Recognition: no theorem link
Per-Loss Adapters for Gradient Conflict in Physics-Informed Neural Networks
Pith reviewed 2026-05-12 04:54 UTC · model grok-4.3
The pith
Gradient conflicts in physics-informed neural networks arise in distinct regimes that each need a different fix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
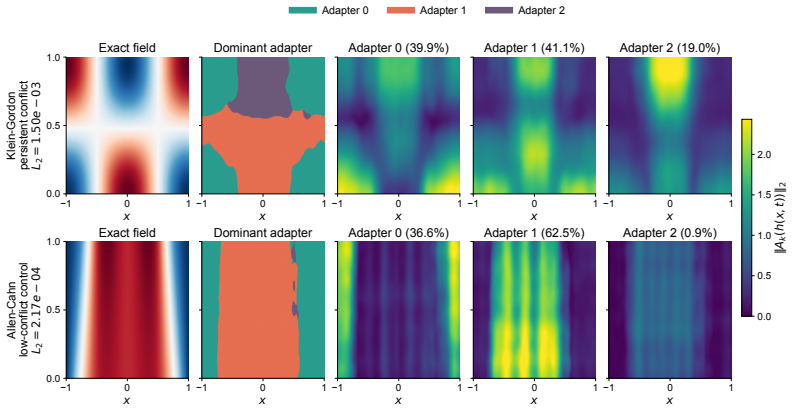
The central claim is that PINN gradient conflict is not a uniform failure mode but consists of distinct regimes—persistent directional conflict that dominates forward K=3 benchmarks and requires per-loss low-rank adapters to create explicit loss-indexed parameter subspaces, magnitude imbalance that dominates inverse problems and natural K=5 or K=6 multi-physics systems and favors scalar reweighting, and low or transient conflict that requires no extra mitigation—such that profiling a 1000-step unmodified run allows selection of the right intervention class, with adapters plus reweighting yielding significant improvements on more than 60 PDE configurations including up to 50D problems.
What carries the argument
The per-loss low-rank adapter, a lightweight module attached to each loss that creates an explicit loss-indexed parameter subspace on a shared PINN trunk, providing each loss with an independent gradient pathway.
If this is right
- Persistent directional conflict in standard forward K=3 benchmarks is best resolved by adapters combined with reweighting.
- K=3 inverse problems and natural K=5 and K=6 multi-physics systems are largely magnitude-dominated and improve with reweighting alone.
- Full-parameter-space gradient surgery performs poorly on heterogeneous parameter spaces.
- The regime-specific approach extends to parameter-varying problems and high-dimensional cases up to 50D.
Where Pith is reading between the lines
- The diagnostic-first selection process could be automated to switch remedies dynamically during training.
- This view of distinct conflict regimes may generalize to other multi-task scientific machine-learning settings.
- If the adapters remain stable at scale, they could be incorporated as default modular components in PINN architectures.
- Extending the regime analysis to time-dependent or stochastic PDEs could reveal additional conflict types.
Load-bearing premise
A 1000-step run of the unmodified PINN reliably diagnoses the dominant conflict regime, and attaching one low-rank adapter per loss creates effective independent gradient pathways without introducing new optimization pathologies or overfitting.
What would settle it
Applying the 1000-step diagnostic to a new forward PDE problem, selecting the adapter intervention, and observing no convergence improvement or worse performance compared with simple reweighting or no intervention.
Figures









read the original abstract
Physics-informed neural networks (PINNs) train a single neural approximation by minimizing multiple physics- and data-derived losses, but the gradients of these losses often interfere and can stall optimization. Existing remedies typically treat this pathology either through scalar loss balancing or full-parameter-space gradient surgery, leaving it unclear which intervention is most appropriate. We show that PINN gradient conflict is not a uniform failure mode with one universal remedy. Instead, we identify distinct PINN gradient-conflict regimes, each associated with a different intervention class. Persistent directional conflict may require separate loss-indexed parameter subspaces, magnitude imbalance often favors scalar reweighting, and low or transient conflict may require no extra mitigation. To select between scalar reweighting and a lightweight architectural intervention, we propose a diagnostic-first framework. It profiles a 1000-step unmodified PINN run and, when intervention is warranted, uses one low-rank adapter per loss to create explicit loss-indexed parameter subspaces attached to a shared PINN trunk, providing each loss with a direct gradient pathway. Across more than 60 PDE configurations, including forward, inverse, multi-physics, parameter-varying, and high-dimensional problems up to 50D, persistent directional conflict dominates standard forward $K=3$ benchmarks and a natural $K=4$ thermoelastic system, where adapters combined with reweighting yield significant improvements. In contrast, $K=3$ inverse problems and natural $K=5$ and $K=6$ multi-physics systems are largely magnitude-dominated and often favor reweighting alone, while full-parameter-space gradient surgery can fail on heterogeneous parameter spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that gradient conflicts in PINNs are not uniform but fall into distinct regimes (persistent directional conflict, magnitude imbalance, or low/transient), which can be diagnosed from a short 1000-step unmodified baseline run; it proposes routing to per-loss low-rank adapters attached to a shared trunk for directional cases (to create explicit loss-indexed subspaces) or scalar reweighting for magnitude cases, and reports that this diagnostic-first approach yields improvements over baselines in more than 60 PDE configurations spanning forward, inverse, multi-physics, and high-dimensional (up to 50D) problems, with adapters+reweighting helping forward K=3 and thermoelastic cases while reweighting alone often suffices for inverse and natural multi-physics systems.
Significance. If the empirical results and regime classification hold under scrutiny, the work offers a practical, lightweight alternative to one-size-fits-all remedies like full-parameter gradient surgery, by matching intervention class to observed conflict type. The breadth of tested configurations (forward/inverse, parameter-varying, high-dimensional) is a clear strength and could help practitioners select among existing balancing techniques more systematically.
major comments (3)
- [Methods (diagnostic framework)] The diagnostic procedure (profiling a 1000-step unmodified PINN run to assign conflict regime and select intervention) is load-bearing for the headline result that adapters+reweighting improve forward K=3 and thermoelastic cases while reweighting suffices elsewhere. However, the manuscript provides no analysis showing that cosine similarities or loss-magnitude ratios remain stable after the initial transient; gradient alignments in PINNs frequently shift once the PDE residual begins to decrease, raising the risk that the prefix misclassifies persistent directional conflict or misses late-onset imbalance.
- [Experiments and Results] Results across >60 PDE configurations: the abstract and experimental claims state that adapters combined with reweighting yield 'significant improvements' in persistent directional cases, yet the provided text supplies no quantitative metrics (e.g., relative L2 errors, convergence curves with error bars), baseline tables, or details on how regimes were assigned and statistical significance assessed. Without these, the magnitude and reliability of the reported gains cannot be verified.
- [Adapter design and analysis] § on adapter architecture: the central assumption that attaching one low-rank adapter per loss creates effective independent gradient pathways without introducing new optimization pathologies (e.g., overfitting on the adapter parameters or instability in 50D problems) is stated but not accompanied by ablation studies on adapter rank, regularization, or comparison against full-parameter surgery on the same heterogeneous spaces where surgery is reported to fail.
minor comments (2)
- [Method] Notation for the per-loss adapters and the shared trunk could be clarified with an explicit diagram or equation showing how the adapter parameters are updated independently of the trunk during back-propagation.
- [Diagnostic] The manuscript would benefit from a short table summarizing the regime-assignment thresholds (e.g., cosine-similarity cutoff or magnitude ratio) used in the 1000-step diagnostic.
Simulated Author's Rebuttal
We are grateful to the referee for the insightful comments that will help improve the clarity and rigor of our work. Below we provide point-by-point responses to the major comments and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: The diagnostic procedure (profiling a 1000-step unmodified PINN run to assign conflict regime and select intervention) is load-bearing for the headline result that adapters+reweighting improve forward K=3 and thermoelastic cases while reweighting suffices elsewhere. However, the manuscript provides no analysis showing that cosine similarities or loss-magnitude ratios remain stable after the initial transient; gradient alignments in PINNs frequently shift once the PDE residual begins to decrease, raising the risk that the prefix misclassifies persistent directional conflict or misses late-onset imbalance.
Authors: We thank the referee for pointing out this potential limitation in the diagnostic framework. The manuscript does not currently include an analysis of the long-term stability of the conflict metrics. In the revised version, we will add a new subsection with plots showing the evolution of cosine similarities and loss magnitude ratios over the full training duration for selected problems from each regime. This will help verify that the 1000-step diagnosis reliably predicts the persistent behavior. revision: yes
-
Referee: Results across >60 PDE configurations: the abstract and experimental claims state that adapters combined with reweighting yield 'significant improvements' in persistent directional cases, yet the provided text supplies no quantitative metrics (e.g., relative L2 errors, convergence curves with error bars), baseline tables, or details on how regimes were assigned and statistical significance assessed. Without these, the magnitude and reliability of the reported gains cannot be verified.
Authors: We agree that the current presentation lacks sufficient quantitative detail in the main text to fully substantiate the claims. We will revise the manuscript to include summary tables of relative L2 errors, averaged over multiple seeds with error bars, and convergence curves for key cases. We will also explicitly describe the regime assignment thresholds and how statistical significance was assessed. revision: yes
-
Referee: § on adapter architecture: the central assumption that attaching one low-rank adapter per loss creates effective independent gradient pathways without introducing new optimization pathologies (e.g., overfitting on the adapter parameters or instability in 50D problems) is stated but not accompanied by ablation studies on adapter rank, regularization, or comparison against full-parameter surgery on the same heterogeneous spaces where surgery is reported to fail.
Authors: The manuscript presents the adapter design but does not provide the ablations or comparisons requested. We will incorporate ablation studies varying the adapter rank and regularization parameters, demonstrating their impact on performance and stability, including in high-dimensional settings. Additionally, we will add comparisons with full-parameter gradient surgery on the same problems to highlight where the per-loss adapters offer advantages on heterogeneous spaces. revision: yes
Circularity Check
No circularity: empirical method with external PDE benchmarks
full rationale
The paper proposes a diagnostic (1000-step unmodified PINN run) to classify gradient conflict regimes and then applies either scalar reweighting or per-loss low-rank adapters. All headline claims of improvement are measured directly on external forward/inverse/multi-physics PDE benchmarks (K=3, thermoelastic, etc.) rather than being derived from or forced by any internal fitted quantity. No equation reduces a reported gain to a self-defined or self-fitted input; the architectural change and its evaluation remain independent of the diagnostic labels. No self-citation chain, uniqueness theorem, or ansatz smuggling is invoked to justify the central result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PINNs are trained by simultaneously minimizing multiple physics- and data-derived losses whose gradients can conflict.
invented entities (1)
-
per-loss adapters
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks. InICML, pages 793–802, 2018
work page 2018
-
[3]
Arka Daw, Jie Bu, Sifan Wang, Paris Perdikaris, and Anuj Karpatne. Mitigating Propagation Failures in Physics-informed Neural Networks using Retain-Resample-Release (R3) Sampling. InICML, pages 7264–7302, 2023
work page 2023
-
[4]
Efficiently Identifying Task Groupings for Multi-Task Learning
Chris Fifty, Ehsan Amid, Zhe Zhao, Tianhe Yu, Rohan Anil, and Chelsea Finn. Efficiently Identifying Task Groupings for Multi-Task Learning. InNeurIPS, pages 27503–27516, 2021
work page 2021
-
[5]
PINNacle: A Comprehensive Benchmark of Physics-Informed Neural Networks for Solving PDEs
Zhongkai Hao, Jiachen Yao, Chang Su, Hang Su, Ziao Wang, Fanzhi Lu, Zeyu Xia, Yichi Zhang, Songming Liu, Lu Lu, and Jun Zhu. PINNacle: A Comprehensive Benchmark of Physics-Informed Neural Networks for Solving PDEs. InNeurIPS, 2024
work page 2024
-
[6]
A. Ali Heydari, Craig A. Thompson, and Asif Mehmood. SoftAdapt: Techniques for Adaptive Loss Weighting of Neural Networks with Multi-Part Loss Functions.CoRR, abs/1912.12355, 2019
-
[7]
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-Efficient Transfer Learning for NLP. InICML, pages 2790–2799, 2019
work page 2019
-
[8]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. In ICLR, 2022
work page 2022
-
[9]
Jagtap, George Em Karniadakis, and Kenji Kawaguchi
Zheyuan Hu, Ameya D. Jagtap, George Em Karniadakis, and Kenji Kawaguchi. Augmented Physics-Informed Neural Networks (APINNs): A gating network-based soft domain decompo- sition methodology.Eng. Appl. Artif. Intell., 126:107183, 2023
work page 2023
-
[10]
Dual Cone Gradient Descent for Training Physics- Informed Neural Networks
Youngsik Hwang and Dong-Young Lim. Dual Cone Gradient Descent for Training Physics- Informed Neural Networks. InNeurIPS, 2024
work page 2024
-
[11]
Neural Tangent Kernel: Convergence and Generalization in Neural Networks
Arthur Jacot, Clément Hongler, and Franck Gabriel. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. InNeurIPS, pages 8580–8589, 2018
work page 2018
-
[12]
Ameya D. Jagtap and George E. Karniadakis. Extended Physics-informed Neural Networks (XPINNs): A Generalized Space-Time Domain Decomposition based Deep Learning Frame- work for Nonlinear Partial Differential Equations. InAAAI Spring Symposium: MLPS, 2021
work page 2021
-
[13]
Ameya D Jagtap, Ehsan Kharazmi, and George Em Karniadakis. Conservative physics-informed neural networks on discrete domains for conservation laws: Applications to forward and inverse problems.Computer Methods in Applied Mechanics and Engineering, 365:113028, 2020
work page 2020
-
[14]
RotoGrad: Gradient Homogenization in Multitask Learning
Adrián Javaloy and Isabel Valera. RotoGrad: Gradient Homogenization in Multitask Learning. InICLR, 2022
work page 2022
-
[15]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[16]
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. InCVPR, pages 7482–7491, 2018
work page 2018
-
[17]
Ehsan Kharazmi, Zhongqiang Zhang, and George Em Karniadakis. Variational Physics- Informed Neural Networks For Solving Partial Differential Equations.CoRR, abs/1912.00873, 2019. 10
-
[18]
Ehsan Kharazmi, Zhongqiang Zhang, and George Em Karniadakis. hp-VPINNs: Variational Physics-Informed Neural Networks With Domain Decomposition.CoRR, abs/2003.05385, 2020
-
[19]
Krishnapriyan, Amir Gholami, Shandian Zhe, Robert M
Aditi S. Krishnapriyan, Amir Gholami, Shandian Zhe, Robert M. Kirby, and Michael W. Mahoney. Characterizing possible failure modes in physics-informed neural networks. In NeurIPS, pages 26548–26560, 2021
work page 2021
-
[20]
How to Avoid Trivial Solutions in Physics-Informed Neural Networks.CoRR, abs/2112.05620, 2021
Raphael Leiteritz and Dirk Pflüger. How to Avoid Trivial Solutions in Physics-Informed Neural Networks.CoRR, abs/2112.05620, 2021
-
[21]
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Fourier Neural Operator for Parametric Partial Differential Equations. InICLR, 2021
work page 2021
-
[22]
Xi Lin, Hui-Ling Zhen, Zhenhua Li, Qingfu Zhang, and Sam Kwong. Pareto Multi-Task Learning. InNeurIPS, pages 12037–12047, 2019
work page 2019
-
[23]
Conflict-Averse Gradient Descent for Multi-task learning
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-Averse Gradient Descent for Multi-task learning. InNeurIPS, pages 18878–18890, 2021
work page 2021
-
[24]
FAMO: Fast Adaptive Multitask Optimization
Bo Liu, Yihao Feng, Peter Stone, and Qiang Liu. FAMO: Fast Adaptive Multitask Optimization. InNeurIPS, 2023
work page 2023
-
[25]
ConFIG: Towards Conflict-free Training of Physics Informed Neural Networks
Qiang Liu, Mengyu Chu, and Nils Thuerey. ConFIG: Towards Conflict-free Training of Physics Informed Neural Networks. InICLR, 2025
work page 2025
-
[26]
Shikun Liu, Edward Johns, and Andrew J. Davison. End-To-End Multi-Task Learning With Attention. InCVPR, pages 1871–1880, 2019
work page 2019
-
[27]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat. Mach. Intell., 3(3):218–229, 2021
work page 2021
-
[28]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts. InKDD, pages 1930–1939, 2018
work page 1930
-
[29]
Levi D. McClenny and Ulisses M. Braga-Neto. Self-adaptive physics-informed neural networks. J. Comput. Phys., 474:111722, 2023
work page 2023
-
[30]
Cross-Stitch Networks for Multi-task Learning
Ishan Misra, Abhinav Shrivastava, Abhinav Gupta, and Martial Hebert. Cross-Stitch Networks for Multi-task Learning. InCVPR, pages 3994–4003, 2016
work page 2016
-
[31]
Ben Moseley, Andrew Markham, and Tarje Nissen-Meyer. Finite basis physics-informed neural networks (FBPINNs): a scalable domain decomposition approach for solving differential equations.Adv. Comput. Math., 49(4):62, 2023
work page 2023
-
[32]
Multi-Task Learning as a Bargaining Game
Aviv Navon, Aviv Shamsian, Idan Achituve, Haggai Maron, Kenji Kawaguchi, Gal Chechik, and Ethan Fetaya. Multi-Task Learning as a Bargaining Game. InICML, pages 16428–16446, 2022
work page 2022
-
[33]
Hamprecht, Yoshua Bengio, and Aaron C
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred A. Hamprecht, Yoshua Bengio, and Aaron C. Courville. On the Spectral Bias of Neural Networks. InICML, pages 5301–5310, 2019
work page 2019
-
[34]
Maziar Raissi, Paris Perdikaris, and George E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.J. Comput. Phys., 378:686–707, 2019
work page 2019
-
[35]
Multi-Task Learning as Multi-Objective Optimization
Ozan Sener and Vladlen Koltun. Multi-Task Learning as Multi-Objective Optimization. In NeurIPS, pages 525–536, 2018
work page 2018
-
[36]
Independent Component Alignment for Multi-Task Learning
Dmitry Senushkin, Nikolay Patakin, Arseny Kuznetsov, and Anton Konushin. Independent Component Alignment for Multi-Task Learning. InCVPR, pages 20083–20093, 2023. 11
work page 2023
-
[37]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of- Experts Layer. InICLR, 2017
work page 2017
-
[38]
Guibas, Jitendra Malik, and Silvio Savarese
Trevor Standley, Amir Zamir, Dawn Chen, Leonidas J. Guibas, Jitendra Malik, and Silvio Savarese. Which Tasks Should Be Learned Together in Multi-task Learning? InICML, pages 9120–9132, 2020
work page 2020
-
[39]
N. Sukumar and Ankit Srivastava. Exact imposition of boundary conditions with distance functions in physics-informed deep neural networks.CoRR, abs/2104.08426, 2021
-
[40]
Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. InNeurIPS, 2020
work page 2020
-
[41]
Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks.SIAM J
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks.SIAM J. Sci. Comput., 43(5):A3055–A3081, 2021
work page 2021
-
[42]
Respecting causality is all you need for training physics-informed neural networks
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality is all you need for training physics-informed neural networks.CoRR, abs/2203.07404, 2022
-
[43]
When and why PINNs fail to train: A neural tangent kernel perspective.J
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why PINNs fail to train: A neural tangent kernel perspective.J. Comput. Phys., 449:110768, 2022
work page 2022
-
[44]
An expert’s guide to training physics-informed neural networks.arXiv preprint arXiv:2308.08468, 2023
Sifan Wang, Shyam Sankaran, Hanwen Wang, and Paris Perdikaris. An Expert’s Guide to Training Physics-informed Neural Networks.CoRR, abs/2308.08468, 2023
-
[45]
Gradient alignment in physics- informed neural networks: a second-order optimization perspective
Sifan Wang, Ananyae Kumar Bhartari, Bowen Li, and Paris Perdikaris. Gradient Alignment in Physics-informed Neural Networks: A Second-Order Optimization Perspective.CoRR, abs/2502.00604, 2025
-
[46]
Zirui Wang, Yulia Tsvetkov, Orhan Firat, and Yuan Cao. Gradient Vaccine: Investigating and Improving Multi-task Optimization in Massively Multilingual Models. InICLR, 2021
work page 2021
-
[47]
Self-adaptive loss balanced Physics-informed neural networks.Neurocomputing, 496:11–34, 2022
Zixue Xiang, Wei Peng, Xu Liu, and Wen Yao. Self-adaptive loss balanced Physics-informed neural networks.Neurocomputing, 496:11–34, 2022
work page 2022
-
[48]
Jeremy Yu, Lu Lu, Xuhui Meng, and George Em Karniadakis. Gradient-enhanced physics- informed neural networks for forward and inverse PDE problems.CoRR, abs/2111.02801, 2021
-
[49]
Gradient Surgery for Multi-Task Learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient Surgery for Multi-Task Learning. InNeurIPS, 2020
work page 2020
-
[50]
Leo Zhiyuan Zhao, Xueying Ding, and B. Aditya Prakash. PINNsFormer: A Transformer-Based Framework For Physics-Informed Neural Networks. InICLR, 2024. 12 Appendix Table of Contents A List of Notation 15 B Related Work 15 C Supplementary Method Details 16 C.1 Shared Feature Trunk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 C.2 Confl...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.