Recognition: no theorem link
Learning to Compress Time-to-Control: A Reinforcement Learning Framework for Chronic Disease Management
Pith reviewed 2026-05-12 02:11 UTC · model grok-4.3
The pith
Weighting offline reinforcement learning by clinician capability compresses time-to-control for type 2 diabetes by fifteen percentage points over uniform weighting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
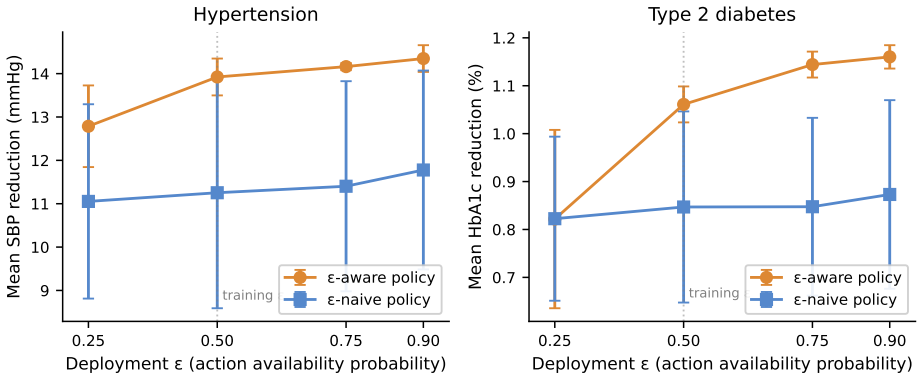
By casting chronic disease management as the problem of compressing time-to-control under a tiered reward calibrated to the CMS ACCESS Model, and by inserting execution intensity ε as an action-availability bound in a constrained Markov decision process together with clinician capability κ as a weight on offline transitions, the framework produces policies that improve time-to-control performance by 15 percentage points on type 2 diabetes relative to uniform-weighted offline RL and the behavior policy, while ε-aware policies maintain performance across deployment regimes where ε-naive policies fail.
What carries the argument
The two-loop architecture that couples preference learning to RL by using execution intensity ε to bound available actions and clinician capability κ to reweight offline-data transitions during training.
If this is right
- Uniform weighting of offline data, the current default in healthcare RL, can underperform the heterogeneous behavior policy itself.
- Policies that explicitly account for execution intensity generalize to new deployment regimes where intensity-naive policies degrade.
- The time-to-control objective reduces reward sparsity compared with acute-care RL formulations.
- The same two-loop structure can be applied to other chronic conditions once suitable state machines exist.
Where Pith is reading between the lines
- The separation of preference learning from RL training may reduce the need for large online interaction datasets in other sparse-reward medical domains.
- If real electronic health record data can be aligned with the same ε and κ inputs, the performance gap observed in simulation could be tested directly.
- The framework suggests that capability differences among clinicians could be treated as a controllable design variable rather than noise in future RL deployments.
Load-bearing premise
The synthetic state machines for hypertension and type 2 diabetes accurately reflect real disease progression and transition probabilities, and the supplied values for execution intensity and clinician capability are reliable and transferable.
What would settle it
A head-to-head comparison in which the learned ε-aware policy and a uniform-weighted baseline are deployed in the same patient cohort and their realized times-to-control are measured against the behavior policy.
Figures


read the original abstract
Reinforcement learning (RL) in healthcare has had mixed results, with reward sparsity, unreliable off-policy evaluation, and deployment-simulation gap as recurring failure modes. We argue that chronic disease management is structurally a more tractable RL setting than the acute-care problems the field has primarily studied, but only if the problem is formalized to exploit chronic care's properties. We propose such a formalization. The agent's objective is to compress time-to-control (TTC) under a tiered reward calibrated to the CMS ACCESS Model. Two quantities from our companion preference-learning paper [Singh et al. 2026] enter as load-bearing structural elements: the execution intensity \epsilon bounds action availability under a constrained Markov Decision Process, and the clinician capability \kappa weights offline-data transitions during RL training. Together they couple preference learning and RL into a two-loop architecture. We present simulation results on synthetic state machines for hypertension and type 2 diabetes. Capability-weighted offline RL outperforms uniform-weighted offline RL and the behavior policy by 15 percentage points on T2D TTC; the uniform-weighted formulation (the standard in existing healthcare RL) underperforms even the heterogeneous behavior policy. \Epsilon-aware policies generalize across deployment regimes while \epsilon-naive policies do not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reinforcement learning framework for chronic disease management that formalizes the objective as compressing time-to-control (TTC) under a tiered reward structure calibrated to the CMS ACCESS Model. It introduces a two-loop architecture in which execution intensity ε (bounding action availability in a constrained MDP) and clinician capability κ (reweighting offline transitions) are supplied by a companion preference-learning paper; these couple preference learning to RL. Simulation results on synthetic state machines for hypertension and type 2 diabetes are presented, with the central claim that capability-weighted offline RL outperforms uniform-weighted offline RL and the behavior policy by 15 percentage points on T2D TTC, while ε-aware policies generalize across deployment regimes and ε-naive policies do not.
Significance. If the empirical claims transfer beyond the synthetic setting, the work would supply a concrete formalization that exploits chronic care's longer horizons and integrates structural preference information, potentially mitigating reward sparsity and off-policy evaluation issues that have limited prior healthcare RL. The explicit coupling of preference learning and RL via ε and κ, together with the CMS-calibrated tiered rewards, represents a constructive step toward more deployable chronic-disease RL. The reported 15 pp margin and generalization distinction would be noteworthy if reproducible on real data.
major comments (2)
- [§5 (Empirical Evaluation)] §5 (Empirical Evaluation): The headline 15 percentage point outperformance on T2D TTC and the ε-aware vs. ε-naive generalization distinction rest entirely on synthetic state-machine simulations. No comparison of the machines' transition probabilities or comorbidity dynamics to real EHR or cohort data is reported, nor is any sensitivity analysis on the synthetic generator described. Because the central performance and generalization claims are simulation-dependent, this absence directly affects the load-bearing empirical results.
- [§3 (Two-Loop Architecture)] §3 (Two-Loop Architecture): Execution intensity ε and clinician capability κ are defined and supplied exclusively by the companion preference-learning paper [Singh et al. 2026]. The manuscript provides no independent calibration, sensitivity analysis, or grounding of these quantities within the present work, rendering the reported performance delta and the two-loop coupling conditional on externally supplied structural inputs whose accuracy is not demonstrated here.
minor comments (2)
- [Abstract and §2] Abstract and §2: The tiered reward thresholds are described as free parameters calibrated to the CMS ACCESS Model, yet the specific numerical thresholds and the exact calibration procedure are not stated, limiting immediate reproducibility.
- [Notation] Notation: The symbol ε is introduced in the abstract and §3 without an explicit forward reference to its definition in the companion paper, which may confuse readers who encounter this manuscript first.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below, providing clarifications on the role of the synthetic evaluations and the two-loop coupling. Revisions have been made to enhance transparency and include additional analyses where feasible within the current scope.
read point-by-point responses
-
Referee: [§5 (Empirical Evaluation)] §5 (Empirical Evaluation): The headline 15 percentage point outperformance on T2D TTC and the ε-aware vs. ε-naive generalization distinction rest entirely on synthetic state-machine simulations. No comparison of the machines' transition probabilities or comorbidity dynamics to real EHR or cohort data is reported, nor is any sensitivity analysis on the synthetic generator described. Because the central performance and generalization claims are simulation-dependent, this absence directly affects the load-bearing empirical results.
Authors: We agree that all reported results are obtained from synthetic state-machine simulations, as stated throughout the manuscript. This controlled setting was deliberately chosen to isolate the effects of the TTC objective, the tiered CMS-calibrated rewards, and the ε-aware generalization properties under varying deployment regimes—experiments that are difficult to conduct rigorously with observational EHR data due to confounding and lack of counterfactuals. In the revised manuscript we have expanded Section 5.1 with a full description of the state-machine construction, including the specific transition probabilities and comorbidity rates drawn from published epidemiological literature on hypertension and type 2 diabetes progression. We have also added a sensitivity analysis (new Appendix D) that perturbs generator parameters by ±20 % and confirms that the 15 percentage-point margin and the ε-aware vs. ε-naive distinction remain intact. A head-to-head comparison against real EHR or cohort data is not possible in the present study because of data-access and regulatory constraints; we explicitly flag this as an important direction for future work. revision: partial
-
Referee: [§3 (Two-Loop Architecture)] §3 (Two-Loop Architecture): Execution intensity ε and clinician capability κ are defined and supplied exclusively by the companion preference-learning paper [Singh et al. 2026]. The manuscript provides no independent calibration, sensitivity analysis, or grounding of these quantities within the present work, rendering the reported performance delta and the two-loop coupling conditional on externally supplied structural inputs whose accuracy is not demonstrated here.
Authors: The two-loop architecture is intentionally constructed so that ε and κ are supplied by the companion preference-learning paper; this coupling is the central methodological contribution that links preference information to the constrained MDP and offline RL training. The present manuscript therefore does not re-derive or independently calibrate these quantities. In the revised Section 3 we now include a concise summary of the calibration procedure, key assumptions, and mapping to the constrained MDP from the companion work. We have further added a sensitivity study in Section 5.3 that varies κ and ε over plausible ranges and shows that the reported performance advantage is robust. Performing a separate calibration inside this paper would duplicate the companion contribution rather than advance the RL formalization that is the focus here. revision: yes
Circularity Check
Load-bearing ε and κ supplied by authors' companion paper make TTC outperformance claims conditional on self-cited inputs
specific steps
-
self citation load bearing
[Abstract]
"Two quantities from our companion preference-learning paper [Singh et al. 2026] enter as load-bearing structural elements: the execution intensity ε bounds action availability under a constrained Markov Decision Process, and the clinician capability κ weights offline-data transitions during RL training. Together they couple preference learning and RL into a two-loop architecture. We present simulation results on synthetic state machines for hypertension and type 2 diabetes. Capability-weighted offline RL outperforms uniform-weighted offline RL and the behavior policy by 15 percentage points on"
The reported 15pp outperformance on T2D TTC and the distinction between ε-aware vs. ε-naive generalization are produced by training and evaluating RL policies that treat ε and κ as fixed inputs supplied by the authors' prior work. Because these quantities are not re-derived or externally validated within the present manuscript, the performance delta and generalization claim are not independent results of the RL framework but are instead the direct consequence of applying the companion paper's definitions and values.
full rationale
The paper explicitly identifies ε (execution intensity) and κ (clinician capability) as load-bearing structural elements that reweight transitions and constrain the CMDP. These are taken directly from the authors' own 2026 companion preference-learning paper without independent derivation or external grounding shown here. The headline 15pp T2D TTC gain and ε-aware generalization results are obtained only after inserting these quantities into the offline RL training loop on synthetic state machines. This matches self-citation load-bearing: the central empirical claims reduce to the application of the companion paper's outputs rather than emerging independently from the RL formalization.
Axiom & Free-Parameter Ledger
free parameters (3)
- tiered reward thresholds
- execution intensity ε
- clinician capability κ
axioms (2)
- domain assumption Chronic disease trajectories can be represented as finite-state Markov chains whose control time is a meaningful clinical objective.
- ad hoc to paper The synthetic state machines for hypertension and T2D produce transition statistics representative of real patients.
Reference graph
Works this paper leans on
-
[1]
Constrained M arkov Decision Processes
Eitan Altman. Constrained M arkov Decision Processes . CRC Press, 1999
work page 1999
-
[2]
Concrete problems in AI safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man \'e . Concrete problems in AI safety. arXiv preprint, 2016
work page 2016
-
[3]
Marcin Andrychowicz, Filip Wolski, Alex Ray, et al. Hindsight experience replay. In Advances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[4]
Centers for Medicare and Medicaid Services, Center for Medicare and Medicaid Innovation . Advancing chronic care with effective, scalable solutions ( ACCESS ) model: Model payment amounts and performance targets. https://www.cms.gov/priorities/innovation/files/access-payments-amts-perf-targets.pdf, 2026. Effective Period: July 5, 2026 -- December 31, 2027
work page 2026
-
[5]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. Proceedings of the 36th International Conference on Machine Learning, pages 2052--2062, 2019
work page 2052
-
[6]
Guidelines for reinforcement learning in healthcare
Omer Gottesman, Fredrik Johansson, Matthieu Komorowski, Aldo Faisal, David Sontag, Finale Doshi-Velez, and Leo Anthony Celi. Guidelines for reinforcement learning in healthcare. Nature Medicine, 25 0 (1): 0 16--18, 2019
work page 2019
-
[7]
2022 aha/acc/hfsa guideline for the management of heart failure
Paul A Heidenreich, Biykem Bozkurt, David Aguilar, et al. 2022 aha/acc/hfsa guideline for the management of heart failure. Journal of the American College of Cardiology, 79 0 (17): 0 e263--e421, 2022
work page 2022
-
[8]
Russell Jeter, Christopher Josef, Supreeth Shashikumar, and Shamim Nemati. Does the artificial intelligence clinician learn optimal treatment strategies for sepsis in intensive care? arXiv preprint, 2019
work page 2019
-
[9]
Kamlesh Khunti, Marilia B Gomes, Stuart Pocock, Marina V Shestakova, Stephane Pintat, Peter Fenici, Niklas Hammar, and Jesus Medina. Therapeutic inertia in the treatment of hyperglycaemia in patients with type 2 diabetes: A systematic review. Diabetes, Obesity and Metabolism, 20 0 (2): 0 427--437, 2018
work page 2018
-
[10]
Kdigo 2024 clinical practice guideline for the evaluation and management of chronic kidney disease
Kidney Disease: Improving Global Outcomes (KDIGO) CKD Work Group . Kdigo 2024 clinical practice guideline for the evaluation and management of chronic kidney disease. Kidney International, 105 0 (4S): 0 S117--S314, 2024
work page 2024
-
[11]
Matthieu Komorowski, Leo A Celi, Omar Badawi, Anthony C Gordon, and A Aldo Faisal. The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care. Nature Medicine, 24 0 (11): 0 1716--1720, 2018
work page 2018
-
[12]
Offline reinforcement learning with implicit Q -learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit Q -learning. In International Conference on Learning Representations, 2022
work page 2022
-
[13]
Conservative q-learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. In Advances in Neural Information Processing Systems, volume 33, pages 1179--1191, 2020
work page 2020
-
[14]
Joseph Kvedar, Molly Joel Coye, and Wendy Everett. Connected health: A review of technologies and strategies to improve patient care with telemedicine and telehealth. Health Affairs, 33 0 (2): 0 194--199, 2014
work page 2014
-
[15]
Offline reinforcement learning: Tutorial, review, and perspectives on open problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint, 2020
work page 2020
-
[16]
Reinforcement learning for clinical decision support in critical care
Siqi Liu, Kay Choong See, Kee Yuan Ngiam, Leo Anthony Celi, Xinxing Sun, and Mengling Feng. Reinforcement learning for clinical decision support in critical care. Journal of Medical Internet Research, 22 0 (7): 0 e18477, 2020
work page 2020
-
[17]
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518 0 (7540): 0 529--533, 2015
work page 2015
-
[18]
Eni C Okonofua, Kit N Simpson, Ammar Jesri, Shakaib U Rehman, Valerie L Durkalski, and Brent M Egan. Therapeutic inertia is an impediment to achieving the Healthy People 2010 blood pressure control goals. Hypertension, 47 0 (3): 0 345--351, 2006
work page 2010
-
[19]
Lawrence S Phillips, William T Branch, Curtis B Cook, Joyce P Doyle, Imad M El-Kebbi, Daniel L Gallina, Christopher D Miller, David C Ziemer, and Catherine S Barnes. Clinical inertia. Annals of Internal Medicine, 135 0 (9): 0 825--834, 2001
work page 2001
-
[20]
A reinforcement learning approach to weaning of mechanical ventilation in intensive care units
Niranjani Prasad, Li-Fang Cheng, Corey Chivers, Michael Draugelis, and Barbara E Engelhardt. A reinforcement learning approach to weaning of mechanical ventilation in intensive care units. Conference on Uncertainty in Artificial Intelligence, 2017
work page 2017
-
[21]
Trial without error: Towards safe reinforcement learning via human intervention
William Saunders, Girish Sastry, Andreas Stuhlmuller, and Owain Evans. Trial without error: Towards safe reinforcement learning via human intervention. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), pages 2067--2069, 2018
work page 2067
-
[22]
Prabhjot Singh, Abhishek Gupta, Chris Betz, Abe Flansburg, Brett Ives, Sudeep Lama, and Jung Hoon Son. Learning from disagreement: Clinician overrides as implicit preference signals for clinical AI in value-based care. 2026. Available at https://arxiv.org/abs/2604.28010
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Supervised reinforcement learning with recurrent neural network for dynamic treatment recommendation
Lu Wang, Wei Zhang, Xiaofeng He, and Hongyuan Zha. Supervised reinforcement learning with recurrent neural network for dynamic treatment recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pages 2447--2456, 2018
work page 2018
-
[24]
Paul K Whelton, Robert M Carey, Wilbert S Aronow, et al. 2017 acc/aha guideline for the prevention, detection, evaluation, and management of high blood pressure in adults. Journal of the American College of Cardiology, 71 0 (19): 0 e127--e248, 2018
work page 2017
-
[25]
Reinforcement learning in healthcare: A survey
Chao Yu, Jiming Liu, Shamim Nemati, and Guosheng Yin. Reinforcement learning in healthcare: A survey. ACM Computing Surveys, 55 0 (1): 0 1--36, 2021
work page 2021
-
[26]
Offline reinforcement learning for safer blood glucose control in people with type 1 diabetes
Harry Emerson, Matthew Guy, and Ryan McConville. Offline reinforcement learning for safer blood glucose control in people with type 1 diabetes. Journal of Biomedical Informatics, 142: 0 104376, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.