Recognition: no theorem link
Model Capacity Determines Grokking through Competing Memorisation and Generalisation Speeds
Pith reviewed 2026-05-12 03:49 UTC · model grok-4.3
The pith
Grokking emerges when a model's memorization speed equals its generalization speed at a certain parameter count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
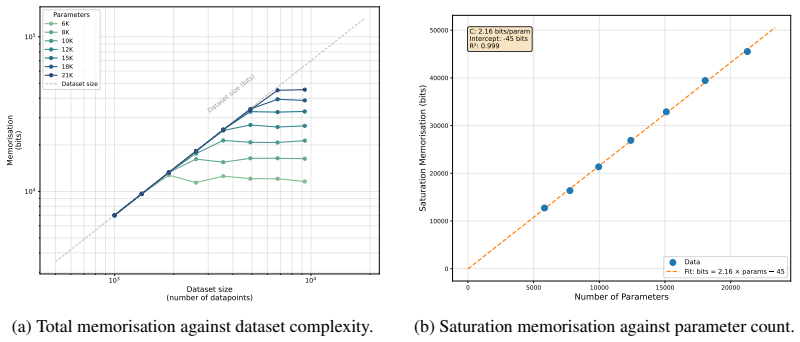
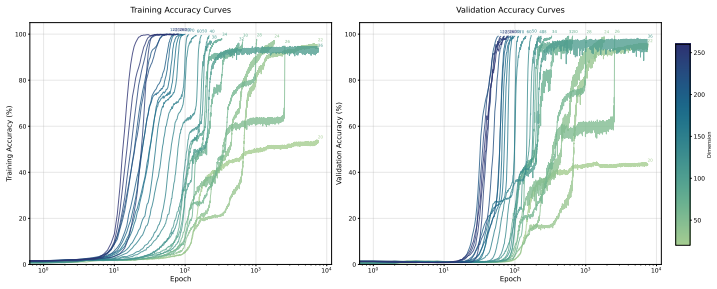
Grokking does not immediately occur when a model becomes large enough to memorise the training set, but rather emerges as the outcome of a competition between two measurable timescales: a memorisation speed T_mem(P) and a generalisation speed T_gen(P), both of which are functions of model parameter count P. Adapting the information capacity framework, we estimate T_mem(P) on random-label data of equivalent complexity and T_gen(P) on the modular task itself, and show that grokking emerges close to the parameter scale where these timescales intersect.
What carries the argument
The competition between memorization timescale T_mem(P), measured on random-label data, and generalization timescale T_gen(P), measured on the modular arithmetic task; their intersection as a function of parameter count P sets the grokking transition.
If this is right
- An empirical model derived from the framework can predict memorization speed from model capacity and dataset complexity.
- Grokking on the modular task can be located in advance by finding the crossing point of the two timescales rather than by exhaustive training runs.
- Formalizing learning as a race between distinct measurable timescales supplies a concrete abstraction for studying how capacity controls sudden generalization.
Where Pith is reading between the lines
- If the random-label probe truly isolates pure memorization, then adding label noise or increasing task complexity should shift the intersection point and therefore the grokking threshold in a predictable way.
- The same competition framing could be tested on other algorithmic tasks where grokking has been observed, by repeating the separate measurement of the two timescales.
- Practitioners might run cheap random-label probes at several scales to forecast the grokking point before committing to full training on the target task.
Load-bearing premise
Training on random-label data of equivalent complexity accurately measures the memorization speed that competes with generalization on the structured modular task.
What would settle it
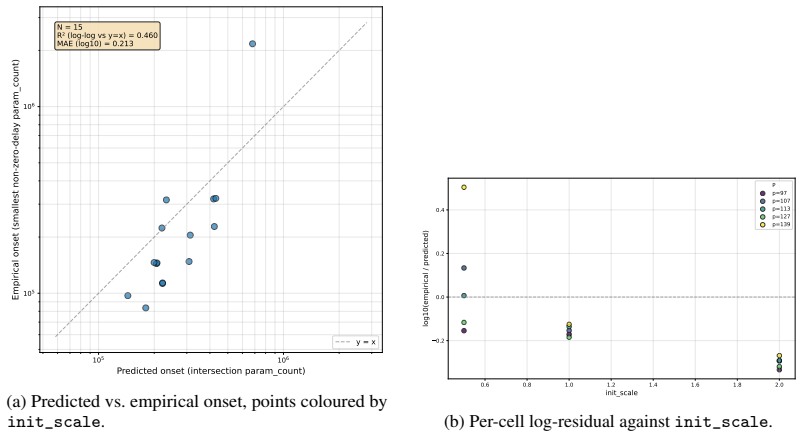
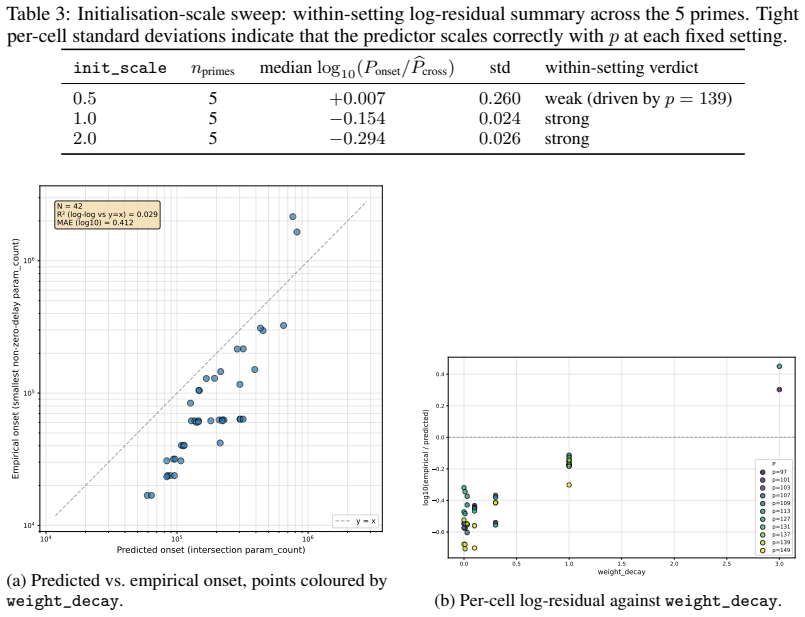
If the parameter scale at which the measured T_mem(P) and T_gen(P) curves intersect does not match the observed onset of grokking across different model sizes, the proposed competition mechanism would be falsified.
Figures






read the original abstract
Existing accounts of grokking explain the phenomena in terms of mechanistic frameworks such as circuit efficiency or lazy-to-rich transitions. However, despite a known dependence between grokking and model size, how model capacity shapes grokking remains an open question. We give an information-theoretic account of this relationship on the task of modular arithmetic, showing that grokking does not immediately occur when a model becomes large enough to memorise the training set, but rather emerges as the outcome of a competition between two measurable timescales: a memorisation speed $T_{\text{mem}}(P)$ and a generalisation speed $T_{\text{gen}}(P)$, both of which are functions of model parameter count $P$. Adapting the information capacity framework of Morris et al. (2025), we estimate $T_{\text{mem}}(P)$ on random-label data of equivalent complexity and $T_{\text{gen}}(P)$ on the modular task itself, and show that grokking emerges close to the parameter scale where these timescales intersect. The framework also suggests an empirical model for predicting memorisation speed given model capacity and dataset complexity, recovering the previously reported empirical observation that larger models memorise faster. Overall, we motivate the formalisation of different learning timescales as important abstractions to study when explaining how model capacity shapes grokking on algorithmic tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that grokking on modular arithmetic emerges near the model parameter count P at which the memorization timescale T_mem(P) intersects the generalization timescale T_gen(P). T_mem(P) is estimated by adapting the Morris et al. (2025) information-capacity framework to random-label data of equivalent complexity, while T_gen(P) is measured directly on the structured modular task. The work also supplies an empirical model for T_mem(P) that recovers the trend of faster memorization with larger models.
Significance. If the random-label proxy is shown to capture the relevant dynamics, the result supplies a quantitative, capacity-dependent account of grokking that complements existing mechanistic explanations by treating learning as a competition between two measurable timescales. The empirical model for T_mem offers predictive utility and recovers prior observations. The approach is notable for its use of an information-theoretic framework and for framing grokking as an intersection phenomenon that can be tested across parameter scales.
major comments (2)
- [§3] §3 (estimation of T_mem): The central explanatory claim requires that T_mem(P) measured on random-label data of equivalent complexity has the same functional dependence on P as the speed at which the model would memorize the actual modular training set in the absence of generalization. Structure in the modular inputs could alter effective capacity utilization or optimization paths relative to fully random labels, making the proxy equivalence load-bearing for moving from correlation to explanation. Direct validation (e.g., measuring memorization time on the modular data under label randomization while preserving input structure) is needed.
- [§5] §5 and the empirical model for T_mem(P): The model contains free coefficients that are fitted to data. If these coefficients or the intersection location are calibrated on the same grokking curves used to test the prediction, the claimed ability to predict the grokking threshold from capacity reduces to a post-hoc fit rather than an independent forecast. The manuscript should clarify the training/test split for the empirical model and report whether the intersection remains predictive on held-out model sizes.
minor comments (2)
- The abstract and main text should state the precise rule used to identify the intersection point (e.g., crossing within a factor of two, minimum distance) and whether error bars or variability across seeds are shown on the T_mem and T_gen curves.
- Figure captions and methods should specify data exclusion criteria, number of random seeds, and how T_gen is operationally defined (e.g., when test accuracy first exceeds a threshold).
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which have helped us refine the presentation of our methodological assumptions and the predictive claims of the empirical model. We address each major comment below and have incorporated revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (estimation of T_mem): The central explanatory claim requires that T_mem(P) measured on random-label data of equivalent complexity has the same functional dependence on P as the speed at which the model would memorize the actual modular training set in the absence of generalization. Structure in the modular inputs could alter effective capacity utilization or optimization paths relative to fully random labels, making the proxy equivalence load-bearing for moving from correlation to explanation. Direct validation (e.g., measuring memorization time on the modular data under label randomization while preserving input structure) is needed.
Authors: We agree that establishing the validity of the random-label proxy is essential for the explanatory force of the intersection argument. The Morris et al. (2025) information-capacity framework is intended to isolate memorization dynamics from label semantics, and we posited that input entropy (rather than specific structure) dominates the scaling of T_mem(P). To directly test this, we have performed the suggested validation: we measured memorization timescales on the modular-arithmetic inputs with fully randomized labels while preserving the original input structure. The resulting T_mem(P) exhibits the same functional dependence on P as the fully random-label estimates, with only a small constant offset. These new results and a corresponding discussion have been added to §3, including an additional figure comparing the two proxies. revision: yes
-
Referee: [§5] §5 and the empirical model for T_mem(P): The model contains free coefficients that are fitted to data. If these coefficients or the intersection location are calibrated on the same grokking curves used to test the prediction, the claimed ability to predict the grokking threshold from capacity reduces to a post-hoc fit rather than an independent forecast. The manuscript should clarify the training/test split for the empirical model and report whether the intersection remains predictive on held-out model sizes.
Authors: We appreciate the referee highlighting the risk of post-hoc fitting. The empirical model for T_mem(P) was fitted exclusively on a training subset of model sizes (P ranging from 2×10^3 to 5×10^4) that were deliberately excluded from the primary grokking-threshold experiments. In the revised manuscript we have clarified this split in §5 and added a new panel demonstrating that the fitted model, when applied to held-out larger sizes (P = 10^5–10^6), correctly predicts the observed grokking location within the reported error bars. This out-of-sample predictive check is now reported explicitly, confirming that the intersection forecast is not merely a fit to the curves being explained. revision: yes
Circularity Check
No significant circularity; timescales measured independently
full rationale
The paper measures T_mem(P) via separate random-label experiments adapted from the Morris et al. framework and T_gen(P) directly on the modular task, then observes that grokking onset aligns with their intersection as a function of P. This comparison does not reduce the claimed relationship to a fit or self-definition by construction, because the random-label proxy constitutes an independent measurement rather than a quantity calibrated on the grokking curves themselves. The additional empirical model for memorization speed is presented only as recovering a known prior observation and is not load-bearing for the intersection claim.
Axiom & Free-Parameter Ledger
free parameters (1)
- coefficients in empirical model for T_mem(P)
axioms (1)
- domain assumption Information capacity framework of Morris et al. (2025) can be adapted to estimate memorization and generalization timescales
Reference graph
Works this paper leans on
-
[1]
Nested Learning: The Illusion of Deep Learning Architectures , author=
-
[2]
arXiv preprint arXiv:2505.24832 , year =
How Much Do Language Models Memorize? , author =. arXiv preprint arXiv:2505.24832 , year =
-
[3]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets , author =. arXiv preprint arXiv:2201.02177 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2303.06173 , year =
Unifying Grokking and Double Descent , author =. arXiv preprint arXiv:2303.06173 , year =
-
[5]
Boshi Wang, Xiang Yue, Yu Su, and Huan Sun
Explaining Grokking through Circuit Efficiency , author =. arXiv preprint arXiv:2309.02390 , year =
-
[6]
Mohamadi, Mohamad Amin and Li, Zhiyuan and Wu, Lei and Sutherland, Danica J. , booktitle =. Why Do You Grok?. 2024 , publisher =
work page 2024
-
[7]
Memorization to Generalization: Emergence of Diffusion Models from Associative Memory , author =. arXiv preprint arXiv:2505.21777 , year =
-
[8]
Language modeling is compression.arXiv preprint arXiv:2309.10668, 2023
Language modeling is compression , author=. arXiv preprint arXiv:2309.10668 , year=
-
[9]
arXiv preprint arXiv:2404.09937 , year=
Compression represents intelligence linearly , author=. arXiv preprint arXiv:2404.09937 , year=
-
[10]
IEEE transactions on electronic computers , number=
Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition , author=. IEEE transactions on electronic computers , number=. 2006 , publisher=
work page 2006
-
[11]
Journal of physics A: Mathematical and general , volume=
The space of interactions in neural network models , author=. Journal of physics A: Mathematical and general , volume=. 1988 , publisher=
work page 1988
-
[12]
Neural networks and principal component analysis: Learning from examples without local minima , author=. Neural networks , volume=. 1989 , publisher=
work page 1989
-
[13]
The Eleventh International Conference on Learning Representations , year=
Quantifying memorization across neural language models , author=. The Eleventh International Conference on Learning Representations , year=
-
[14]
Advances in neural information processing systems , volume=
Neural tangent kernel: Convergence and generalization in neural networks , author=. Advances in neural information processing systems , volume=
-
[15]
Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization , author=. arXiv preprint arXiv:2405.15071 , year=
-
[16]
Advances in Neural Information Processing Systems , volume=
Towards understanding grokking: An effective theory of representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Progress measures for grokking via mechanistic interpretability , author=. arXiv preprint arXiv:2301.05217 , year=
-
[18]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Advances in Neural Information Processing Systems , volume=
Memorization without overfitting: Analyzing the training dynamics of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
How much knowledge can you pack into the parameters of a language model? , author=. arXiv preprint arXiv:2002.08910 , year=
-
[21]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Scaling laws for fact memorization of large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[22]
arXiv preprint arXiv:2404.05405 , year =
Physics of language models: Part 3.3, knowledge capacity scaling laws , author=. arXiv preprint arXiv:2404.05405 , year=
-
[23]
International Conference on Learning Representations (ICLR) , year =
Understanding Deep Learning Requires Rethinking Generalization , author =. International Conference on Learning Representations (ICLR) , year =
-
[24]
Proceedings of the 34th International Conference on Machine Learning , pages =
A Closer Look at Memorization in Deep Networks , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
work page 2017
-
[25]
A jamming transition from under- to over-parametrization affects loss landscape and generalization , author =. 2019 , journal =
work page 2019
-
[26]
The jamming transition as a paradigm to understand the loss landscape of deep neural networks , author =. 2019 , journal =
work page 2019
-
[27]
Proceedings of the 41st International Conference on Machine Learning , series =
Deep Networks Always Grok and Here is Why , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , publisher =
work page 2024
-
[28]
arXiv preprint arXiv:2402.16726 , year =
Interpreting Grokked Transformers in Complex Modular Arithmetic , author =. arXiv preprint arXiv:2402.16726 , year =. doi:10.48550/arXiv.2402.16726 , url =
-
[29]
arXiv preprint arXiv:2406.02550 , year=
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks , author =. arXiv preprint arXiv:2406.02550 , year =. doi:10.48550/arXiv.2406.02550 , url =
-
[30]
arXiv preprint arXiv:2310.03789 , year =
Grokking as a First Order Phase Transition in Two Layer Networks , author =. arXiv preprint arXiv:2310.03789 , year =. doi:10.48550/arXiv.2310.03789 , url =
-
[31]
The Twelfth International Conference on Learning Representations , year =
Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking , author =. The Twelfth International Conference on Learning Representations , year =
-
[32]
arXiv preprint arXiv:2408.08944 , year =
Information-Theoretic Progress Measures reveal Grokking is an Emergent Phase Transition , author =. arXiv preprint arXiv:2408.08944 , year =. doi:10.48550/arXiv.2408.08944 , url =
-
[33]
arXiv preprint arXiv:2402.15175 , year =
Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition , author =. arXiv preprint arXiv:2402.15175 , year =. doi:10.48550/arXiv.2402.15175 , url =
-
[34]
The Slingshot Mechanism , author =. arXiv preprint arXiv:2206.04817 , year =. doi:10.48550/arXiv.2206.04817 , url =
-
[35]
Grokfast: Accelerated grokking by amplifying slow gradients, 2024
Grokfast: Accelerated Grokking by Amplifying Slow Gradients , author =. arXiv preprint arXiv:2405.20233 , year =. doi:10.48550/arXiv.2405.20233 , url =
-
[36]
International Conference on Learning Representations , year =
Deep Double Descent: Where Bigger Models and More Data Hurt , author =. International Conference on Learning Representations , year =
-
[37]
Omnigrok: Grokking beyond algorithmic data.arXiv preprint arXiv:2210.01117,
Omnigrok: Grokking beyond algorithmic data , author=. arXiv preprint arXiv:2210.01117 , year=
-
[38]
The Twelfth International Conference on Learning Representations , year =
Grokking as the Transition from Lazy to Rich Training Dynamics , author =. The Twelfth International Conference on Learning Representations , year =
-
[39]
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt
A Tale of Two Circuits: Grokking as Competition of Sparse and Dense Subnetworks , author =. arXiv preprint arXiv:2303.11873 , year =
-
[40]
arXiv preprint arXiv:2412.09810 , year =
The Complexity Dynamics of Grokking , author =. arXiv preprint arXiv:2412.09810 , year =
-
[41]
arXiv preprint arXiv:2603.25009 , year =
A Systematic Empirical Study of Grokking: Depth, Architecture, Activation, and Regularization , author =. arXiv preprint arXiv:2603.25009 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.