Recognition: 2 theorem links
· Lean TheoremDoubly Robust Proxy Causal Learning with Neural Mean Embeddings
Pith reviewed 2026-05-12 03:53 UTC · model grok-4.3
The pith
A neural doubly robust estimator recovers causal response curves for continuous treatments by combining outcome and treatment proxy bridges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By estimating both the outcome-inducing bridge and a neural mean-embedding treatment bridge, then correcting via a final regression stage, the doubly robust estimator consistently recovers the causal response function; the error is bounded by the final averaging and regression errors together with the minimum of the two weak-norm bridge errors.
What carries the argument
Neural mean-embedding estimator for the treatment bridge function, which is averaged and combined with the outcome bridge inside a doubly robust correction obtained by final regression.
If this is right
- The method produces consistent estimators for population, heterogeneous, and conditional dose-response functions rather than binary effects.
- Training stability is achieved through two-stage bridge estimation and history-aware linear-layer updates.
- Error control depends on the smaller of the outcome-side and treatment-side weak-norm bridge errors plus the final regression error.
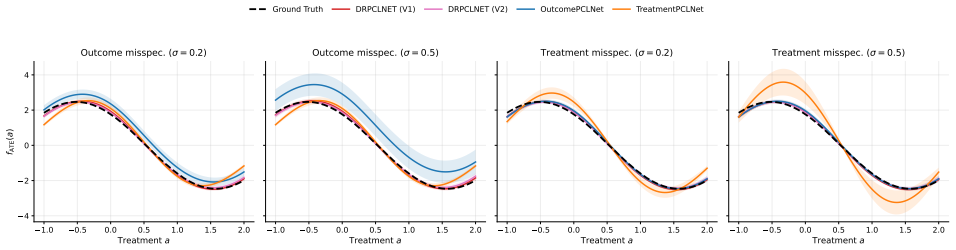
- The approach outperforms single-bridge neural estimators and kernel-based baselines on synthetic and image-valued benchmarks.
Where Pith is reading between the lines
- The construction may extend naturally to other high-dimensional structured treatments where kernel methods become impractical.
- Integration with deeper or recurrent architectures could improve approximation rates for time-varying or sequential treatments.
- The double-robustness property suggests the method remains useful even when one bridge is misspecified, provided the other is accurate enough.
Load-bearing premise
Valid treatment- and outcome-inducing proxies exist that satisfy the required bridge equations, and neural networks can approximate those bridge functions sufficiently well in the relevant norms.
What would settle it
A dataset where the proxies satisfy the bridge equations yet the estimated response curve deviates from the true causal curve by more than the sum of the reported final-stage and minimum-bridge errors.
Figures




read the original abstract
Unobserved confounding prevents standard covariate adjustment from identifying causal response functions in observational studies. Proxy causal learning addresses this problem through bridge equations involving treatment- and outcome-inducing proxies, avoiding direct recovery of the latent confounder. Existing doubly robust proxy estimators combine outcome and treatment bridges, but typically rely on fixed kernels, sieves, or low-dimensional semiparametric models; existing neural proxy methods are more flexible, but are largely single-bridge estimators. We develop a neural doubly robust framework for proxy causal learning with continuous and structured treatments. Our method introduces a neural mean-embedding estimator for the treatment bridge, combines it with a neural outcome bridge, and estimates the doubly robust correction through a final regression stage. The framework covers population, heterogeneous, and conditional dose-response functions, yielding full response-curve estimators rather than binary-treatment effects. The algorithms use two stages for each bridge and history-aware updates of the final linear layers to stabilize stochastic multi-stage training. We prove consistency of the algorithms showing that the doubly robust error is controlled by the final averaging and regression errors together with the smaller of the outcome- and treatment-side weak-norm bridge errors. Across synthetic and image-valued benchmarks, the proposed estimators outperform existing baselines and single-bridge neural estimators, showing the benefit of combining learned outcome and treatment bridges in a doubly robust construction. Our implementation is available at https://github.com/BariscanBozkurt/DRPCL-Neural-Mean-Embedding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a neural doubly robust framework for proxy causal learning with continuous and structured treatments. It introduces a neural mean-embedding estimator for the treatment bridge, combines it with a neural outcome bridge, and estimates the doubly robust correction via a final regression stage. The method covers population, heterogeneous, and conditional dose-response functions. Training uses two stages per bridge with history-aware linear-layer updates for stability. A consistency result is proved showing that the doubly robust error is controlled by final averaging/regression errors together with the smaller of the outcome- and treatment-side weak-norm bridge errors. Empirical results on synthetic and image-valued benchmarks show outperformance over baselines and single-bridge neural estimators, with code released at a GitHub repository.
Significance. If the consistency theorem holds under the stated proxy and approximation conditions, the work meaningfully extends proxy causal learning by providing a flexible, doubly robust neural approach that improves robustness for non-binary treatments. The explicit error bound in terms of the minimum bridge error plus regression terms follows standard doubly robust logic while accommodating neural function classes. Open-source code supports reproducibility and is a clear strength.
minor comments (3)
- §3 (bridge function definitions): the weak-norm notation is introduced without an explicit comparison to standard RKHS or L2 norms; adding one sentence relating the weak norm to the bridge equation would clarify the approximation requirements for neural networks.
- §5 (experiments): benchmark tables report point estimates but omit standard errors or confidence intervals across runs; including these would strengthen the claim of consistent outperformance over single-bridge estimators.
- Algorithm 1/2 (training procedure): the history-aware linear-layer update is described in prose; a short pseudocode block would improve clarity for readers implementing the two-stage stabilization.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation for minor revision. The provided summary accurately captures the main contributions of the paper, including the neural doubly robust framework, the mean-embedding treatment bridge, consistency guarantees, and empirical results. No major comments were listed in the report.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper's central consistency result bounds the doubly robust error explicitly in terms of final regression/averaging errors plus the smaller of the two weak-norm bridge approximation errors. This follows directly from standard doubly robust analysis once the neural mean-embedding estimators for the treatment and outcome bridges are assumed to achieve the stated rates in the relevant function spaces; the bound does not reduce to any fitted parameter by construction, nor does it rely on a self-citation chain for its validity. The two-stage training procedure and history-aware linear-layer updates are presented as practical stabilization heuristics without being invoked in the theoretical guarantee. Empirical comparisons on synthetic and image benchmarks are reported separately from the proof and do not serve as load-bearing evidence for the consistency claim. No self-definitional, fitted-input-renamed-as-prediction, or uniqueness-imported-from-authors steps appear in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network architecture and hyperparameters
axioms (2)
- domain assumption Existence of treatment-inducing and outcome-inducing proxies satisfying the bridge equations
- domain assumption Neural networks can approximate the required bridge functions in the relevant weak norms
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 5.1 (Dose-response consistency of OutcomeNet, TreatmentNet, and DRPCLNET). ... doubly robust error is controlled by the final averaging and regression errors together with the smaller of the outcome- and treatment-side weak-norm bridge errors.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop a neural doubly robust framework for proxy causal learning with continuous and structured treatments. ... neural mean-embedding estimator for the treatment bridge
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
P. Rosenbaum and D. Rubin. The central role of the propensity score in observational studies for causal effects.Biometrika, 70:41–55, 1983
work page 1983
-
[3]
Guido Imbens. Nonparametric estimation of average treatment effects under exogeneity: A review.Review of Economics and Statistics, 2004
work page 2004
-
[4]
Jennifer L. Hill. Bayesian nonparametric modeling for causal inference.Journal of Computational and Graphical Statistics, 20:217–240, 03 2011. doi: 10.1198/jcgs.2010.08162
-
[5]
Learning representations for counterfactual inference
Fredrik Johansson, Uri Shalit, and David Sontag. Learning representations for counterfactual inference. In International Conference on Machine Learning, 2016
work page 2016
-
[6]
Representation learning for treatment effect estimation from observational data
Liuyi Yao, Sheng Li, Yaliang Li, Mengdi Huai, Jing Gao, and Aidong Zhang. Representation learning for treatment effect estimation from observational data. InAdvances in Neural Information Processing Systems, 2018. URL https://proceedings.neurips.cc/paper_files/paper/2018/file/a50abba8132 a77191791390c3eb19fe7-Paper.pdf
work page 2018
-
[7]
PhD thesis, Almqvist & Wiksell, 1945
Olav Reiersøl.Confluence analysis by means of instrumental sets of variables. PhD thesis, Almqvist & Wiksell, 1945
work page 1945
-
[8]
James Stock and Francesco Trebbi. Retrospectives: Who invented instrumental variable regression?Journal of Economic Perspectives - J ECON PERSPECT, 17:177–194, 09 2003. doi: 10.1257/089533003769204416
-
[9]
Whitney K. Newey and James L. Powell. Instrumental variable estimation of nonparametric models. Econometrica, 71(5):1565–1578, 2003. ISSN 00129682, 14680262. URLhttp://www.jstor.org/stable/1 555512
work page 2003
-
[10]
Measurement bias and effect restoration in causal inference.Biometrika, 101(2):423–437, 2014
Manabu Kuroki and Judea Pearl. Measurement bias and effect restoration in causal inference.Biometrika, 101(2):423–437, 2014
work page 2014
-
[11]
Wang Miao, Zhi Geng, and Eric Tchetgen Tchetgen. Identifying causal effects with proxy variables of an unmeasured confounder.Biometrika, 105(4):987—993, 2018
work page 2018
-
[12]
Tchetgen Tchetgen, Andrew Ying, Yifan Cui, Xu Shi, and Wang Miao
Eric J. Tchetgen Tchetgen, Andrew Ying, Yifan Cui, Xu Shi, and Wang Miao. An introduction to proximal causal inference.Statistical Science, 39(3):375–390, 2024. doi: 10.1214/23-STS911
-
[13]
Yifan Cui, Hongming Pu, Xu Shi, Wang Miao, and Eric Tchetgen Tchetgen. Semiparametric proximal causal inference.Journal of the American Statistical Association, 119(546):1348–1359, 2024. doi: 10.1080/ 01621459.2023.2191817. URLhttps://doi.org/10.1080/01621459.2023.2191817
-
[14]
Proxy controls and panel data, 2023
Ben Deaner. Proxy controls and panel data, 2023. URLhttps://arxiv.org/abs/1810.00283
-
[15]
Kusner, Arthur Gretton, and Krikamol Muandet
Afsaneh Mastouri, Yuchen Zhu, Limor Gultchin, Anna Korba, Ricardo Silva, Matt J. Kusner, Arthur Gretton, and Krikamol Muandet. Proximal causal learning with kernels: Two-stage estimation and moment restriction. InInternational Conference on Machine Learning, 2021
work page 2021
-
[16]
Kernel methods for unobserved confounding: Negative controls, proxies, and instruments,
Rahul Singh. Kernel methods for unobserved confounding: Negative controls, proxies, and instruments,
- [17]
-
[18]
Deep proxy causal learning and its application to confounded bandit policy evaluation
Liyuan Xu, Heishiro Kanagawa, and Arthur Gretton. Deep proxy causal learning and its application to confounded bandit policy evaluation. InAdvances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=0FDxsIEv9G. 11
work page 2021
-
[19]
Benjamin Kompa, David Bellamy, Tom Kolokotrones, Andrew Beam, et al. Deep learning methods for proximal inference via maximum moment restriction.Advances in Neural Information Processing Systems, 2022
work page 2022
-
[20]
James M. Robins, Miguel A. Hernán, and Babette Brumback. Marginal structural models and causal inference in epidemiology.Epidemiology, 11(5):550–560, September 2000. doi: 10.1097/00001648-2000090 00-00011. PMID: 10955408
-
[21]
Nathan Kallus, Xiaojie Mao, and Masatoshi Uehara. Causal inference under unmeasured confounding with negative controls: A minimax learning approach, 2021
work page 2021
-
[22]
Density ratio-based proxy causal learning without density ratios
Bariscan Bozkurt, Ben Deaner, Dimitri Meunier, Liyuan Xu, and Arthur Gretton. Density ratio-based proxy causal learning without density ratios. InThe 28th International Conference on Artificial Intelligence and Statistics, 2025
work page 2025
-
[23]
Bingxi Zhang, Tao Shen, and Yifan Cui. Neural estimation of treatment bridge functions for proximal causal inference.Statistical Analysis and Data Mining: An ASA Data Science Journal, 18(5):e70045, 2025. doi: https://doi.org/10.1002/sam.70045. URL https://onlinelibrary.wiley.com/doi/abs/10.1002/ sam.70045
-
[24]
Heejung Bang and James M. Robins. Doubly robust estimation in missing data and causal inference models.Biometrics, 61(4):962–973, December 2005. doi: 10.1111/j.1541-0420.2005.00377.x. PMID: 16401269
-
[25]
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal, 21(1):C1–C68, 2018. doi: 10.1111/ectj.12097
-
[26]
Edward H. Kennedy. Semiparametric doubly robust targeted double machine learning: A review. In Eric Laber, Bibhas Chakraborty, Erica E. M. Moodie, Tianxi Cai, and Mark J. van der Laan, editors, Handbook of Statistical Methods for Precision Medicine, pages 207–236. Chapman and Hall/CRC, 2024. doi: 10.48550/arXiv.2203.06469
-
[27]
Doubly robust proximal causal learning for continuous treatments
Yong Wu, Yanwei Fu, Shouyan Wang, and Xinwei Sun. Doubly robust proximal causal learning for continuous treatments. InInternational Conference on Learning Representations, 2024. URLhttps: //openreview.net/forum?id=TjGJFkU3xL
work page 2024
-
[28]
Density ratio-free doubly robust proxy causal learning
Bariscan Bozkurt, Houssam Zenati, Dimitri Meunier, Liyuan Xu, and Arthur Gretton. Density ratio-free doubly robust proxy causal learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=a9HOg4f9Gh
work page 2025
-
[29]
Closed-Form Last Layer Optimization
Alexandre Galashov, Nathaël Da Costa, Liyuan Xu, Philipp Hennig, and Arthur Gretton. Closed-form last layer optimization, 2025. URLhttps://arxiv.org/abs/2510.04606
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
A neural mean embedding approach for back-door and front-door adjustment
Liyuan Xu and Arthur Gretton. A neural mean embedding approach for back-door and front-door adjustment. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps: //openreview.net/forum?id=rLguqxYvYHB
work page 2023
-
[31]
Learning deep features in instrumental variable regression
Liyuan Xu, Yutian Chen, Siddarth Srinivasan, Nando de Freitas, Arnaud Doucet, and Arthur Gretton. Learning deep features in instrumental variable regression. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=sy4Kg_ZQmS7
work page 2021
-
[32]
Peter J. Huber. Robust estimation of a location parameter.The Annals of Mathematical Statistics, 35(1): 73–101, 1964
work page 1964
-
[33]
Mathematical Programming , author =
Dong C. Liu and Jorge Nocedal. On the limited memory BFGS method for large scale optimization. Mathematical Programming, 45(1):503–528, 1989. doi: 10.1007/BF01589116. URLhttps://doi.org/10 .1007/BF01589116. 12
-
[34]
Andrew Bennett, Nathan Kallus, Xiaojie Mao, Whitney K Newey, Vasilis Syrgkanis, and Masatoshi Uehara. Inference on strongly identified functionals of weakly identified functions.Journal of the Royal Statistical Society Series B: Statistical Methodology, page qkaf075, 2025
work page 2025
-
[35]
Zonghao Chen, Atsushi Nitanda, Arthur Gretton, and Taiji Suzuki. Towards a unified analysis of neural networks in nonparametric instrumental variable regression: Optimization and generalization.arXiv preprint arXiv:2511.14710, 2025
-
[36]
Bartlett, Olivier Bousquet, and Shahar Mendelson
Peter L. Bartlett, Olivier Bousquet, and Shahar Mendelson. Local Rademacher complexities.The Annals of Statistics, 33(4):1497 – 1537, 2005. doi: 10.1214/009053605000000282. URL https: //doi.org/10.1214/009053605000000282
-
[37]
Orthogonal statistical learning.The Annals of Statistics, 51(3): 879–908, 2023
Dylan J Foster and Vasilis Syrgkanis. Orthogonal statistical learning.The Annals of Statistics, 51(3): 879–908, 2023
work page 2023
-
[38]
Richard Blundell, Xiaohong Chen, and Dennis Kristensen. Semi-nonparametric iv estimation of shape- invariant engel curves.Econometrica, 75(6):1613–1669, 2007
work page 2007
-
[39]
Xiaohong Chen and Timothy M Christensen. Optimal sup-norm rates and uniform inference on nonlinear functionals of nonparametric iv regression.Quantitative Economics, 9(1):39–84, 2018
work page 2018
-
[40]
dsprites: Disentanglement testing sprites dataset
Loic Matthey, Irina Higgins, Demis Hassabis, and Alexander Lerchner. dsprites: Disentanglement testing sprites dataset. https://github.com/deepmind/dsprites-dataset/, 2017
work page 2017
-
[41]
Jason Abrevaya, Yu-Chin Hsu, and Robert P. Lieli. Estimating conditional average treatment effects. Journal of Business & Economic Statistics, 33(4):485–505, 2015. doi: 10.1080/07350015.2014.975555. URL https://doi.org/10.1080/07350015.2014.975555
-
[42]
Kennedy, Zongming Ma, Matthew D
Edward H. Kennedy, Zongming Ma, Matthew D. McHugh, and Dylan S. Small. Non-parametric Methods for Doubly Robust Estimation of Continuous Treatment Effects.Journal of the Royal Statistical Society Series B: Statistical Methodology, 79(4):1229–1245, 09 2017
work page 2017
-
[43]
Kyle Colangelo and Ying-Ying Lee. Double debiased machine learning nonparametric inference with continuous treatments.Journal of Business & Economic Statistics, pages 1–26, 2025
work page 2025
-
[44]
Double debiased machine learning for mediation analysis with continuous treatments
Houssam Zenati, Judith Abécassis, Julie Josse, and Bertrand Thirion. Double debiased machine learning for mediation analysis with continuous treatments. InInternational Conference on Artificial Intelligence and Statistics, volume 258, pages 4150–4158, 2025
work page 2025
-
[45]
Hilbert space embeddings of conditional distributions with applications to dynamical systems
Le Song, Jonathan Huang, Alex Smola, and Kenji Fukumizu. Hilbert space embeddings of conditional distributions with applications to dynamical systems. InInternational Conference on Machine Learning, 2009
work page 2009
-
[46]
Conditional mean embeddings as regressors
Steffen Grünewälder, Guy Lever, Luca Baldassarre, Sam Patterson, Arthur Gretton, and Massimilano Pontil. Conditional mean embeddings as regressors. InInternational Conference on Machine Learning, 2012
work page 2012
-
[47]
Junhyung Park and Krikamol Muandet. A measure-theoretic approach to kernel conditional mean embeddings.Advances in Neural Information Processing Systems, 2020
work page 2020
-
[48]
Kernel single proxy control for deterministic confounding, 2024
Liyuan Xu and Arthur Gretton. Kernel single proxy control for deterministic confounding, 2024. URL https://arxiv.org/abs/2308.04585
-
[49]
Bernhard Schölkopf, Ralf Herbrich, and Alex J. Smola. A generalized representer theorem. In David Helmbold and Bob Williamson, editors,Computational Learning Theory, pages 416–426, Berlin, Heidelberg,
- [50]
-
[51]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael L...
-
[52]
On rate optimality for ill-posed inverse problems in econometrics
Xiaohong Chen and Markus Reiss. On rate optimality for ill-posed inverse problems in econometrics. Econometric Theory, 27(3):497–521, 2011
work page 2011
-
[53]
Nonparametric Instrumental Regression via Kernel Methods is Minimax Optimal
Dimitri Meunier, Zhu Li, Tim Christensen, and Arthur Gretton. Nonparametric instrumental regression via kernel methods is minimax optimal.arXiv preprint arXiv:2411.19653, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Nonparametric instrumental variable regression with observed covariates, 2025
Zikai Shen, Zonghao Chen, Dimitri Meunier, Ingo Steinwart, Arthur Gretton, and Zhu Li. Nonparametric instrumental variable regression with observed covariates, 2025. URLhttps://arxiv.org/abs/2511.194 04
work page 2025
-
[55]
Optimality and adaptivity of deep neural features for instrumental variable regression
Juno Kim, Dimitri Meunier, Arthur Gretton, Taiji Suzuki, and Zhu Li. Optimality and adaptivity of deep neural features for instrumental variable regression. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 94163–94206, 2025. URL https://proceedings.iclr.cc/paper_files/paper/20...
work page 2025
-
[56]
Cambridge university press, 2019
Martin J Wainwright.High-dimensional statistics: A non-asymptotic viewpoint, volume 48. Cambridge university press, 2019
work page 2019
-
[57]
Yen-Chi Chen. A tutorial on kernel density estimation and recent advances.Biostatistics & Epidemiology, 1(1):161–187, 2017. doi: 10.1080/24709360.2017.1396742. URLhttps://doi.org/10.1080/24709360.2 017.1396742
-
[58]
Masashi Sugiyama, Taiji Suzuki, Shinichi Nakajima, Hisashi Kashima, Paul Bunau, and Motoaki Kawanabe. Direct importance estimation for covariate shift adaptation.Annals of the Institute of Statistical Mathematics, 60(4):699–746, December 2008. doi: 10.1007/s10463-008-0197-x. URL https://ideas.repec.org/a/spr/aistmt/v60y2008i4p699-746.html
-
[59]
beta-VAE: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-VAE: Learning basic visual concepts with a constrained variational framework. InInternational Conference on Learning Representations, 2017. URL https: //openreview.net/forum?id=Sy2fzU9gl
work page 2017
-
[60]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=Bkg6RiCqY7. 14 Appendix Contents A Treatment bridge identification of the heterogeneous dose-response 16 B Doubly robust identification of causal functions: dose, heterogeneous, and condi...
work page 2019
-
[61]
Outcome bridge network.We begin with the Deep Feature Proxy Causal Learning (DFPCL) architecture of Xu et al.[17], which provides a neural parameterization of the outcome bridge estimator. We refine this component by incorporating proximal closed-form updates for the final linear layer and by introducing a hybrid optimization scheme for the second-stage h...
-
[62]
Treatment bridge network.We next introduce a neural estimator of the treatment bridge function in Section E.2. This construction follows the same principles as the outcome-side network: adaptive feature learning, proximal closed-form updates for the last linear layer, and hybrid optimization in the second stage. 26
-
[63]
This final stage is designed to leverage the complementary strengths of both bridge functions
Neural doubly robust unification.Finally, in Section E.3, we combine the outcome- and treatment- bridge components into a fully neural doubly robust estimator of the dose-response curve. This final stage is designed to leverage the complementary strengths of both bridge functions. E.1 Dose-response curve estimation: outcome bridge-based approach We first ...
-
[64]
Featurizer update.We first update the second-stage neural parametersθ(h) 2 by a gradient step on Equation 42, using the current estimate of the head and the current auxiliary first-stage operatorˇV (h) t
-
[65]
Head refinement.Holding the feature extractors fixed, we then refine the second-stage linear headh by approximately minimizing Equation 42 with respect toh. In our implementation, this inner optimization is performed byKh steps of L-BFGS [32], using thePyTorchimplementation [49]. This numerical refinement plays the same role as the closed-form update in t...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.