrin Sessler, Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. Language models are realistic tabular data generators. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[9]
João Bravo. Nrgboost: Energy-based generative boosted trees.International Conference on Learning Representations, 2025
work page 2025
-
[10]
Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. Smote: synthetic minority over-sampling technique.Journal of artificial intelligence research, 16:321– 357, 2002
work page 2002
-
[11]
Andrew G Clark, Michael Foster, Benedikt Prifling, Neil Walkinshaw, Robert M Hierons, V olker Schmidt, and Robert D Turner. Testing causality in scientific modelling software.ACM Transactions on Software Engineering and Methodology, 33(1):1–42, 2023
work page 2023
-
[12]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[13]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[14]
Systematic assessment of tabular data synthesis algorithms.arXiv e-prints, pages arXiv–2402, 2024
Yuntao Du and Ninghui Li. Systematic assessment of tabular data synthesis algorithms.arXiv e-prints, pages arXiv–2402, 2024
work page 2024
-
[15]
Systematic assessment of tabular data synthesis
Yuntao Du and Ninghui Li. Systematic assessment of tabular data synthesis. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 2414–2428, 2025
work page 2025
-
[16]
Conor Durkan, Artur Bekasov, Iain Murray, and George Papamakarios. Neural spline flows. Advances in neural information processing systems, 32, 2019. 10
work page 2019
-
[17]
Layerlock: Non-collapsing repre- sentation learning with progressive freezing
Goker Erdogan, Nikhil Parthasarathy, Catalin Ionescu, Drew A Hudson, Alexander Lerchner, Andrew Zisserman, Mehdi SM Sajjadi, and Joao Carreira. Layerlock: Non-collapsing repre- sentation learning with progressive freezing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19461–19470, 2025
work page 2025
-
[18]
Tabarena: A living benchmark for machine learning on tabular data
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
work page 2025
-
[19]
Xi Fang, Weijie Xu, Fiona Anting Tan, Ziqing Hu, Jiani Zhang, Yanjun Qi, Srinivasan H Sengamedu, and Christos Faloutsos. Large language models (llms) on tabular data: Prediction, generation, and understanding-a survey.Transactions on Machine Learning Research, 2024
work page 2024
-
[20]
Review of causal discovery methods based on graphical models.Frontiers in genetics, 10:524, 2019
Clark Glymour, Kun Zhang, and Peter Spirtes. Review of causal discovery methods based on graphical models.Frontiers in genetics, 10:524, 2019
work page 2019
-
[21]
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data.Advances in neural information processing systems, 34:18932– 18943, 2021
work page 2021
-
[22]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models.arXiv preprint arXiv:2511.08667, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data?Advances in neural information processing systems, 35:507–520, 2022
work page 2022
-
[24]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
work page 2025
-
[25]
Lasse Hansen, Nabeel Seedat, Mihaela van der Schaar, and Andrija Petrovic. Reimagining syn- thetic tabular data generation through data-centric ai: A comprehensive benchmark.Advances in Neural Information Processing Systems, 36:33781–33823, 2023
work page 2023
-
[26]
Mikel Hernandez, Gorka Epelde, Ane Alberdi, Rodrigo Cilla, and Debbie Rankin. Synthetic data generation for tabular health records: A systematic review.Neurocomputing, 493:28–45, 2022
work page 2022
-
[27]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
work page 2025
-
[28]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[29]
Sok: Privacy-preserving data synthesis
Yuzheng Hu, Fan Wu, Qinbin Li, Yunhui Long, Gonzalo Munilla Garrido, Chang Ge, Bolin Ding, David Forsyth, Bo Li, and Dawn Song. Sok: Privacy-preserving data synthesis. In2024 IEEE Symposium on Security and Privacy (SP), pages 4696–4713. IEEE, 2024
work page 2024
-
[30]
J. D. Hunter. Matplotlib: A 2d graphics environment.Computing in Science & Engineering, 9(3):90–95, 2007
work page 2007
-
[31]
TabSCM: A practical Framework for Generating Realistic Tabular Data
Sven Jacob, Bardh Prenkaj, Weijia Shao, and Gjergji Kasneci. Tabscm: A practical framework for generating realistic tabular data.arXiv preprint arXiv:2604.22337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Jun-Peng Jiang, Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and Han-Jia Ye. Representation learning for tabular data: A comprehensive survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026. 11
work page 2026
-
[33]
Xiangjian Jiang. Tabcamel: A dataframe-focused solution for tabular datasets in machine learning workflows.https://github.com/SilenceX12138/TabCamel, 2025
work page 2025
-
[34]
Xiangjian Jiang. Tabeval: A comprehensive evaluation framework for tabular synthetic data generation.https://github.com/SilenceX12138/TabEval, 2025
work page 2025
-
[35]
Xiangjian Jiang, Andrei Margeloiu, Nikola Simidjievski, and Mateja Jamnik. Protogate: prototype-based neural networks with global-to-local feature selection for tabular biomedical data. InProceedings of the 41st International Conference on Machine Learning, pages 21844– 21878, 2024
work page 2024
-
[36]
Xiangjian Jiang, Nikola Simidjievski, and Mateja Jamnik. How well does your tabular generator learn the structure of tabular data? InICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy, 2025
work page 2025
-
[37]
Tabstruct: Measuring structural fidelity of tabular data
Xiangjian Jiang, Nikola Simidjievski, and Mateja Jamnik. Tabstruct: Measuring structural fidelity of tabular data. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[38]
Pate-gan: Generating synthetic data with differential privacy guarantees
James Jordon, Jinsung Yoon, and Mihaela Van Der Schaar. Pate-gan: Generating synthetic data with differential privacy guarantees. InInternational conference on learning representations, 2018
work page 2018
-
[39]
Causal machine learning: A survey and open problems.arXiv preprint arXiv:2206.15475, 2022
Jean Kaddour, Aengus Lynch, Qi Liu, Matt J Kusner, and Ricardo Silva. Causal machine learning: A survey and open problems.arXiv preprint arXiv:2206.15475, 2022
-
[40]
Jan Kapar, Niklas Koenen, and Martin Jullum. What’s wrong with your synthetic tabular data? using explainable ai to evaluate generative models.arXiv e-prints, pages arXiv–2504, 2025
work page 2025
-
[41]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
work page 2022
-
[42]
Neville Kenneth Kitson, Anthony C Constantinou, Zhigao Guo, Yang Liu, and Kiattikun Chobtham. A survey of bayesian network structure learning.Artificial Intelligence Review, 56(8):8721–8814, 2023
work page 2023
-
[43]
Tabddpm: Mod- elling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Mod- elling tabular data with diffusion models. InInternational conference on machine learning, pages 17564–17579. PMLR, 2023
work page 2023
-
[44]
Prior Lab. tabpfn-extensions: Community extensions for tabpfn, the foundation model for tabular data.https://github.com/priorlabs/tabpfn-extensions, 2026
work page 2026
-
[45]
Anton D Lautrup, Tobias Hyrup, Arthur Zimek, and Peter Schneider-Kamp. Syntheval: a framework for detailed utility and privacy evaluation of tabular synthetic data.Data Mining and Knowledge Discovery, 39(1):6, 2025
work page 2025
-
[46]
Guillaume Lemaître, Fernando Nogueira, and Christos K. Aridas. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning.Journal of Machine Learning Research, 18(17):1–5, 2017
work page 2017
-
[47]
Jiale Li, Run Qian, Yandan Tan, Zhixin Li, Luyu Chen, Sen Liu, Jie Wu, and Hongfeng Chai. Tabsal: Synthesizing tabular data with small agent assisted language models.Knowledge-Based Systems, 304:112438, 2024
work page 2024
-
[48]
Ctsyn: A foundation model for cross tabular data generation
Xiaofeng Lin, Chenheng Xu, Matthew Yang, and Guang Cheng. Ctsyn: A foundation model for cross tabular data generation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[49]
ctsyn: A foundation model for cross tabular data generation
Xiaofeng Lin, Chenheng Xu, Matthew Yang, and Guang Cheng. The official implementa- tion of the paper "ctsyn: A foundation model for cross tabular data generation". https: //openreview.net/forum?id=Sh4FOyZRpv, 2025. 12
work page 2025
-
[50]
Zinan Lin, Ashish Khetan, Giulia Fanti, and Sewoong Oh. Pacgan: The power of two samples in generative adversarial networks.Advances in neural information processing systems, 31, 2018
work page 2018
-
[51]
Goggle: Generative modelling for tabular data by learning relational structure
Tennison Liu, Zhaozhi Qian, Jeroen Berrevoets, and Mihaela van der Schaar. Goggle: Generative modelling for tabular data by learning relational structure. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[52]
An evaluation framework for synthetic data generation models
Ioannis E Livieris, Nikos Alimpertis, George Domalis, and Dimitris Tsakalidis. An evaluation framework for synthetic data generation models. InIFIP International Conference on Artificial Intelligence Applications and Innovations, pages 320–335. Springer, 2024
work page 2024
-
[53]
Siqi Lu, Junlin Guo, James R Zimmer-Dauphinee, Jordan M Nieusma, Xiao Wang, Parker VanValkenburgh, Steven A Wernke, and Yuankai Huo. Vision foundation models in remote sensing: A survey.IEEE Geoscience and Remote Sensing Magazine, 13(3):190–215, 2025
work page 2025
-
[54]
Tabpfgen– tabular data generation with tabpfn
Junwei Ma, Apoorv Dankar, George Stein, Guangwei Yu, and Anthony Caterini. Tabpfgen– tabular data generation with tabpfn. InNeurIPS 2023 Second Table Representation Learning Workshop, 2023
work page 2023
-
[55]
Tabdpt: Scaling tabular foundation models on real data
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Alex Labach, Jesse C Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L Caterini, and Maksims V olkovs. Tabdpt: Scaling tabular foundation models on real data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[56]
Andrei Margeloiu, Xiangjian Jiang, Nikola Simidjievski, and Mateja Jamnik. Tabebm: A tabular data augmentation method with distinct class-specific energy-based models.Advances in Neural Information Processing Systems, 37:72094–72144, 2024
work page 2024
-
[57]
Tshilidzi Marwala.Causality, correlation and artificial intelligence for rational decision making. World Scientific, 2015
work page 2015
-
[58]
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, Vishak Prasad C, Ganesh Ramakr- ishnan, Micah Goldblum, and Colin White. When do neural nets outperform boosted trees on tabular data?Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[59]
Graphical-model based estimation and inference for differential privacy
Ryan McKenna, Daniel Sheldon, and Gerome Miklau. Graphical-model based estimation and inference for differential privacy. InInternational Conference on Machine Learning, pages 4435–4444. PMLR, 2019
work page 2019
-
[60]
Continuous diffusion for mixed-type tabular data
Markus Mueller, Kathrin Gruber, and Dennis Fok. Continuous diffusion for mixed-type tabular data. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[61]
Vivian Nastl and Moritz Hardt. Do causal predictors generalize better to new domains? Advances in Neural Information Processing Systems, 37:31202–31315, 2024
work page 2024
-
[62]
Elias Chaibub Neto. Tabsds: a lightweight, fully non-parametric, and model free approach for generating synthetic tabular data. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[63]
Generating realistic tabular data with large language models
Dang Nguyen, Sunil Gupta, Kien Do, Thin Nguyen, and Svetha Venkatesh. Generating realistic tabular data with large language models. In2024 IEEE International Conference on Data Mining (ICDM), pages 330–339. IEEE, 2024
work page 2024
-
[64]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[65]
Zhaozhi Qian, Rob Davis, and Mihaela Van Der Schaar. Synthcity: a benchmark framework for diverse use cases of tabular synthetic data.Advances in neural information processing systems, 36:3173–3188, 2023. 13
work page 2023
-
[66]
Tabicl: A tabular foundation model for in-context learning on large data
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. Tabicl: A tabular foundation model for in-context learning on large data. InInternational Conference on Machine Learning, pages 50817–50847. PMLR, 2025
work page 2025
-
[67]
Tabiclv2: A better, faster, scalable, and open tabular foundation model, 2026
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. Tabiclv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139, 2026
-
[68]
tabddpm: Modelling tabular data with diffusion models
Yandex Research. The official implementation of the paper "tabddpm: Modelling tabular data with diffusion models".https://github.com/yandex-research/tab-ddpm, 2023
work page 2023
-
[69]
Learning deep generative models.Annual Review of Statistics and Its Application, 2(1):361–385, 2015
Ruslan Salakhutdinov. Learning deep generative models.Annual Review of Statistics and Its Application, 2(1):361–385, 2015
work page 2015
-
[70]
Findiff: Diffusion models for financial tabular data generation
Timur Sattarov, Marco Schreyer, and Damian Borth. Findiff: Diffusion models for financial tabular data generation. InProceedings of the Fourth ACM International Conference on AI in Finance, pages 64–72, 2023
work page 2023
-
[71]
Rick Sauber-Cole and Taghi M Khoshgoftaar. The use of generative adversarial networks to alleviate class imbalance in tabular data: a survey.Journal of Big Data, 9(1):98, 2022
work page 2022
-
[72]
Curated llm: synergy of llms and data curation for tabular augmentation in low-data regimes
Nabeel Seedat, Nicolas Huynh, Boris Van Breugel, and Mihaela Van Der Schaar. Curated llm: synergy of llms and data curation for tabular augmentation in low-data regimes. InProceedings of the 41st International Conference on Machine Learning, pages 44060–44092, 2024
work page 2024
-
[73]
Tab- diff: a mixed-type diffusion model for tabular data generation
Juntong Shi, Minkai Xu, Harper Hua, Hengrui Zhang, Stefano Ermon, and Jure Leskovec. Tab- diff: a mixed-type diffusion model for tabular data generation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[74]
A comprehensive survey of synthetic tabular data generation.arXiv preprint arXiv:2504.16506, 2025
Ruxue Shi, Yili Wang, Mengnan Du, Xu Shen, Yi Chang, and Xin Wang. A comprehensive survey of synthetic tabular data generation.arXiv preprint arXiv:2504.16506, 2025
-
[75]
Tabular data: Deep learning is not all you need
Ravid Shwartz-Ziv and Amitai Armon. Tabular data: Deep learning is not all you need. Information fusion, 81:84–90, 2022
work page 2022
-
[76]
Shriyank Somvanshi, Subasish Das, Syed Javed, Gian Antariksa, and Ahmed Hossain. A survey on tabular data: From tree-based methods to tabular deep learning.ACM Computing Surveys, 2026
work page 2026
-
[77]
Mihaela CÄ Stoian, Eleonora Giunchiglia, and Thomas Lukasiewicz. A survey on tabular data generation: Utility, alignment, fidelity, privacy, and beyond.arXiv preprint arXiv:2503.05954, 2025
-
[78]
Does tabpfn understand causal structures? InEurIPS 2025 Workshop: AI for Tabular Data, 2025
Omar Swelam, Lennart Purucker, Jake Robertson, Hanne Raum, Joschka Boedecker, and Frank Hutter. Does tabpfn understand causal structures? InEurIPS 2025 Workshop: AI for Tabular Data, 2025
work page 2025
-
[79]
The PyTorch Lightning team. Pytorch lightning. https://github.com/Lightning-AI/ pytorch-lightning, 2026
work page 2026
-
[80]
Paul Tiwald, Ivona Krchova, Andrey Sidorenko, Mariana Vargas Vieyra, Mario Scriminaci, and Michael Platzer. Tabularargn: A flexible and efficient auto-regressive framework for generating high-fidelity synthetic data.arXiv preprint arXiv:2501.12012, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.