Recognition: 1 theorem link
· Lean TheoremLearning Graph Foundation Models on Riemannian Graph-of-Graphs
Pith reviewed 2026-05-12 03:59 UTC · model grok-4.3
The pith
Treating structural scale as a variable via multi-scale Riemannian graph-of-graphs reduces structural domain generalization error in graph foundation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing a multi-scale GoG over subgraphs sampled at different hop distances and learning geometry-adaptive representations from Riemannian manifolds, R-GFM treats structural scale as a first-class citizen and reduces structural domain generalization error compared to fixed-scale GFMs.
What carries the argument
The Riemannian Graph-of-Graphs (GoG) that over-samples subgraphs at multiple hop distances to enable geometry-adaptive learning on manifolds.
If this is right
- Graph foundation models can better generalize across domains with varying structural scales.
- Pretraining incorporates scale as a learnable geometric property rather than a fixed parameter.
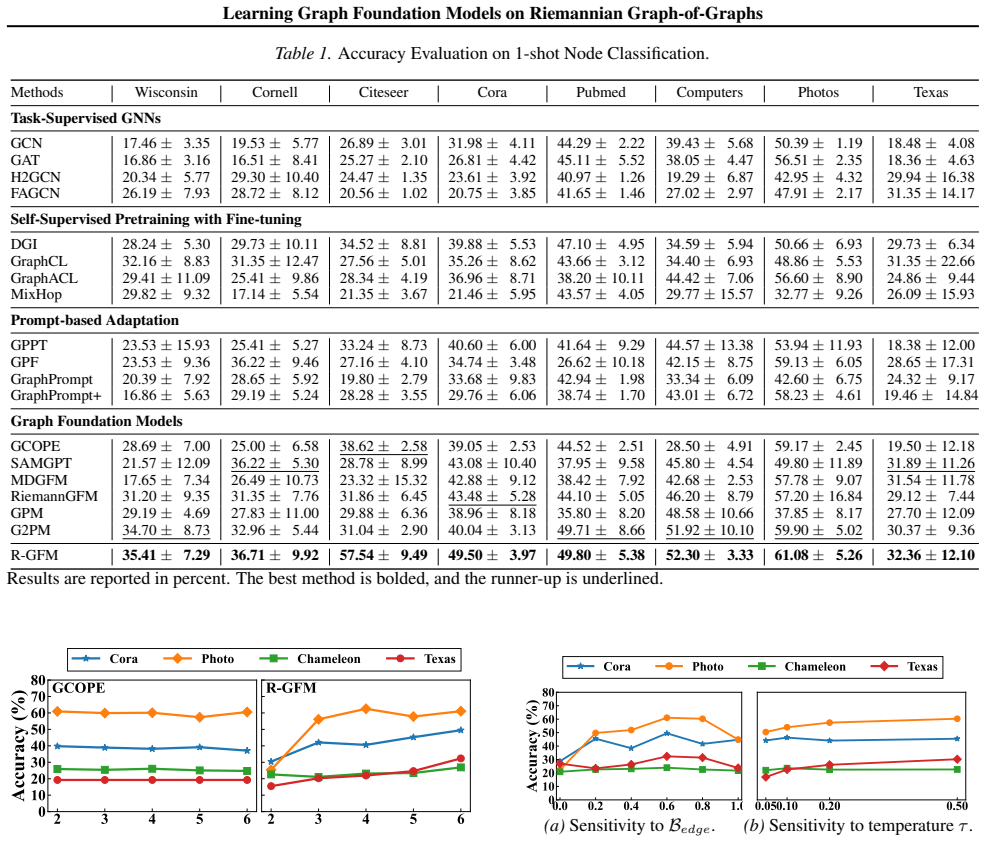
- Downstream task performance improves substantially, as shown by up to 49% relative gains.
- Structural domain shifts become less problematic due to the adaptive receptive fields.
Where Pith is reading between the lines
- Applying similar manifold-based multi-scale constructions could benefit foundation models in other structured data types.
- Computational efficiency on very large graphs remains an open question that would need empirical validation.
- Integration with existing GFM architectures might allow incremental adoption of the scale-adaptive component.
Load-bearing premise
That constructing and learning on a multi-scale graph-of-graphs over Riemannian manifolds will reliably capture heterogeneous and unknown structural contexts without introducing new sources of overfitting or computational intractability on large graphs.
What would settle it
A direct comparison where fixed-scale GFMs achieve lower or equal structural domain generalization error than R-GFM on scale-heterogeneous graph datasets would falsify the reduction claim.
Figures






read the original abstract
Graph foundation models (GFMs), pretrained on massive graph data, have transformed graph machine learning by supporting general-purpose reasoning across diverse graph tasks and domains. Existing GFMs pretrained with fixed-hop subgraph sampling impose a fixed receptive field, causing scale mismatch on diverse tasks, which often require heterogeneous and unknown structural contexts beyond a fixed sampling scale. We propose R-GFM, a Riemannian Graph-of-Graphs (GoG) based foundation model, that treats structural scale as a first-class citizen in modeling. R-GFM constructs a multi-scale GoG over-sampled subgraphs at different hop distances and learns geometry-adaptive representations from Riemannian manifolds. Theoretical analysis shows that R-GFM reduces structural domain generalization error compared to fixed-scale GFMs. Experiments on various datasets demonstrate that R-GFM achieves state-of-the-art performance, with up to a 49% relative improvement on downstream tasks. Our code is available at https://github.com/USTC-DataDarknessLab/R-GFM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes R-GFM, a Riemannian Graph-of-Graphs (GoG) foundation model for graphs. It constructs multi-scale GoGs from over-sampled subgraphs at varying hop distances and learns geometry-adaptive representations on Riemannian manifolds. The central claims are a theoretical reduction in structural domain generalization error relative to fixed-scale GFMs, plus empirical SOTA results with up to 49% relative improvement on downstream tasks.
Significance. If the theoretical reduction holds under the stated manifold and sampling assumptions and the empirical gains prove robust to controls, the work would meaningfully advance graph foundation models by elevating structural scale to a learnable, geometry-aware component rather than a fixed hyperparameter. This directly targets a known limitation of current GFMs and could improve cross-domain generalization.
major comments (2)
- [Abstract / Theoretical analysis] Abstract and theoretical analysis section: the claim that R-GFM reduces structural domain generalization error is asserted without an explicit derivation, definition of the error term, or statement of the manifold curvature and subgraph-sampling assumptions; this is load-bearing for the central contribution and prevents verification of the reduction.
- [Experiments] Experiments section: the reported 49% relative improvement lacks error bars, statistical significance tests, or explicit description of controls for baseline hyperparameter tuning and subgraph sampling; without these, the SOTA claim cannot be assessed as load-bearing evidence.
minor comments (2)
- [Methods] Notation for the multi-scale GoG construction and Riemannian operations should be introduced with a single consistent diagram or table early in the methods section to aid readability.
- [Experiments] The code repository link is provided but the manuscript does not specify which exact experimental configurations (hyperparameters, dataset splits) are reproduced by the released code.
Simulated Author's Rebuttal
We sincerely thank the referee for their constructive and insightful comments, which help us strengthen the clarity and rigor of the manuscript. We address each major comment point by point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract / Theoretical analysis] Abstract and theoretical analysis section: the claim that R-GFM reduces structural domain generalization error is asserted without an explicit derivation, definition of the error term, or statement of the manifold curvature and subgraph-sampling assumptions; this is load-bearing for the central contribution and prevents verification of the reduction.
Authors: We acknowledge that while Section 4 of the manuscript contains the theoretical analysis under the Riemannian manifold setting, the presentation in the abstract and the main theoretical section could be more explicit to facilitate verification. The analysis relies on the structural domain generalization error defined as the expected discrepancy in node representations across domains due to scale mismatch, with the reduction shown via a bound that depends on the learnable curvature and multi-scale sampling. In the revised manuscript, we will (i) add a concise statement of the key assumptions (constant negative curvature on the manifold and uniform over-sampling of subgraphs at hop distances {1,2,...,K}) directly in the abstract, (ii) include the formal definition of the error term at the beginning of Section 4, and (iii) expand the proof to provide a complete, self-contained derivation of the error reduction relative to fixed-scale GFMs. These changes will make the central theoretical claim fully verifiable without altering the underlying result. revision: yes
-
Referee: [Experiments] Experiments section: the reported 49% relative improvement lacks error bars, statistical significance tests, or explicit description of controls for baseline hyperparameter tuning and subgraph sampling; without these, the SOTA claim cannot be assessed as load-bearing evidence.
Authors: We agree that the empirical evaluation would benefit from greater statistical rigor and transparency. The 49% relative improvement is computed from mean performance across datasets, but variability and controls are not reported. In the revised version, we will: (i) report mean performance with standard deviation error bars computed over five independent runs using different random seeds for initialization and sampling; (ii) add statistical significance tests (paired t-tests or Wilcoxon signed-rank tests with p-values) comparing R-GFM against each baseline; and (iii) include a new appendix subsection that explicitly documents the hyperparameter search grids and tuning protocols applied to all baselines, as well as the precise subgraph sampling procedure (including the set of hop distances, over-sampling ratios, and how the multi-scale GoG is constructed). These additions will allow readers to assess the robustness of the SOTA claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents R-GFM as a novel architecture that constructs multi-scale Riemannian GoG representations to address fixed-scale limitations in existing GFMs. The central theoretical claim—that this reduces structural domain generalization error—is stated as following from the multi-scale manifold construction itself rather than from any fitted parameter, self-referential definition, or load-bearing self-citation. No equations or steps are shown that rename a fitted quantity as a prediction or import uniqueness via prior author work. The modeling decisions are introduced explicitly as design choices for heterogeneous structural contexts, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Riemannian manifolds can be used to model geometry-adaptive representations on graphs
invented entities (1)
-
Riemannian Graph-of-Graphs (GoG)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean; IndisputableMonolith/Foundation/AlexanderDuality.leanwashburn_uniqueness_aczel; alexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
R-GFM constructs a multi-scale GoG over-sampled subgraphs at different hop distances and learns geometry-adaptive representations from Riemannian manifolds. ... Theorem 3.2: ∥σV∥2 ≤ ∥σF∥2 ... Theorem 3.5: ϵR-GFM < ϵMDGFM
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ting Chen and Simon Kornblith and Mohammad Norouzi and Geoffrey E. Hinton , title =. ICML , pages =
- [2]
-
[3]
DuetGraph: Coarse-to-Fine Knowledge Graph Reasoning with Dual-Pathway Global-Local Fusion , author=. NeurIPS , year=
- [4]
- [5]
- [6]
- [7]
-
[8]
Kai Han and Yunhe Wang and Jianyuan Guo and Yehui Tang and Enhua Wu , title =. NeurIPS , year =
- [9]
-
[10]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[11]
M. J. Kearns , title =
-
[12]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[13]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[14]
Suppressed for Anonymity , author=
-
[15]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[16]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[17]
Collective Classification in Network Data , journal =
Prithviraj Sen and Galileo Namata and Mustafa Bilgic and Lise Getoor and Brian Gallagher and Tina Eliassi. Collective Classification in Network Data , journal =
-
[18]
Cohen and Ruslan Salakhutdinov , title =
Zhilin Yang and William W. Cohen and Ruslan Salakhutdinov , title =
-
[19]
8th International Conference on Learning Representations,
Pei, Hongbin and Wei, Bingzhe and Chang, Kevin Chen-Chuan and Lei, Yu and Yang, Bo , journal=. 8th International Conference on Learning Representations,
-
[20]
McAuley, Julian and Targett, Christopher and Shi, Qinfeng and Van Den Hengel, Anton , booktitle =
-
[21]
Pitfalls of Graph Neural Network Evaluation
Pitfalls of graph neural network evaluation , author=. arXiv preprint arXiv:1811.05868 , year=
-
[22]
Graph Attention Networks , journal =
Petar Velickovic and Guillem Cucurull and Arantxa Casanova and Adriana Romero and Pietro Li. Graph Attention Networks , journal =
-
[23]
Deyu Bo and Xiao Wang and Chuan Shi and Huawei Shen , title =
-
[24]
Jiong Zhu and Yujun Yan and Lingxiao Zhao and Mark Heimann and Leman Akoglu and Danai Koutra , title =
-
[25]
Petar Velickovic and William Fedus and William L. Hamilton and Pietro Li. Deep Graph Infomax , booktitle =
-
[26]
Yuning You and Tianlong Chen and Yongduo Sui and Ting Chen and Zhangyang Wang and Yang Shen , title =. NeurIPS , year =
-
[27]
Teng Xiao and Zhengyu Chen and Zhimeng Guo and Zeyang Zhuang and Suhang Wang , title =. NeurIPS , year =
-
[28]
Teng Xiao and Huaisheng Zhu and Zhengyu Chen and Suhang Wang , title =. NeurIPS , year =
-
[29]
Mingchen Sun and Kaixiong Zhou and Xin He and Ying Wang and Xin Wang , title =
-
[30]
Zemin Liu and Xingtong Yu and Yuan Fang and Xinming Zhang , title =
-
[31]
Xingtong Yu and Zhenghao Liu and Yuan Fang and Zemin Liu and Sihong Chen and Xinming Zhang , title =
-
[32]
Ruiyi Fang and Bingheng Li and Zhao Kang and Qiuhao Zeng and Nima Hosseini Dashtbayaz and Ruizhi Pu and Charles Ling and Boyu Wang , title =
-
[33]
Haihong Zhao and Aochuan Chen and Xiangguo Sun and Hong Cheng and Jia Li , title =
-
[34]
Xingtong Yu and Zechuan Gong and Chang Zhou and Yuan Fang and Hui Zhang , title =
-
[35]
Shuo Wang and Bokui Wang and Zhixiang Shen and Boyan Deng and Zhao Kang , title =
-
[36]
Li Sun and Zhenhao Huang and Suyang Zhou and Qiqi Wan and Hao Peng and Philip S. Yu , title =
-
[37]
Zhe Xu and Yuzhong Chen and Qinghai Zhou and Yuhang Wu and Menghai Pan and Hao Yang and Hanghang Tong , title =
-
[38]
Taoran Fang and Yunchao Zhang and Yang Yang and Chunping Wang and Lei Chen , title =. NeurIPS , year =
-
[39]
Xiangguo Sun and Hong Cheng and Jia Li and Bo Liu and Jihong Guan , title =
-
[40]
Hanchen Wang and Defu Lian and Ying Zhang and Lu Qin and Xuemin Lin , title =
-
[41]
Learning Mixed-Curvature Representations in Product Spaces , booktitle =
Albert Gu and Frederic Sala and Beliz Gunel and Christopher R. Learning Mixed-Curvature Representations in Product Spaces , booktitle =
-
[42]
Jiezhong Qiu and Qibin Chen and Yuxiao Dong and Jing Zhang and Hongxia Yang and Ming Ding and Kuansan Wang and Jie Tang , title =
-
[43]
Hamilton and Zhitao Ying and Jure Leskovec , title =
William L. Hamilton and Zhitao Ying and Jure Leskovec , title =. NeuIPS , pages =
- [44]
-
[45]
Jie Chen and Tengfei Ma and Cao Xiao , title =
-
[46]
Representation Learning with Contrastive Predictive Coding , journal =
A. Representation Learning with Contrastive Predictive Coding , journal =
-
[47]
Hanqing Zeng and Hongkuan Zhou and Ajitesh Srivastava and Rajgopal Kannan and Viktor K. Prasanna , title =. 8th International Conference on Learning Representations,
-
[48]
Zhiwei Zhen and Yuzhou Chen and Murat Kantarcioglu and Yulia R. Gel , title =
-
[49]
Constant Curvature Graph Convolutional Networks , booktitle =
Gregor Bachmann and Gary B. Constant Curvature Graph Convolutional Networks , booktitle =
-
[50]
Feinberg and Joseph Gomes and Caleb Geniesse and Aneesh S
Zhenqin Wu and Bharath Ramsundar and Evan N. Feinberg and Joseph Gomes and Caleb Geniesse and Aneesh S. Pappu and Karl Leswing and Vijay S. Pande , title =. CoRR , year =
-
[51]
Justin Gilmer and Samuel S. Schoenholz and Patrick F. Riley and Oriol Vinyals and George E. Dahl , title =
-
[52]
Hamilton and Jure Leskovec , title =
Rex Ying and Ruining He and Kaifeng Chen and Pong Eksombatchai and William L. Hamilton and Jure Leskovec , title =
-
[53]
LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation , booktitle =
Xiangnan He and Kuan Deng and Xiang Wang and Yan Li and Yong. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation , booktitle =
-
[54]
Kipf and Peter Bloem and Rianne van den Berg and Ivan Titov and Max Welling , title =
Michael Sejr Schlichtkrull and Thomas N. Kipf and Peter Bloem and Rianne van den Berg and Ivan Titov and Max Welling , title =
-
[55]
Yaguang Li and Rose Yu and Cyrus Shahabi and Yan Liu , title =
-
[56]
Zonghan Wu and Shirui Pan and Fengwen Chen and Guodong Long and Chengqi Zhang and Philip S. Yu , title =. CoRR , year =
-
[57]
Jie Zhou and Ganqu Cui and Shengding Hu and Zhengyan Zhang and Cheng Yang and Zhiyuan Liu and Lifeng Wang and Changcheng Li and Maosong Sun , title =
-
[58]
Yixin Liu and Ming Jin and Shirui Pan and Chuan Zhou and Yu Zheng and Feng Xia and Philip S. Yu , title =
-
[59]
Kaveh Hassani and Amir Hosein Khas Ahmadi , title =
-
[60]
Zhenyu Hou and Xiao Liu and Yukuo Cen and Yuxiao Dong and Hongxia Yang and Chunjie Wang and Jie Tang , title =
-
[61]
Jacob Devlin and Ming
-
[62]
Masked Autoencoders Are Scalable Vision Learners , booktitle =
Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Doll. Masked Autoencoders Are Scalable Vision Learners , booktitle =
-
[63]
Chawla and Chuxu Zhang and Yanfang Ye , title =
Zehong Wang and Zheyuan Liu and Tianyi Ma and Jiazheng Li and Zheyuan Zhang and Xingbo Fu and Yiyang Li and Zhengqing Yuan and Wei Song and Yijun Ma and Qingkai Zeng and Xiusi Chen and Jianan Zhao and Jundong Li and Meng Jiang and Pietro Lio and Nitesh V. Chawla and Chuxu Zhang and Yanfang Ye , title =. CoRR , year =
- [64]
-
[65]
Recipe for a General, Powerful, Scalable Graph Transformer , booktitle =
Ladislav Ramp. Recipe for a General, Powerful, Scalable Graph Transformer , booktitle =
-
[66]
Shurui Gui and Xiner Li and Limei Wang and Shuiwang Ji , title =. NeurIPS , year =
-
[67]
Boshen Shi and Yongqing Wang and Fangda Guo and Jiangli Shao and Huawei Shen and Xueqi Cheng , title =
- [68]
-
[69]
Hyperbolic Graph Convolutional Neural Networks , booktitle =
Ines Chami and Zhitao Ying and Christopher R. Hyperbolic Graph Convolutional Neural Networks , booktitle =
-
[70]
Pande and Jure Leskovec , title =
Weihua Hu and Bowen Liu and Joseph Gomes and Marinka Zitnik and Percy Liang and Vijay S. Pande and Jure Leskovec , title =
- [71]
-
[72]
Andrea Cavallo and Claas Grohnfeldt and Michele Russo and Giulio Lovisotto and Luca Vassio , title =. CoRR , year =
-
[73]
Yang Liu and Xiang Ao and Zidi Qin and Jianfeng Chi and Jinghua Feng and Hao Yang and Qing He , title =
-
[74]
Yu Wang and Yuying Zhao and Neil Shah and Tyler Derr , title =
-
[75]
Nino Shervashidze and Pascal Schweitzer and Erik Jan van Leeuwen and Kurt Mehlhorn and Karsten M. Borgwardt , title =. J. Mach. Learn. Res. , pages =
-
[76]
Hui Shen and Huifang Ma and Jiyuan Sun and Yuwei Gao and Zhixin Li , title =. Neural Networks , pages =
-
[77]
Jackson and Pietro Tebaldi , title =
Francis Bloch and Matthew O. Jackson and Pietro Tebaldi , title =. Soc. Choice Welf. , pages =
-
[78]
Deeper Insights Into Graph Convolutional Networks for Semi-Supervised Learning , booktitle =
Qimai Li and Zhichao Han and Xiao. Deeper Insights Into Graph Convolutional Networks for Semi-Supervised Learning , booktitle =
- [79]
-
[80]
Provably Powerful Graph Neural Networks for Directed Multigraphs , booktitle =
B. Provably Powerful Graph Neural Networks for Directed Multigraphs , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.