Recognition: no theorem link
Many Needles in a Haystack: Active Hit Discovery for Perturbation Experiments
Pith reviewed 2026-05-12 03:35 UTC · model grok-4.3
The pith
Probability-of-Hit ranks perturbation candidates by their chance of exceeding a fixed phenotypic threshold to locate many effective interventions rather than one optimum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize hit discovery as a sequential experimental design problem and propose Probability-of-Hit, an acquisition function that directly targets threshold exceedance by ranking candidates according to their posterior probability of being a hit. We prove asymptotic optimality of this approach and demonstrate strong empirical performance on both synthetic benchmarks and real biological immunology datasets, including up to 6.4% improvement over baselines on the Schmidt IL-2 dataset.
What carries the argument
Probability-of-Hit acquisition function that selects the next perturbation by maximizing the surrogate model's estimated probability that the candidate exceeds the predefined phenotypic threshold.
If this is right
- Experimental budgets in perturbation screens are spent on candidates more likely to meet the effect threshold.
- Asymptotic optimality ensures the fraction of discovered hits approaches the best possible rate as the number of tests grows.
- Empirical gains appear on synthetic benchmarks and reach 6.4% higher hit recovery on the Schmidt IL-2 immunology dataset compared with baselines.
Where Pith is reading between the lines
- The same ranking logic could transfer to other budgeted search tasks that seek many good solutions, such as screening chemical libraries or materials candidates.
- Testing the method when the threshold itself must be learned from data would reveal whether the current fixed-threshold assumption limits practical use.
- Comparing performance across different surrogate models on the same biological data would expose how sensitive the hit-ranking gains are to model choice.
Load-bearing premise
A surrogate model must supply reliable posterior probabilities that each candidate exceeds the fixed, known phenotypic threshold.
What would settle it
Running the method and standard Bayesian optimization on the same real perturbation dataset and finding that Probability-of-Hit recovers no more or fewer actual hits within the budget.
Figures

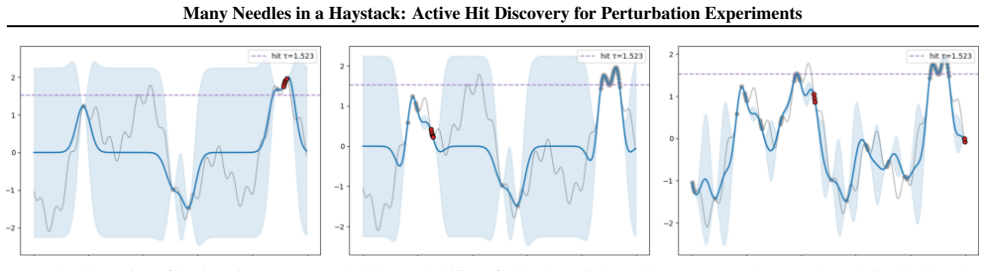




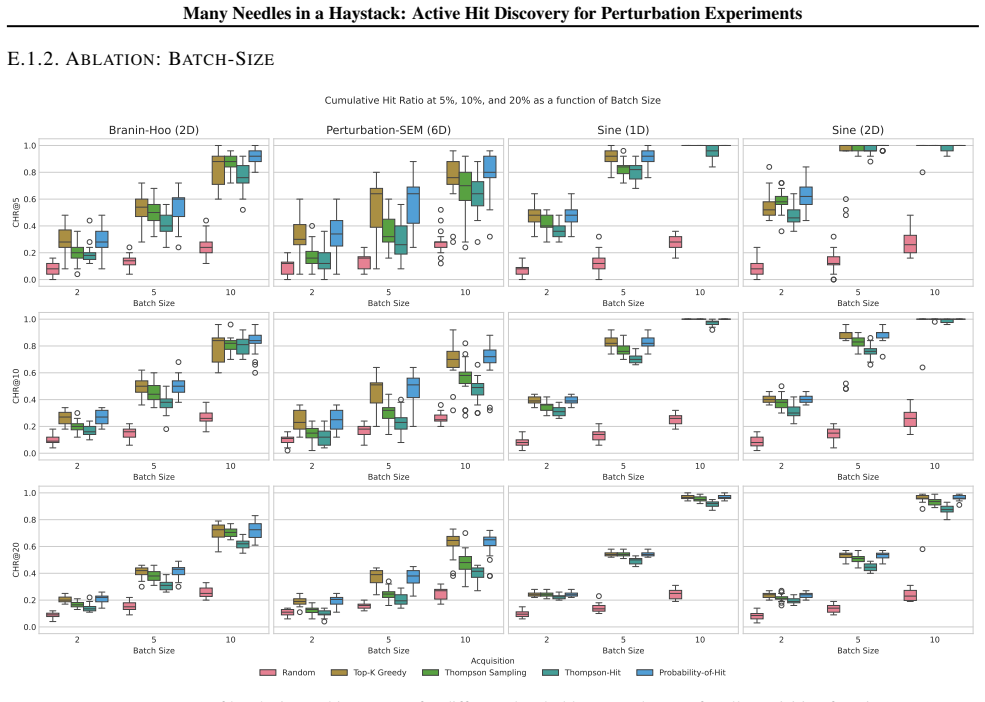




read the original abstract
High-throughput gene perturbation experiments can test several genetic interventions in parallel, yet experimental budgets remain limited. A central goal is hit discovery: identifying as many perturbations as possible whose phenotypic effect exceeds a predefined threshold. Pure exploration strategies are statistically inefficient, wasting budget on low-value regions. Bayesian optimization methods offer a principled alternative but target a single global optimum, over-exploiting dominant modes while neglecting other high-value regions. We formalize hit discovery as a sequential experimental design problem and propose Probability-of-Hit, an acquisition function that directly targets threshold exceedance by ranking candidates according to their posterior probability of being a hit. We prove asymptotic optimality of this approach and demonstrate strong empirical performance on both synthetic benchmarks and real biological immunology datasets, including up to 6.4% improvement over baselines on the Schmidt IL-2 dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes hit discovery in high-throughput gene perturbation experiments as a sequential experimental design problem. It introduces the Probability-of-Hit (PoH) acquisition function that ranks candidates by their posterior probability of exceeding a fixed phenotypic threshold τ, proves asymptotic optimality of this ranking strategy, and reports empirical gains (including up to 6.4% improvement over baselines) on synthetic benchmarks and real immunology datasets such as Schmidt IL-2.
Significance. If the asymptotic optimality holds under the paper's modeling assumptions and the empirical results prove robust to surrogate misspecification, the work offers a targeted alternative to standard Bayesian optimization for multi-hit discovery tasks. This could improve sample efficiency in biological screening by prioritizing threshold exceedance over single-mode exploitation, with potential impact on experimental design in perturbation biology.
major comments (3)
- [Section 4] Section 4 (Theoretical Analysis), Theorem 1: The asymptotic optimality proof for PoH appears to invoke posterior consistency of the surrogate (likely a GP) to guarantee that ranking by P(f(x) > τ | D) yields optimal hit discovery. In high-dimensional noisy perturbation data, such models are typically misspecified; please explicitly state the function class, noise, and consistency assumptions under which the proof holds and provide a robustness discussion or counterexample analysis when these fail, as this is load-bearing for the central theoretical claim.
- [Section 5.3] Section 5.3 (Real Data Experiments), Table 3 or equivalent results table: The 6.4% improvement on the Schmidt IL-2 dataset is reported, but it is unclear whether the threshold τ was fixed a priori (as required by the problem statement) or selected post-hoc, and whether hit definitions or data exclusion criteria were applied identically across all methods and runs. Clarify these choices and include sensitivity analysis to τ, since arbitrary threshold selection directly affects whether the reported gains validate the method.
- [Section 3.2] Section 3.2 (Acquisition Function Definition): PoH is defined as the posterior probability of threshold exceedance. Specify the exact surrogate model, how the probability is computed (closed-form, MC sampling, etc.), and any approximations used in high dimensions, as these details are necessary to assess both the proof and reproducibility of the empirical results.
minor comments (2)
- [Notation] Notation: Ensure the posterior probability symbol (e.g., P(hit|x,D)) is used consistently and defined precisely in the problem formulation section to avoid ambiguity with related quantities like expected improvement.
- [Figures] Figures: In regret or hit-discovery curves (e.g., Figure 4 or 5), include standard error bars across multiple random seeds to convey variability, and label axes with explicit units or normalized scales.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We have carefully considered each point and provide detailed responses below. Where appropriate, we have revised the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Theoretical Analysis), Theorem 1: The asymptotic optimality proof for PoH appears to invoke posterior consistency of the surrogate (likely a GP) to guarantee that ranking by P(f(x) > τ | D) yields optimal hit discovery. In high-dimensional noisy perturbation data, such models are typically misspecified; please explicitly state the function class, noise, and consistency assumptions under which the proof holds and provide a robustness discussion or counterexample analysis when these fail, as this is load-bearing for the central theoretical claim.
Authors: We agree that the assumptions should be stated explicitly. In the revised manuscript, we will add a paragraph in Section 4 specifying the function class (Gaussian Process with continuous kernel such as Matérn), noise model (homoscedastic Gaussian), and consistency conditions drawn from standard GP regression theory. We will also add a robustness discussion noting that empirical gains persist on real immunology data despite likely misspecification, supporting practical utility. A full counterexample analysis lies outside the paper's scope, but the added discussion addresses the load-bearing aspect of the claim. revision: yes
-
Referee: [Section 5.3] Section 5.3 (Real Data Experiments), Table 3 or equivalent results table: The 6.4% improvement on the Schmidt IL-2 dataset is reported, but it is unclear whether the threshold τ was fixed a priori (as required by the problem statement) or selected post-hoc, and whether hit definitions or data exclusion criteria were applied identically across all methods and runs. Clarify these choices and include sensitivity analysis to τ, since arbitrary threshold selection directly affects whether the reported gains validate the method.
Authors: The threshold τ was fixed a priori using domain-specific biological criteria from the Schmidt IL-2 data source. Hit definitions and data exclusion criteria were applied identically to all methods and runs. In the revision we will state this explicitly in Section 5.3 and add a sensitivity analysis over a range of τ values, confirming that relative gains remain stable. revision: yes
-
Referee: [Section 3.2] Section 3.2 (Acquisition Function Definition): PoH is defined as the posterior probability of threshold exceedance. Specify the exact surrogate model, how the probability is computed (closed-form, MC sampling, etc.), and any approximations used in high dimensions, as these details are necessary to assess both the proof and reproducibility of the empirical results.
Authors: We use a Gaussian Process surrogate (kernel and hyperparameter details in Section 3.1). The probability is obtained via Monte Carlo sampling from the posterior predictive distribution. In high dimensions we apply standard sparse GP approximations for tractability. We will expand Section 3.2 with these exact computational details and pseudocode to improve reproducibility. revision: yes
Circularity Check
No circularity: Probability-of-Hit is a direct definition, not a reduction to fitted inputs
full rationale
The paper defines hit discovery as sequential design and introduces Probability-of-Hit as an acquisition function that ranks points by their posterior probability of exceeding a fixed threshold τ. This is a straightforward application of standard posterior inference rather than a quantity fitted to the target metric and then relabeled as a prediction. The claimed asymptotic optimality is presented as a separate proof step whose details are not visible in the abstract, but nothing in the provided text indicates that the proof or the function reduces by construction to the data, to a self-citation chain, or to an ansatz imported from the authors' prior work. No equations are shown that equate the acquisition value to a fitted parameter or that rename an existing empirical pattern. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Stem cell reviews and reports , volume=
Genome editing in induced pluripotent stem cells using CRISPR/Cas9 , author=. Stem cell reviews and reports , volume=. 2018 , publisher=
work page 2018
-
[10]
Current opinion in systems biology , volume=
Exploring intermediate cell states through the lens of single cells , author=. Current opinion in systems biology , volume=. 2018 , publisher=
work page 2018
-
[11]
CHESS: a new human gene catalog curated from thousands of large-scale RNA sequencing experiments reveals extensive transcriptional noise , author=. Genome biology , volume=. 2018 , publisher=
work page 2018
-
[12]
The cost of new drug discovery and development , author=. Discovery medicine , volume=
-
[13]
Journal of health economics , volume=
Innovation in the pharmaceutical industry: new estimates of R&D costs , author=. Journal of health economics , volume=. 2016 , publisher=
work page 2016
-
[14]
Defining cell types and states with single-cell genomics , author=. Genome research , volume=. 2015 , publisher=
work page 2015
-
[15]
Estimation of clinical trial success rates and related parameters , author=. Biostatistics , volume=. 2019 , publisher=
work page 2019
-
[16]
Annual review of genomics and human genetics , volume=
Single-cell (multi) omics technologies , author=. Annual review of genomics and human genetics , volume=. 2018 , publisher=
work page 2018
-
[17]
Frontiers in oncology , volume=
The unique molecular and cellular microenvironment of ovarian cancer , author=. Frontiers in oncology , volume=. 2017 , publisher=
work page 2017
-
[18]
Nature Reviews Genetics , volume=
Using next-generation sequencing to isolate mutant genes from forward genetic screens , author=. Nature Reviews Genetics , volume=. 2014 , publisher=
work page 2014
-
[19]
CRISPR technology: A decade of genome editing is only the beginning , author=. Science , volume=. 2023 , publisher=
work page 2023
-
[20]
British journal of pharmacology , volume=
Principles of early drug discovery , author=. British journal of pharmacology , volume=. 2011 , publisher=
work page 2011
-
[21]
Nature Reviews Genetics , volume=
A new era in functional genomics screens , author=. Nature Reviews Genetics , volume=. 2022 , publisher=
work page 2022
-
[22]
The emerging era of cell engineering: Harnessing the modularity of cells to program complex biological function , author=. Science , volume=. 2022 , publisher=
work page 2022
-
[23]
International Conference on Research in Computational Molecular Biology , pages=
Sequential optimal experimental design of perturbation screens guided by multi-modal priors , author=. International Conference on Research in Computational Molecular Biology , pages=. 2024 , organization=
work page 2024
-
[24]
Nature Biotechnology , volume=
Predicting transcriptional outcomes of novel multigene perturbations with GEARS , author=. Nature Biotechnology , volume=. 2024 , publisher=
work page 2024
-
[25]
Gaussian process optimization in the bandit setting: No regret and experimental design,
Gaussian process optimization in the bandit setting: No regret and experimental design , author=. arXiv preprint arXiv:0912.3995 , year=
-
[26]
Journal of Global optimization , volume=
Efficient global optimization of expensive black-box functions , author=. Journal of Global optimization , volume=. 1998 , publisher=
work page 1998
-
[27]
Advances in neural information processing systems , volume=
Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning , author=. Advances in neural information processing systems , volume=
-
[28]
International Conference on Machine Learning , pages=
DiscoBAX: Discovery of optimal intervention sets in genomic experiment design , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[29]
International Conference on Machine Learning , pages=
Bayesian algorithm execution: Estimating computable properties of black-box functions using mutual information , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[30]
international conference on machine learning , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. international conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[31]
GeneDisco: A Benchmark for Experimental Design in Drug Discovery , year=
Mehrjou, Arash and Soleymani, Ashkan and Jesson, Andrew and Notin, Pascal and Gal, Yarin and Bauer, Stefan and Schwab, Patrick , booktitle=. GeneDisco: A Benchmark for Experimental Design in Drug Discovery , year=
-
[32]
CRISPR activation and interference screens decode stimulation responses in primary human T cells , author=. Science , volume=
-
[33]
Communications Biology , volume=
Genome-wide CRISPR screen identifies protein pathways modulating tau protein levels in neurons , author=. Communications Biology , volume=
-
[34]
Nature Communications , volume=
A genome-wide CRISPR screen identifies host factors that regulate SARS-CoV-2 entry , author=. Nature Communications , volume=
-
[35]
Frontiers in Immunology , volume=
Genome-wide CRISPR screen reveals cancer cell resistance to NK cells induced by NK-derived IFN-γ , author=. Frontiers in Immunology , volume=
- [36]
-
[37]
Nucleic Acids Research , volume=
STRING v11: protein--protein association networks with increased coverage , author=. Nucleic Acids Research , volume=
-
[38]
Extracting biological insights from the project achilles genome-scale CRISPR screens in cancer cell lines , author=. BioRxiv , pages=. 2019 , publisher=
work page 2019
-
[39]
A sequential algorithm for training text classifiers , author=. Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[40]
Information-based objective functions for active data selection , author=. Neural Computation , volume=
-
[41]
Gaussian Processes for Machine Learning , author=. 2006 , publisher=
work page 2006
- [42]
-
[43]
International Conference on Machine Learning , pages=
Weight uncertainty in neural networks , author=. International Conference on Machine Learning , pages=
-
[44]
Advances in Neural Information Processing Systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
International Conference on Machine Learning , pages=
On kernelized multi-armed bandits , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[46]
On Information Gain and Regret Bounds in Gaussian Process Bandits , author =. Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS) , year =
-
[47]
Nature Cell Biology , volume =
Decoding heterogeneous single-cell perturbation responses , author =. Nature Cell Biology , volume =. 2025 , doi =
work page 2025
-
[48]
Systema: a framework for evaluating genetic perturbation response prediction beyond systematic variation , author =. Nature Biotechnology , year =
-
[49]
Computational and Structural Biotechnology Journal , volume =
A mini-review on perturbation modelling across single-cell omic modalities , author =. Computational and Structural Biotechnology Journal , volume =
-
[50]
Nature Machine Intelligence , volume =
Active learning for optimal intervention design in causal models , author =. Nature Machine Intelligence , volume =. 2023 , doi =
work page 2023
-
[51]
Nature Communications , volume =
Large scale active-learning-guided exploration for in vitro protein production optimization , author =. Nature Communications , volume =. 2020 , doi =
work page 2020
-
[52]
Proceedings of the National Academy of Sciences , volume =
Machine learning-assisted directed evolution with combinatorial libraries , author =. Proceedings of the National Academy of Sciences , volume =. 2019 , doi =
work page 2019
-
[53]
arXiv preprint arXiv:2509.19988 , year =
BioBO: Biology-informed Bayesian Optimization for Perturbation Design , author =. arXiv preprint arXiv:2509.19988 , year =
-
[54]
Advances in Neural Information Processing Systems , year =
Amortized Bayesian Experimental Design for Decision-Making , author =. Advances in Neural Information Processing Systems , year =
-
[55]
Knowledge graph-aided Bayesian active learning for top- K genetic interaction discovery , author =. Scientific Reports , volume =. 2025 , doi =
work page 2025
-
[56]
Nature Communications , volume =
A Bayesian active learning platform for scalable combination drug screens , author =. Nature Communications , volume =. 2025 , doi =
work page 2025
-
[57]
A genome-wide CRISPR screen identifies CALCOCO2 as a regulator of beta cell function influencing type 2 diabetes risk , author =. Nature Genetics , volume =. 2023 , doi =
work page 2023
-
[58]
High-Resolution CRISPR Screens Reveal Fitness Genes and Genotype-Specific Cancer Liabilities , author =. Cell , volume =. 2015 , doi =
work page 2015
-
[59]
Proceedings of the IEEE , volume =
Taking the Human Out of the Loop: A Review of Bayesian Optimization , author =. Proceedings of the IEEE , volume =. 2016 , doi =
work page 2016
-
[60]
Proceedings of the 27th International Conference on Machine Learning , year =
Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design , author =. Proceedings of the 27th International Conference on Machine Learning , year =
-
[61]
Proceedings of the 23rd Conference on Learning Theory , year =
Best Arm Identification in Multi-Armed Bandits , author =. Proceedings of the 23rd Conference on Learning Theory , year =
-
[62]
arXiv preprint arXiv:0802.2655 , year =
Pure Exploration in Multi-Armed Bandits Problems , author =. arXiv preprint arXiv:0802.2655 , year =
-
[63]
Proceedings of the 27th Conference on Learning Theory , year =
lil’UCB: An Optimal Exploration Algorithm for Multi-Armed Bandits , author =. Proceedings of the 27th Conference on Learning Theory , year =
-
[64]
Proceedings of the 23rd International Joint Conference on Artificial Intelligence , year =
Active Learning for Level Set Estimation , author =. Proceedings of the 23rd International Joint Conference on Artificial Intelligence , year =
-
[65]
Active Learning for Distributionally Robust Level-Set Estimation , author =. Neural Computation , year =
-
[66]
SIAM/ASA Journal on Uncertainty Quantification , volume =
Quantifying Uncertainties on Excursion Sets Under a Gaussian Random Field Prior , author =. SIAM/ASA Journal on Uncertainty Quantification , volume =
-
[67]
Foundations and Trends in Machine Learning , volume =
A Tutorial on Thompson Sampling , author =. Foundations and Trends in Machine Learning , volume =
-
[68]
Proceedings of the 20th Machine Learning in Computational Biology Meeting , series =
PerTurboAgent: An LLM-based Agent for Designing Iterative Perturb-Seq Experiments , author =. Proceedings of the 20th Machine Learning in Computational Biology Meeting , series =
-
[69]
A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise , author =. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD) , pages =. 1996 , address =
work page 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.